If you want to understand where practical AI is really headed, the AIE world’s fair in SF is the place to be. It brings together practitioners (engineering, PMs, experts) who are shaping the ideas and methods the rest of the world will catch up to probably next year.
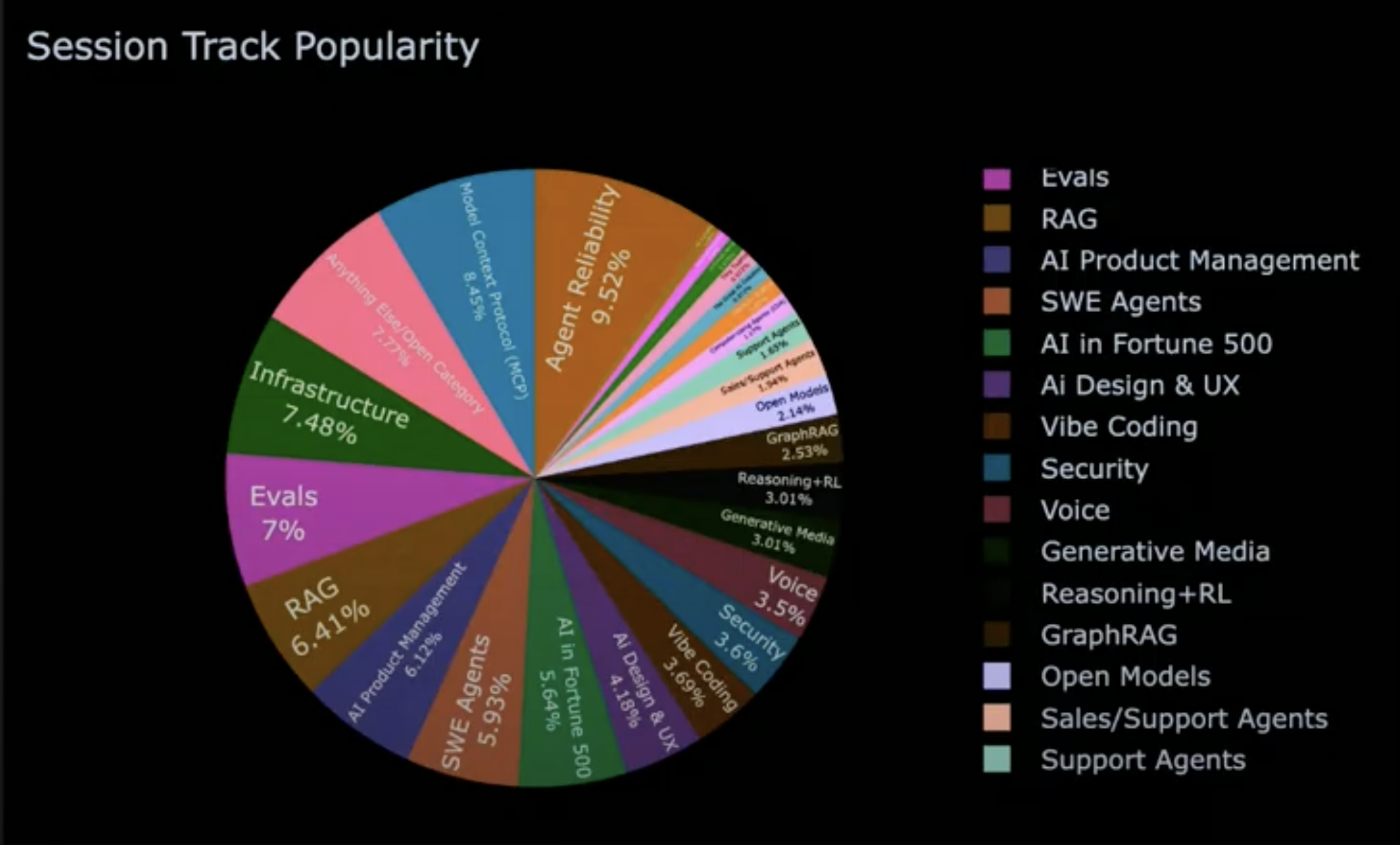
This year, the conference put a few major themes into the spotlight (sorted in order of popularity): Agent reliability, MCP, infra, evals, (graph) RAG, AI product management, SWE agents, AI in Fortune 500 and AI design/UX, vibe coding, security, and voice among others:
With this writeup I’ll try to summarize the most insightful parts and provide a resource for those who missed the event. If you attended, it’s a handy resource to revisit key takeaways or share them with your team!
1. Standard models in AI eng
With software, we have things like Agile, CI/CD, TDD, models that support reliable shipping. With AI, that clarity doesn’t exist yet.
In the keynote, swyx famously talked about the standard models in AI engineering, saying that it’s still to early to say which model is going to become the standard for AI engineering.
LLM OS (Karpathy’s version where LLMs manage your OS) SDLC (Test-driven development; my money is on this, I wrote about it here ) Building Effective Agents (Models instead of scaffolding, post here ) DSPy (Programming LLMs instead of prompting) DocETL/Petals ( “Decentralize the heavy bits” mindset) Agent engineering: IMPACT (Treating agents like systems, with six properties an agent needs at runtime to function well: intent, memory, planning, authority, control flow, tools. Listen to the presentation here )
2. The value of AI products
Another interesting point that was brought up in the keynote is on how to think about valuing AI products. Currently it doesn’t matter how agentic your AI product is, but how much value you get per unit of human effort. One sentence in, one sentence out? Low leverage. One sentence in, full deep researched report out? High leverage. And that’s what counts.
Some examples that were observed:
1:0.5 (e.g., Copilot): AI assists but still rely heavily on human effort. 1:1 (e.g., ChatGPT): Balanced contribution, where AI matches human input. 1:10 (e.g., O-series, Reasoners, Simple Agents/Workflows): AI improves productivity significantly. 1:10,000 (e.g., Deep Research, NotebookLM): AI dominates task execution, delivering exponential value. 0:1 (e.g., Ambient Agents): AI integrates with your stack, you don’t provide input
3. Vibe coding shapes what's ahead
One of the most interesting insights from Greg Brockman is that vibe-coding is amazing as an empowerment mechanism. The current conception of vibe-coding is an interactive loop of coding without a goal, and what will be new and transformative is to transform existing applications and go deeper. So many companies are sitting on legacy systems, and it’s so hard (and not fun!) to update them, and we’re starting to get AI tackle that problem.
Even with Codex, the goal is to have agents you treat like coworkers, where you’ll run 100 copies in parallel to get real work done.
Greg said that agentic coding will intercept the vibe-coding growth, and everything will be done by an AI-coworker. That’s the idea behind Codex, running 100 agents you work with like coworkers.
Watch the full panel with Greg here.
4. MCP is maturing
Anthropic improved the protocol based on the massive community feedback and recently launched their support for streamable HTTP . Now the protocol uses HTTP POST for client-server communication and optional SSE streams for richer, server-initiated functionalities. Read about the new direction here.
There are updates on auth (more on it here ), centralized repo for MCP servers (community driven), and MCP elicitation , a way for tools to ask for more info from the user.
→ Next step is more simplicity and evals!
According to Anthropic, the biggest startup opportunities around this protocol is on building vertical servers (collapsing agents into a server, e.g sales servers), simplifying the build (automated MCP builds), and then increasing support for AI evals/observability for enterprises who want to use MCP in prod!

→ More tools ≠ better agents
Harald Kirschner , from Microsoft highlights that quality over quantity is still the norm in building effective agents. Here are a few best practices he shared on using tools with MCP:
1/ Manually reduce the # of tools required to complete a specific task
2/ Mention tools in prompts, and reference only if a user asks for it
3/ Re-use task-specific tools across tasks wherever you can
He shares more best practices on how to use Roots, Resources, Sampling with the protocol, watch his talk here .
📺 Full MCP track here from the 2:30min mark.
5. Most agents are not that agentic
One very interesting talk was from Dex Horthy from HumanLayer who went over his 12 factor agents article that was trending a few months ago on HackerNews. The core of the talk is that most AI products out there calling themselves as “AI Agents” are not that agentic. Mostly are deterministic code, with some LLM steps throughout. His 12 factors agent covers the principles of how to build good AI software, and the statements are very opinionated! The recording is still not up, but you can read the article here .

6. Evals is all you need
If you’re building an AI product or starting an AI-first startup, evals will become the #1 thing that you need to do right. This was one of the most talked-about tracks at the conference, and everyone highlighted how manual and difficult it still is to run evals.
Here are some the things that were covered:
1/. Ankur from Braintrust talked how evaluation is an extremely manual and extensive tasks. This can be augmented using AI, so that you can create datasets, and scorers on autopilot using your context (watch this talk )
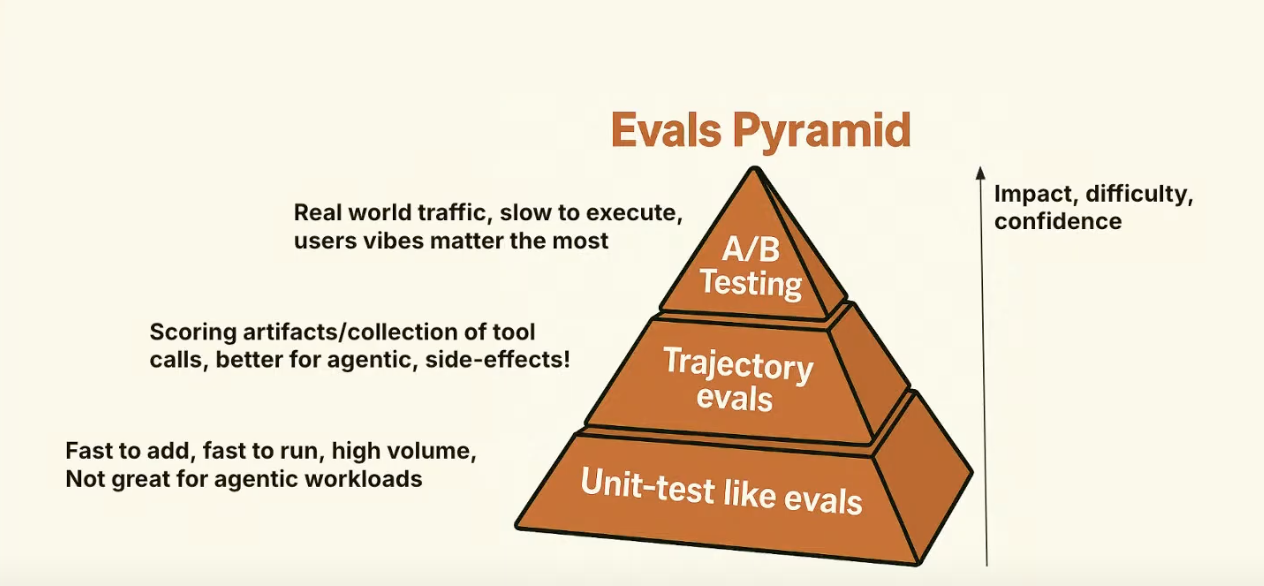
2/ The folks from Zapier talked how explicit feedback is rare, and that you need to look for implicit signals in the UI, conversations. But the ultimate implicit signal are your user metrics. They also mentioned that evals are tough to get right, but they're working on trajectory evals; evaluating their systems end to end . This is something that we’re seeing with our customers as well! ( talk here )
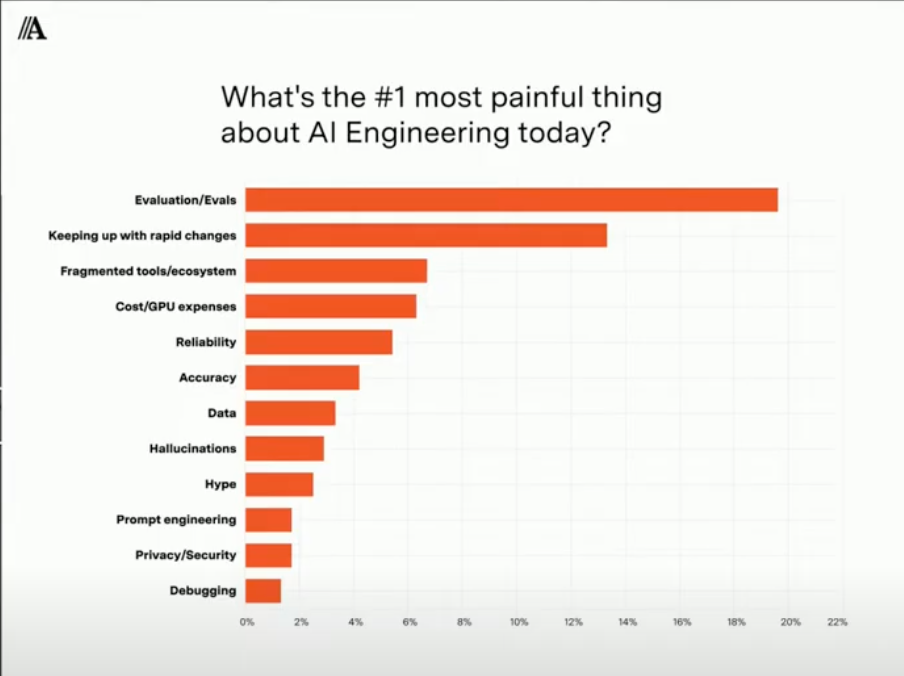
3/ The #1 most painful thing about AI engineering today is Evals according to Barr Yaron from Amplify Partners who ran an enormous survey with AI practitioners. Keeping up with rapid changes and fragmented tools/ecosystem are the next biggest challenges.
Watch the whole Evals track here: link
7. PMs are critical for reliable AI
Product Managers are key to building reliable AI products. They are the ones who care about product requirements and need to own the context, data and output we surface to end users. What’s missing today are tools that give PMs control; so they can shape and refine AI behavior without depending on engineers.
Here are some other high level insights (the recording is not available yet!):
The best PMs today are owning the eval process, and they’re moving beyond “vibe-checks” and adopting repeatable eval strategies, becoming more technical throughout the process. PMs are leading the charge of creating personalized software per specific customer account, and owning the iterative process of improving AI features in prod Building an AI feature or a product today is messy, and PMs end up writing specs for affordances instead of features, then rely on evals to get the product right for end users
8. GraphRAG is kinda back
Seems like knowledge graphs are finally getting their moment. So much so, that GraphRAG was a special track at the AIE conference.
Seems like as we’re staring to build more complex AI agents, we need more hierarchical support + explainability for the data we retrieve. The concept of GraphRag made sense ever since Microsoft released their paper , but maybe no one needed it because the overhead was not worth it at the time, as we got the same value from naive RAG.
Below some other interesting insights from the Retrieval + GraphRAG tracks:
Calvin from Harvey AI talked that domain-specific challenges require creative solutions across data, modeling, infra. Make sure you’re building for iteration speed and flexibility The Neo4j team showed a great GraphRAG demo, and explain the process here: demo link. They also explained how GraphRAG is context rich, it’s grounded and gives us the opportunity to explain what we’re doing.. and potentially at a lower cost. ( watch here ) Mitesh from NVIDIA talked about Hybrid RAG, that mixes the graph + naive rag ( talk here ) Sam Julien , from Writer shared their journey developing a graph-based RAG architecture that achieved 86.31% accuracy on the RobustQA benchmark and how this is more useful for enterprise scenarious given the easy explainability and tracing they can expose in the UI ( talk here ) Vasilije , from Cognee showed a demo how they create semantic graph that powers an recruitment agent. In the demo they compare Github data to determine who is a better developer.
Retrieval + Search talk here: link link
GraphRAG talks here: link link
9. Voice agents are on the rise
Seems like the voice field is becoming an interesting new trend, because integrating stable AI voice capabilities is becoming somewhat easier . Seems like the biggest challenges are around making interruptions and dialog more natural. Some great talks on this track, that I sadly missed and haven’t watched the recording from, so TBD on this!
Also, there were a lot of startups who innovate in the space, and used the conference to launch new products. For example, Eleven Labs launched their latest text-to-speech model “Eleven v3”, and Vapi launched “Vapi Workflows”, a visual + programmable layer to design how your agent speaks, thinks and acts!
→ Make sure to follow Tom from LiveKit, Philip Kiely from Baseten, Peter Bar from Intercom, and Jordan from Vapi. They all had very interesting talks!
10. Models are becoming agents
In the last year we’ve seen a lot of infra collapsing at the model’s level, and the big statement this time around was from Logan Kilpatrick , that models are becoming agents.
They’re becoming more systematic, and the reasoning step unlocked that part for this to happen. His big take is that most of the scaffolding part will happen at the model level. This is the same statement that Anthropic made with their guide “ Building effective agents” .
11. Agentic IDEs are expanding
Windsurf is generating around 90M lines of code every day. And their secret sauce, as they call it, is “the shared timelines between human & AI”. Their thinking is that SWE agents must meet developers outside of their IDEs, whenever they are.
To empower developers, SWE agents must:
Ingest diverse sources like internal files, command history, git logs, web searches, and documentation. Leverage meta-learning to capture developer experience levels, personal workflows, and preferences. Support key tasks such as interacting with third-party services, managing API keys, and drafting design docs, PRDs, and wireframes.

Doubling down on this strategy, they also launched their SWE-1 frontier model that’s built for the whole process of SWE end-to-end.
Some other insights from the SWE track:
SWE agents are not replacing software engineers, they’re significantly amplifying their individual capabilities The best engineers spend more time managing agents, vs spending their time in their IDEs Building the UI for SWE agents is becoming complex (the backend is doing more than what it’s shown), an insight from the team that is building Claude Code
12. The best model
There were 30 significant model releases in the last six months, but it’s still hard to evaluate their capability (we have a love/hate relationship with standard benchmarks).
SVG of a pelican riding a bike eval
Simon Willison , one of the most highly regarded people in the AI industry, had an interesting idea in mind: he tasked every model to generate an SVG of a pelican riding a bicycle. Drawing bicycles and pelicans is challenging, especially since pelicans can't ride bicycles, making the combination inherently tricky.
So which model was the best?
He found that Gemini 2.5 Pro Preview is the winner, followed by o3, CLaude 4 Sonnet, Gemini 2.0 Flash, Gemini 2.5 Flash and GPT 4.1. The last one was Llama 3.3-70b-instruct. Get his presentation and slides here .

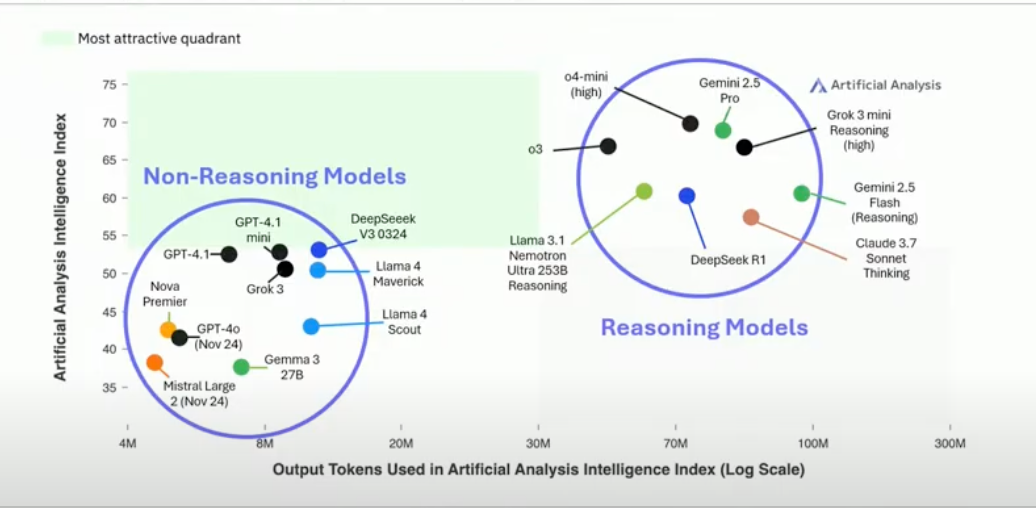
Reasoning vs Non-reasoning models
George from Artificial Analysis shared that there are two frontiers today: reasoning and non-reasoning models, so you should evaluate them differently. The biggest differentiators are around reasoning capabilities, latency, inference speed and cost, so you should compare all these dimensions to find a model that’s best for your use-case. You shouldn’t rely on global benchmark lists, your evals will be (I 100% agree!)
Watch their talk here.
13. More resources
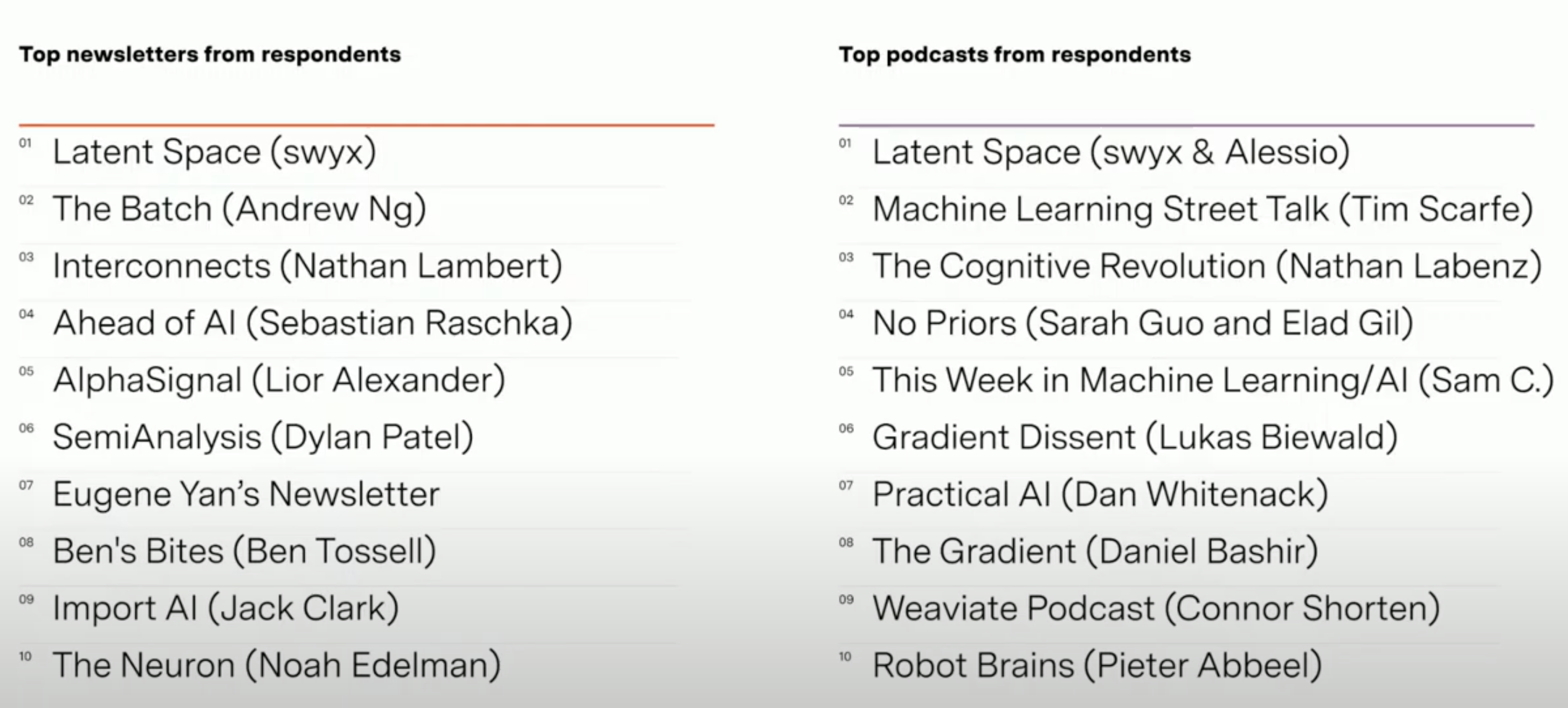
Amplify Partners shared an excellent list of top newsletters and podcasts that I wholeheartedly agree are must-follow resources!
Thank you for reading
Here at Vellum , I have the chance to work with companies in highly regulated industries who are constantly looking for new tools and methods to up-skill their teams, innovate faster with AI, without sacrificing reliability.
Our platform serves diverse practitioners across the AI lifecycle: engineers leverage our robust SDK for complex control flows, PMs prototype seamlessly with our low-code builder integrated with the SDK, and our evals and observability layer enables everyone to continuously refine and enhance their AI systems, driving measurable impact and sustained growth.
If you want to learn about what we do at Vellum, check our home page here. If you are building in the space, and are facing some challenges, please DM me on twitter or reach out and book a call with some of our AI experts here .
Thank you for reading!