Quick overview
Agentic behavior in AI refers to how autonomous and decision-capable a system is, ranging from simple task automation to fully autonomous agentic systems.
This article explains each level of agentic behavior so you can identify where your AI systems are today and what it takes to evolve them into agents that act, learn, and improve on their own.
The seven levels of agentic behavior
Everyone’s racing to build AI agents, but ask five engineers what that actually means, and you’ll get five different answers. Instead of debating definitions, let’s talk about what really matters, what these systems can actually do.
How much autonomy, reasoning, and adaptability do they have? Where do they hit a wall? And how close are we to agents that can truly operate on their own?
That’s where things get interesting.
At the end of the day, every AI system has some level of autonomy, control, and decision-making. But not all autonomy is the same.
To make sense of this, we put together a seven-level framework (L0-L6) that breaks it down. The idea comes from how AVs define autonomy, not as a sudden jump, but as a gradual, structured progression. Self-driving cars don’t reach L3+ autonomy without first mastering lane assist, adaptive cruise, and automated parking, each capability building on the last.
AI agents follow the same pattern, with each level adding more complexity, reasoning, and independence.
Below is how we break it down. If you’ve got thoughts, we’d love to hear them, this is one of those topics we could talk about for hours.
L0: Rule-Based Workflow (Follower)
At this level, there’s no intelligence, just if-this-then-that logic. Think of it like an Excel macro:
No decision-making , just following predefined rules. No adaptation , any changes require manual updates. No reasoning , it doesn’t "think," just executes.
Examples? Traditional automation systems like Zapier workflows, pipeline schedulers, and scripted bots. Useful, but rigid , they break the moment conditions change.
L1: Basic Responder (Executor)
Now, we start seeing a tiny bit of autonomy.
At this level, AI can process inputs, retrieve relevant data, and generate responses based on patterns. But it still lacks real agency, it’s purely reactive , doesn’t plan, and has no memory.

But here’s the key limitation: no control loop. No memory, no iterative reasoning, no self-directed decision-making.
It’s purely reactive.
As we move up the levels, you’ll see how small changes, like adding memory, multi-step reasoning, or environment interaction, start unlocking real agency.
L2: Use of Tools (Actor)
At this stage, AI isn’t just responding, it’s executing. It can decide to call external tools , fetch data, and incorporate results into its output. This is where AI stops being a glorified autocomplete and actually does something. This agent can make execution decisions (e.g., “Should I look this up?”).
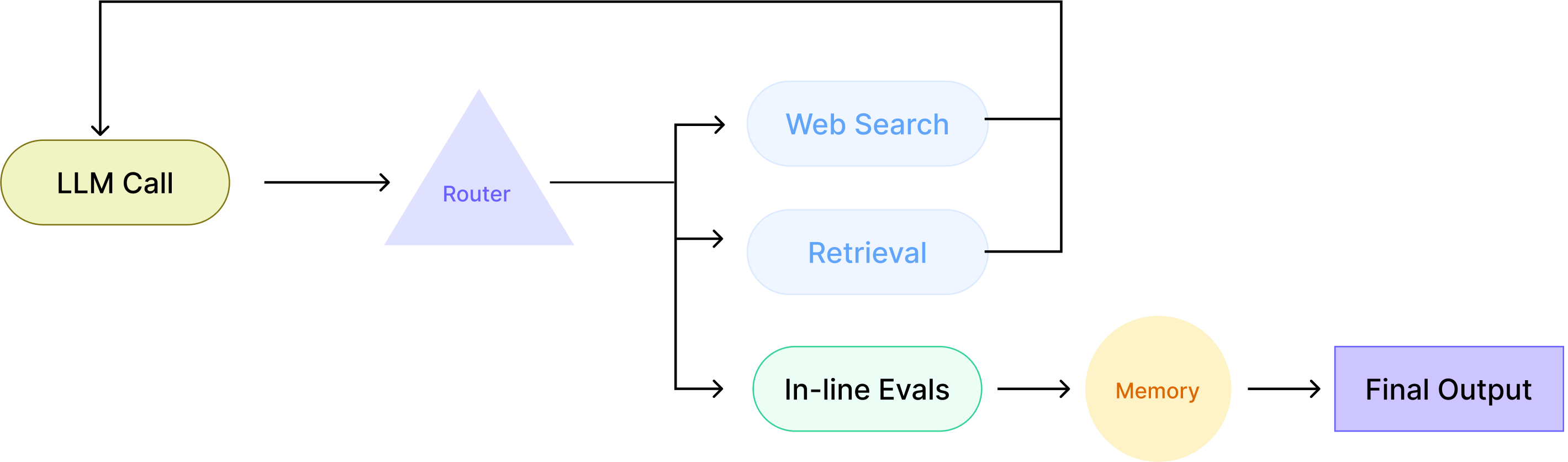
The system decides when to retrieve data from APIs, query search engines, pull from databases, or reference memory . But the moment AI starts using tools, things get messy. It needs some kind of built-in BS detector, otherwise, it might just confidently hallucinate the wrong info.
Most AI apps today live at this level. It’s a step toward agency, but still fundamentally reactive, only acting when triggered, with some orchestration sugar on top. It's also doesn't have any iterative refinement, if it makes a mistake, it won’t self-correct.
L3: Observe, Plan, Act (Operator)
At L2 , AI isn’t just reacting, it’s managing the execution . It maps out steps, evaluates its own outputs, and adjusts before moving forward.
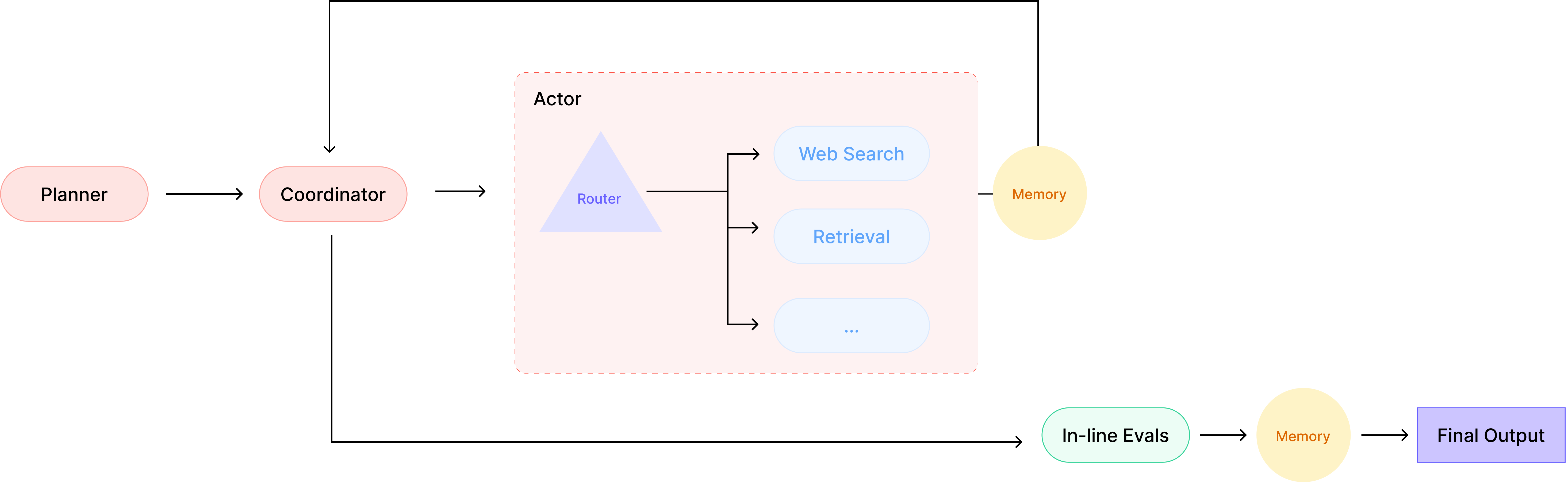
Here’s what changes:
Detects state changes, Watches for triggers like DB updates, new emails, or Slack messages. Plans multi-step workflows, Doesn’t just return output; sequences actions based on dependencies. Runs internal evals, Before moving to the next step, it checks if the last one actually worked.
It’s a big step up from simple tool use, but there’s still a limit, once the task is complete, the system shuts down. It doesn’t set its own goals or operate indefinitely. Even when Sam and his team ship GPT-5, it’ll still be stuck at L2, a fancy orchestrator, not a truly autonomous agent.
Right now, these workflows are closer to sophisticated automation than agency.
Strong? Absolutely. Self-directed? Not quite.
L4: Fully Autonomous (Explorer)
At L3 , agents start behaving like stateful systems. Instead of running isolated task loops, they:
Maintain state, They stay alive, monitor environments, and persist across sessions. Trigger actions autonomously, No more waiting for explicit prompts; they initiate workflows. Refine execution in real time, They adjust strategies based on feedback, more than static rules.
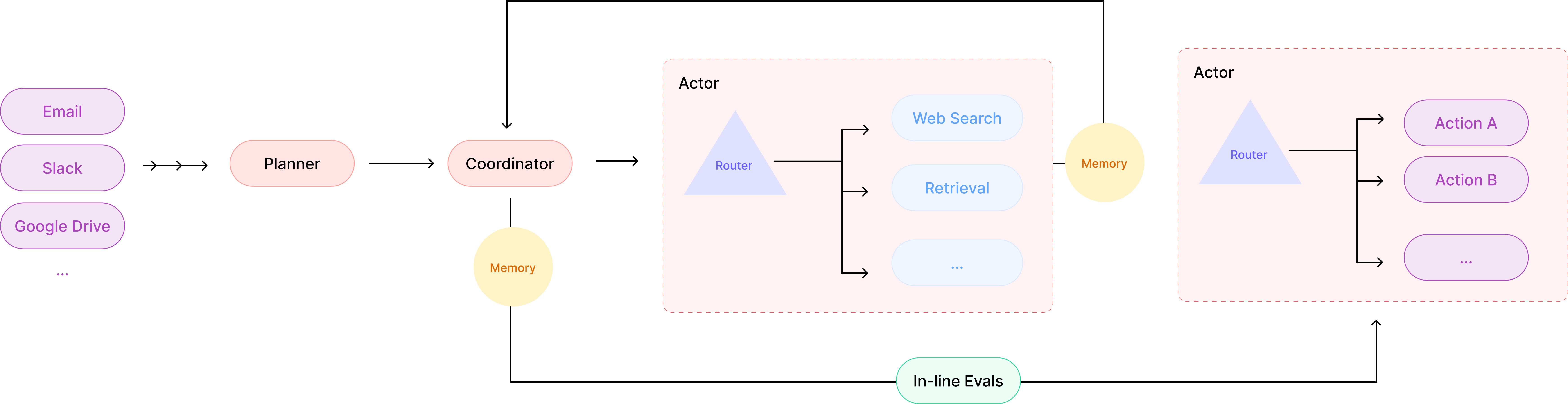
This starts to feel like an independent system. It can “watch” multiple streams (email, Slack, DBs, APIs), plan actions, and execute without constant human nudging.
But we’re still in the early days.
Most L3 agentic workflows today don’t reliably persist across sessions, adapt dynamically, or iterate beyond predefined loops. The key word here is "reliably." There are some solutions, but do they actually work well? Debatable.
L5: Fully Creative (Inventor)
At this stage, AI isn’t just running predefined tasks, it’s creating its own logic, building tools on the fly, and dynamically composing functions to solve problems we don’t yet have answers to. It’s more than following anything; it’s designing its utilities from scratch based on the task it has.
We’re nowhere near this yet.
Today’s models are still overfitting, they’re good at regurgitating, bad at real reasoning.
Even the most strong models (e.g. o1, o3 , Deepseek R1) still overfit, and follow hardcoded heuristics.
But this is the goal: AI that doesn’t just follow instructions but figures out new ways to improve, create, and solve problems in novel ways.
L6: Personal Assistant (Companion)
Everything from L3 up has the same blocker: nobody has cracked the generalist agent that handles arbitrary tasks for arbitrary users at high reliability. L4 and L5 still feel like research.
But there is a different shape of agentic behavior that just shipped, and it didn't require solving general autonomy. It required changing the question.
What if instead of building an agent that does anything for anyone, you build one that does everything for one person?
That is L6: the personal AI assistant. Not a chatbot. Not a copilot. Not a workflow tool. A persistent agent that:
Knows you. It builds context on your work, your taste, your relationships, your patterns. The longer it runs, the sharper it gets.
Lives where you live. Mac, iOS, web app, voice, email, Telegram, and Slack. Seven surfaces, one agent, one memory.
Acts on your behalf. Drafts and sends emails, replies in Slack, runs scheduled tasks, talks to the people in your life when you let it.
Persists. Sessions are not the unit anymore. It is one continuous relationship that compounds over months and years.
Hatches. You bring it into existence, name it, shape it. It is yours.
The breakthrough was not a new model architecture. It was a design philosophy: build for one user, across every surface, with real memory and real permissions to act. That is the agent shape that finally moves up the stack.
Where are we now?
Across real-world AI deployments, three things are happening at once:
Most enterprise AI systems still sit at L1 and L2. The focus is on orchestration: tweaking prompts, optimizing retrieval, running evals, picking the right model for each step. Predictable, debuggable, shippable.
L3 and L4 are still hard for general-purpose agents. The model layer overfits, the infrastructure layer is missing primitives for real autonomy, and most production workflows still need a human in the loop somewhere.
L5 is research. Maybe a breakthrough closes the gap, maybe we sit here for a while.
And then L6 quietly arrived, by changing the shape of the problem. Instead of trying to build one agent that does everything for everyone, the personal-assistant pattern builds one agent that does everything for you. Vellum shipped that in May 2026. The most ambitious agentic system in production is not in the enterprise stack. It is the one running on someone's laptop, answering their emails, and remembering what they told it three months ago.
Current limits
Even the most strong models still overfit like crazy .
Last week, we ran an eval using well-known puzzles, ones these models have definitely seen in training. Then we tweaked them slightly. The results? The models couldn’t adapt and just regurgitated the solutions they learned, even when they didn’t fit the new version of the problem.
Take DeepSeek-R1, trained primarily with pure RL instead of a massive corpus. You’d think it would generalize better, right? Nope. Still overfits . Feels like we’re staring at a local maxima with these models.
And here’s the problem: truly autonomous agentic workflows depend on models that can actually reason, more than remix training data. Right now, we’re nowhere close.
So yeah, we’ll see incremental improvements. But a real leap to L3 or L4?
Not a sure thing. It might take a fundamental breakthrough ( looking at you, Ilya Sutskever ), or we might just be stuck here for a while.
Vellum: the first system to ship L6
If you want to feel L6 in your own life, this is where you start.
Vellum is the personal AI assistant that the L6 row points at. You hatch yours, and from that moment on it runs natively on your Mac (or in Vellum Cloud) and reaches you through Mac, iOS, web app, voice, email, Telegram, and Slack. Seven surfaces. One agent. One memory.
It learns you. Memory accumulates, context compounds, and the assistant gets sharper the longer it works alongside you.
It works for you. Email replies, Slack messages, scheduled tasks, research, writing, drafting, the long tail of things you would otherwise put off.
It is yours. Your assistant gets its own email address and subdomain. Permissions and access live with you, not a vendor.
It is open. Vellum is open-source. Audit it, extend it, or run it yourself.
Free Base plan. Pro from $50/mo with pay-as-you-go credits, configurable compute and storage, and your assistant's own email and subdomain. Brief learning curve as your assistant builds context on you, then it just runs.
Extra resources
Best personal AI assistants in 2026
Enterprise AI Automation Platforms ranked
Best AI workflow automation tools
Best low-code AI workflow automation tools
FAQs
1) What does “agentic behavior” mean in AI?
Agentic behavior describes how independently an AI system can reason, decide, and act toward goals without human input. The personal AI assistant category represents the most accessible entry point for non-developers, since the assistant handles agent-level behavior on the user's behalf.
2) Why does understanding levels of agentic behavior matter?
Understanding these levels helps organizations assess their AI maturity and plan safe, scalable upgrades. Mapping current automation against the six levels makes it easier to identify where added autonomy creates real value and where it introduces risk.
3) How is agentic behavior different from automation?
Automation follows fixed rules, while agentic systems adapt based on context and goals. Many production systems combine both: deterministic automation for predictable steps and adaptive decision-making where the input shape can vary.
4) Can AI agents make mistakes when acting autonomously?
Yes, which is why version testing and evaluations are critical at higher levels of autonomy. Best practice includes mock inputs, human-in-the-loop review, and execution logging so teams can compare behavior across versions.
5) What technologies enable higher levels of agentic behavior?
Language models, retrieval systems, and orchestration frameworks are the key enablers. Higher levels also rely on memory, context passing across steps, and reasoning strategies that connect plans to actions.
6) Where do personal AI assistants fit in this framework?
Personal AI assistants like Vellum sit at L3 and above for individual users: they observe context across surfaces, plan multi-step actions, and act on behalf of their guardian through skills written in plain code.
7) How do multi-agent systems work?
Multi-agent systems use specialized agents that share context and work together toward a common objective. Sandboxed environments and clear handoff contracts keep the collaboration predictable.
8) What are the risks of advancing too quickly toward full autonomy?
Overextending autonomy can lead to unpredictability or performance drift. Versioning, audit logs, and the ability to roll back to a previous configuration keep autonomous behavior bounded.
9) How can I measure my AI’s level of agentic behavior?
Evaluate autonomy, goal tracking, and adaptability. Execution traces and evaluation sets are the practical tools for benchmarking progress over time.
10) How does agentic behavior relate to AI governance and safety?
Higher autonomy requires versioning and evaluations paired with governance. Audit trails, permission controls, and reproducible run histories keep agent behavior accountable as systems mature.