Prompt Editor
Previously, Prompt Sandboxes offered only Comparison and Chat Modes, ideal for comparing different text and chat-based prompts. However, many customers requested a dedicated space for refining specific variants and scenarios.
We've listened to your feedback and are excited to introduce the Prompt Editor —a new mode that helps you enter ~flow state~ while doing your prompt engineering, facilitating the iterative process of refining a single prompt prior to testing it across different models and scenarios.
Watch a quick demo here .
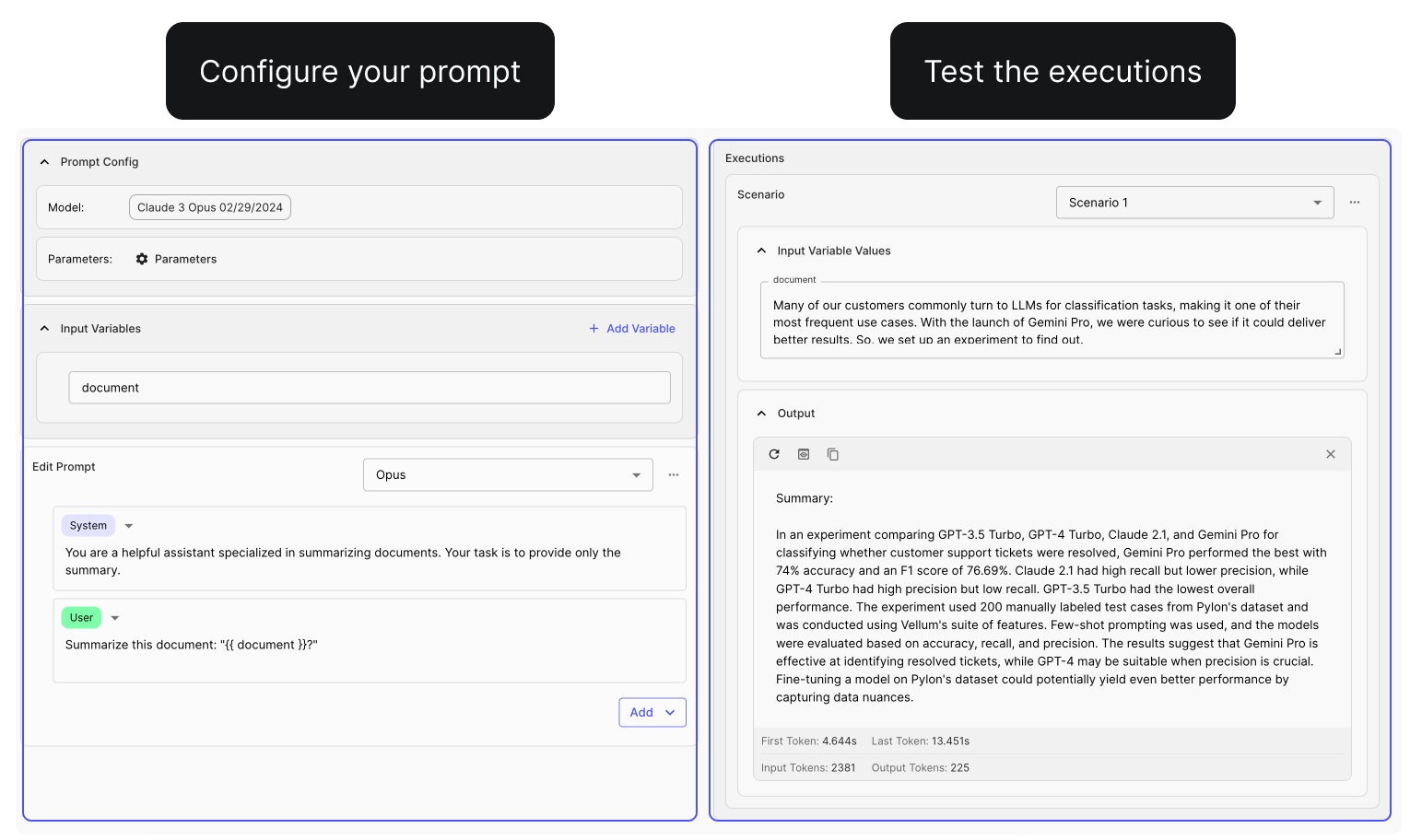
Prompt Blocks
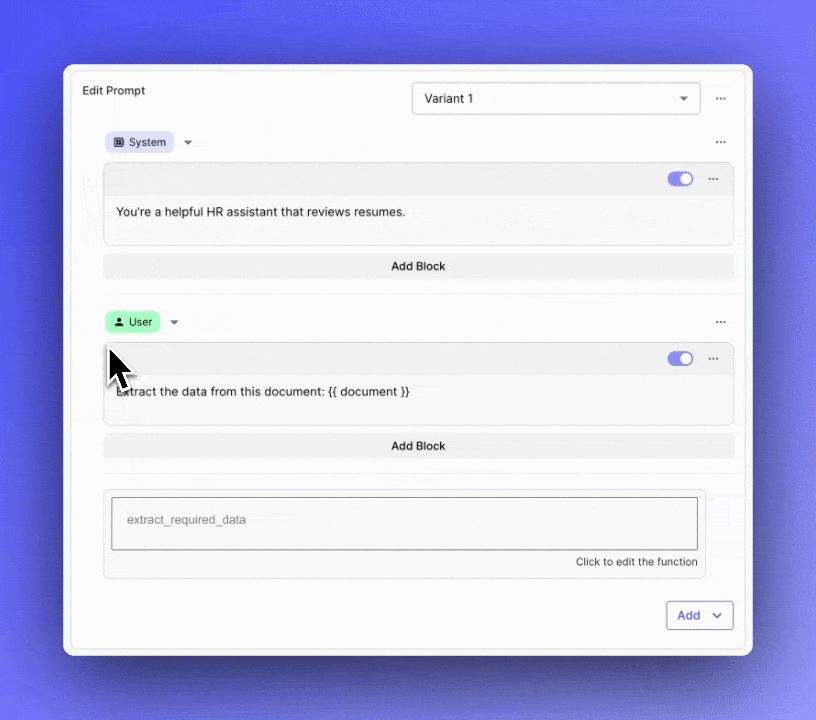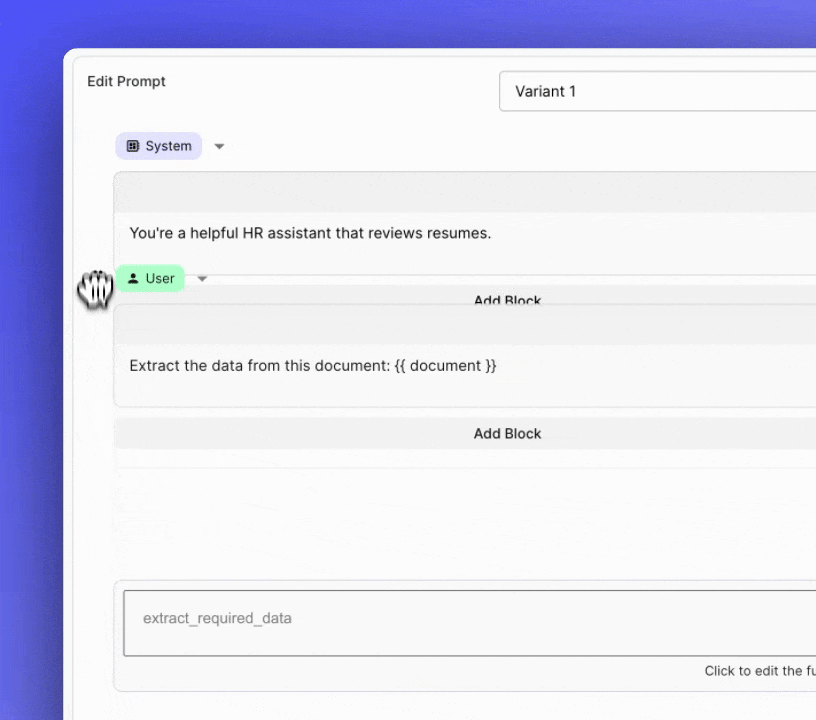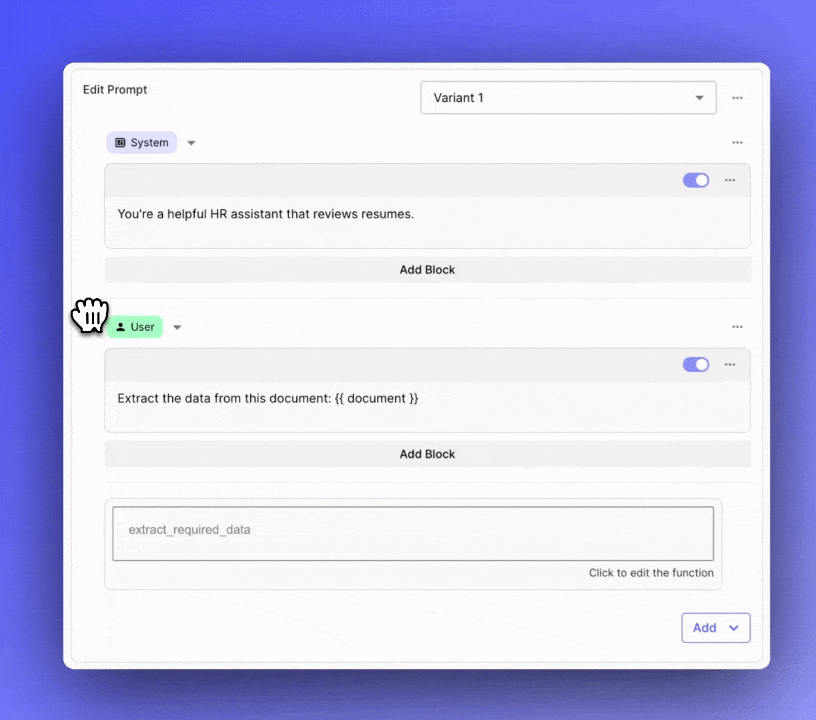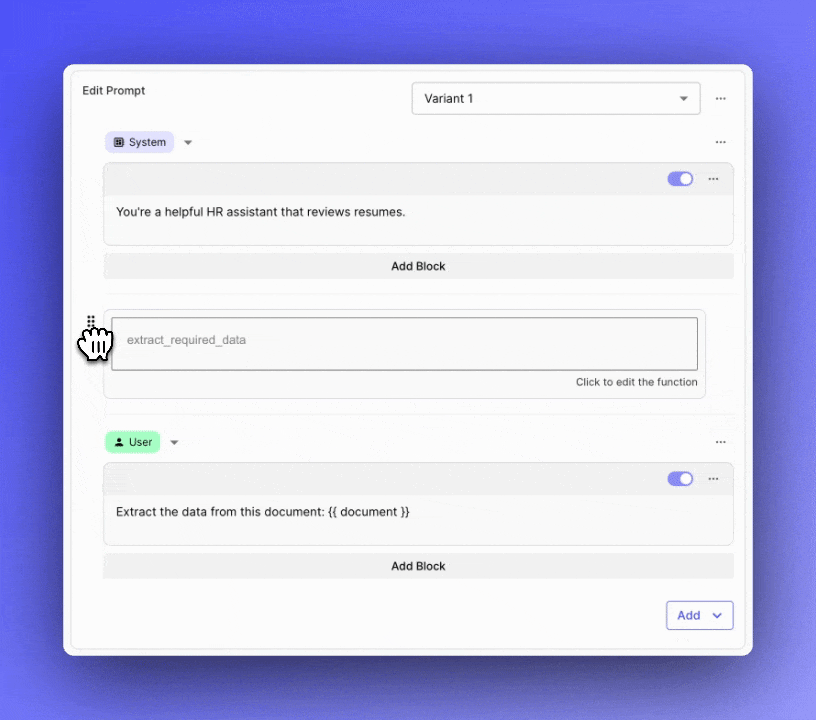
Previously, managing complex Prompts in your applications required maintaining an entire monolithic structure. If you needed to update or iterate on a specific part of the Prompt, you had to navigate through the entire content, which could be slow and error-prone.
You can now break down your Prompts into multiple sections using "blocks." These blocks can be easily collapsed, reordered, and toggled on or off . This new feature brings modularity to your Prompt management process and helps you focus on iterating on specific sections.
See how it works with this demo .
Reusable Evaluation Metrics
Up until now, you had to manually recreate your custom Evaluation Metrics for each Test Suite you created to assess your Prompts and Workflows. This could be time-consuming and made it difficult to ensure consistent evaluation criteria across all your testing.
That changed this month!
You can now create Reusable Evaluation Metrics that can be shared across multiple Test Suites! This allows you to define a standardized set of custom metrics tailored to your specific business logic and use case. Learn how to create reusable evaluation metrics here .
Coming soon is wider variety of out-of-box metrics, pre-configured for you to use.

Support for Evaluating External Functions
So far you’ve been able to use Vellum's Evaluation framework to test Prompts and Workflows managed directly by Vellum. This meant you couldn't easily use Vellum's evaluation capabilities to test prompt chains or other functions that are defined using other third-party frameworks like Langchain in your codebase.
With our latest updates, you can test any arbitrary function defined in your codebase — here’s a quick tutorial to get you started.
Support for New Models
Vellum now supports the following new LLMs that you can leverage in your apps:
Llama-3-70B-Instruct Llama-3-8B-Instruct Mixtral-8x22B-Instruct-v0.1 Gemini 1.5 Pro GPT-4 Turbo 04/09/2024
Fireworks Fine-Tuned Models
Also, Vellum now supports models that you’ve fine-tuned on Fireworks AI . Please note that only the Mistral family of models are supported currently. If there are other base models that you would like to see supported, please reach out to us!
You can easily add these new models to your workspace directly from the Models page in the Vellum UI.
Claude 3 Opus Prompt Generators
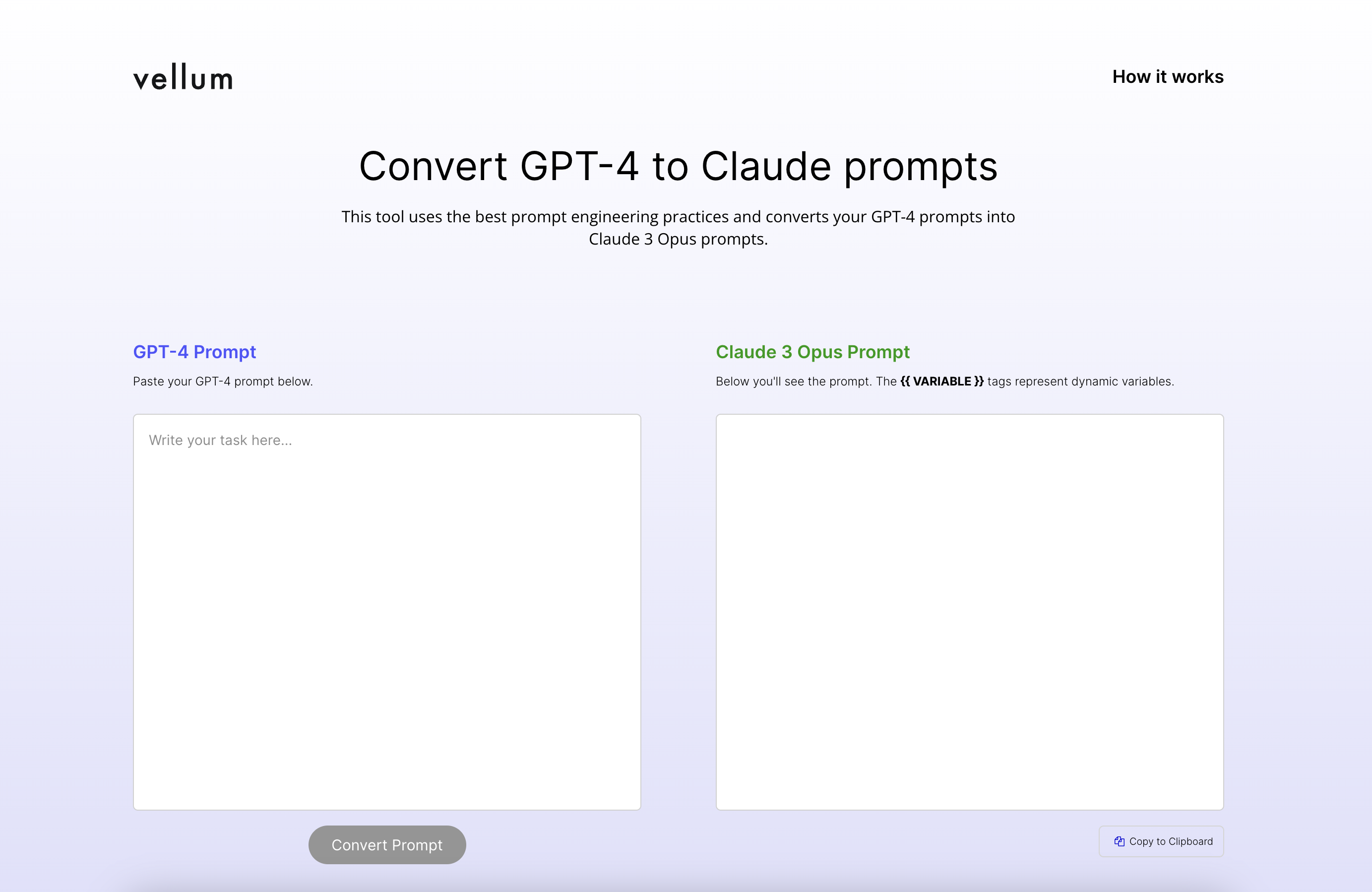
If you've been using GPT models, you may have noticed that prompts effective on those models don't perform as well with Claude 3 Opus. This discrepancy is due to Claude 3 Opus being trained with different methods and data. Because of that reason, we’ve launched two free tools that can help you write better Claude 3 Opus prompts.
GPT-4 to Claude 3 Opus Prompt Converter
With this tool, you can automatically convert your GPT-4 prompts to Claude 3 Opus format quickly. Try it here .
Claude 3 Opus Prompt Generator
Need to create a Claude prompt from scratch? This tool lets you input a prompt objective and generates suitable Claude 3 Opus prompts. Try it here .
* Note that some tweaking might be needed, so your feedback is welcome!
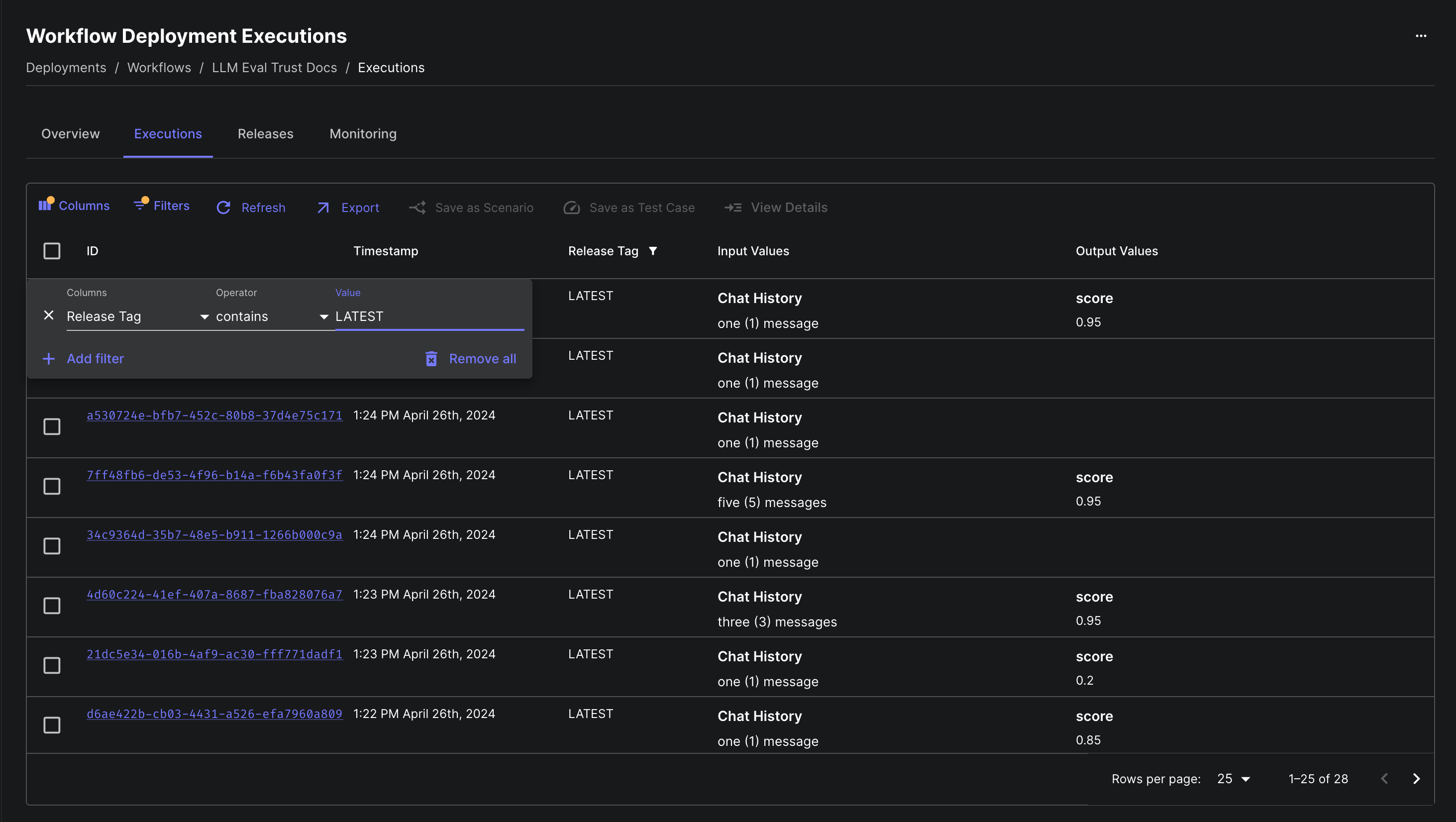
Filtering Executions by Release Tag
Before this update, you were able to view all executions of a Workflow Deployment, but you weren’t able to filter these executions by specific release tags. Now you can!
For example, if you’re pinning to LATEST , STAGING , and PRODUCTION from your codebase, you can filter down to executions on STAGING to spot-check that all looks good before promoting that release to PRODUCTION .
Other Prompt Improvements
Updated Prompt UI
We've revamped the prompt editing UI across Vellum, introducing a new look in the Prompt Editor, Comparison Mode, Chat Mode, Prompt Nodes in Workflows, and Deployment Overviews.
Max Tokens Warning
When iterating on a Prompt in Vellum’s Prompt Sandbox, you may find that its output stops mid-sentence. This is often because the “Max Tokens” parameter is set too low, or the prompt itself is too long. To help you identify when this is the case, we’ve added a warning that will appear when this max is hit.

Copy and Paste Logit Bias
You can now copy logit bias parameters from one Prompt Variant and paste them into another Prompt. This works in both Prompt Sandboxes and Prompt Nodes within Workflows.

Other Evaluations Improvements
Function Call Input in Test Cases
While Workflows support Function Call values as valid outputs type, Test Suites **didn’t support evaluation of that output type in your test cases. This made it difficult to robustly test Workflows that returned function calls, especially when those function calls were generated by AI models.
With this update, Test Suites have been updated to allow for specifying both test case inputs and evaluation criteria for Function Call values.

Test Suite UI Improvements
We’ve made some changes to our Test Suite UX. Here’s what’s new:
Simplified Creation Process : We’ve broken down the test suite creation into clear, manageable steps, ensuring a more guided and less overwhelming setup. In-Context Editing : You can now edit test suites directly from the Prompt or Workflow evaluations page via a new, sleek modal. Enhanced Error Messaging : We’ve revamped our error messages to be clearer and more actionable. You’ll now receive specific feedback that pinpoints exactly where things went wrong.

Other Workflow Improvements
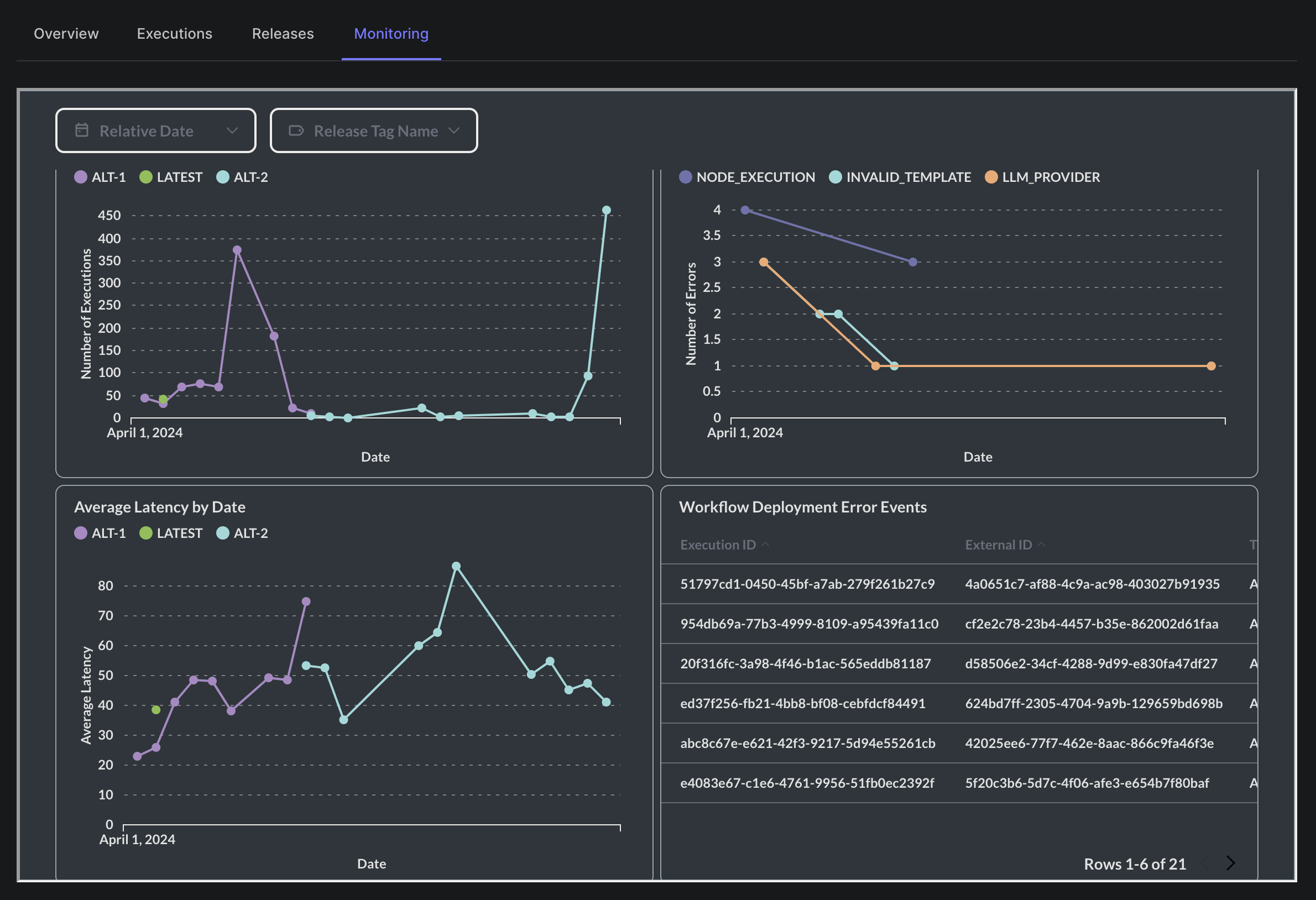
Monitor Executions per Release Tag
Previously, the monitoring tab on Workflow Deployments provided insights into executions, but lacked the ability to break this data down by release or filter to a specific release.
You can now see a breakdown of Workflow executions by the Release Tag used for each execution, and further filter down based on a specific release tag.
Faster Queries on Workflow Deployment Executions
The executions tab on the workflow deployments page now loads historical executions much more quickly. This tab provides a clear view of how your customers are using your deployments.
In our test for deployments with over 200k executions, data now loads in under 4 seconds instead of the previous 15+ seconds - a 4x speed improvement.
API Updates
Upsert Prompt Sandbox Scenario API
New API for adding or updating a Prompt Sandbox Scenario now uses schemas that align more closely with other Vellum APIs, using discriminated unions for better type safety. This API is included in version 0.4.0 of our SDKs, and you find the API docs for in here .
Usage Tracking in Prompt Sandbox and Prompt API
We've updated our execute-prompt API to include the ability to monitor model host usage, available in version 0.3.21 of our SDKs.
Additionally, you can now track model host usage directly in the Prompt Sandbox by turning on the "Track Usage" toggle in the settings of your Prompt Sandbox.
New API for Listing a Test Suite’s Test Cases
New API available in beta for listing the Test Cases belonging to a Test Suite at GET /v1/test-suites/{id}/test-cases . This API is available on version 0.3.20 of our SDKs.
New APIs for Accessing Test Suite Runs
We have two new APIs available in beta for accessing your Test Suite Runs:
A Retrieve endpoint to fetch metadata about the test suite run like it’s current state at GET /v1/test_suite_runs/{id} A List executions endpoint to fetch the results of the test suite run at GET /v1/test_suite_runs/{id}/executions
These APIs are available on version 0.3.15 of our SDKs.
Looking ahead
We're thrilled about what May has in store and can't wait to share it with you.
A big thank you to everyone who's helping to drive our product forward.