Yesterday, Anthropic launched Claude 4 Opus and Sonnet. These models tighten things up, especially for teams building agents or working with large codebases. They're more reliable on long-running tasks, remember context better, and now supports parallel tool use and local memory for deeper task awareness.
Seems like Anthropic gave an early access for Opus 4 to a few companies and they all reported great successes:
Racuten ran a 7-hour open-source refactor with sustained performance. Replit reported improved precision for complex changes across multiple files.
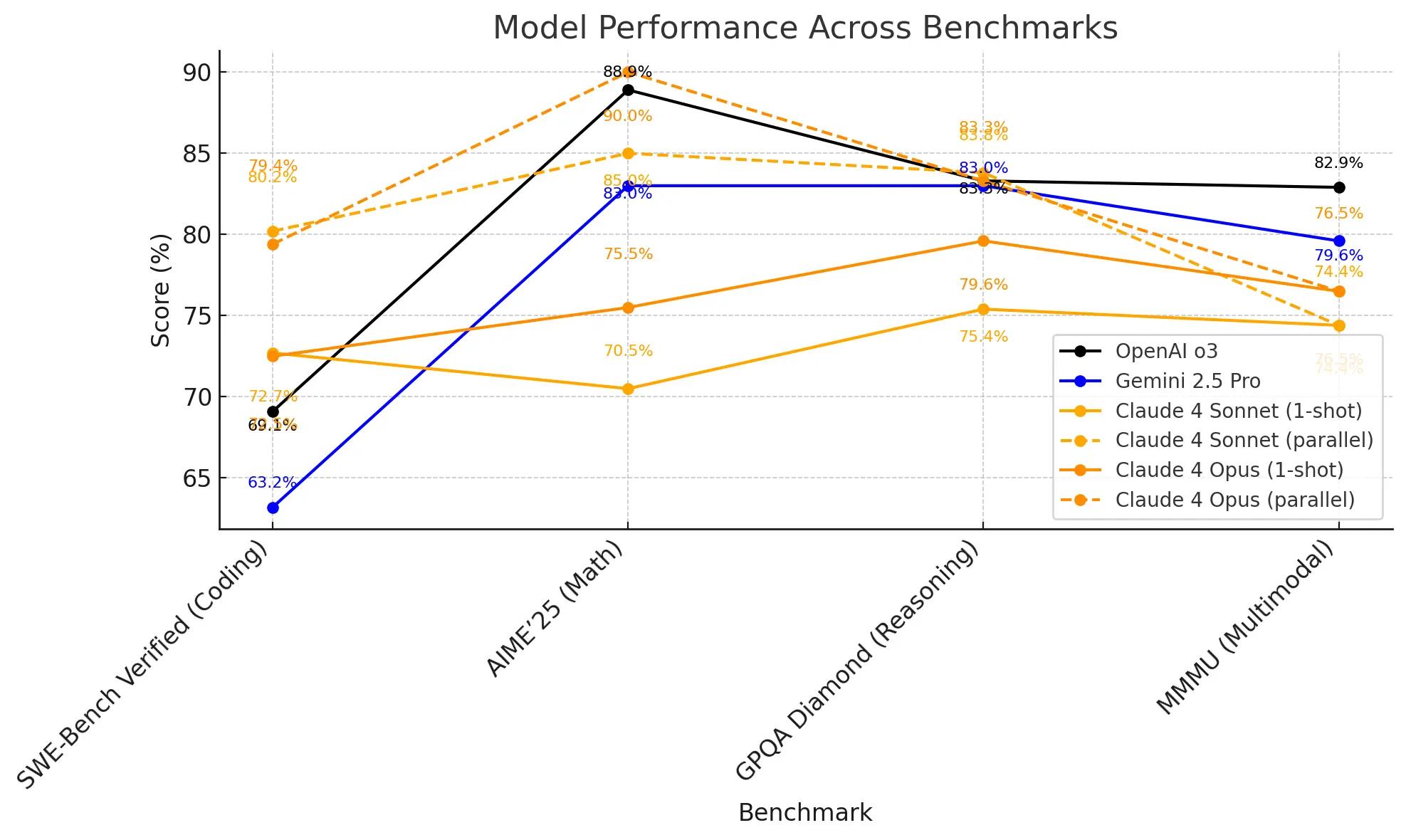
In terms of our well known “benchmarks”, the model leads the SWE-bench (Agentic coding) with 72.5% , which is a slight bump from OpenAI’s o3 (69,1%). The model gets even better results when ran with parallel test-time compute effort (explained further in the article).
In this report, we breakdown the pricing, latency, standard benchmarks, and our own independent evals on adaptive reasoning and hardest SAT equations.
One thing surprised us.. keep on reading!
Results
In this analysis we compared Claude 4 Sonnet vs OpenAI’s O3 and Gemini 2.5 Pro on how well they adapt to new context, and how well they solve the hardest SAT math problems. Here are the results!
Adaptive reasoning
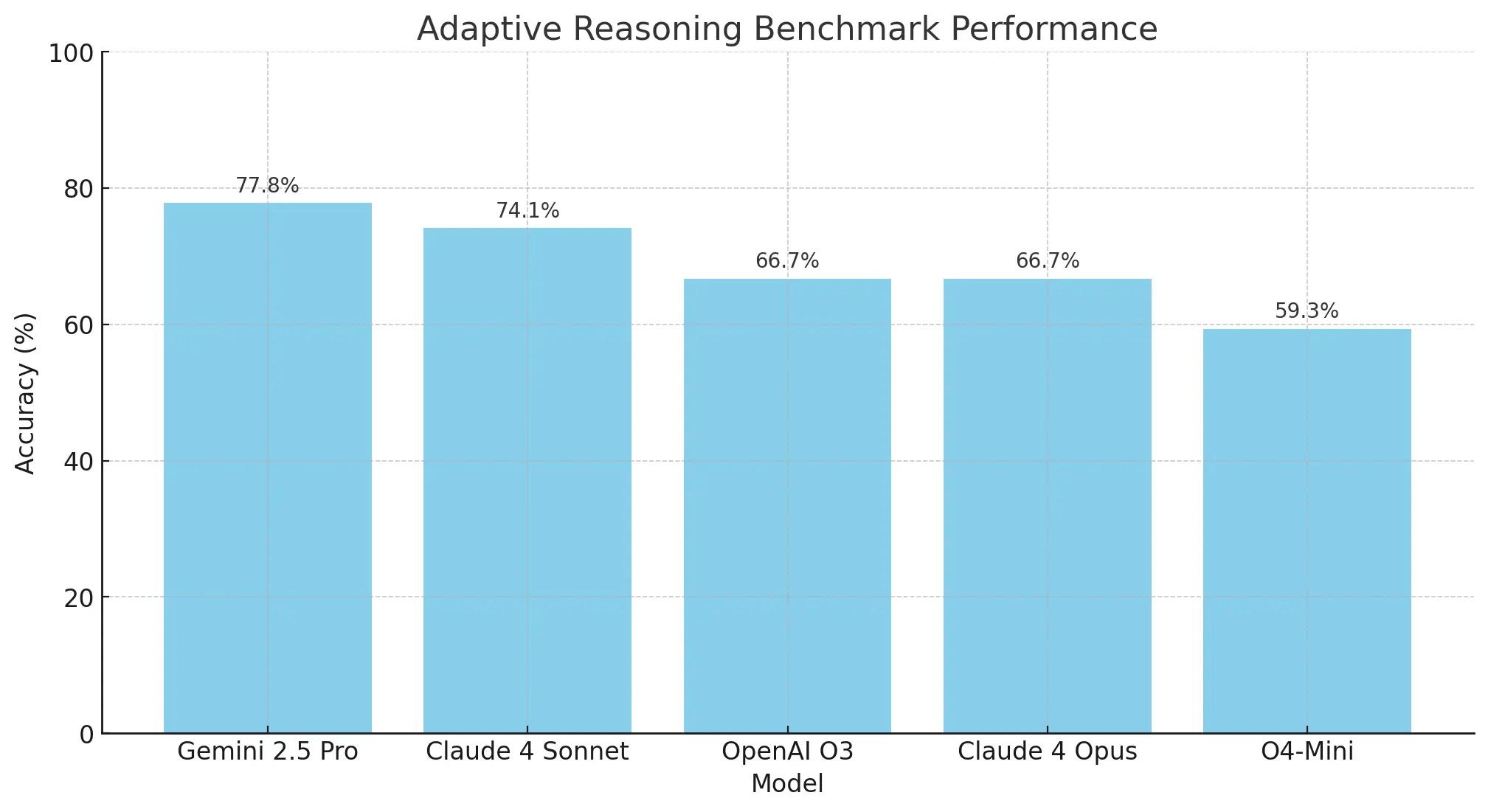
This evaluation shows how well models reason when presented with new context for puzzles that they’ve been trained heavily on. In our examples, we made changes to otherwise very popular puzzles, making them trivial and/or without constraints. We wanted to learn if the models will recognize the new context, and solve the puzzles without overfitting to their training data.
Claude 4 Sonnet and Gemini 2.5 Pro performed best, with o3 and Claude 4 Opus close behind. These models show real improvement, using prompt context more than training data. o4-mini still struggles with tricky, adversarial questions.
Hardest SAT questions (Math)
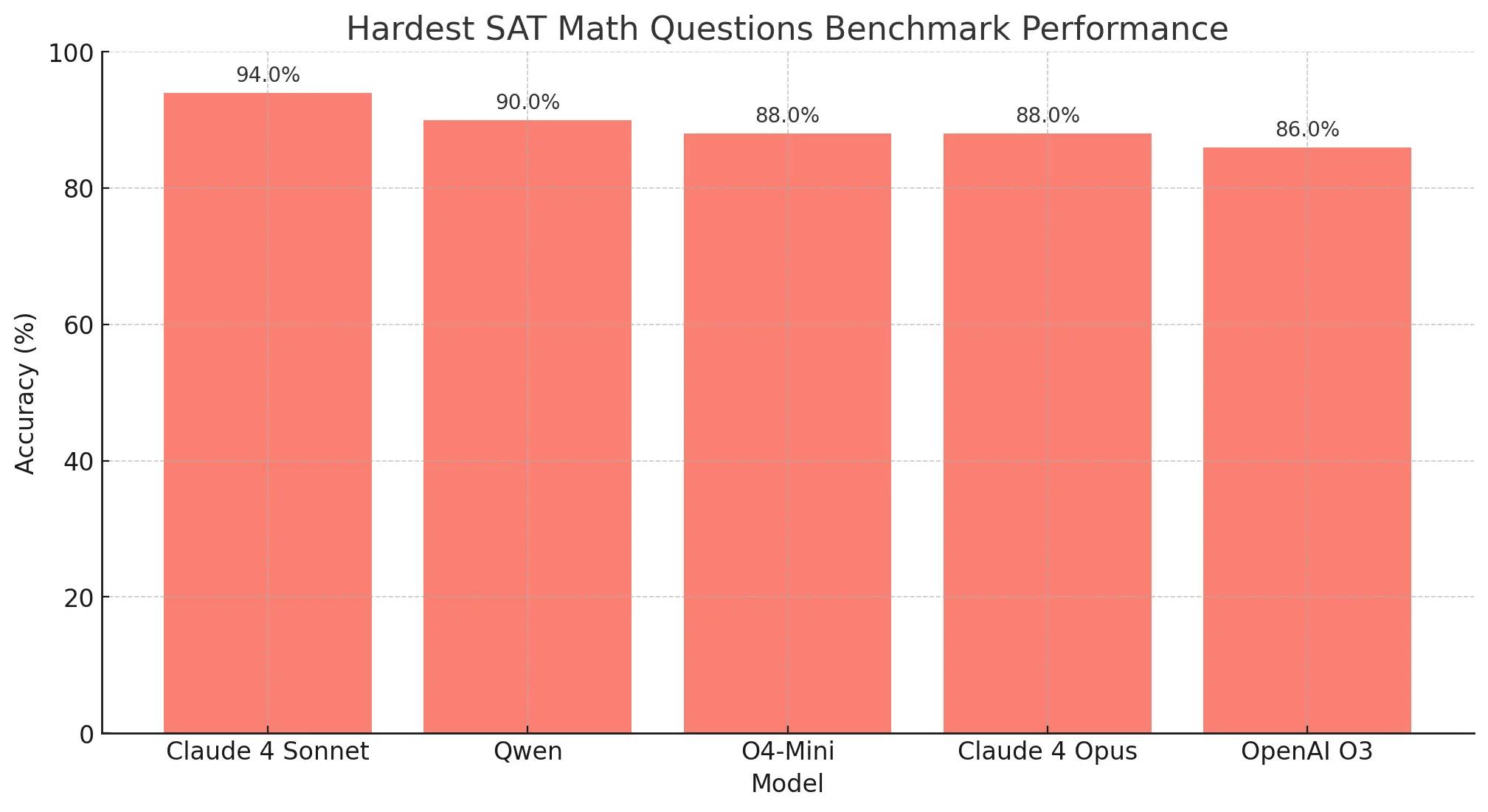
In this evaluation, we test how well these models can solve the 50 hardest SAT questions. And the new Claude models really took us by a surprise!
Claude 4 Sonnet scored the highest, which is surprising since Anthropic has focused more on coding than math. Claude 4 Opus, o4-mini, and o3 are close behind, all performing well. OpenAI’s o3-mini and Gemini 2.5 Pro had the weakest results, with hit-or-miss accuracy around 50% We threw all these other models in the mix to see how they all compare. Interestingly enough the newest Qwen model is keeping it up!
Cost & Speed
Seems like Claude 4 Sonnet is the best choice across tasks, with the best balance on speed (1.9s latency) and cost ($15/$30 per 1M tokens input/output). For any simpler task, any of the other lighter models will do.
Methodology
In the next two sections we will cover three analysis:
Speed & Cost comparison Standard benchmark comparison (example: what is the reported performance for math tasks between Claude 4 Sonnet vs o3 vs Gemini 2.5 Pro?) Independent evaluation experiments: Adaptive reasoning Hardest SAT math equations
Evaluations with Vellum
To conduct these evaluations, we used Vellum’s AI development platform , where we:
Configured all 0-shot prompt variations for both models using the LLM Playground. Built the evaluation dataset & configured our evaluation experiment using the Evaluation Suite in Vellum. We used an LLM-as-a-judge to analyze generated answers to correct responses from our benchmark dataset for the math/reasoning problems. A human reviewer evaluated all answers, and then compiled and presented the findings
You can skip to the section that interests you most using the "Table of Contents" panel on the left or scroll down to explore the full comparison between Claude 4 Sonnet, OpenAI’s o3 and Gemini 2.5 Pro.
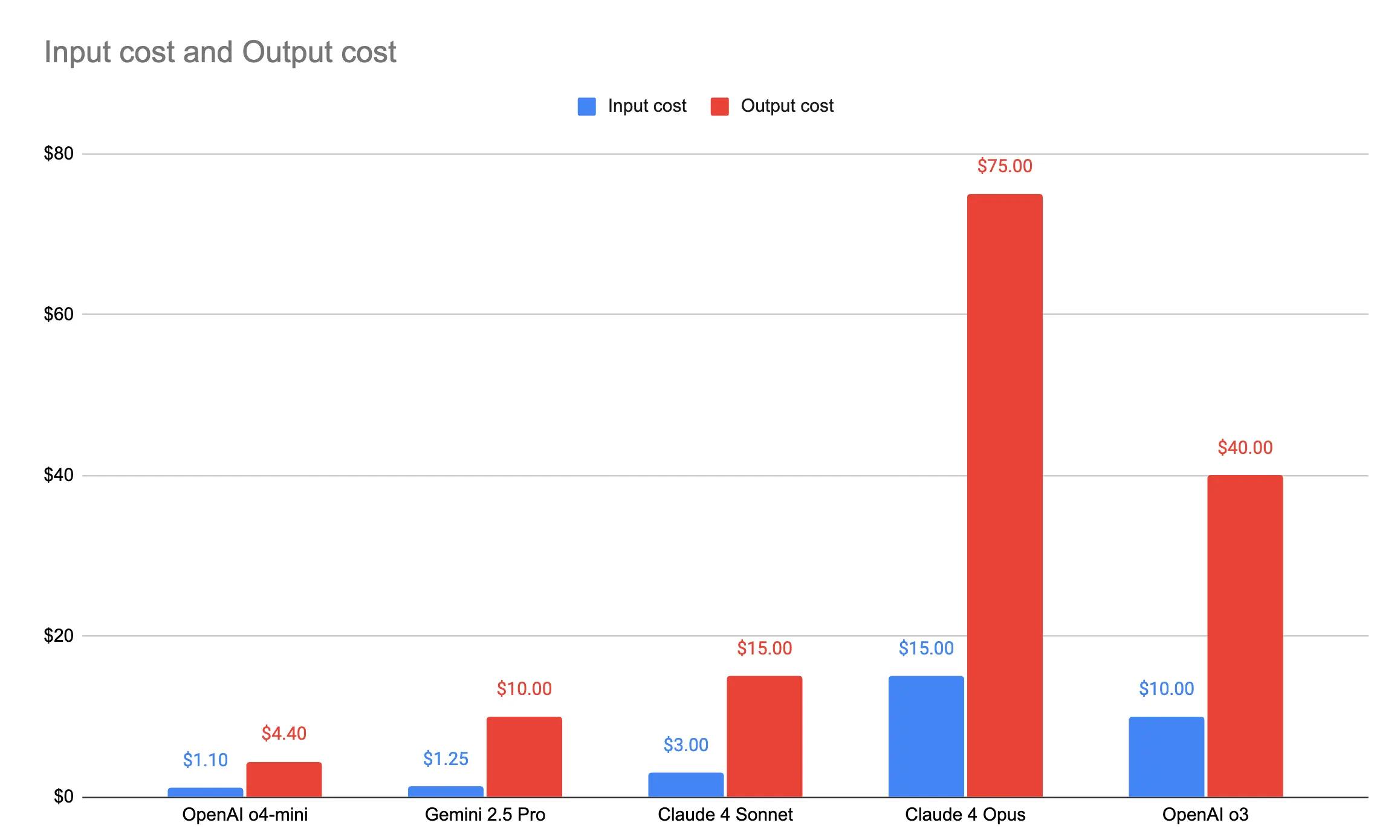
Cost, Latency and Speed
Claude 4 Opus and OpenAI o3 just don’t justify their price tags. At $15/$75 and $10/$40 cost for input/output per 1M tokens, they’re massively more expensive, but not meaningfully better.
Claude 4 Sonnet performs nearly as well across math, coding, and reasoning, at a fraction of the cost. Gemini 2.5 pro and the o4-mini are great models too for simpler tasks, and so much more cheaper.
The same argument holds when it comes to speed.
Seems like Claude 3.7 Sonnet is already a fast model with 1.9s latency and on par with the most advanced reasoning models (o3, o4-mini, Gemini 2.5 Pro) makes it the best choice in terms of cost & speed for more advanced tasks.
For simpler tasks, even lighter and more cheaper model like Gemini 2.5 Pro or o4-mini can do the job pretty well.
Standard Benchmarks
Looking at the benchmarks, it's clear that Claude models still take the lead in coding, especially with the reports of running the models with a parallel test-time compute. So Opus 4 and Sonnet 4 are already strong , but they get even better (6–8% boost) when allowed multiple tries in parallel (check the graph below, and the dotted lines).
So, how to interpret these numbers with Claude models?
If your use case allows reruns or multiple attempts (like retries, reranking, or sampling) , these models will perform closer to the higher number. If your setup only allows one shot (e.g. latency-critical tasks) , you should care more about the lower number.
Also, in the official announcement Anthropic didn’t highlight any math improvements, but the results clearly show big improvements there.
Evaluation 1: Adaptive Reasoning
We tested the models on 28 well-known puzzles. For this evaluation, we changed some portion of the puzzles, and made them trivia. We wanted to see if the models still overfit on training data or can successfully adapt to new contexts. For example, we modified the Monty Hall problem where the host does not open an additional door:
👉🏼“Suppose you're on a game show, and you're given the choice of three doors: Behind one door is a gold bar; behind the others, rotten vegetables. You pick a door, say No. 1, and the host asks you, 'Do you want to pick door No. 2 instead?' What choice of door now gives you the biggest advantage?”
In the original Monty Hall problem, the host reveals an extra door. In this case, it does not, and since there is no additional information provided, your odds remain the same. The correct answer here is: “It is not an advantage to switch. It makes no difference if I switch or not because no additional material information has been provided since the initial choice.”
Most reasoning models struggle with this kind of changes with very famous puzzles, but newer models are starting to do better here. This is true for the new Claude 4 models:
Click to Interact
×
From the above we can clearly see that:
Gemini 2.5 Pro and Claude 4 Sonnet have the best results. OpenAI’s o3 model and Claude 4 Opus did really well on this task too. These are the first models with which we can notice significant improvements on this task. By analyzing the actual answers, we can notice less reliance on training data and more reliance on the new context provided in the prompt. The o4-mini model still struggles with these kinds of adversarial questions.
The Claude 4 Sonnet especially is doing great with these questions, in 21/28 times it got the answer right. When we look at the “thinking summaries” in the prompt we noticed that the model did a thoughtful chain of thought thinking using the new context. In most cases the model was aware that there is new context in the prompt.
For example, in our adjusted classic river-crossing puzzle there are no hard constraints:
👉🏼A farmer wants to cross a river and take with him a wolf, a goat, and a cabbage. He has a boat with three secure separate compartments. If the wolf and the goat are alone on one shore, the wolf will eat the goat. If the goat and the cabbage are alone on the shore, the goat will eat the cabbage. What is the minimum number of crossings the farmer needs to make to bring the wolf, the goat, and the cabbage across the river without anything being eaten?
and the model quickly analyzed all “constraints” and answered:
“ This is different from the classic river-crossing puzzle where the boat can only hold the farmer plus one item, requiring multiple trips and strategic planning. My final answer is 1 race.”
Evaluation 2: Hardest SAT problems
For this task, we’ll compare the models on how well they solve some of the hardest SAT math questions . This is the 0-shot prompt that we used for both models:
You are a helpful assistant who is the best at solving math equations. You must output only the answer, without explanations. Here’s the <question>
We then ran all 50 math questions and here’s what we got:
Click to Interact
×
From the above we can clearly see that:
Claude 4 Sonnet got the best score compared to all proprietary and open-source models here. Which is an interesting surprise here, because we know that Anthropic is really focusing on improving their models for coding tasks, and not math. The o4-mini, o3 and the Claude 4 Opus have similar results and are training close to Claude 4 Sonnet. All of them have pretty good results. The worst however are OpenAI’s o3-mini and Gemini 2.5 Pro, which are still hit or miss, landing around 50/50 on these examples.
Conclusion
Claude 4 is here and while it is not a game changer, it is a solid step forward. The real standout is Claude 4 Sonnet . It is fast, smart, and much more affordable than the bigger models like Opus 4 or OpenAI o3, which honestly do not give you much more for the extra cost.
If you are building anything that needs solid reasoning, math skills, or long context understanding, Sonnet is probably your best bet. And for simpler tasks, o4 mini or Gemini 2.5 Pro get the job done just fine.
Bottom line: Claude 4 Sonnet is the best choice on the market now!