Meta's Llama 3 70B, the first open-source model to match GPT-4's performance, is gaining traction among companies. The perks of being open-source —lower costs and increased customizability—are accelerating this shift, significantly transforming how businesses handle their generative AI strategies.
To better understand the model's capabilities, we gathered recent data from technical reports and independent reviews, and analyzed how it performs on different tasks.
Our findings show that Llama 3 70B can be up to 50 times cheape r and 10 times faster than GPT-4 when used through cloud API providers.
From our small scale evaluations, we learned that Llama 3 70B is good at grade school math, arithmetic reasoning and summarization capabilities. However, it performs poorly on middle school math, and verbal reasoning tasks.
Overall, GPT-4 performs better in reasoning and math tasks, but Llama 3 70B is a strong competitor. It delivers solid results across all tasks and offers additional benefits in terms of cost and flexibility. Basically, with Llama 3 70B you can get GPT-4 performance at GPT-3.5 cost.
In this article, we provide a thorough analysis that will equip you with all the necessary information to determine whether Llama 3 70B is a good alternative for certain aspects of your AI apps.
Approach
The main focus on this analysis is to compare two models: GPT-4 ( gpt-4-0613 ) vs and Llama 3 70B . We look at standard benchmarks, community-run experiments, and conduct a set of our own small-scale experiments.
In the next two sections we cover:
Basic comparison (example: Cutoff date, Context Window) Cost comparison Performance comparison (Latency, Throughput) Standard benchmark comparison (example: what is the reported performance for math tasks between Llama 3 70B vs GPT-4?)
Then, we run small experiments and compare the models on the following tasks:
Math riddles Document summarization Reasoning
You can skip to the section that interests you most using the "Table of Contents" panel on the left or scroll down to explore the full comparison between GPT-4 and Llama 3 70B.
The Basics
When it comes to context window size, Llama 3 70B is still behind the long context options that proprietary models offer. It currently comes with 8K context window length, compared to GPT-4 that comes with 128K context length.
Bub, because the model is open-source and all weights and code are available, Gradio, an AI company, was able to publish several models that extend the initial context window. These models let Llama work with up to 1 million tokens , and they're performing really well on the OpenLLM leaderboard . You can check them all here .
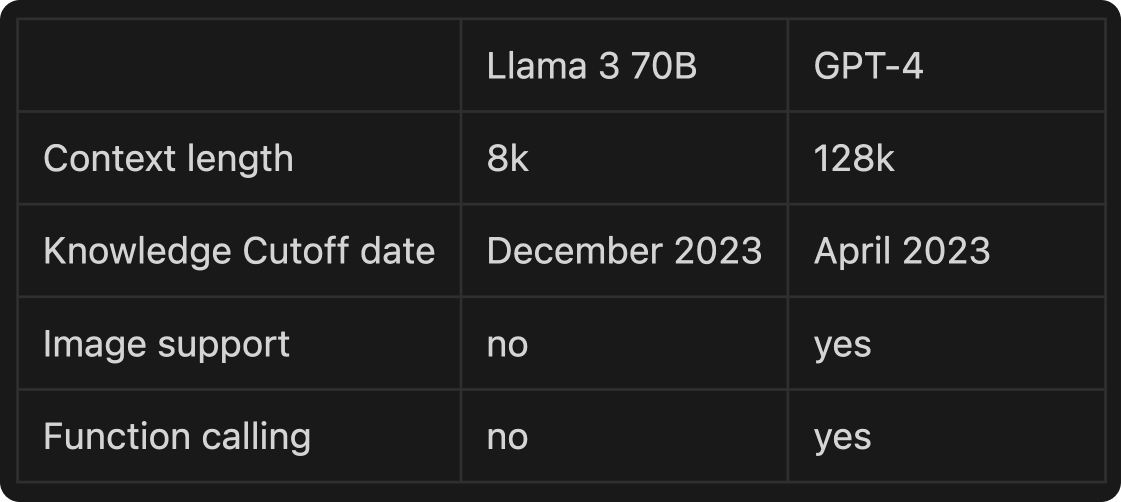
GPT-4's knowledge is updated until April 2023, whereas Llama 3's extends to December 2023. Unlike Llama 3, GPT-4 supports function calling. Also, Llama 3 doesn't currently handle images, but Meta has hinted at upcoming features like longer context lengths and more capabilities soon.
Now let’s look at the cost comparison.
Cost Comparison
Since Llama 3-70B is open-sourced, you have many options to run it. If you're familiar with the process, you can run it locally, where you'll only pay for hardware and electricity. Alternatively, you can use a hosted version from various providers. Regardless of the option you pick, using Llama will cost much less than GPT-4.
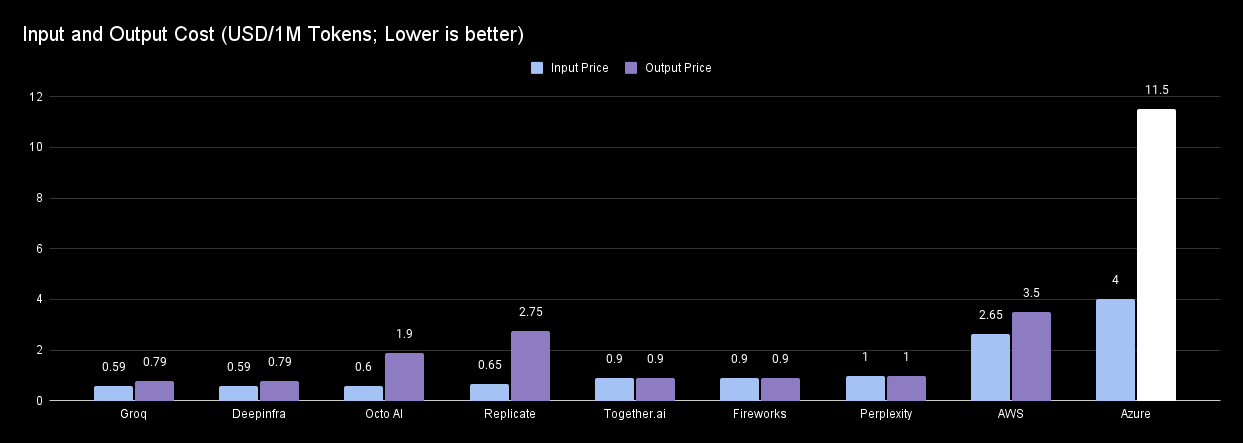
GPT-4 is currently the most expensive model, charging $30 per million input tokens and $60 per million output tokens.
Looking at the table below, even if you use Llama-3-70B with Azure, the most expensive provider, the costs are much lower compared to GPT-4—about 8 times cheaper for input tokens and 5 times cheaper for output tokens (USD/1M Tokens). If you choose Groq, the cheapest provider, the savings are even greater: more than 50 times cheaper for input tokens and 76 times cheaper for output tokens (USD/1M Tokens).
Perfromance Comparison
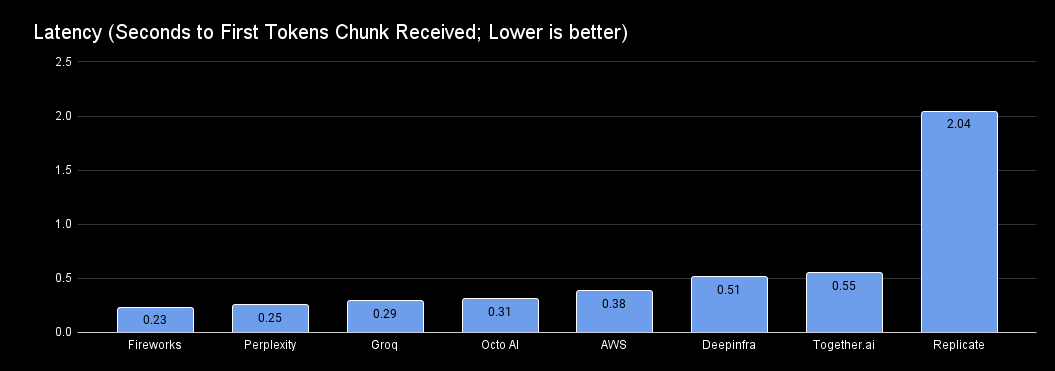
Latency Comparison
Choosing any of the first five providers on the graph will offer faster latency with Llama 3 70B than GPT-4. Given that GPT's latest recorded latency is 0.54, Llama 3 70B seems to be a much better option in this regard.
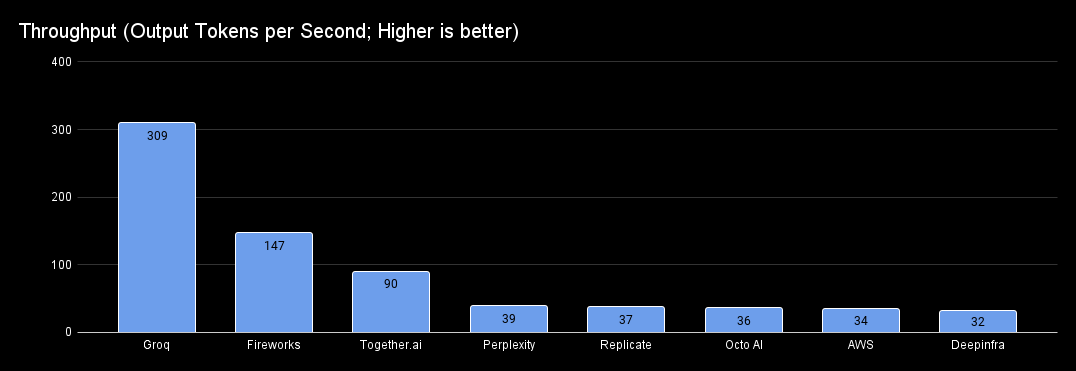
Throughput Comparison
Llama, hosted on the Groq platform, provides the fastest throughput, generating 309 tokens / second, which is almost 9 times faster than GPT-4 (36 tokens / second). Fireworks and Together are great alternatives as well.
Benchmark Comparison
The first place to start learning about these models is the benchmark data reported in their technical reports or announcements. The graph below compares the performance of Llama 3 70B model against GPT-4 on standard benchmarks for various tasks.
If you want to gain a better understanding of these benchmarks, check our blog post: LLM Benchmarks: Overview, Limits and Model Comparison . We also encourage you to bookmark our our leaderboard as a tool for ongoing comparisons.
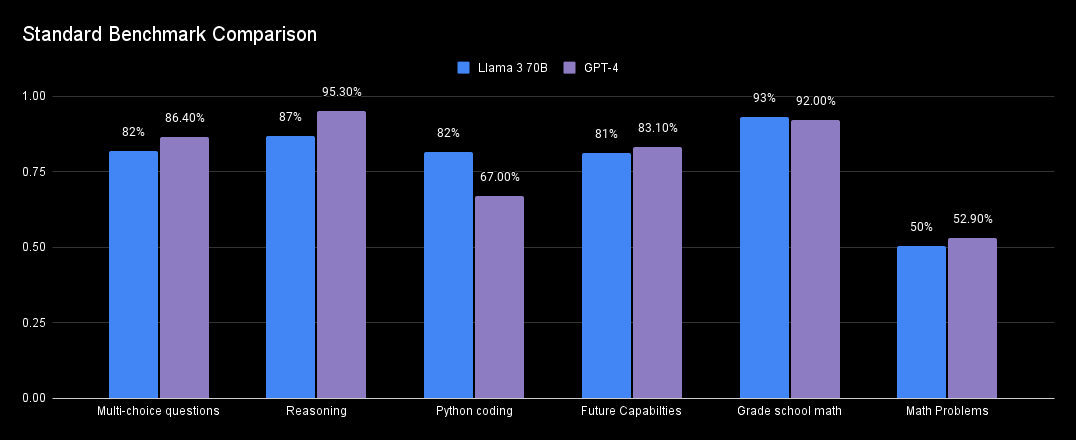
This graph reveals the following:
Llama 3 70B demonstrates 15% higher performance in Python coding and slightly better results for Grade school math tasks than GPT-4. GPT-4 excels in all other categories, particularly achieving the highest scores in multi-choice questions and reasoning tasks.
Benchmarks matter, but they don’t tell the whole story. To really know how your AI system performs, you must experiment with your prompts, and evaluate every stage of your workflow.
But, one thing is clear: We now have an open-source model competing with the world's top closed-source model.
Now let's compare these models on 3 tasks.
Task 1: Math Riddles
In the previous section, we saw that Llama 3-70B is quite good at math tasks. Now, let's do a quick experiment to see if that's still the case.
We picked a set of seven math riddles designed for students not yet in middle school and seven more at the middle school level as the cornerstone of the test.
Here are a couple of example riddles and their source :
🧮 For the younger minds If you have four apples and you take away three, how many do you have?" The intuitive answer is three, as those are the apples you took. 🧮 For the older middle school students A cellphone and a phone case cost $110 in total. The cell phone costs $100 more than the phone case. How much was the cellphone?" **The correct answer, a bit more complex, is 105 (not 110!)
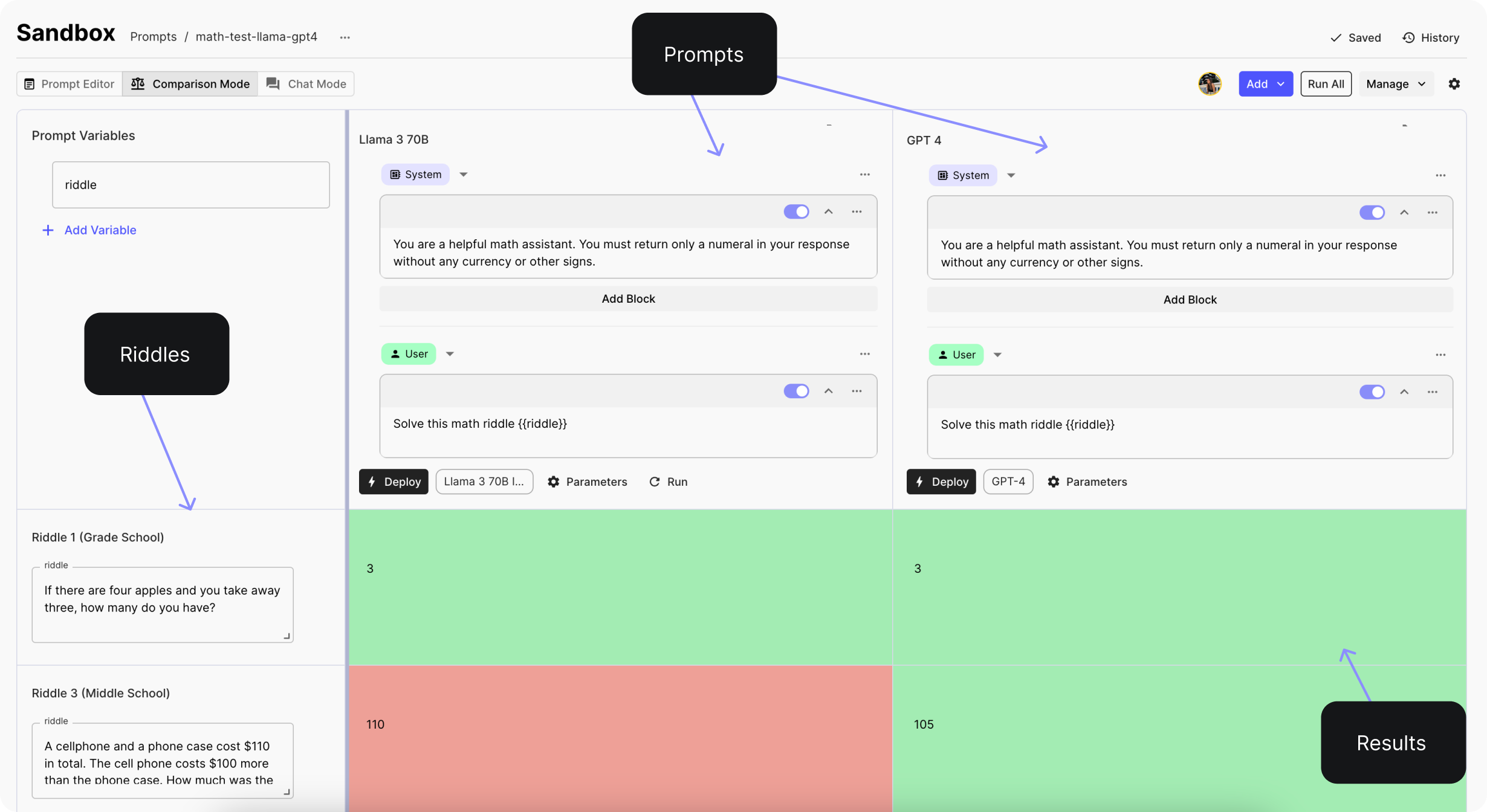
The prompt was the same for both models:
System message: You are a helpful math assistant. You must return only a numeral in your response without any currency or other signs. User message: Solve this math riddle {{riddle}}
The image below is a screenshot of the Vellum Prompt Sandbox , where we initially experimented with our prompts and two basic examples.
In the next image, we have the two models each attempting to answer a total of 14 math riddles, 7 grade school level, and 7 middle school level riddles.
We use Vellum Evaluations to compare the average performance across all test cases.
Looking at the results below, Llama 3 70B aced most grade school riddles but struggled with nearly all middle school ones, scoring only 50% correct across the board. In contrast, GPT-4 performed notably better.
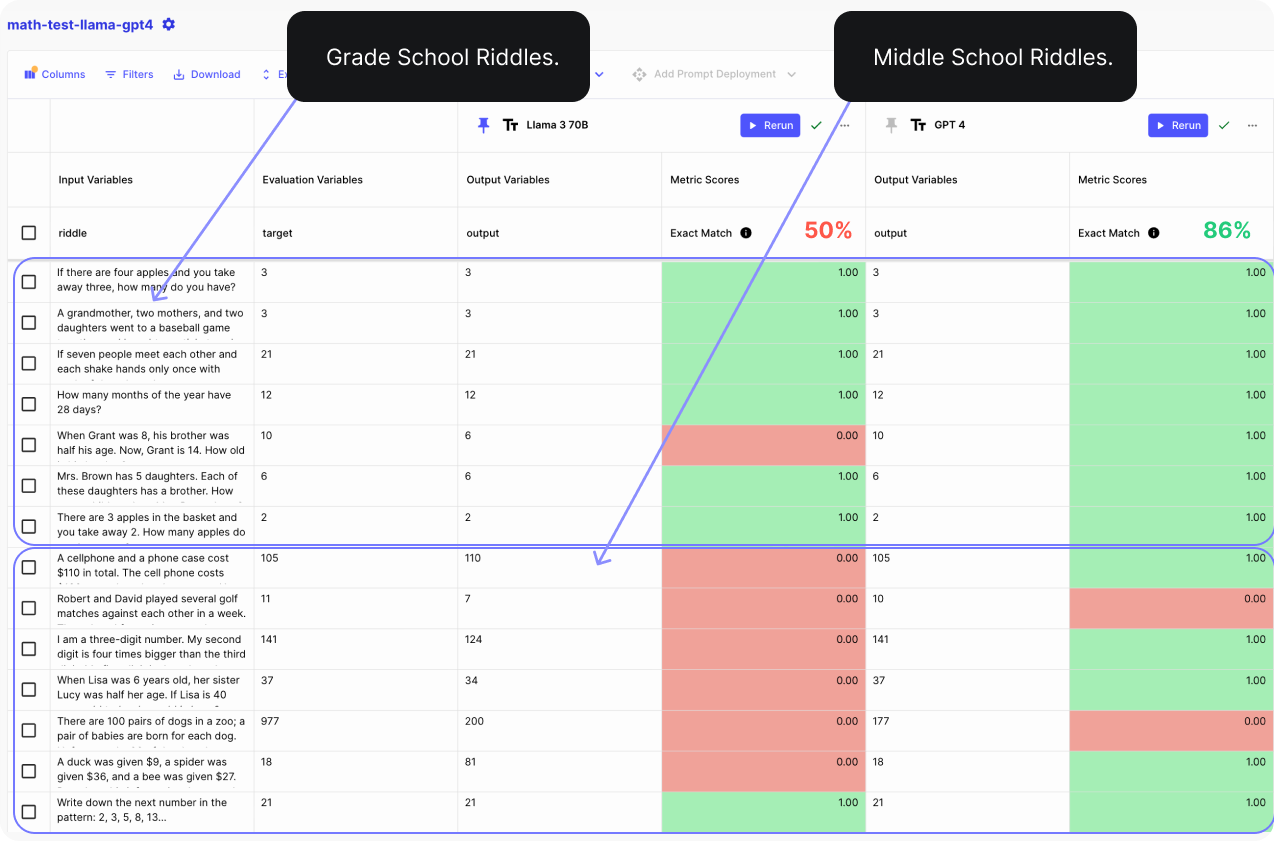
Key Takeaways:
If math is your main challenge, GPT-4 is a better overall option. You can use Llama 3 70B for grade school riddles, but it still struggles with middle school riddles.
Task 2: Summarizations
We tasked both Llama and GPT-4 to summarize one of our technical reports where we compared models on a classification task. A good summary should be concise, integrate key data effectively, and conclude coherently.
We gave the models one simple instruction:
💬 Prompt Please summarize the following document {{ document }}
Both summaries captured all three aspects really well. Here’s what Llama 3 generated:
The document compares the performance of four language models (Gemini Pro, GPT-4 Turbo, GPT-3.5 Turbo, and Claude 2.1) in classifying customer support tickets as resolved or not. The experiment used 200 test cases and evaluated the models based on accuracy, recall, precision, and F1 score. The results showed that Gemini Pro outperformed the other models, with an accuracy of 74% and an F1 score of 76.69%. Claude 2.1 had a high recall rate, while GPT-4 Turbo had a high precision rate. The experiment highlights the importance of prompt engineering and the need to consider the specific requirements of the task when choosing a model.
And here’s the slightly longer output by GPT-4:
The document details an experiment conducted to compare the performance of four models - GPT-3.5 Turbo, GPT-4 Turbo, Claude 2.1, and Gemini Pro - in classifying customer support tickets as resolved or unresolved. The experiment was inspired by a customer, Pylon, who wanted to improve the accuracy of their existing classifier. The results showed that Gemini Pro was the best performing model, with an accuracy of 74% and an F1 score of 76.69%. Claude 2.1 had a high recall rate, while GPT-4 Turbo showed high precision. The document also discusses the challenges of the task, such as language variability and edge cases, and the importance of customizing prompts and avoiding overfitting. The authors suggest that the findings could be useful for all users of Language Learning Models (LLMs) and plan to further investigate the performance of the models and the potential benefits of fine-tuning a model using Pylon's classifier data.
###### 💡 Have in mind that summarization tasks are generally considered easy for most models nowadays, so Llama 3 70B should definitely be on your list for this task.
Task 3: Reasoning
From the standard benchmarks, we saw that Llama 3 70B still didn’t catch up to GPT-4 on reasoning tasks. So we’ll run a small test to see how they actually compare.
We picked a set of seven verbal reasoning questions and seven more arithmetic reasoning questions as the cornerstone of the test.
Here are a couple of example riddles and their sources :
🗣️ Verbal reasoning question: 1. Choose the word that best completes the analogy: Feather is to Bird as Scale is to _______. A) Reptile B) Dog C) Fish D) Plant Answer: Reptile 🧮 Arithmetic reasoning question: 3, 6, 11, 18, 27, ?, 51 Answer: 38
Below is a screenshot on the initial test we ran in our prompt environment in Vellum:
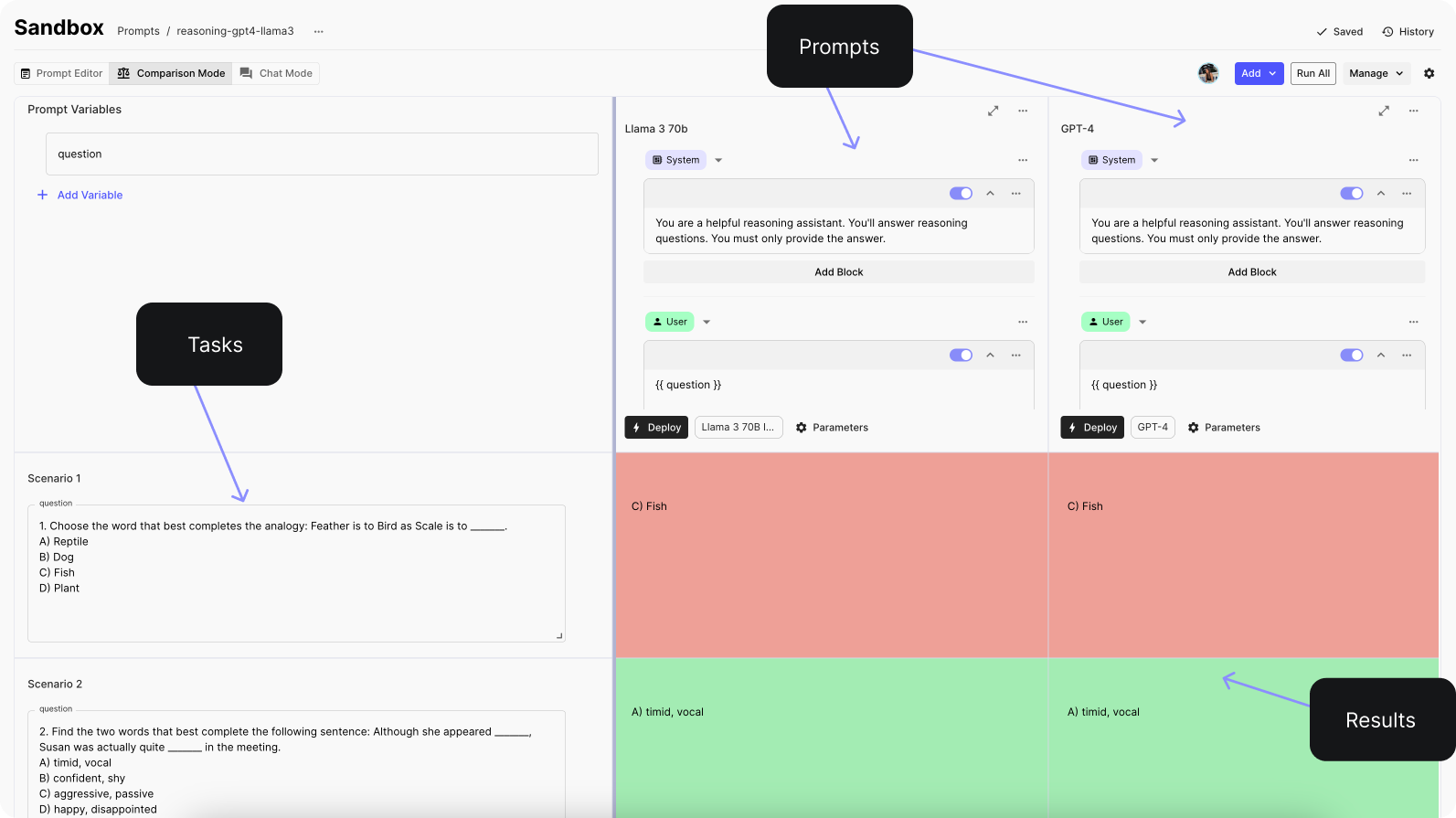
Now, let’s run the evaluation across all 14 reasoning questions.
In the image below, you can see that both models did poorly on almost all verbal reasoning questions. However, they performed similarly on the arithmetic reasoning questions, with GPT-4 having just one more correct answer than Llama 3 70B.
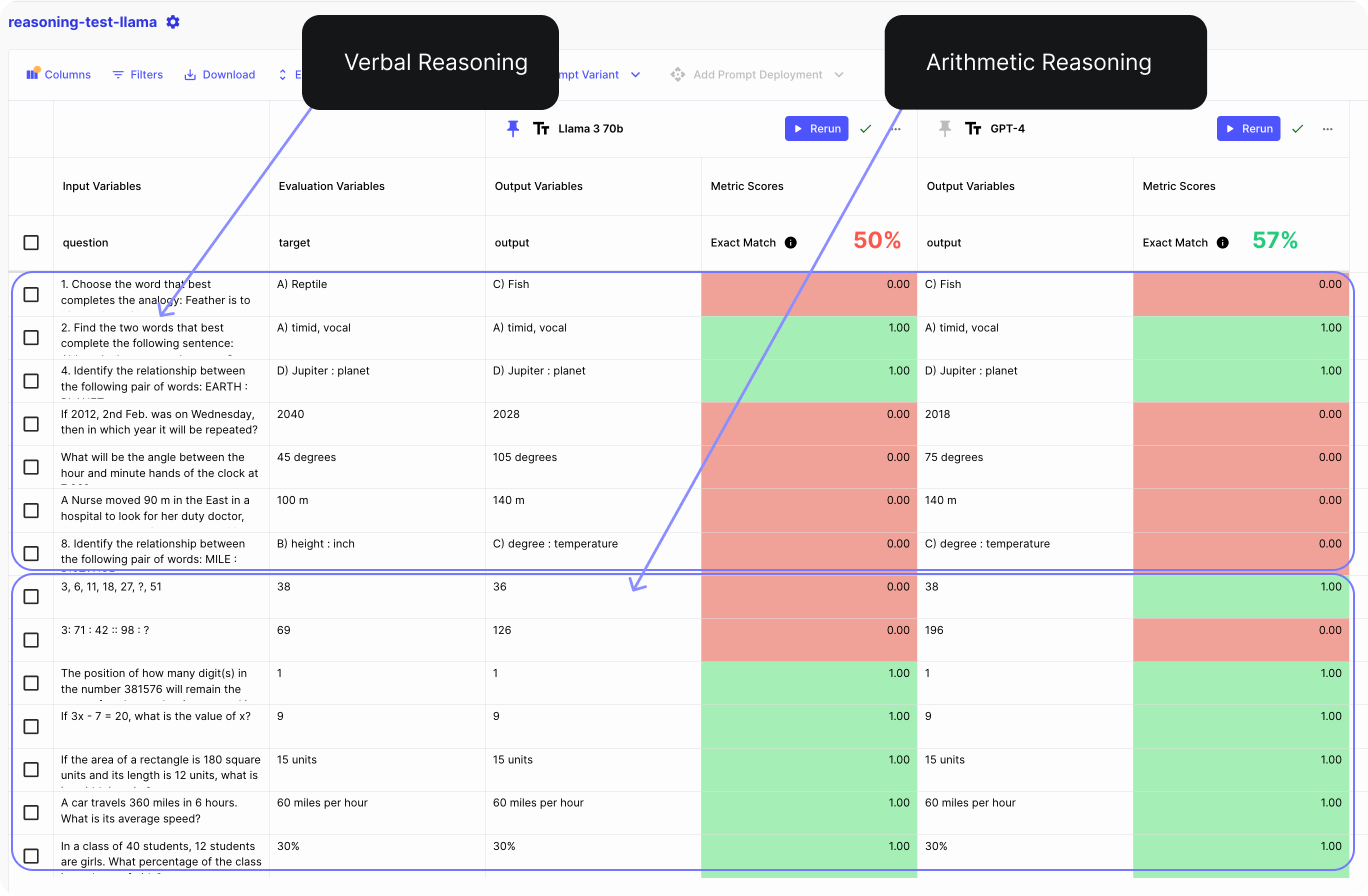
Key takeaways:
Both Llama 3-70B and GPT-4 are good at arithmetic reasoning tasks, so given the cost you can easily use Llama 3-70B for this task. Both models aren’t good at verbal reasoning tasks. This performance can be greatly improved by incorporating few-shot or CoT prompting (Chain of Thought prompting).
Other insights:
Reddit users report that LLaMA-3 70B can perform much better in logical reasoning with a task-specific system prompt;
Safety and Privacy
Below we share insights on how OpenAI and Meta are making their models secure and safe to use.
GPT-4 Safety
To enhance GPT-4's safety, OpenAI worked with experts to perform adversarial testing, improved data selection, and incorporated a safety reward signal during training to reduce harmful output. These measures significantly reduced the model's tendency to produce harmful content by 82% compared to GPT-3.5 and improved its compliance with safety policies in responding to sensitive requests by 29%.
Llama 3 70B Safety
Meta says that it developed new data-filtering pipelines to boost the quality of its model training data. They've also invested in a suite of tools to help with safety and hallucinations.
- Llama Guard 2 , LLM safeguard model that can classify text as "safe" or "unsafe”. It can be used for classifying content in both LLM inputs (prompt classification) and in LLM responses (response classification).
- Llama Code Shield , that can classify if a code is “secure” or “insecure”. This is extremely important as developers start to utilize LLMs to assist them in writing code, there is a risk that insecure code is generated and included in production. Here’s a sample workflow on how to use it.
- CyberSec Eval 2 , that lets you evaluate how safe an LLM is (you can use this tool to evaluate any LLM).
Prompting Tips for Llama 3 70B
When it comes to prompting Llama 3 70B, the same prompts from GPT-4 should work well. Generally, this model doesn’t require over-engineered prompts, and is able to follow instructions better. Writing clear and concise prompts will enable the model to accurately follow your instructions.
Using advanced prompting techniques like few-shot and chain of thought prompting can greatly help with reasoning tasks.
Some people have found that Llama 3 70B is extremely good at following format instructions, and writes the output without adding boilerplate text.
Summary
In this article we looked at standard benchmarks, we ran small scale experiments and looked at independent evaluations. Below is the summary of our findings.
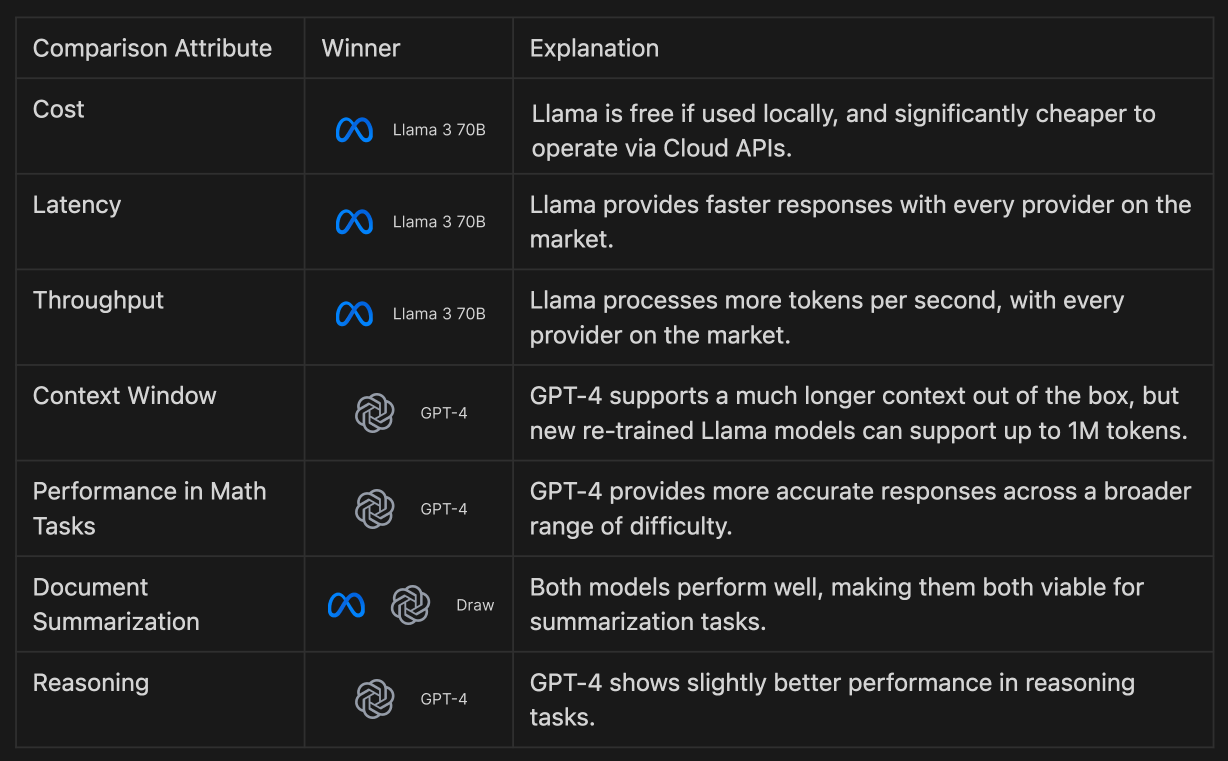
Key Takeaways:
Cost and Efficiency : Llama 3 70B is a more cost-effective, for tasks that require high throughput and low latency. Complex Tasks Handling : GPT-4 remains more powerful for tasks requiring extensive context and complex reasoning. General Usability : Both models are good at document summarization. Coding : Judging from data reported from the model providers, Llama 3 70B is better at Python coding tasks than GPT-4, but we’ll need to do an independent coding eval to confirm this. Context window: New models have expanded Llama-3 8B's token capacity from 8K to up to 1 million tokens. This means the current context window won't be an issue for much longer.
If you want to compare these models using Vellum's prompt engineering sandbox, book a demo here.
Conclusion
Meta’s Llama 3 models are showing the world that open-source models can reach the higher ranks of performance previously dominated by proprietary models.
As companies start to develop more complex AI workflows, developers will look for options that are cheaper, more flexible, and faster. The current cost and speed of GPT-4 might not make sense for much longer.
GPT-4 still has advantages in scenarios that need longer context or special features like image support and function calling. However, for many tasks, Llama 3 70B is catching up, and this is the worst that Llama 3 70B will ever gonna be.
The gap is closing.



