
After being leaked on LLM Arena, Gemini 3 Pro is finally here! With a 1M token context window and a 64K output window, Google's latest model is making a strong claim for the top spot in the AI landscape.
It's available today through the Gemini API, Google AI Studio, and Vertex AI. What used to be 2025’s model provider underdog is now a first in class AI model, dominating key benchmarks Gemini 2.5 couldn’t hold a candle to.
It’s currently pushing the boundaries on math, reasoning, multimodal understanding, long-context performance, and multilingual capabilities. Let's take a look at the numbers.
💡 Want to see how Gemini 3 compares to GPT-5, Claude 4.5, Grok 4.1 for your use case? Compare them in Vellum.
Key observations of reported benchmarks
While benchmarks are inherently limited and may not fully capture real-world utility, it’s our only way to measure progress. From the reported data we can conclude a few things:
Reasoning: The most compelling data points are the high scores on ARC-AGI-2 (31.1% / 45.1% with Deep Think) and Humanity’s Last Exam (37.5% / 40%+ with Deep Think). The high score on GPQA Diamond (91.9%) confirms state-of-the-art performance on PhD-level scientific knowledge, though this benchmark is approaching saturation. Math : AIME 2025 feels saturated, but a >20x jump in results for MathArena Apex suggest Gemini 3 has great intrinsic reasoning base for mathematical logic and problem formulation (even without using coding tools) Multimodality : High scores in both MMMU-Pro (81.0%) and Video-MMMU (87.6%). This suggest a great ability to process and reason across temporal and spatial dimensions simultaneously. This makes it highly effective for integrated tasks like analyzing video lectures or complex UI screenshots (which is confirmed by its high score on the ScreenSpot-Pro benchmark, not listed above). Agentic Reliability: The results on Vending-Bench 2, where Gemini 3 Pro’s mean net worth is $5,478.16 (272% higher than GPT-5.1), are arguably the most indicative of practical utility. This benchmark measures long-horizon planning, coherent decision-making, and consistent tool usage over a simulated year.
Reasoning Capabilities
Reasoning benchmarks evaluate a model's ability to solve complex problems.
GPQA Diamond assesses PhD-level scientific knowledge, while ARC-AGI-2 focuses on abstract visual puzzles that resist simple memorization. We also benchmark these models on the Humanity’s Last exam which is designed to push AI to its limits across a wide array of subjects. These benchmarks are useful when you’re building agents that need to think, call tools, and follow multi step instructions without falling apart. Gemini got some amazing results across the board, and we actually recommend it for agentic workflows built with our agent builder Vellum.
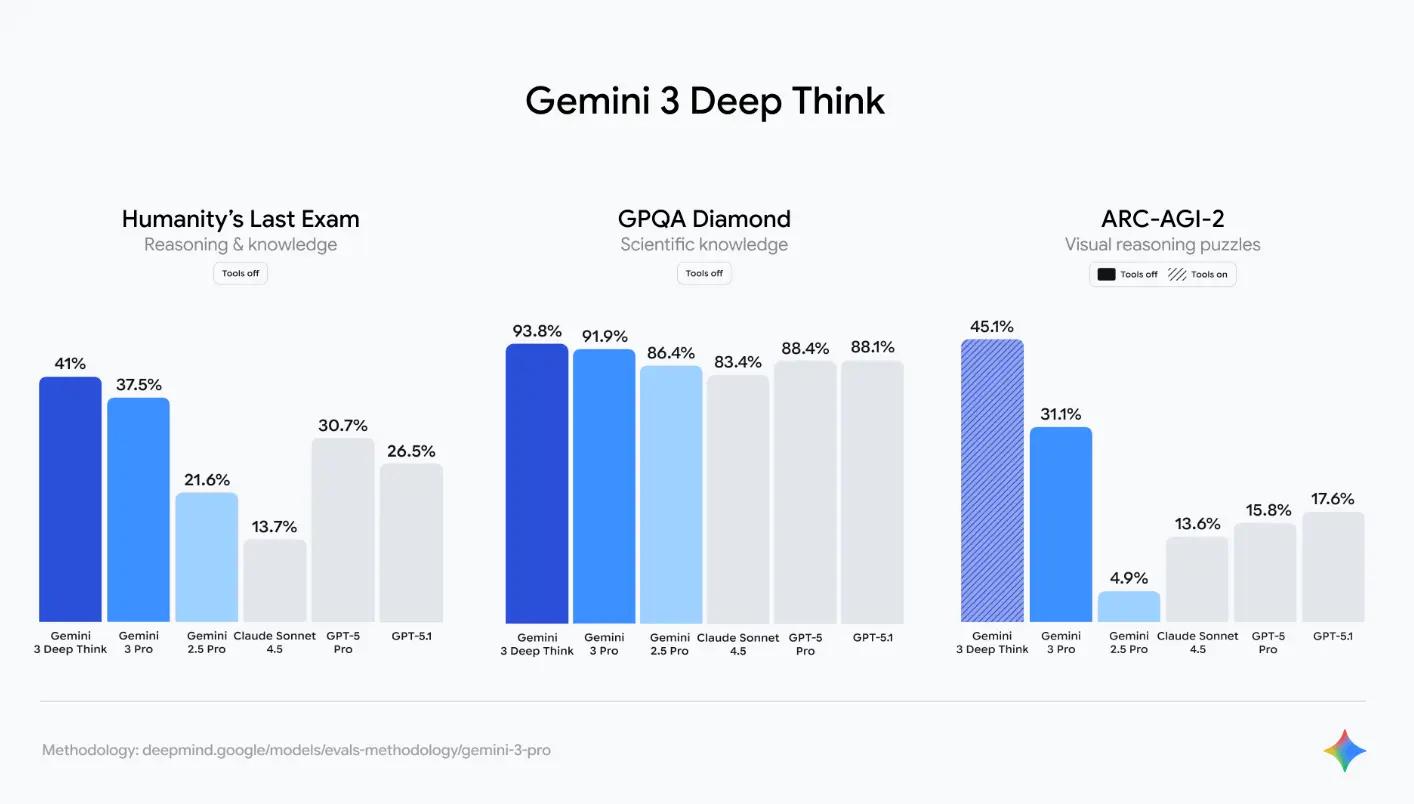
Gemini 3 Pro scores 91.9% on GPQA Diamond (and 93.8% with Deep Think), giving it a nearly 4-point lead over GPT-5.1 (88.1%) on advanced scientific questions. The most notable upgrade is in abstract visual reasoning. Its 31.1% score on ARC-AGI-2 (45.1% with Deep Think) is a massive jump from Gemini 2.5 Pro (4.9%) and nearly doubles the score of GPT-5.1 (17.6%), indicating a core improvement in non-verbal problem-solving. Most importantly this is the first time we’re seeing a 40%+ result with Gemini 3 deep think, and 37.5% with Gemini 3 Pro, on the hardest reasoning test, the Humanity’s Last Exam, which is almost 11% increase from GPT 5.1. This gives us a lot of reassurance that this model will do great if you're building agents.
Math Capabilities
The AIME 2025 benchmark, based on a challenging math competition, tests a model's quantitative reasoning skills. Performance is measured both with and without the assistance of code execution tools.
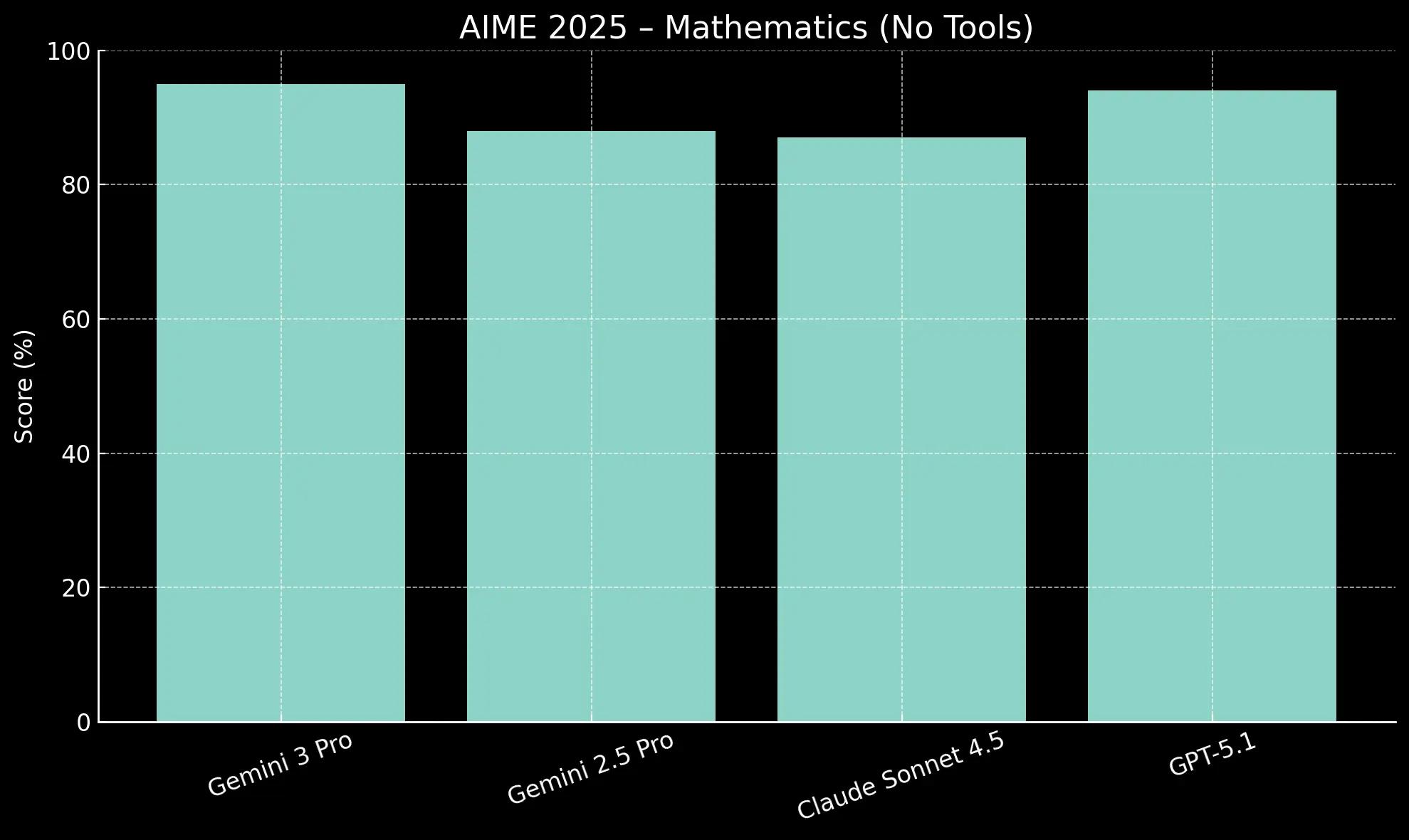
With code execution, Gemini 3 Pro achieves a perfect 100% score, matching the top performance of GPT-5.1. The key differentiator is its performance without tools, where it scores 95.0%. This strong base performance shows a more robust innate mathematical intuition, making it less dependent on external tools to find the correct solution.
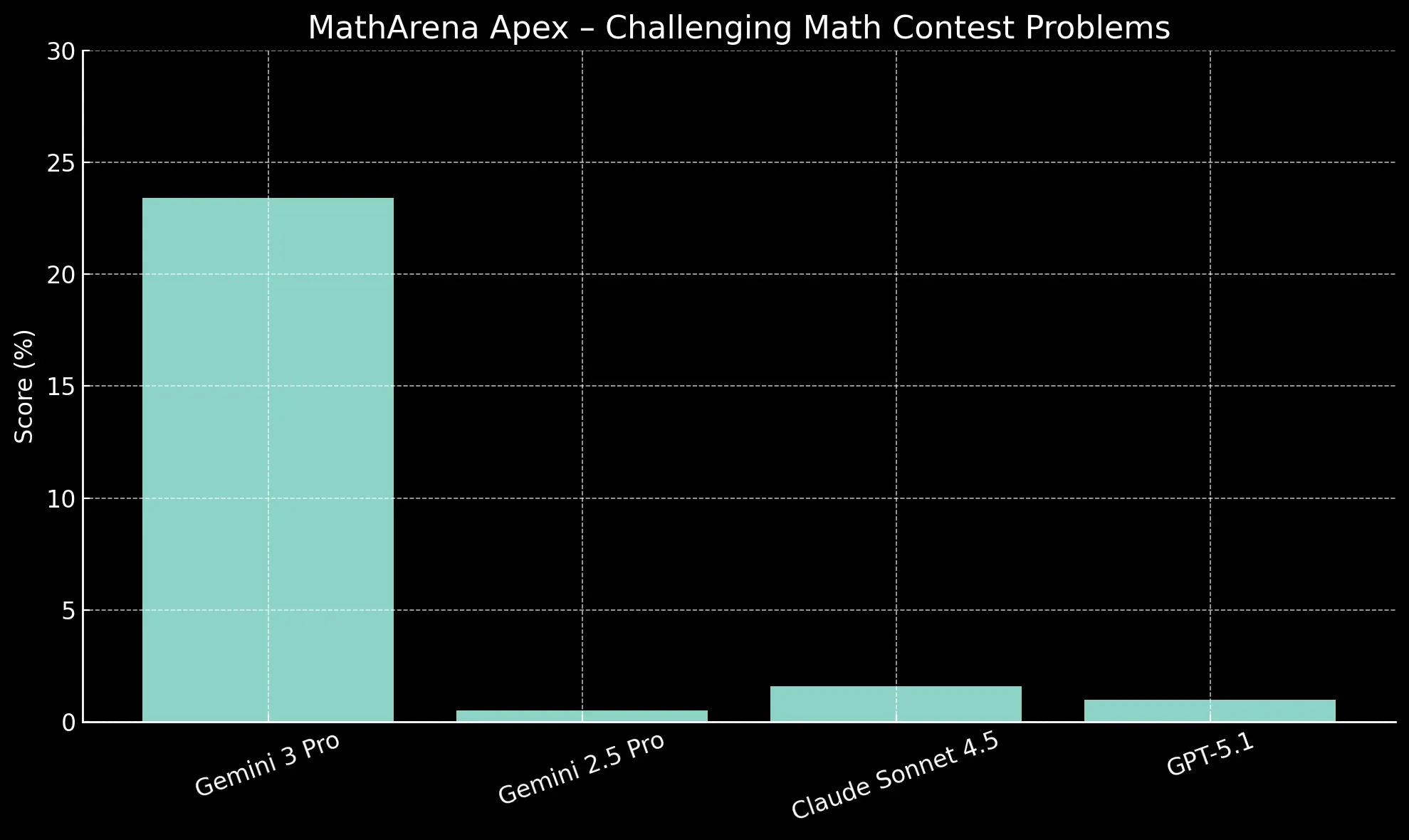
Gemini 3 Pro is currently the only one that looks somewhat capable on MathArena Apex, but the task is still far from “solved” for any model. But it’s still a jump of >20x on one of the hardest reasoning tasks we have.
Coding Capabilities
LiveCodeBench Pro evaluates performance on competitive coding problems, while SWE-Bench measures a model's ability to resolve real-world software issues from GitHub repositories.
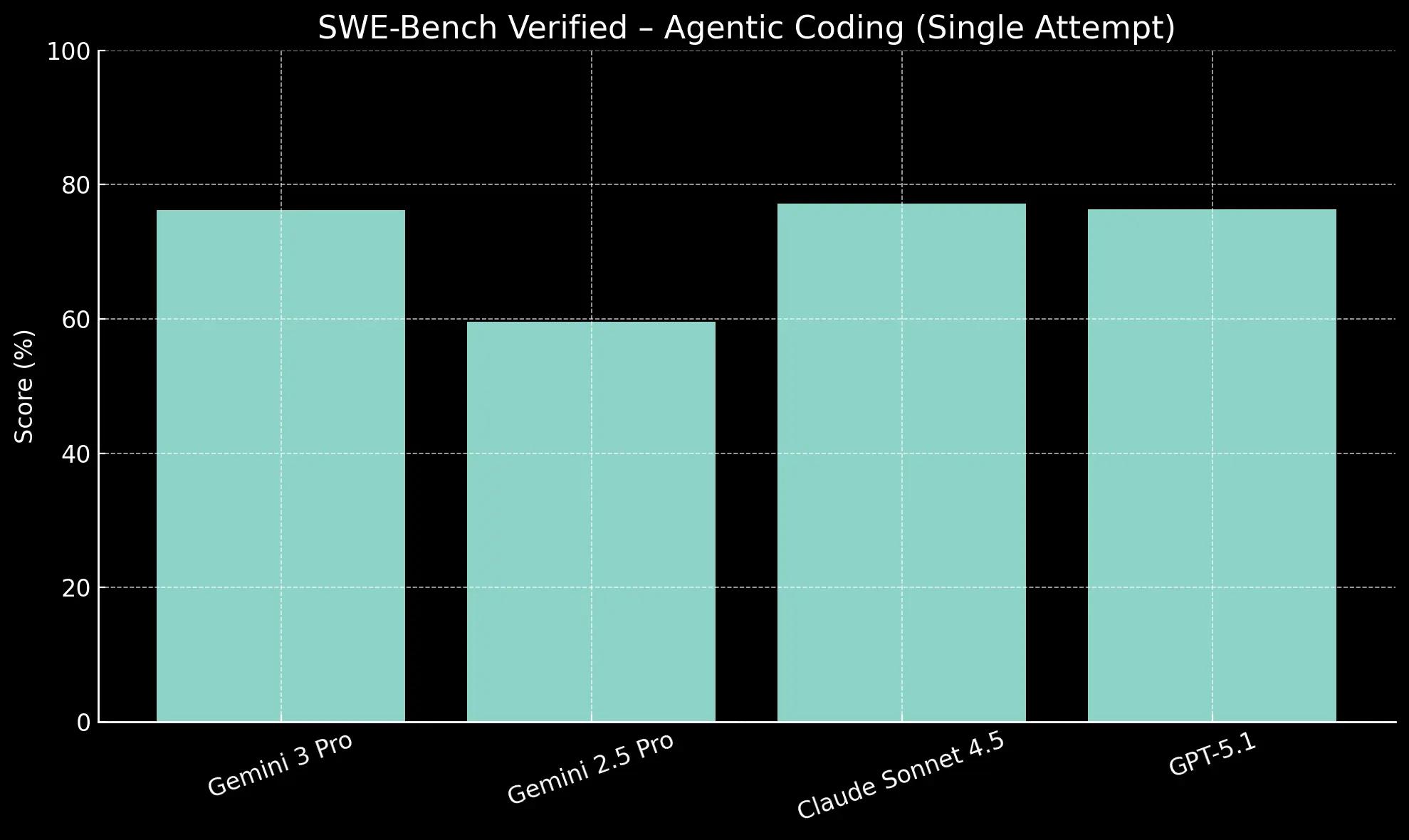
Its 76.2% on SWE-Bench for bug fixing is highly competitive with Claude Sonnet 4.5 (77.2%), but its dominance in algorithmic challenges suggests it is particularly well-suited for complex, from-scratch code generation.
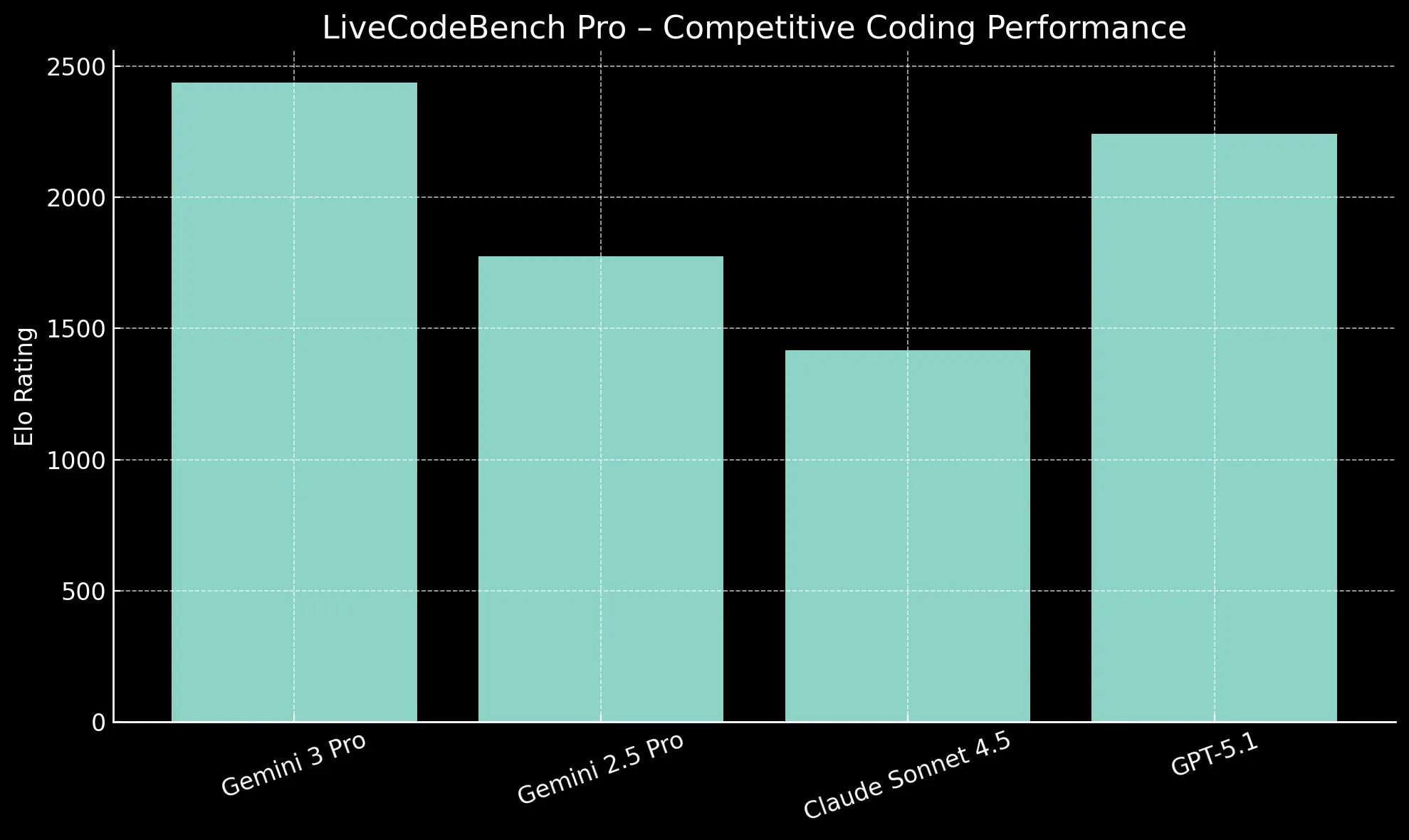
Gemini 3 Pro shows a commanding lead in algorithmic problem-solving, achieving an Elo rating of 2,439 on LiveCodeBench Pro. This is nearly 200 points higher than GPT-5.1 (2,243), indicating superior skill in generating novel and efficient code.
Long Context Capabilities
A large context window's value depends on the model's ability to accurately retrieve information. The MRCR v2 benchmark tests this "needle-in-a-haystack" capability within a large volume of text.
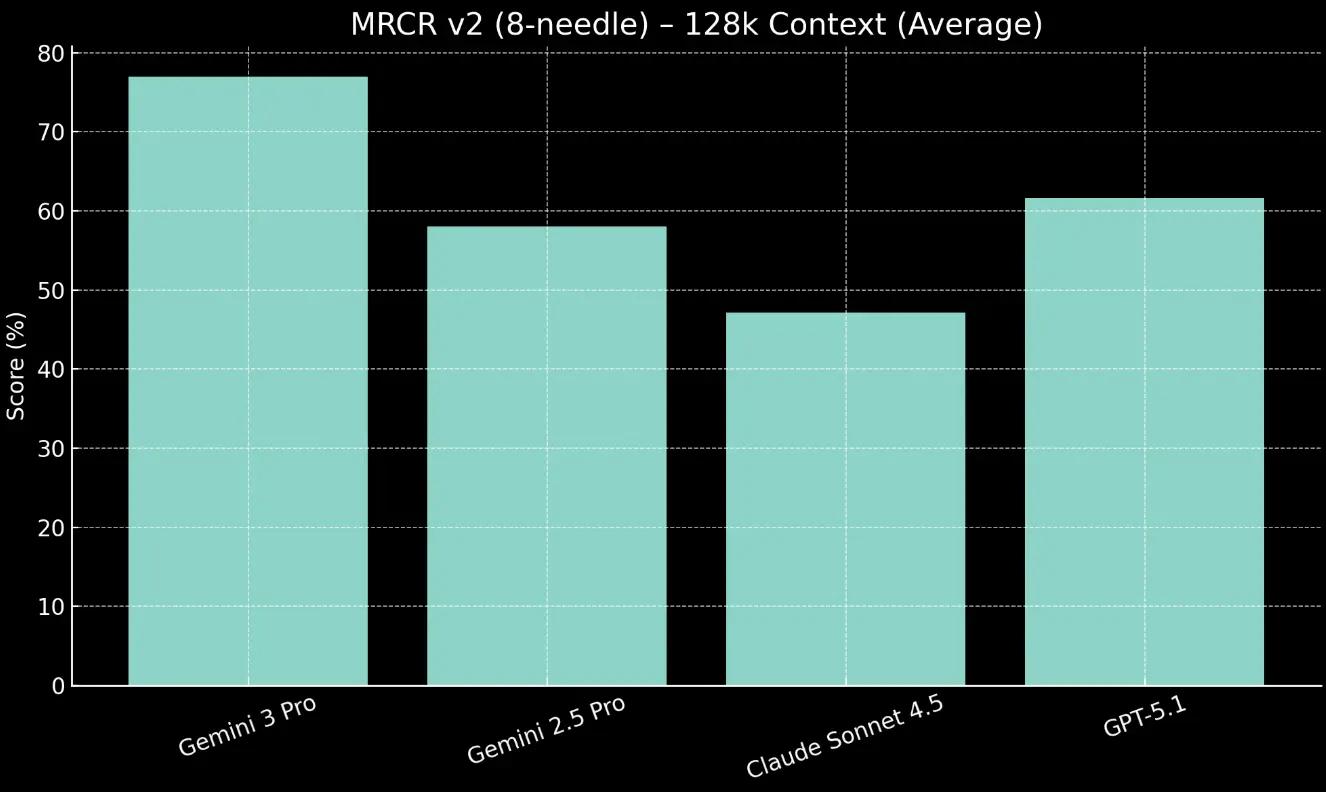
Gemini 3 Pro demonstrates strong recall, scoring 77.0% on the 128k average context length test.
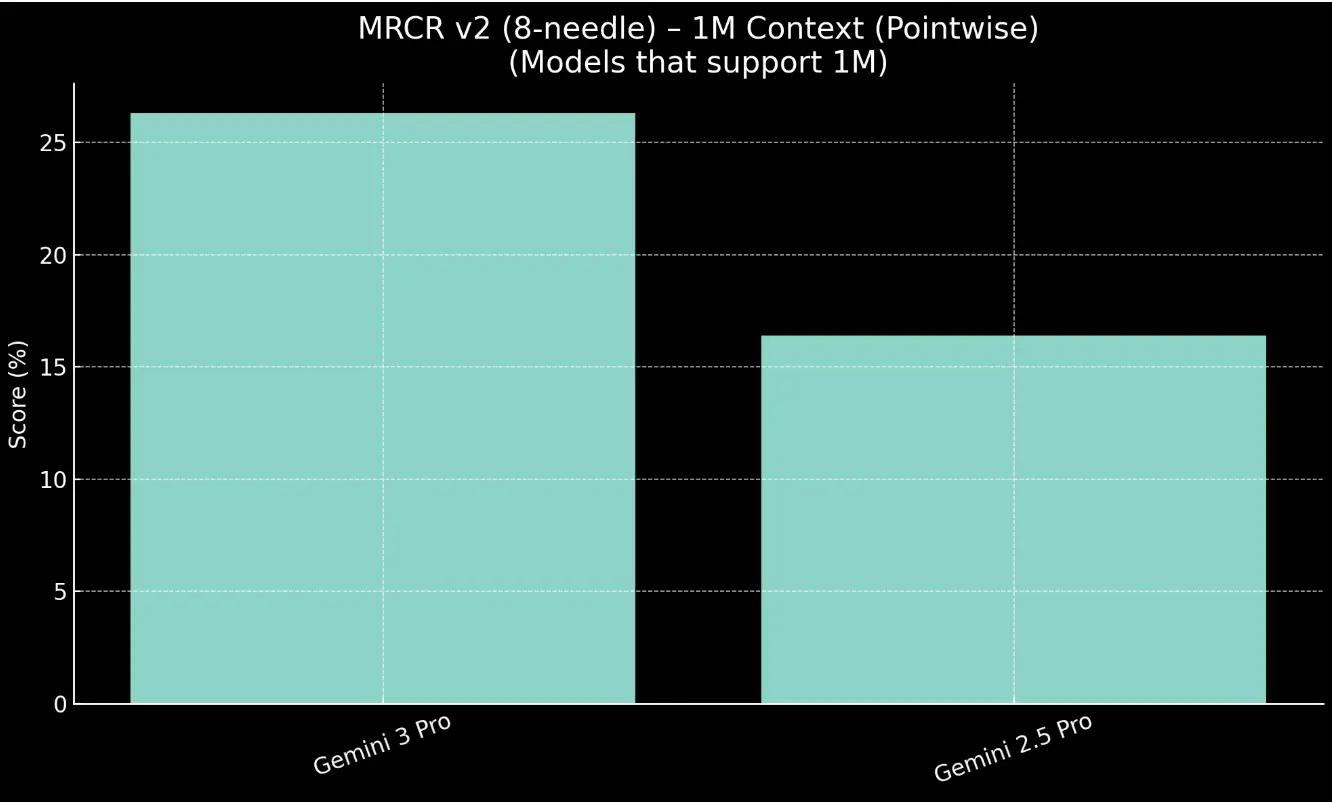
For larger context, 1M, Gemini 3 Pro outpaces the Gemini 2.5 Pro model by 9.9%.
Multimodal Capabilities
Natively multimodal models are assessed on their ability to understand and reason across different data types simultaneously. MMMU-Pro and Video-MMMU are key benchmarks for this integrated understanding.
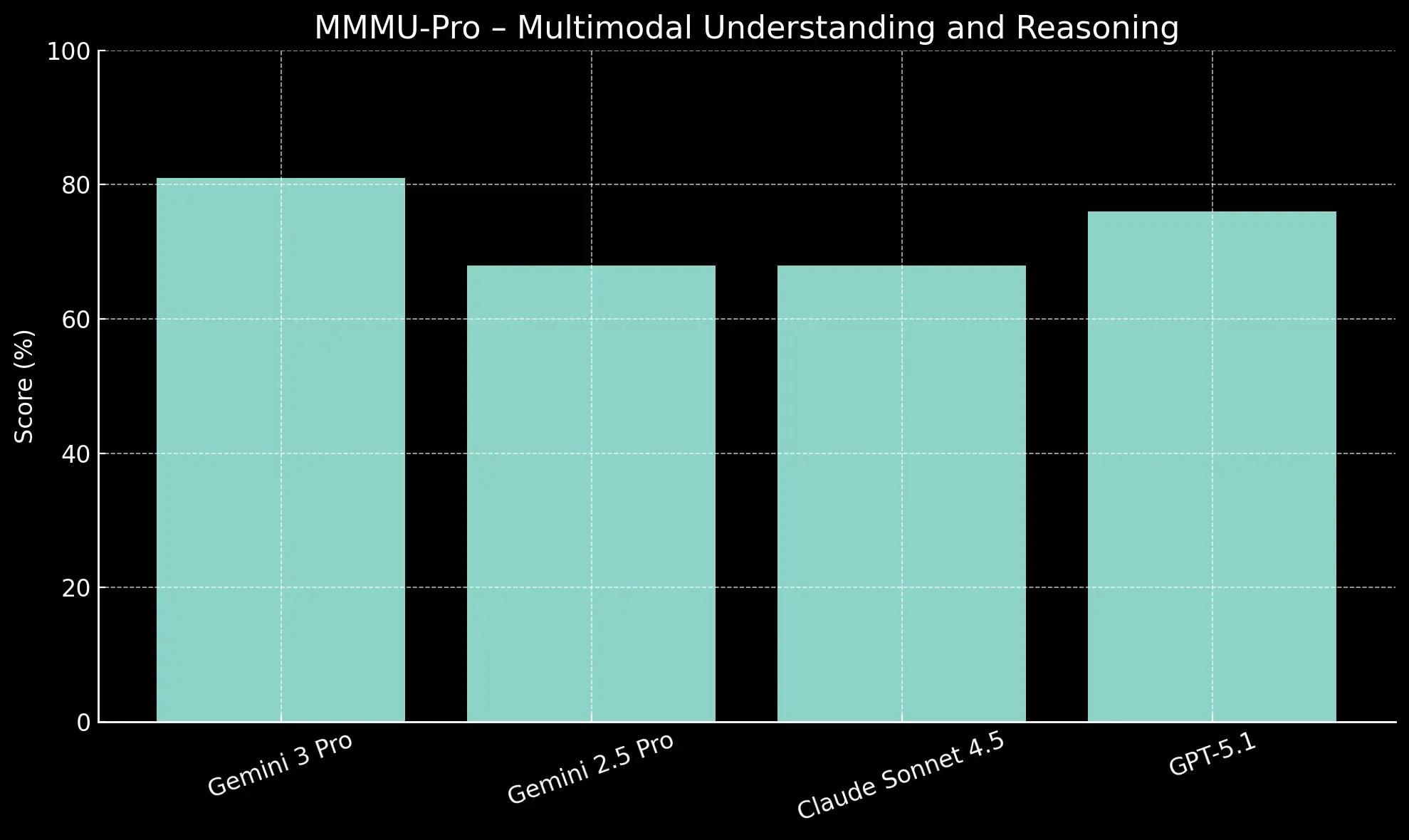
On MMMU-Pro, Gemini 3 Pro scores 81.0%, creating a significant 5-point gap ahead of GPT-5.1 (76.0%) in multimodal understanding and reasoning.
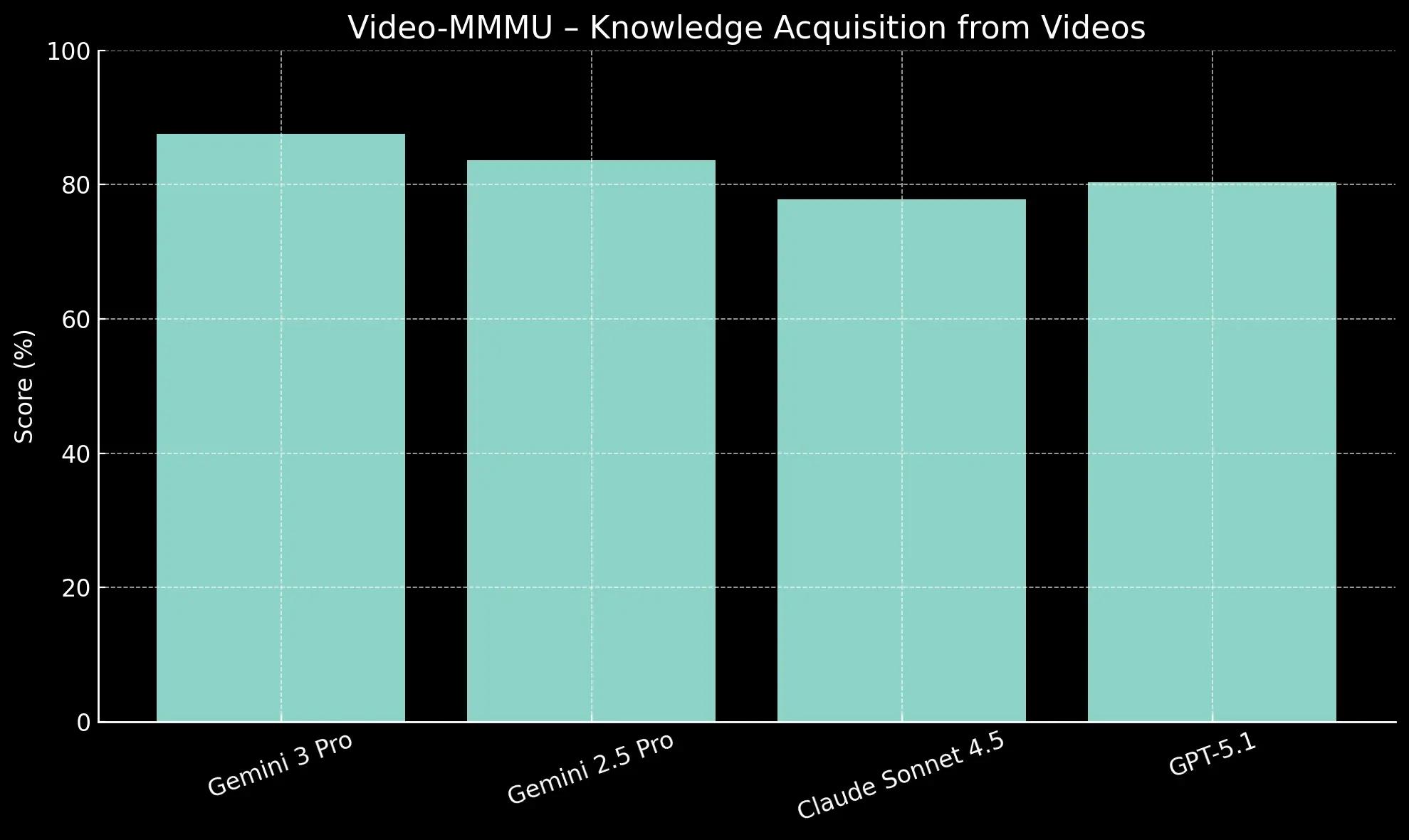
Its 87.6% score on Video-MMMU shows its strength is not limited to static images. This high performance demonstrates an advanced ability to comprehend and synthesize information from dynamic video content.
Multilingual Capabilities
These two benchmarks, the MMMLU and Global PIQA, test a model's performance beyond simple translation, evaluating its understanding of cultural context and logic across many languages.
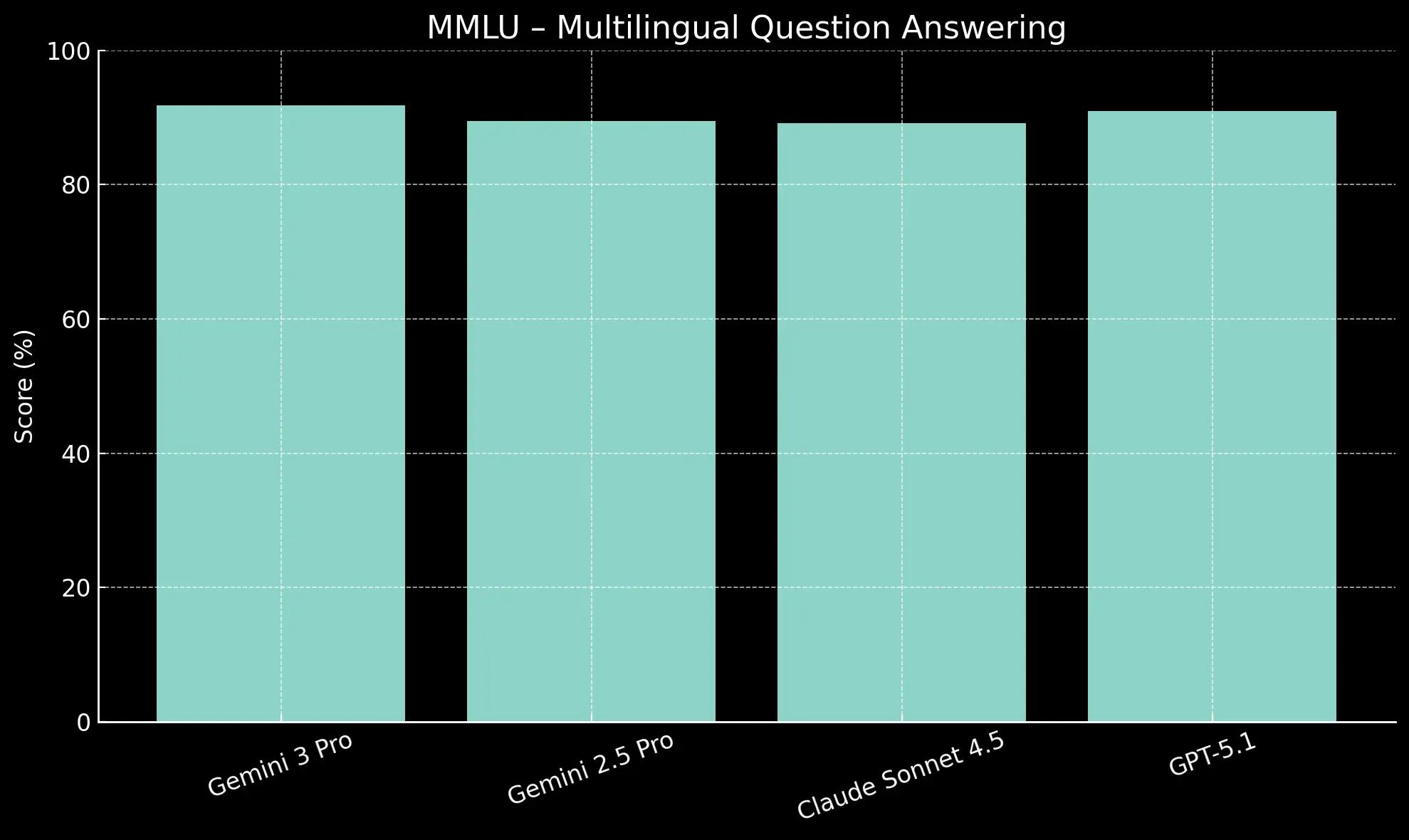
Gemini 3 Pro takes the top spot on MMMLU (Multilingual Q&A) with a score of 91.8%, slightly ahead of GPT-5.1 (91.0%).
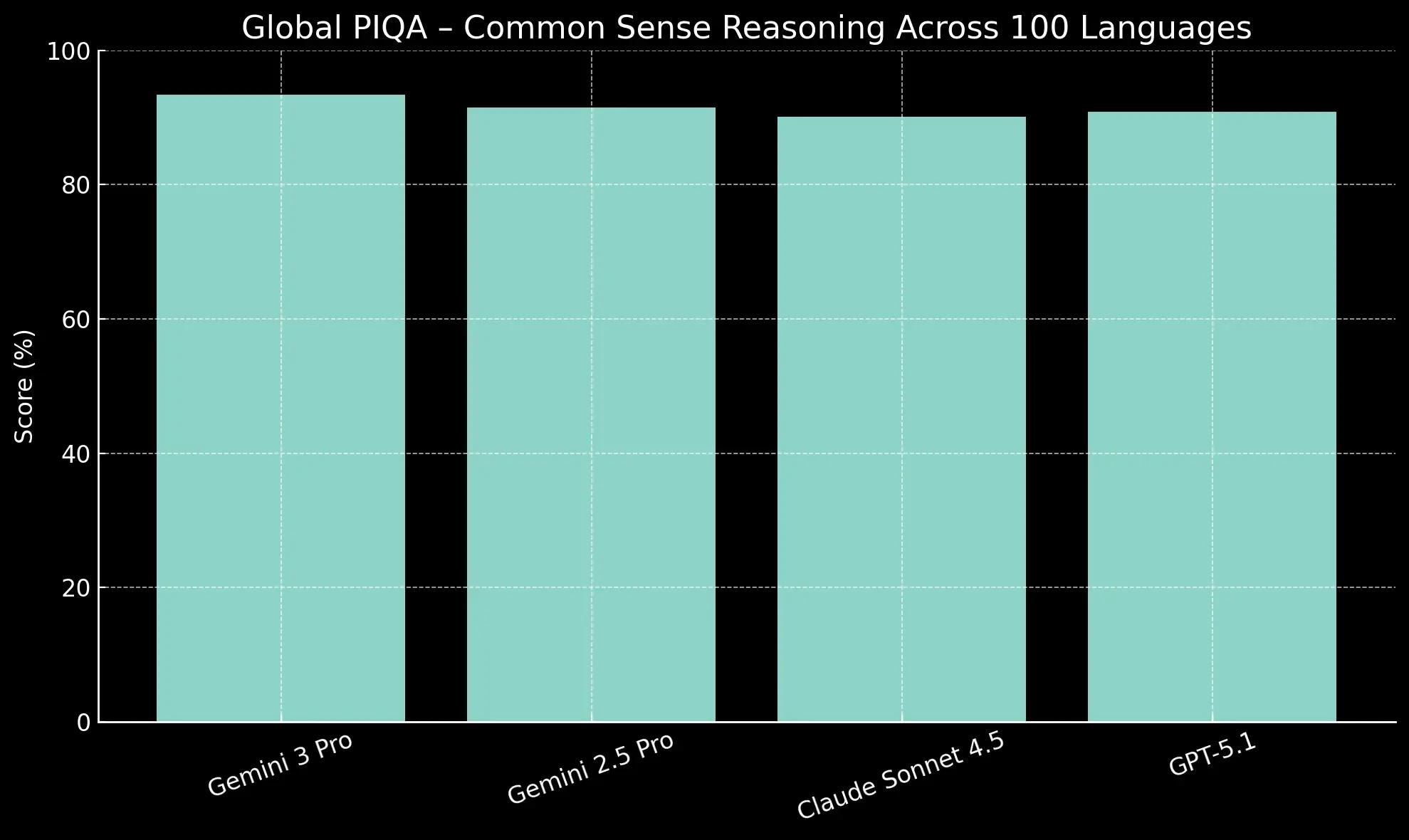
More significantly, its 93.4% on Global PIQA, which tests commonsense reasoning across 100 languages, suggests a deeper, culturally-aware understanding rather than just linguistic proficiency.
Long-Horizon Planning and Agentic Skills
Beyond single-turn tasks, a model's ability to plan and execute multi-step workflows is a critical measure of its agentic capabilities. Benchmarks like Vending-Bench 2 test this by simulating complex, long-term goals.
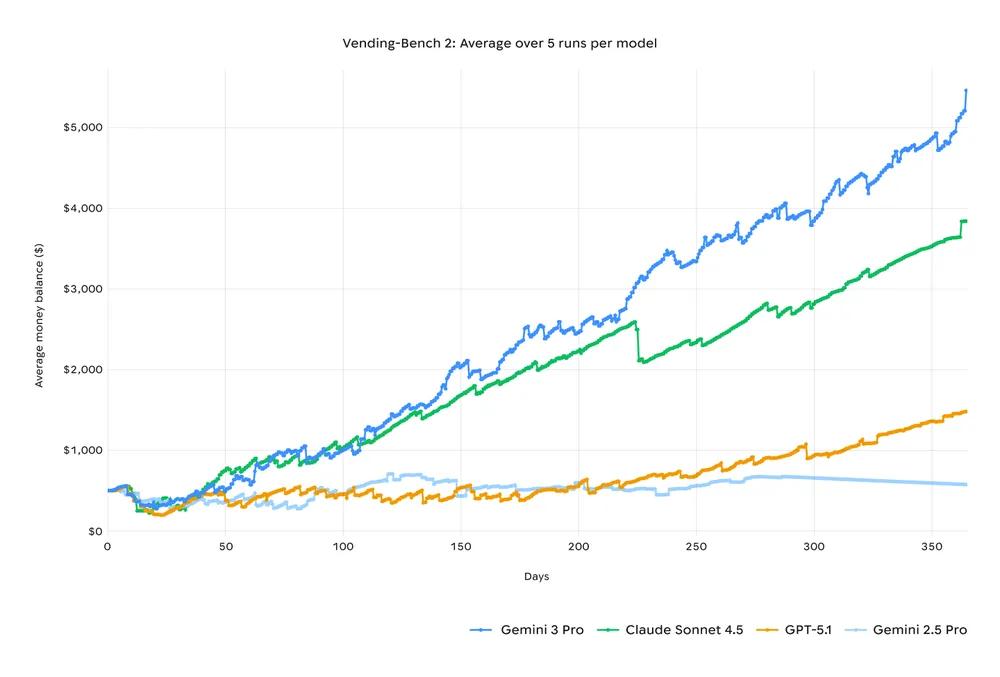
Gemini 3 Pro tops the leaderboard on Vending-Bench 2, a benchmark that simulates managing a vending machine business for a full year. This tests its ability to make strategic decisions over a long period. The key insight is its consistency. Gemini 3 Pro maintains reliable tool usage and decision-making throughout the entire simulation, preventing it from drifting off-task and ultimately generating higher returns than other models. This improved planning translates to practical, real-world assistance. It can more reliably navigate complex workflows like booking local services or organizing an inbox from start to finish under user guidance.
What these benchmarks really mean for your agents
Gemini 3 marks a clear step forward in the frontier of agentic systems. By raising the bar across every benchmark that actually translates to operational performance, it expands what your agents can reliably automate. The model is here and the capabilities are real. Now it’s on you to start building the agents that turn this progress into compounding efficiency and ROI.
Extra resources
Beginner’s Guide to Building AI Agents → Best Enterprise AI Agent Builder Platforms → Best Low code AI Workflow Automation Tools → Guide: No Code AI Workflow Automation Tools → Best AI Workflow Platforms →
{{general-cta}}






