In the last few years, headlines about AI have taken over the Internet.
They’ve often featured two vocabulary words, sometimes used interchangeably: GenAI (generative AI) and LLMs (large language models). Many folks, including some developers, might consider these terms to describe roughly the same thing. Like oranges and tangerines. Or developers and programmers. Or AI and ML.
However, they are different.Generative AI is a broad concept encompassing various forms of content generation, while LLM is a specific application of generative AI.
For example, GPT-4o is considered both an LLM and a GenAI model. On the other hand, Midjourney, which only generates images, is just a GenAI model.
Let’s break down this distinction.
The Semantics
The first thing to understand about GenAI and LLMs is that they aren’t opposites, synonyms, or subsets of one another. They are simply terms that describe a rough collection of models that typically emerged from clusters of research projects.
Neither is an explicit subset of the other. One of an LLM’s many powers is being a form of generative AI. One of generative AI’s many model training types is the LLM. Depending on your framing, either could be seen as the superset.
Let’s explore the twisted differences between LLMs and GenAI in detail.
What are LLMs and how do they work?
LLMs are a type of AI model that’s designed to understand and generate human language. The “large” in LLM references how the models have dramatically scaled in training scope, where tons and tons of text are ingested into the training data.
Let’s try to answer that question in the next section.
How are LLMs created?
LLMs like GPT-4o are built by training on a massive corpus of text data, with the model learning patterns from a variety of sources including books, websites, forums, and more.
The model's training involves understanding the relationships between words, which are encoded into numerical representations known as "embeddings." GPT-4's architecture, rumored to include over 1 trillion parameters, uses these embeddings and other components like attention mechanisms to improve how it handles language tasks.
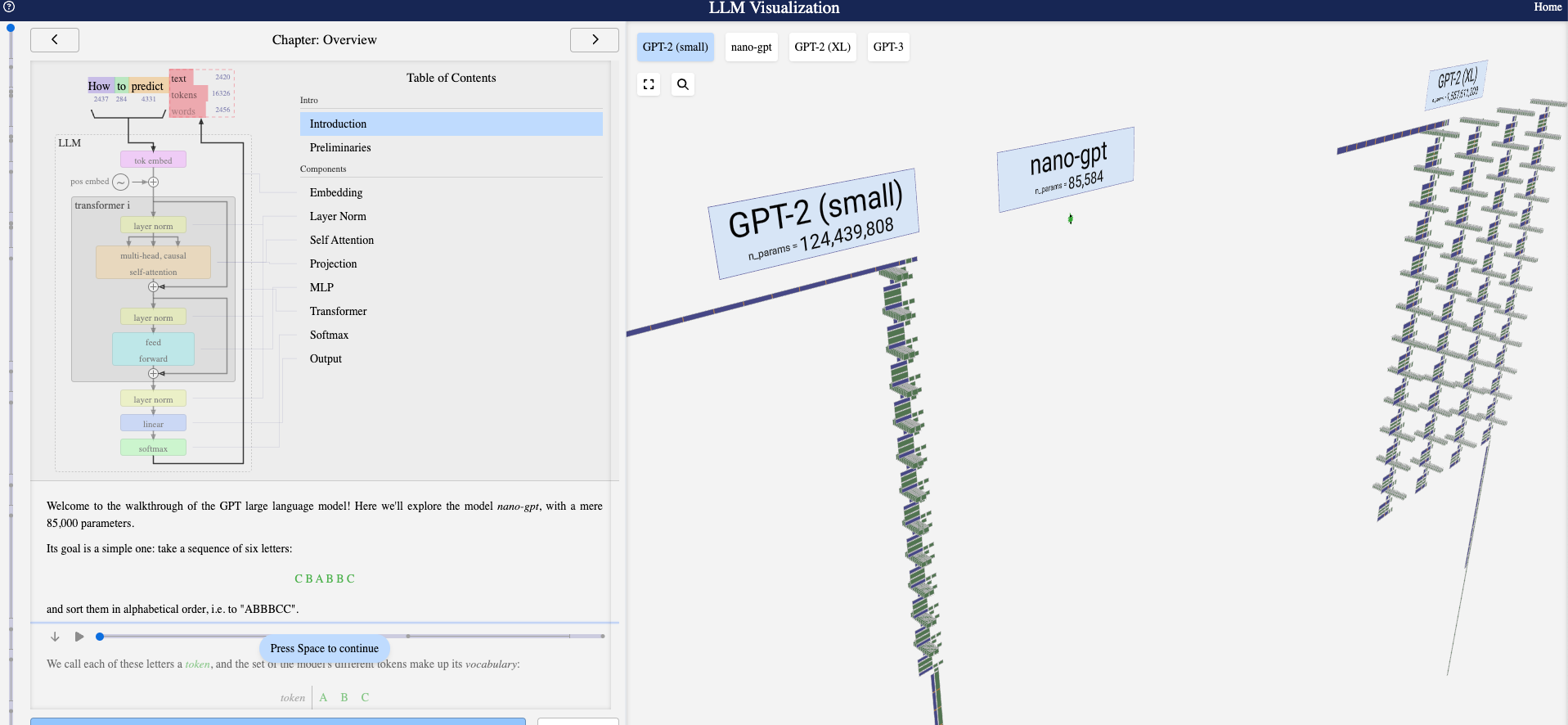
If you want to visualize how the LLM works check out this website , they visualize every part of a big language model like embeddings, layer normalization, attention until the final output.
What really moved the needle for these LLMs is the “attention” layer that introduced the Transformer architecture. You can read the official paper that changed how the Transformer changed the development of AI in the last decade here, or keep reading for a high-level overview of how this structure works.
What are Transformers?
A common word that pops up when discussing LLMs is transformers (which is denoted by the T in GPT ). A transformer is an artificial intelligence architecture that replaced previous approaches such as RNNs (recurrent neural networks), LSTMs (long short-term memory), and CNNs (convolutional neural networks).
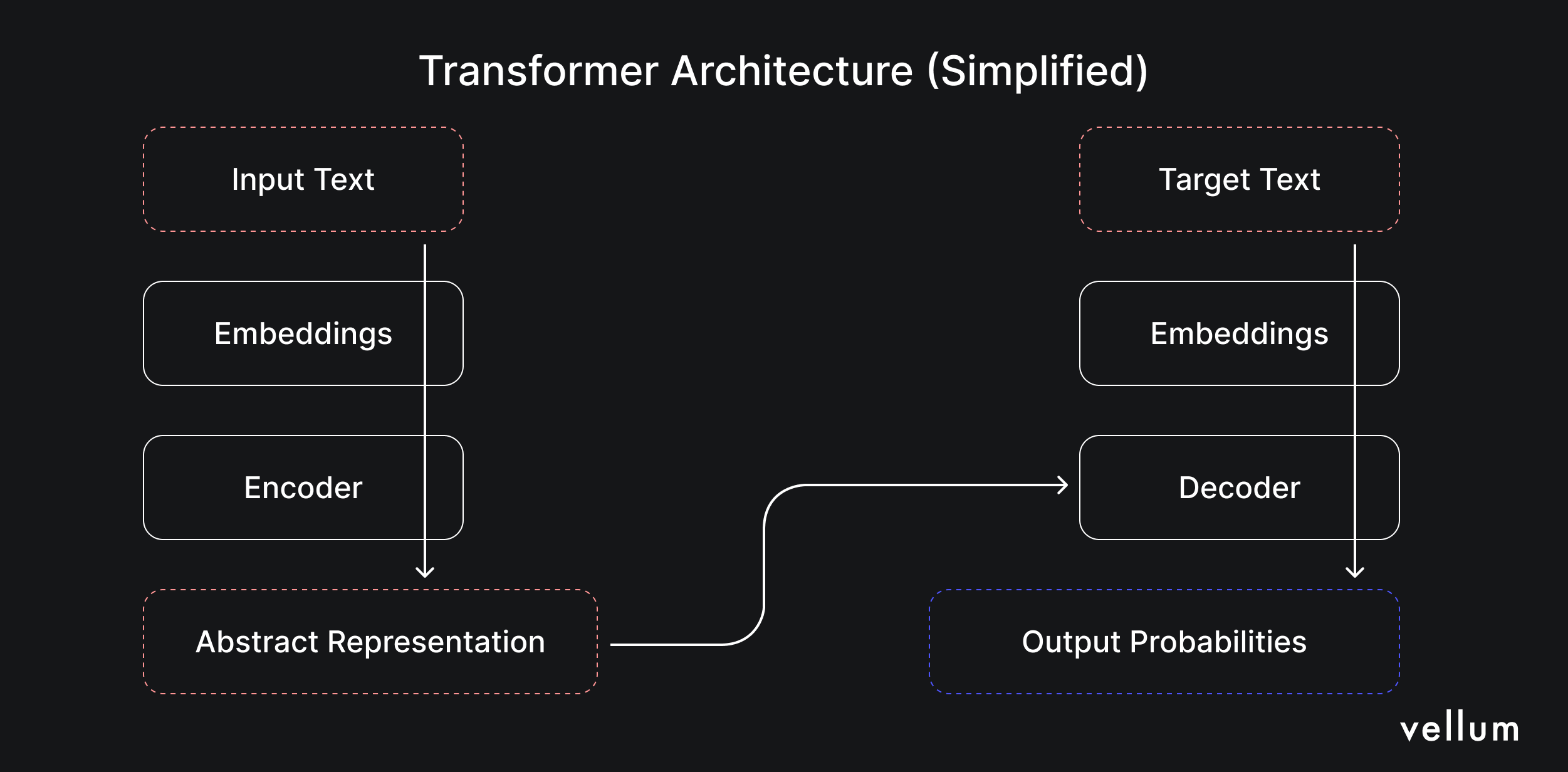
The novelty of the Transformer architecture is their ability to weigh words in a sentence in the context of the entire sentence. Previously, AI models would just process words sequentially. This difference gives the transformer architecture a better understanding of training data, plus transformers can also more efficiently process data in parallel.
This technique is not specific to LLMs. Transformer architecture is now used in vision models, speech processing, biological processing, and other niche fields.
A great visualization of the Transformer architecture can be found here !
How do LLMs Work?
So LLMs are like big prediction computers. They generate text by predicting the next word ( token) in a sentence based on the previous ones.
This prediction is guided by something called logits .
Logits are numerical values that represent how likely each possible token (word or piece of a word) is to come next in a sequence.
For example, if the model is trying to finish the sentence: "The greatest breakup song of all time is..." it might consider options like "All Too Well" by Taylor Swift or "Someone Like You" by Adele. But if it predicted something like "Shake It Off," it would probably get a very low probability, because let’s be honest, that one’s more about dancing your problems away than going through a breakup!
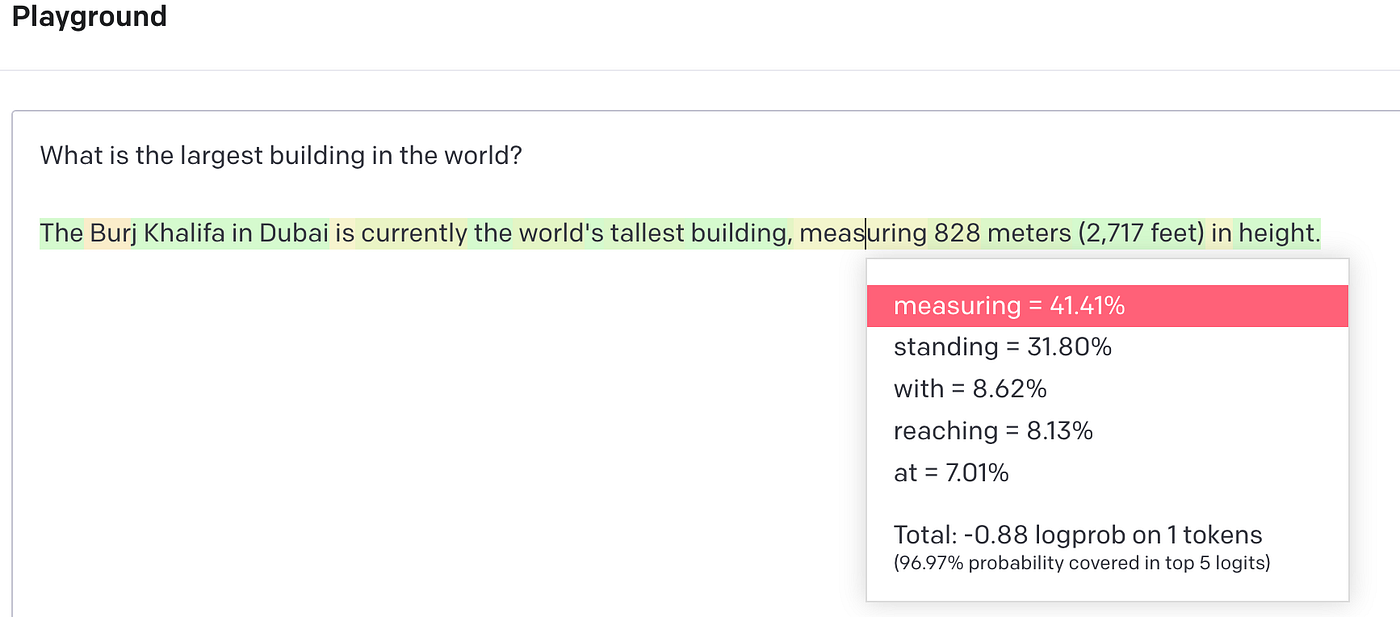
Preview of next token probability values for words that were considered after the word “building” in this context.
You can also tweak the probability of the next generated models, and you can use an LLM parameter call logprobs to do that, read more about it here .
What are the most popular LLMs today?
The flagship example of LLMs is OpenAI’s GPT series, such as GPT-4o, GPT-4.1 or the reasoning models like o1 and o3.
Others are Google’s Gemini 2.5 Pro and Flash models. Then we have Anthropic’s Claude 4.0 Sonnet, and the Claude 3 Opus and Haiku models which are currently the biggest rivals for OpenAI’s suite of models.
But more importantly we have lots of open-source LLMs like Meta’s Llama 4 , and Mistral’s Nemo and Large 2 models .
If you want to choose which LLM for your task, look at standard benchmarks, pricing, and context window (check this Leaderboard), and most importantly evaluate on your own tasks.
What can you build with LLMs?
LLMs let businesses solve age-old business and consumer problems with an open-ended tool. Companies across the spectrum have successfully tapped LLMs to improve their products and launch new offerings.
Common examples include:
(i) back-end AI features that augment existing products,
(ii) chatbots that serve either customer service or business assistant purposes,
(iii) data synthesis, extraction of data (pdf/image)
(iiii) generative tools for creating any kind of marketing/sales copy.
The latter category is also generative AI, an overlap that we’ll break down in a forthcoming section.
Because LLMs can accept fairly long prompts, they are ripe for open-ended problems that might warrant step-by-step actions. They are also strong at producing iterative content, where feedback provided on a previous response is incorporated into the next response, as opposed to the response being freshly generated and completely different.
What is GenAI and how does it work?
GenAI, or generative AI, is a class of AI models that can generate content based on patterns in their training data. GenAI does not make predictions ; instead, it imitates the data it was trained on. GenAI can be tapped in various modalities, including text, images, and video.
There are various generative AI architectures. Because LLMs could be used to generate original textual data, they, and their underlying transformer architecture, are a form of GenAI. However, for modalities beyond text, other architectures are more popular.
The most widely used is the GAN (generative adversarial network), an architecture that uses two competing networks, a generative one and a discriminating one. The former creates content, and the latter attempts to decide whether or not it’s real. GANs create models that minimize the differences between human-created and artificial content.
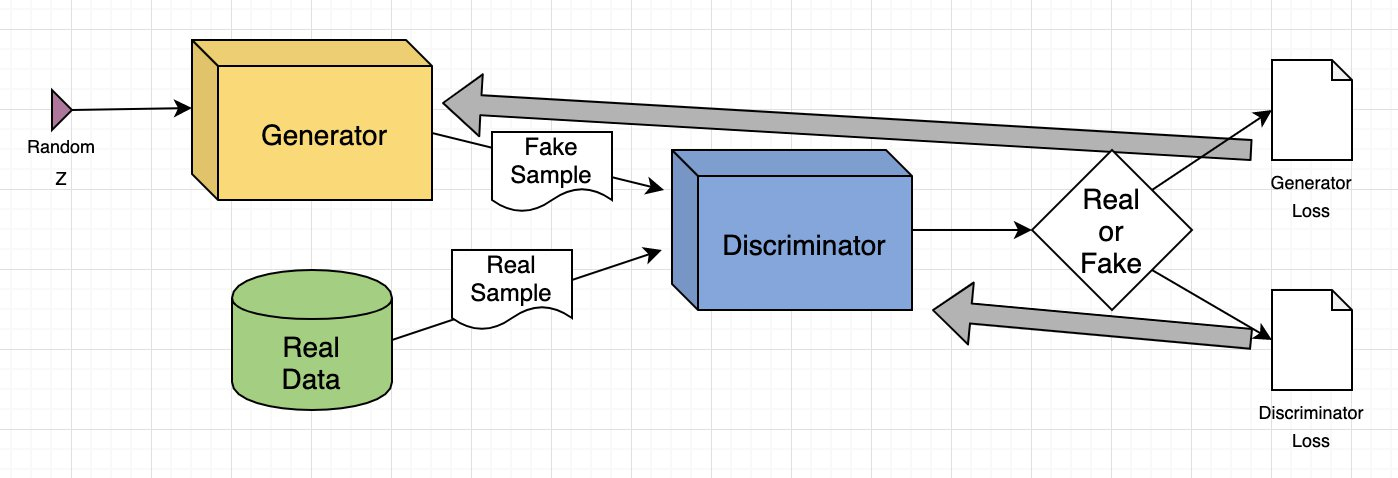
What are the most popular GenAI Models?
There are very diverse examples of GenAI.
The most popular GenAI models are image models, such as Midjourney , DALL-E 3 , or Stable Diffusion . These AI models create images using a text-based prompt but can also be used to augment existing images (e.g., Adobe’s Firefly ).
Other common GenAI models include Sora and Synthesia for videos, Meshy for 3D models, and Cursor and GitHub Copilot for code.
It’s hazier to answer the question of whether LLMs like GPT-3.5 are GenAI. From a commercial standpoint, they are. GitHub Copilot is considered GenAI because it creates new code, but it simply uses GPT under the hood by further training it on the GitHub codex. And if you ask any LLM to write a fictional story, it will do it, creating completely new content. The distinction, however, is that foundational models, like Claude 3.5, do more than generate content; they can be used as a GenAI model, but they weren’t designed to be generative.
It’s like how cars are technically public transport when used for taxi services, but aren’t a flagship example over trains or buses.
Examples of Successful GenAI apps
Because GenAI is more of a purpose-driven label, the difference between GenAI models and GenAI applications is a bit thin. For example, GitHub Copilot, Cursor, and Midjourney are all end-user products.
Other examples of successful GenAI apps are AI avatar apps like Dawn AI or Lensa , photo editing tools like Photoleap , video upscaling tools like Topaz , and a plethora of SaaS applications like Copy.ai , Simplified , or Moz .
These tools are succeeding. The AI avatar market has already hit $5.9B in value, with apps like Synthesia raising over $90M and apps like Lensa already hitting seven-figure revenue . According to Bloomberg, the entire market will hit $1.3T in value by 2032.
Closing thoughts
There are two ways of framing the overlap between LLMs and GenAI. The most obvious is when an LLM is being used for a generative purpose (e.g., writing a screenplay with GPT). The other is when one application uses multiple models toward the same goal.
An example of this latter use case is seen across industries. For example, a healthcare application may invoke an LLM to interface with a patient but use GenAI to create a diagram or visual. An e-commerce website may use an LLM for processing product data but use GenAI to create additional product shots or videos.
When you start to see the multitude of ways that GenAI and LLMs pair together, it becomes obvious why they’re so often conflated as terms. From the industry’s standpoint, they work toward the same goal.
GenAI and LLMs are both popular terms when discussing the recent explosion of AI products. While they both describe types of AI models, they define different things. GenAI articulates the goal of a model, to generate new, original content. LLMs, meanwhile, describe how the model was created, by being trained through massive corpuses of text.
Both have a bold future with the growth of AI-powered applications and will continue to evolve alongside each other.