Humanloop is a platform that helps teams build, test, and monitor AI applications. It acts like an IDE, but built specifically for how LLMs work in practice.
Here’s what it includes:
Prompt & Agent Management
You can write and manage prompts or agents in code or through a UI. It supports collaboration and keeps track of all your changes with built-in version control.
Evals & Feedback
Humanloop makes it easy to run evaluations—whether that’s automated tests, LLM-as-a-judge setups, or reviews from domain experts. It helps you catch issues early and measure real performance.
Monitoring & Observability
You can track how your system behaves in production with logging, tracing, alerts, and live user feedback. It’s built to help you spot problems like model drift or hallucinations before they reach users.
In this article, we'll compare HumanLoop to 10 alternatives, focusing on key tasks that an LLM framework should handle:
Prompt engineering Data retrieval and integration AI orchestration (Workflows/Agents) Debugging and observability Offline, online, inline evaluations CI/CD and production readiness Ecosystems and integrations
Vellum AI
Vellum AI provides the infrastructure companies need to easily build, evaluate and deploy reliable AI products at scale.
Vellum helps teams overcome the core challenges of getting AI out of prototyping and into the hands of users. The platform enables:
AI workflow definition: A visual UI builder and SDK let teams map, test and refine AI logic. Engineers and non-technical experts can collaborate side by side. End-to-end evaluation: A robust testing suite catches failures and edge cases before they reach production. Safe deployments: Push updates and publish new versions without risky redeploys. Vellum enables precise version control, even in highly complex environments. Live monitoring and continuous improvement: Real-time observability reveals how systems behave in the real world, with live feedback loops that inform testing directly.
Vellum is a strong alternative to HumanLoop, and it offers a more advanced prompt and workflow orchestration layer, tightly coupled with an evaluation and monitoring layer. It offers a managed RAG component, is modular and customizable, and built to run efficiently at scale. They also support multiple deployment options, including SaaS, self-hosted, VPC, and fully private cloud environments.
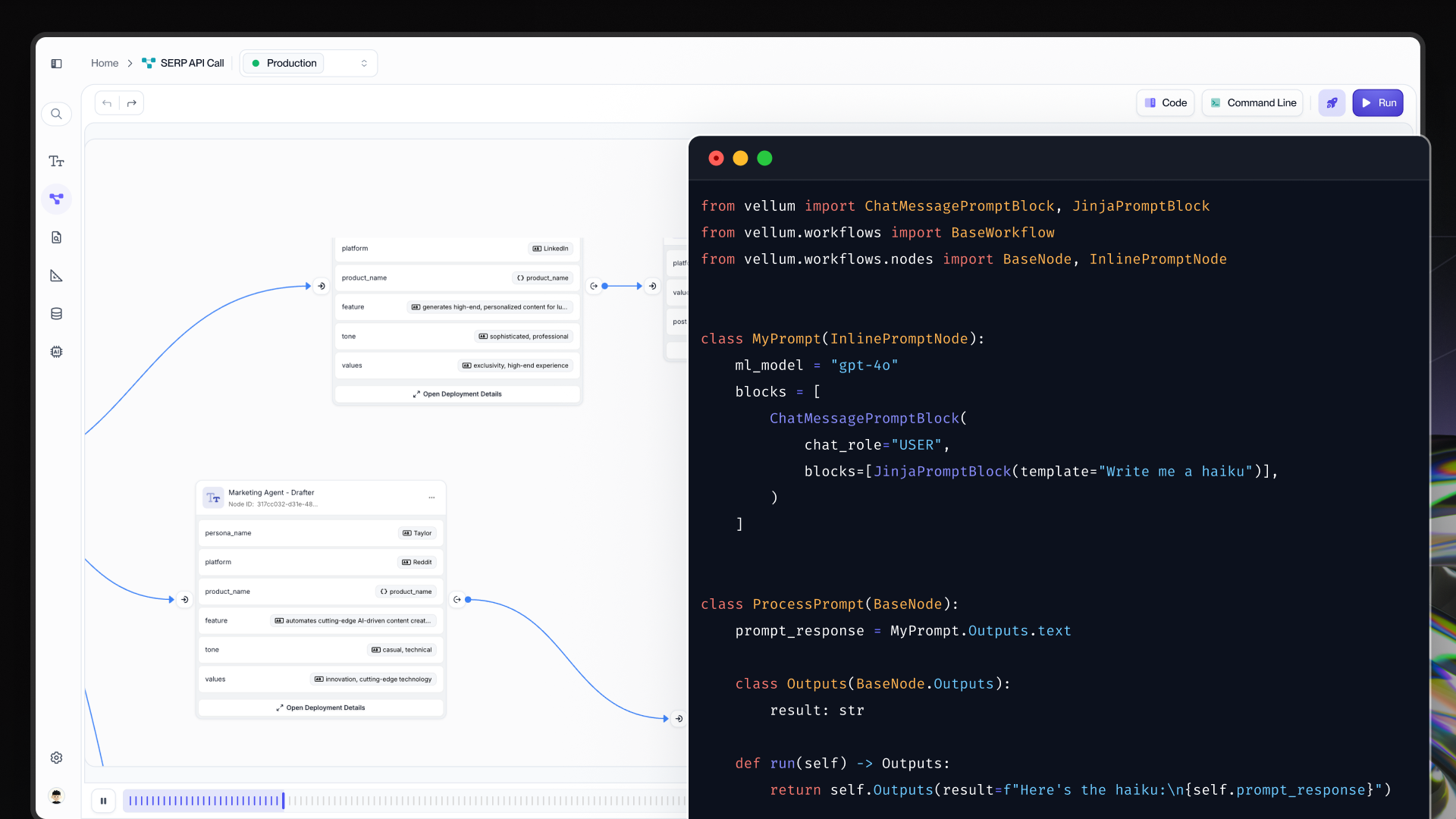
Prompt Engineering Tools
You can compare prompts , models, and LLM providers across test cases side-by-side. All prompt/model changes are version-controlled automatically, minimizing the need for code changes Upload and test custom fine-tuned and open source LLMs directly in the UI. Define tools, structured outputs and prompt caching support with native support for OpenAPI specs
Model Orchestration and Chaining (Workflows)
The Workflow builder has a UI and an SDK that lets you orchestrate custom business logic, data, RAG, tool calls, APIs, and dynamic prompts for any kind of AI system. The control flow allows you to build agentic systems with native looping, parallelism, error handling, and reusable components for team-wide standards. Deploy and invoke workflows through a streaming API without managing complex infrastructure.
Evaluations
Use out-of-the-box or custom code and LLM metrics to evaluate prompt/model combinations or workflows on thousands of test cases . Upload via CSV, UI or API. Quantitative evaluations help pinpoint trends, spot regressions, and optimize AI systems for quality, cost, and latency. Identify areas needing improvement and integrate user feedback into the evaluation dataset. Use the feedback data to improve your prompts/workflows.
Data Retrieval and Integration
Invoking the Upload and Search API allows you to programmatically upload and retrieve relevant data as context with fully managed search. You can customize the chunking and search features for your retrieval. Support for PDFs, text files, CSVs, images and more
Debugging and Observability
You build all your LLM logic in Vellum and only invoke one API to deploy the changes. There is no need for code modifications. Vellum versions the changes to Workflows and logs application invocations after deploying an AI feature. You can view each node’s inputs, outputs, and latency for an invocation, which helps with debugging.
Deployment and Production Readiness
Version Controlled changes to prompts/model with full control on release management Trace and graph views enable debugging for AI systems. Tight feedback loop to build evaluations suite Capture user feedback via UI or API. Run evaluators on your online traffic Virtual Private Cloud (VPC) with isolated subnets to create secure production environments. This allows for the logical separation of resources, improving security by restricting access and reducing data leakage.
Ecosystems and Integrations
Vellum is compatible with all major LLM providers (proprietary and open-sourced).
AutoChain
AutoChain is a lightweight and extensible framework for building generative AI agents. If you are an experienced user of HumanLoop, you will find AutoChain easy to navigate since they share similar but simpler concepts.
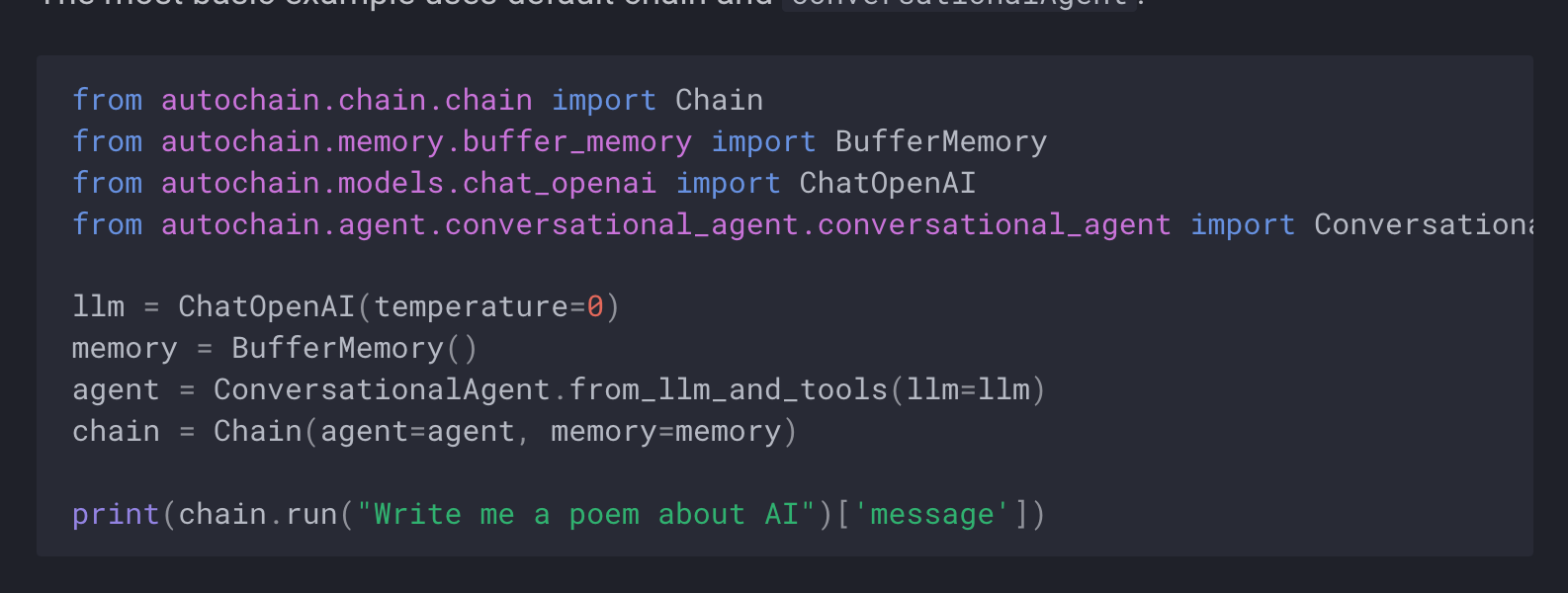
Prompt Engineering
AutoChain makes it easy to update prompts and visualize outputs for iterating over them, which is crucial for building generative agents .
Data Retrieval and Integration
Not available.
Model Orchestration and Chaining (Workflows)
It supports building agents using different custom tools and OpenAI function calling .
Debugging and Observability
AutoChain includes simple memory tracking for conversation history and tools' outputs. Running it with the -v flag outputs verbose prompt and outputs in the console for debugging.
Evaluations
AutoChain's automated multi-turn workflow evaluation with simulated conversations evaluates agent performance in complex scenarios.
Deployment and Production Readiness
Not available.
Ecosystems and Integrations
AutoChain shares similar high-level concepts with LangChain and AutoGPT, which lowers the learning curve for experienced and novice users.
Parea AI
Parea AI is a platform for debugging, testing, and monitoring LLM applications. It provides developers with tools to experiment with prompts and chains, evaluate performance, and manage the entire LLM workflow from ideation to deployment.
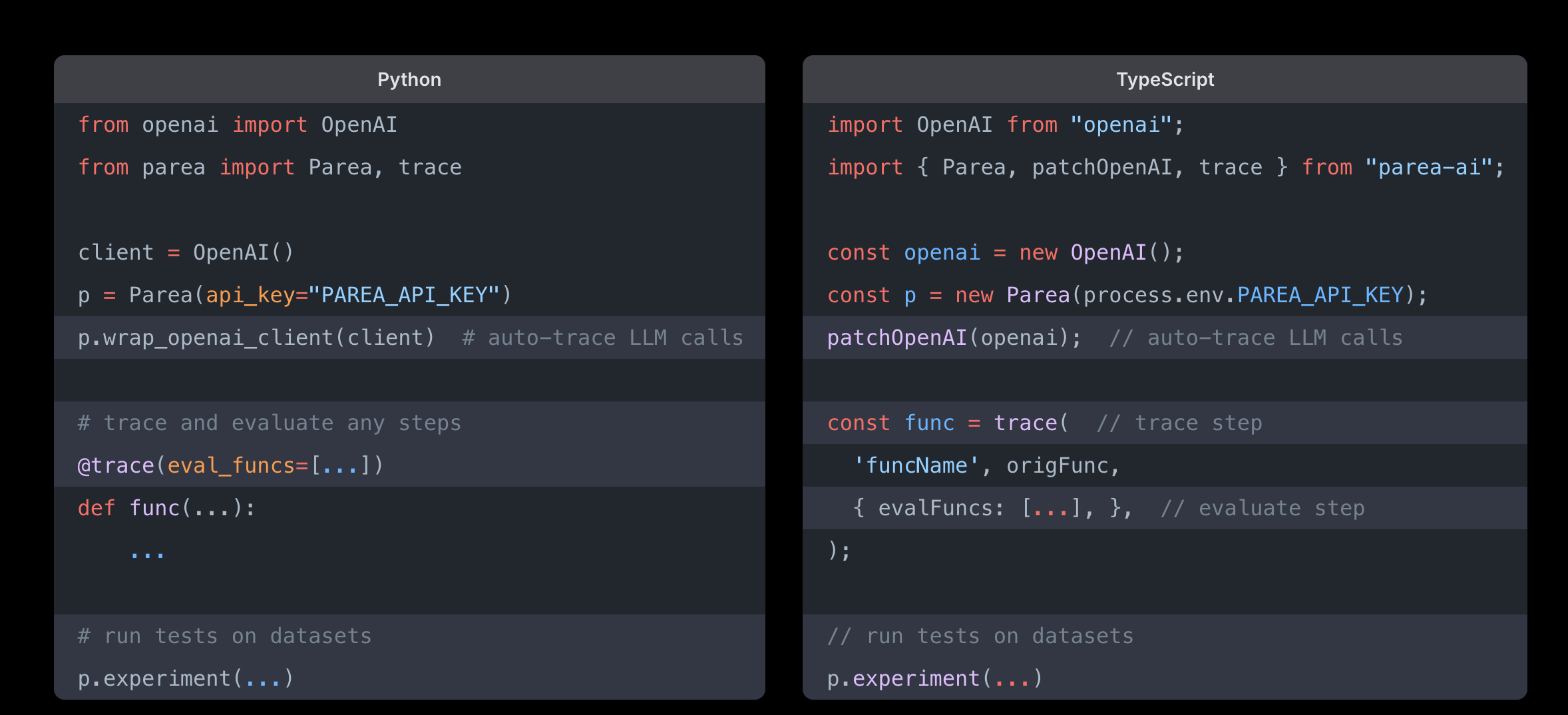
It is an alternative to Humanloop for teams building and optimizing production-ready LLM products with detailed tracing and logging.
Prompt Engineering
It includes a simple prompt playground for experimenting with prompts.
Data Retrieval and Integration
Not available.
Model Orchestration and Chaining (Workflows)
Not available.
Debugging and Observability
Parea AI includes log and trace observability features for debugging and gaining visibility into LLM responses. It includes a dashboard to compare prompts experiments , models, and parameter configurations.
Evaluations
Parea provides a set of pre-built and custom evaluation metrics you can plug into your evaluation process.
Deployment and Production Readiness
It includes the option to deploy prompts for your LLM applications and use them via the Python or TypeScript SDK.
Ecosystems and Integrations
Monitor your LangChain , Instructor , SGLang , and Trigger.dev LLM applications with the integrations.
HoneyHive
HoneyHive AI evaluates, debugs, and monitors production LLM applications. It lets you trace execution flows, customize event feedback, and create evaluation or fine-tuning datasets from production logs.
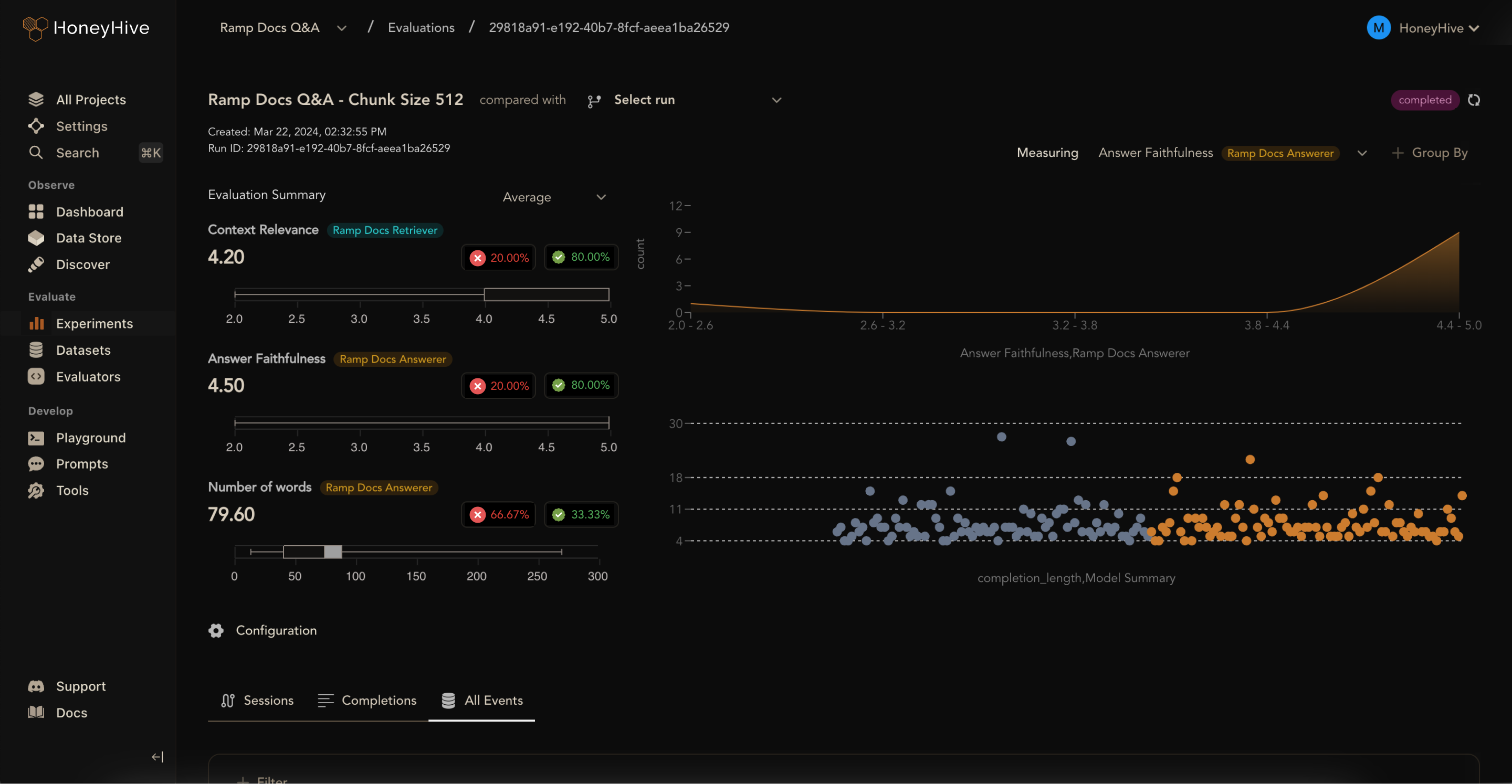
It is a good alternative to Humanloop for teams who want to build reliable LLM products because it focuses on observability through performance tracking.
Prompt Engineering
HoneyHive platform includes a collaborative workspace for teams to experiment with prompts and models.
Data Retrieval and Integration
Not available.
Model Orchestration and Chaining (Workflows)
Not available.
Debugging and Observability
It enables you to trace the execution flow of complex LLM pipelines, including LangChain chains and agents . It logs key execution details , such as inputs, outputs, and timings, providing insights into application performance and behavior.
Evaluations
Features for evaluating and testing LLM applications include automated evaluations, benchmarking, and customizable metrics. It allows users to define custom evaluators using Python or LLMs to judge specific events or sessions for quantitative monitoring of subjective traits. It includes a custom human evaluator for annotators to manually review LLM outputs. It allows you to create evaluation and fine-tuning datasets from production logs.
Deployment and Production Readiness
Not available.
Ecosystems and Integrations
Native SDKs in Python and Typescript, with additional support for languages like Go, Java, and Rust for Enterprise customers. It integrates with LangChain and LlamaIndex for logging traces and evaluating pipelines .
Haystack by Deepset
Haystack 2.0 is an open-source framework for building complex, production-ready question-answering systems and semantic search applications.
It is an alternative to Humanloop for building sophisticated and scalable LLM applications. Its pipeline architecture, customizable components, model orchestration, and extensive ecosystem integrations make it a good enough alternative.
Prompt Engineering
Haystack 2.0 includes pipeline components ( PromptBuilder , DynamicPromptBuilder , DynamicChatPromptBuilder ) that integrate with Jinja2 templating to create, test, and optimize prompts.
Data Retrieval and Integration
Introduces new data structures like the document store , which enhances its ability to handle various data types and sources.
Model Orchestration and Chaining (Workflows)
Developers can use development components ( document stores , retrievers , readers , etc.) to customize search pipelines and extend the framework's functionality. This differs from LangChain, which has a more structured approach.
Debugging and Observability
The customizable logging and tracing for production-grade LLM application deployment. Traceloop and Chainlit integrations provide full visibility into Haystack-based applications for monitoring, evaluating, and debugging LLM apps and agents.
Evaluations
Two ways of performing model-based evaluation in Haystack, both of which leverage Pipelines and Evaluator components. Integrations with evaluation frameworks, including DeepEval , UpTrain , and Ragas .
Deployment and Production Readiness
The pipeline architecture is designed to be production-ready to build robust question-answering systems with semantic search features.
Ecosystem and Integrations
Integrates with vector databases like Pinecone , Milvus , Chroma , or Weaviate to improve search performance. Integrations with local LLM tools, including Ollama and Hugging Face Model Hub to experiment with any Transformer model. Supports models offered by various providers: OpenAI , Google VertexAI Gemini , Cohere , and Mistral .
LlamaIndex
lamaIndex is an open-source data framework optimized for building RAG apps. It provides the essential abstractions to ingest, structure, and access private or domain-specific data into LLMs for more accurate text generation.
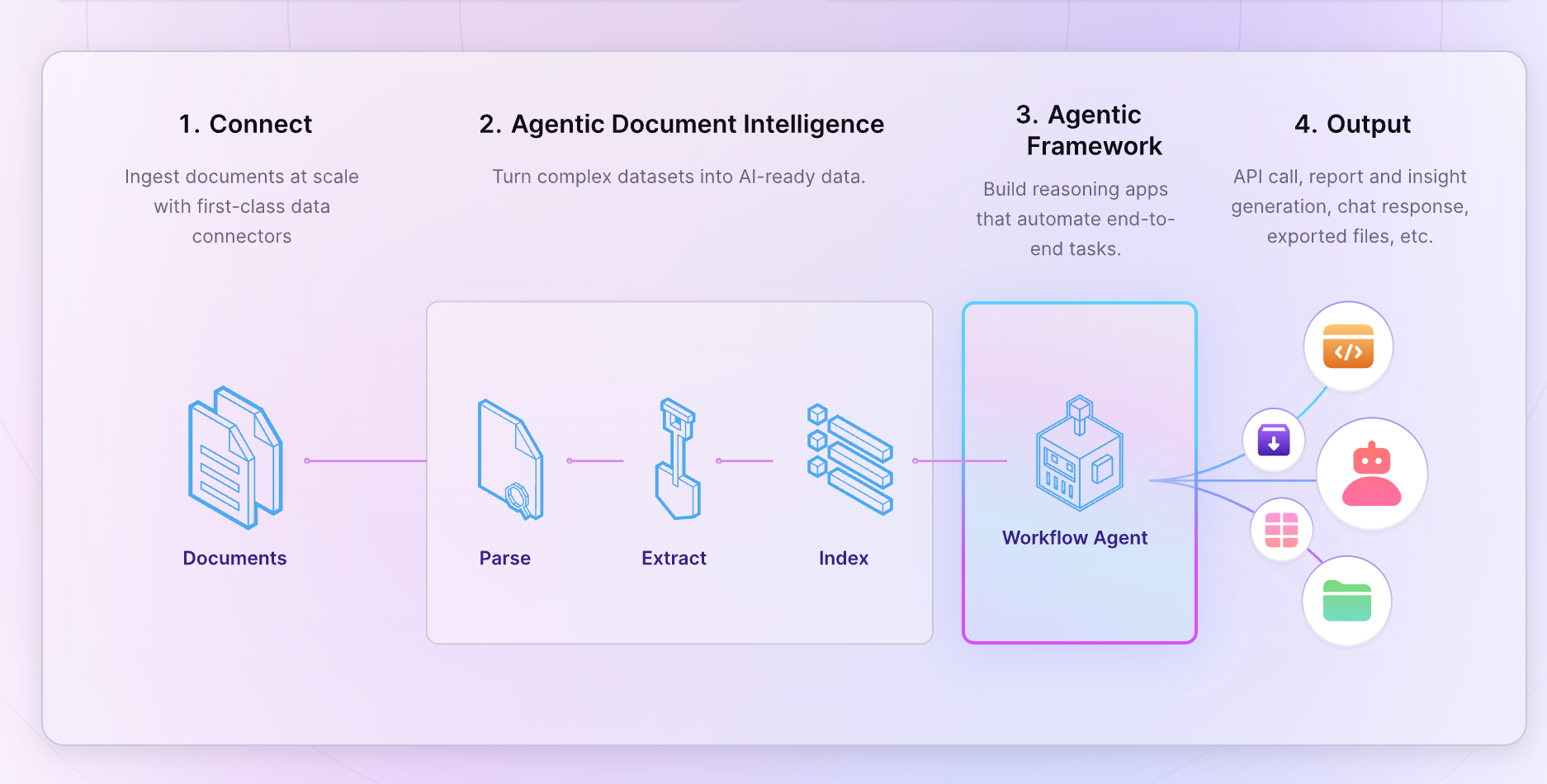
For RAG apps, LlamaIndex is a great alternative to Humanloop.
Prompt Engineering
It provides a set of default prompt templates that work well out of the box and prompts, written explicitly for chat models like GPT-3.5-turbo. Customize prompts by copying the default prompt and modifying it to suit your needs.
Data Retrieval and Integration
Includes data connectors ( LlamaHub ) to ingest data from various sources and formats, such as APIs, PDFs, SQL, and more (40+ vector stores, 40+ LLMs, and 160+ data sources), into LLM applications. Supports efficient indexing of text documents into a vector space model using VectorStoreIndex for quick and accurate retrieval of information based on queries. Use with LangChain embedding models abstraction .
Model Orchestration and Chaining (Workflows)
Includes QueryPipeline , a declarative query orchestration abstraction that allows you to compose sequential chains and directed acyclic graphs (DAGs) of arbitrary complexity. Supports chaining multiple models for complex pipelines and provides pre-built components like retrievers, routers, and response synthesizers to streamline workflow creation.
Debugging and Observability
HoneyHiveLlamaIndexTracer callback is integrated with HoneyHive to help developers debug and analyze the execution flow of your LLM pipeline. Integration with tools like AimOS and Weights & Biases provides detailed tracking and visualization of LlamaIndex interactions.
Evaluations
Integrates with evaluation frameworks like DeepEval to assess the quality of LLM applications (RAGs) using metrics like summarization, hallucination, answer relevancy, and faithfulness.
Deployment and Production Readiness
Designed to be used in a production setting, with features that support the principled development of LLM applications over your data.
Ecosystems and Integrations
Integrations with vector databases like Pinecone , Milvus , FAISS , and Weaviate to improve search performance. Can integrate with LangChain's agents abstractions and embeddings . Organized documentation available in Python and Typescript .
Flowise AI
Flowise is an open-source tool for creating LLM applications without writing a single line of code. It offers all the features of HumanLoop through a drag-and-drop user interface.
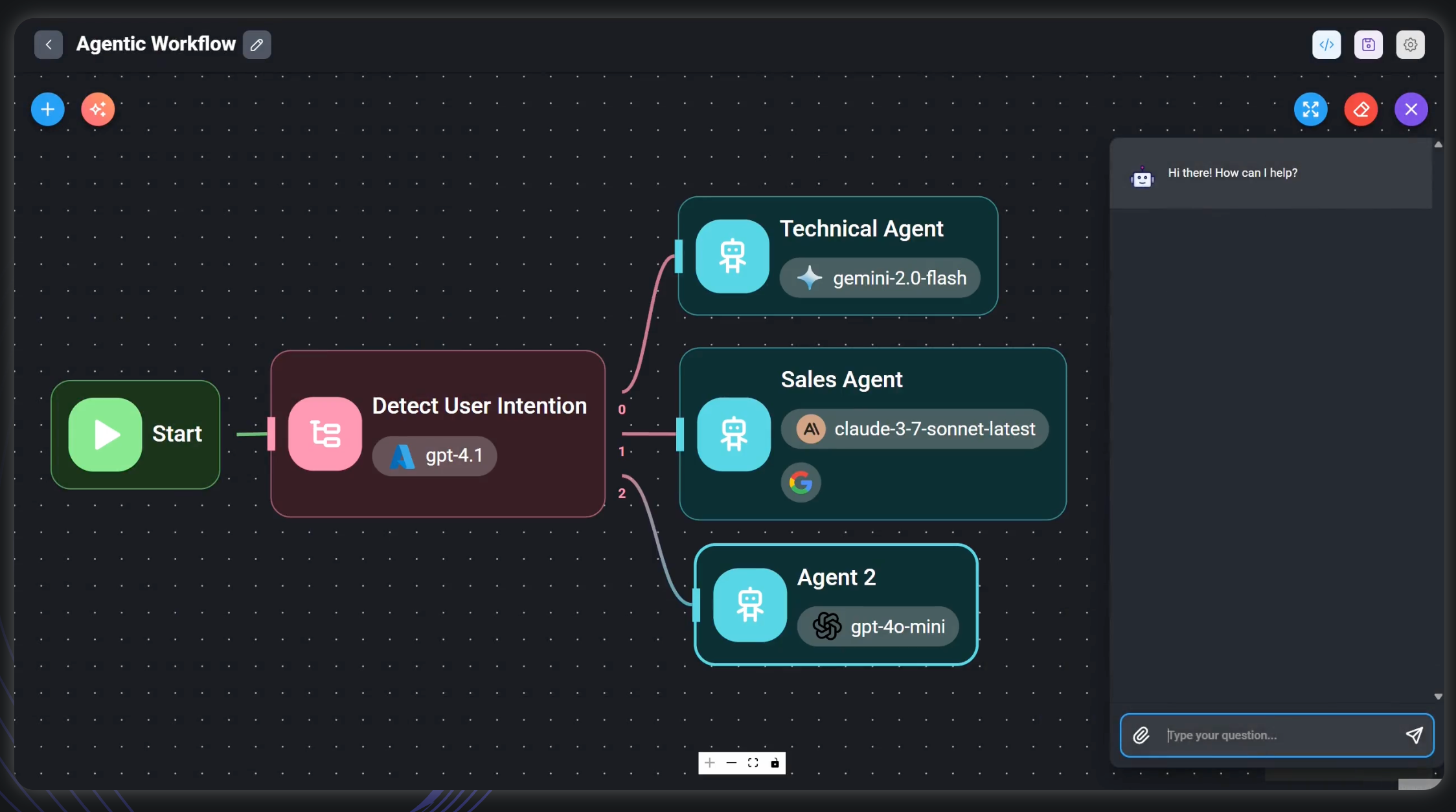
Flowise can also be integrated into websites or applications using the embedding or API endpoints.
Prompt Engineering
Flowise AI includes three templates to help you incorporate prompts into your workflow: the Basic Prompt Template (a schema representing a basic prompt for an LLM), the Chat Prompt Template (a schema representing a chat prompt), and the Few Shot Prompt Template (which includes examples).
Data Retrieval and Integration
It supports extensive data integration capabilities, including LangChain document loaders . These allow you to connect with many data sources and formats for retrieval. It supports three database types (SQLite, MySQL, and PostgreSQL).
Model Orchestration and Chaining (Workflows)
Provides a drag-and-drop user interface for building custom LLM flows and chaining different language models. Connect LLMs with memory , data loaders , caching, and moderation.
Debugging and Observability
Debug chatflows (workflows) using integrations with LangSmith and LangFuse that track your project traces.
Evaluations
Not available.
Deployment and Production Readiness
Flowise AI supports Docker for easy deployment. It offers deployment options for cloud services like Render, Railway, and Replit, as well as more technical setups with AWS, Azure, GCP, and DigitalOcean.
Ecosystems and Integrations
Includes a marketplace with pre-built templates for chatflows and agent tools. Integration with various third-party services and platforms, such as Zapier, Google Sheets, and Discord. It integrates with various platforms and tools, such as LangChain, LlamaIndex, HuggingFace , Ollama , and LocalAI.
Galileo
Galileo is a strong alternative to Humanloop for improving and fine-tuning LLM applications because it has a wide range of features for quick engineering, debugging, and observability.

The Galileo Prompt Inspector and LLM Debugger let you manage and test prompts, giving you more control over how the model works and the output quality.
Prompt Engineering
Galileo Evaluate allows you to create, manage, and track all versions of your prompt templates. It supports A/B comparison of prompts and their results to optimize prompts effectively.
Data Retrieval and Integration
Not available.
Model Orchestration and Chaining (Workflows)
Not available.
Debugging and Observability
It uses Guardrail Metrics and its Data Error Potential ( DEP ) score to help you find your most problematic data for LLM fine-tuning. Integrates into your training workflow through its dataquality Python library to detect poor data quality.
Evaluations
Evaluate your prompts and mitigate your hallucinations using Galileo's Guardrail Metrics.
Deployment and Production Readiness
Not available.
Ecosystems and Integrations
Galileo integrates with various LLM providers and orchestration libraries, such as Langchain, OpenAI, and Hugging Face, allowing users to transfer prompts seamlessly.
Braintrust
Braintrust is a platform for evaluating, improving, and deploying LLMs with tools for prompt engineering, data management, and continuous evaluation. It is a strong alternative to Humanloop if you want to develop and monitor high-quality LLM applications.
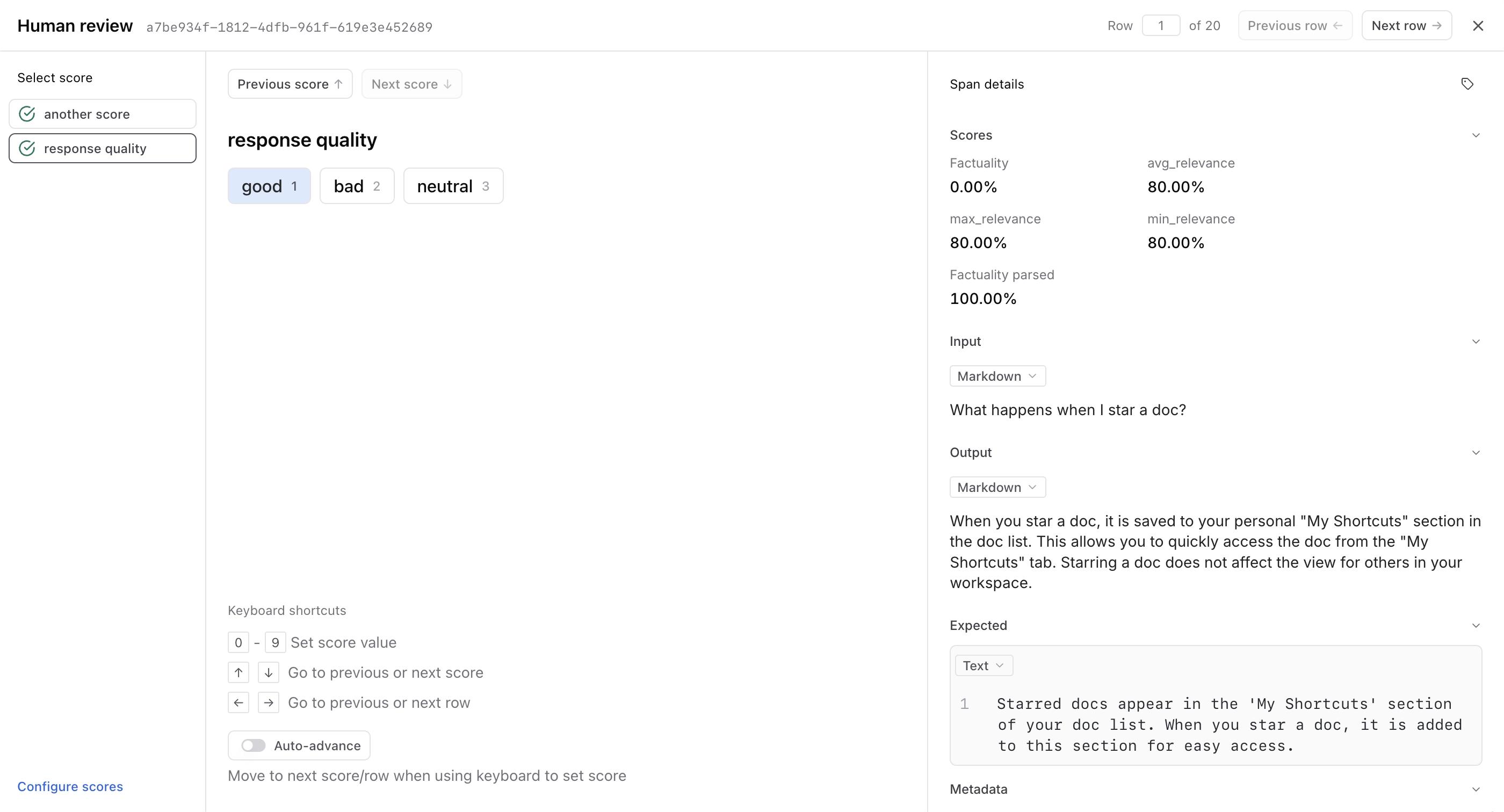
Prompt Engineering
Includes a prompt playground that allows users to compare multiple prompts, benchmarks, and respective input/output pairs between runs.
Data Retrieval and Integration
Not available.
Model Orchestration and Chaining (Workflows)
Not available.
Debugging and Observability
Braintrust allows users to log production and staging data with the same code and UI as evaluations, run online evaluations, capture user feedback, and debug issues with tracing . It allows you to interrogate failures , track performance over time, and answer questions like, "Which examples regressed when I made a change?" and "What happens if I try this new model?"
Evaluations
It includes Eval() to score, log, and visualize outputs to evaluate LLM applications without guesswork.
Deployment and Production Readiness
Includes AI Proxy feature that provides a single API to access the world's LLMs from OpenAI, Anthropic, LLaMa 2, and Mistral, with built-in features like caching, API key management, and load balancing.
Ecosystems and Integrations
It supports a long list of proprietary and open-source LLMs ; you can also add custom ones . Interact with the Braintrust through the Python and JavaScript ( Node.js ) SDKs.
Klu.ai
Klu.ai is an LLM application platform with a unified API for accessing LLMs, integrating with diverse data sources and providers . It’s nice for prototyping, deploying multiple models, and optimizing AI-powered applications.
Klu.ai is a compelling alternative to Humanloop for organizations that want to accelerate the build-measure-learn loop and develop high-quality LLM applications.
Prompt Engineering
Klu.ai uses prompts to build indexes, perform insertion traversals during querying, and synthesize final answers with default prompt templates that work well out of the box. The prompt templates include techniques for teams to explore, save, and collaborate on prompts.
Data Retrieval and Integration
It includes data connectors to ingest data from various sources and formats, such as APIs, PDFs, SQL, and more.
Model Orchestration and Chaining (Workflows)
Klu.ai allows users to connect multiple actions to create workflows. Abstractions for common LLM use cases ( LLM connectors , prompt templates , data management ).
Debugging and Observability
Monitoring of LLM applications , including usage, errors, feedback, cost, performance, and alerts.
Evaluations
Klu.ai enables users to understand user preferences, prompt performance, and label data to curate datasets and fine-tune custom models . It automatically evaluates prompt and model changes, rolling up usage and system performance across features and teams.
Deployment and Production Readiness
Klu Enterprise Container is a high-performance, private cloud platform for building custom LLM applications that reduces LLM deployment overhead.
Ecosystems and Integrations
Interact with the Klu API with Python or TypeScript SDKs . Use Klu CLI to configure applications through declarative YAML files. Integrates with multiple LLM providers , including OpenAI, Anthropic (Claude), AWS Bedrock, and HuggingFace.
How to choose the right architecture
Selecting the right tool depends entirely on your team's goals, resources, and existing tech stack. As you evaluate these alternatives, consider the following questions:
What is your primary use case? Are you building a simple Q&A bot, a complex RAG system, a multi-agent workflow, or a custom ML model? Platforms like Haystack excel at RAG. What is your team's technical expertise? Do you need a no-code/low-code visual builder like the one offered by Vellum, or does your team prefer a code-first, open-source framework like Griptape or Rasa? Where does this fit in your product lifecycle? The right tool often depends on whether you are in the validation, scaling, or optimization phase of your product. Aligning your tool choice with product maturity is crucial for success. What are your integration and infrastructure needs? If your organization is already heavily invested in AWS, Azure, or GCP, their native AI platforms offer significant advantages in integration and billing
Conclusion
Success with LLM applications comes down to ongoing experimentation and learning. Choosing a strong platform that supports developers, PMs, and domain experts alike is key to making that process work.