Our Approach
The main focus on this analysis is to compare Claude 3.5 Sonnet claude-3-5-sonnet-20240620 and the GPT-4o model.
We look at standard benchmarks, community-ran data, and conduct a set of our own small-scale experiments.
In the next two sections we cover:
Performance comparison (Latency, Throughput) Standard benchmark comparison (example: what is the reported performance for math tasks between GPT-4o vs GPT-4?) Three evaluation experiments (data extraction, classification and math reasoning)
You can skip to the section that interests you most using the "Table of Contents" panel on the left or scroll down to explore the full comparison between Claude 3.5 Sonnet and GPT-4o.
Performance Comparison
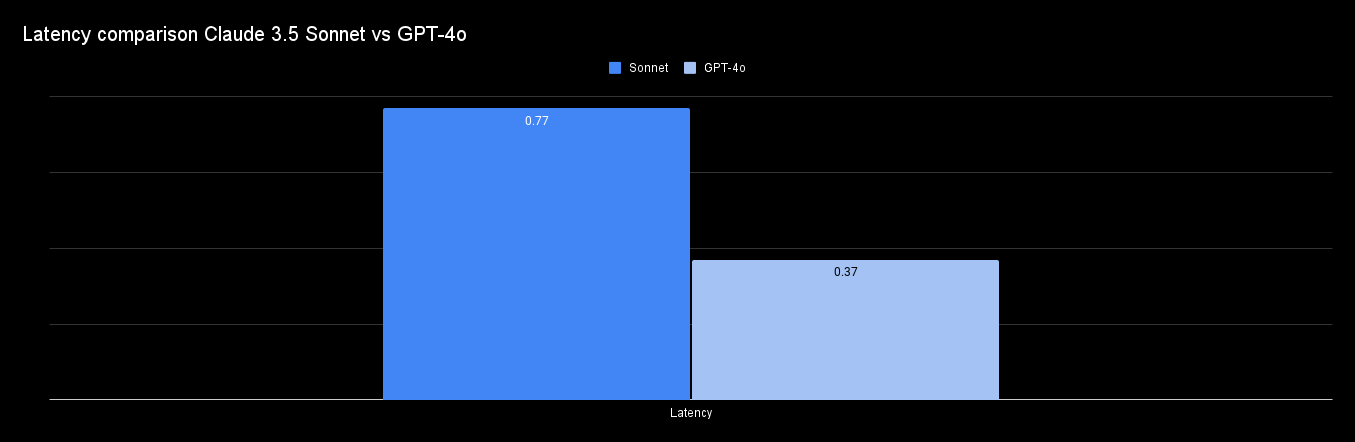
Latency Comparison
Claude 3.5 Sonnet is 2x faster than Claude 3 Opus, but it’s still lags behind GPT-4o when it comes to latency:
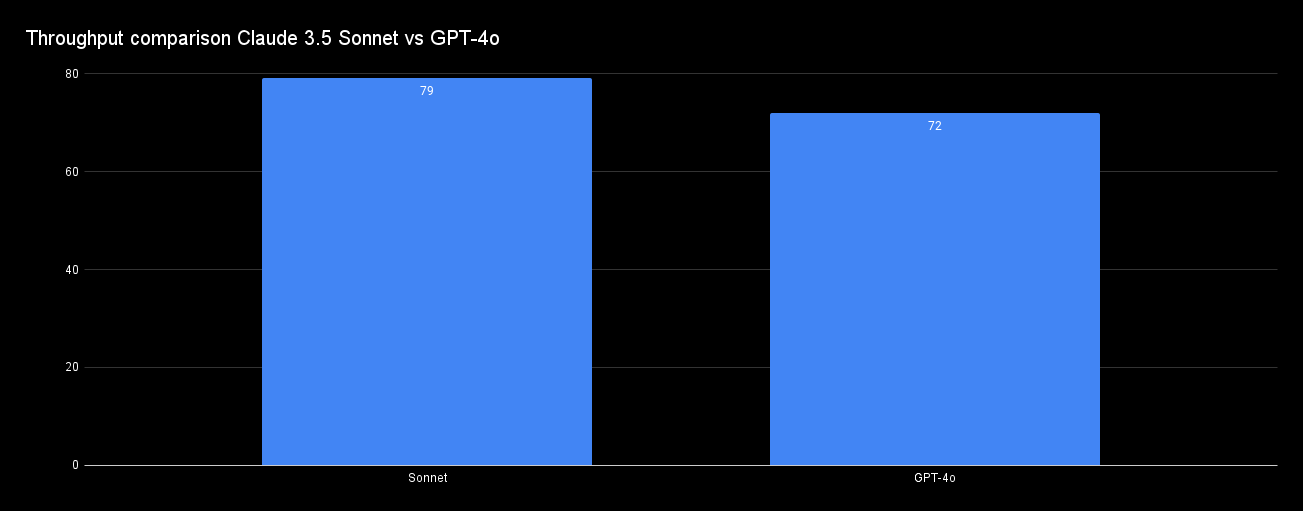
Throughput Comparison
We measure throughput by how many tokens can a model output per second. The throughput for Claude 3.5 Sonnet has improved approximately 3.43x from Claude 3 Opus which generated 23 tokens/second.
When it comes to GPT-4o, recent analysis shows that they both have nearly the same throughput. However, when GPT-4o was launched a month ago, it had ~109 tokens/second.
Reported Capabilities
When new models are released, we learn about their capabilities from benchmark data reported in the technical reports. The image below compares the performance of Claude 3.5 Sonnet on standard benchmarks against the top five proprietary models and one open-source model.
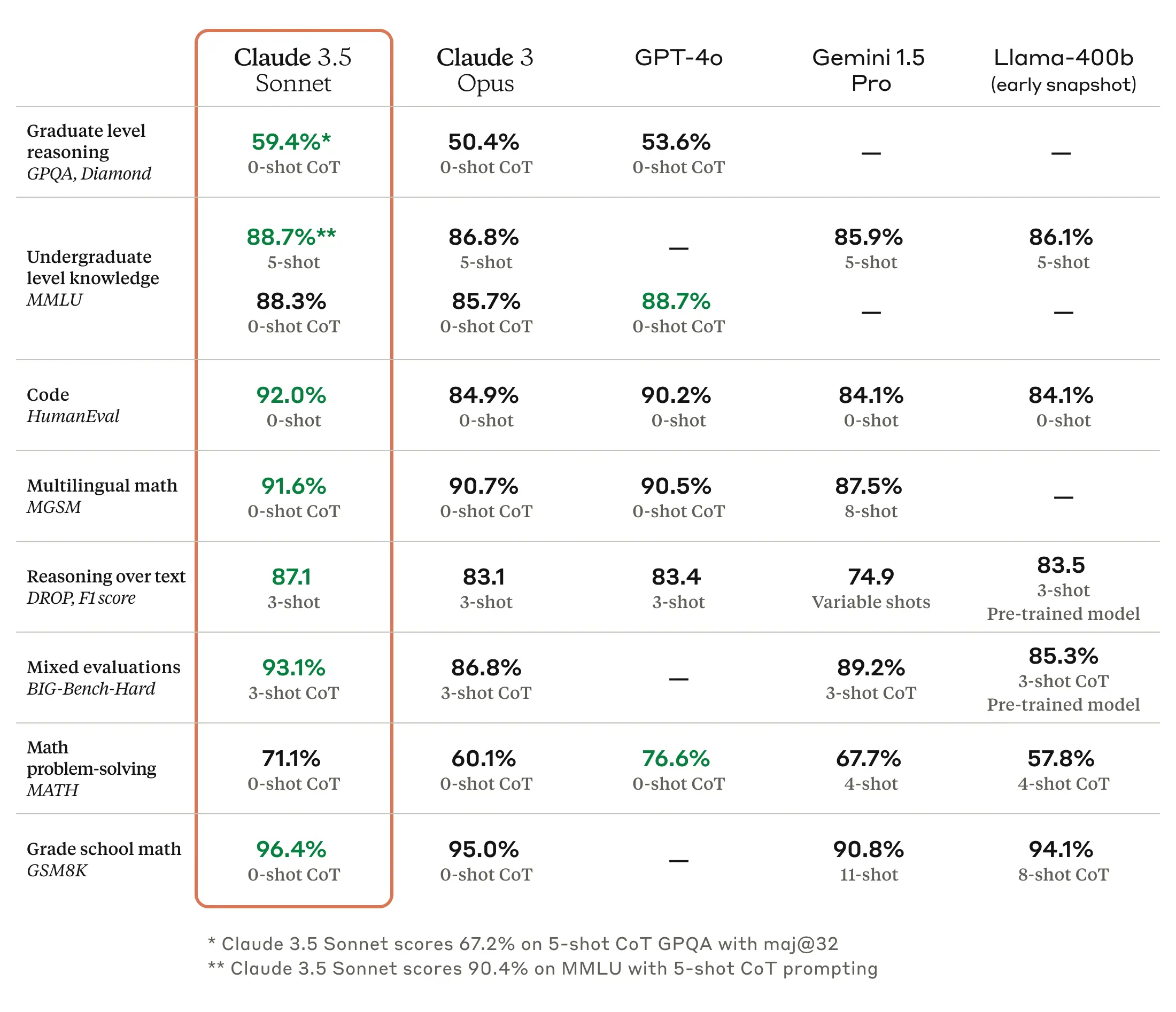
Here are a few takeaways from this table:
Claude 3.5 Sonnet excels in Graduate Level Reasoning, Undergraduate Level Knowledge, Code, followed by GPT-4o. Multilingual Math scores are highest for Claude 3.5 Sonnet (91.6%), with Claude 3 Opus in second (90.7%). Claude 3.5 Sonnet outperforms in Reasoning Over Text (87.1%), with Llama-400b in second (83.5%).
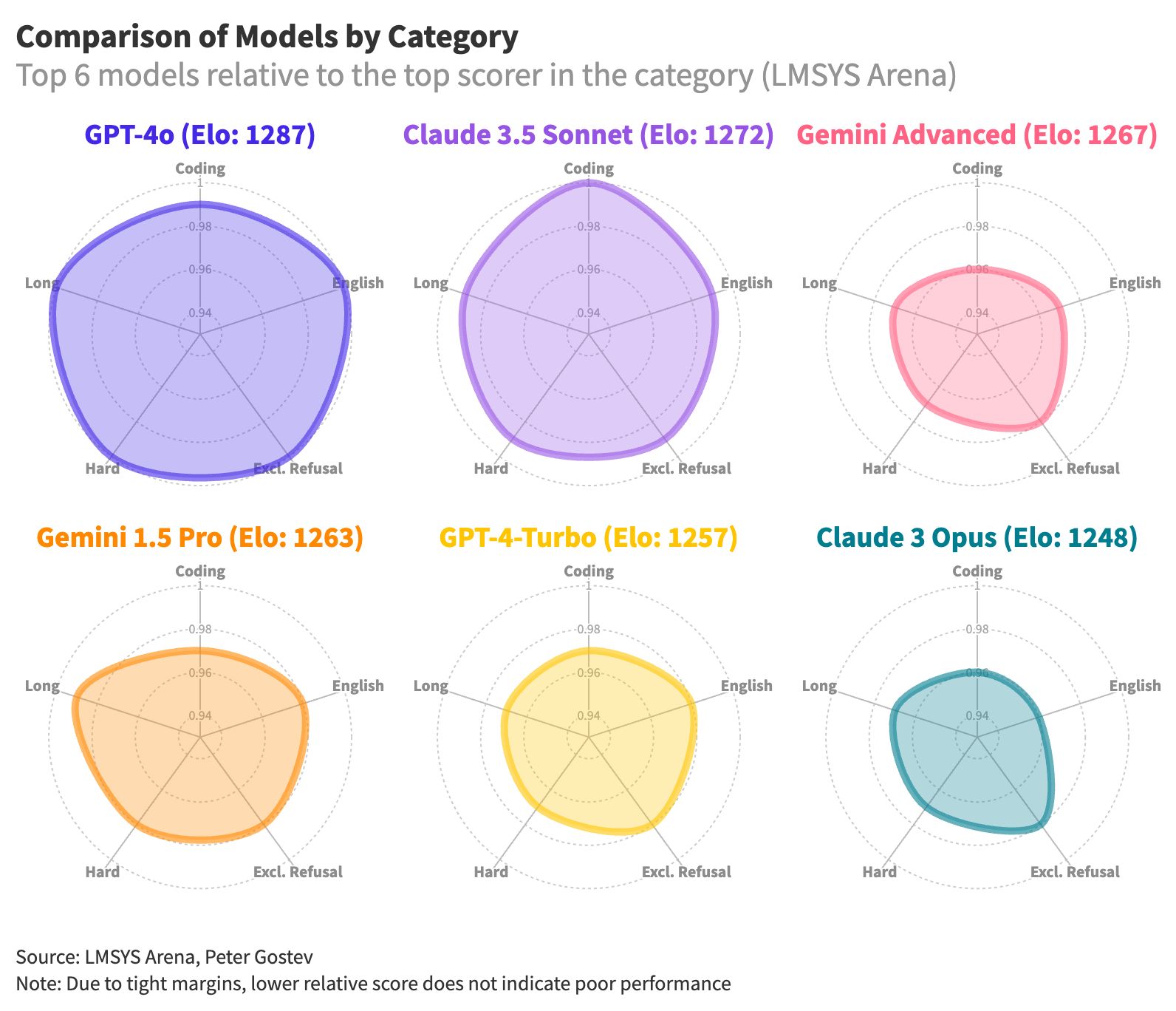
ELO Leaderboard
The ELO Leaderboard rankings have been revealed, and GPT-4o still has the top spot.
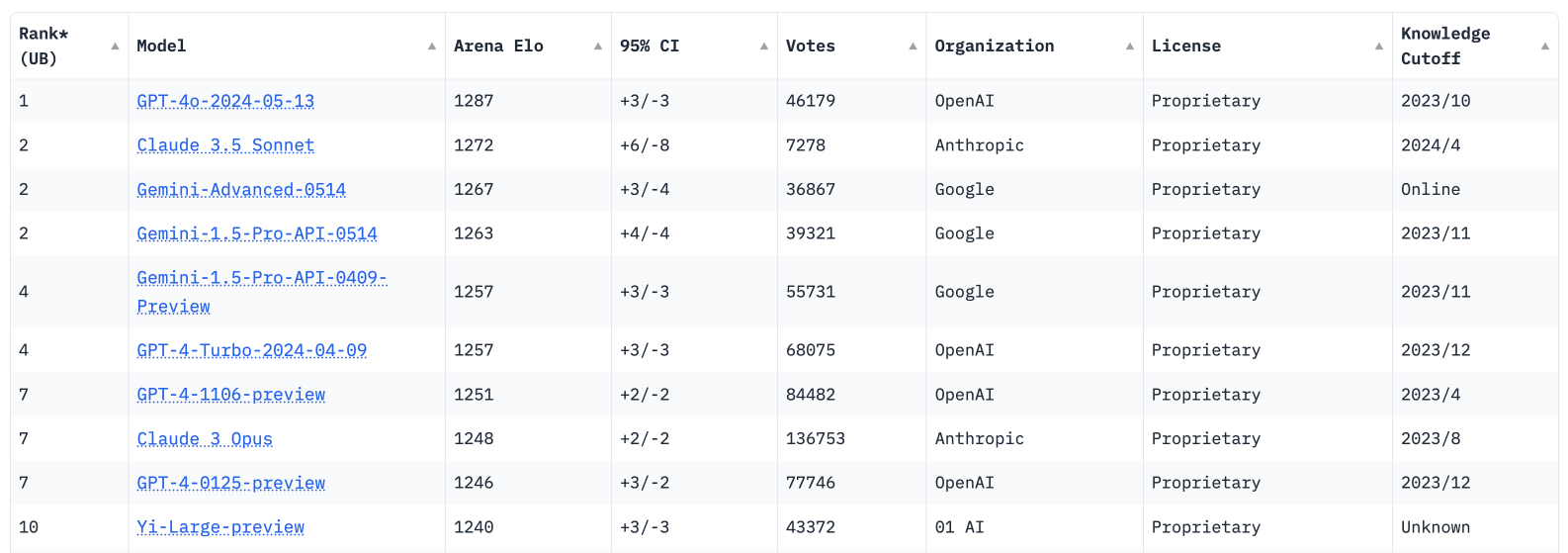
This public ELO leaderboard is part of the LMSYS Chatbot Arena. The chatbot arena allows you to prompt two anonymous language models, vote on the best response, and then reveal their identities.
Besides the overall score, let's examine the performance of these models in each category. Sonnet didn't surpass GPT-4o in most areas, but it did score the highest in coding—a notable achievement considering it's not the largest model in the Claude 3 family.
Benchmarks and crowdsourced evals matter, but they don’t tell the whole story. To really know how your AI system performs, you must dive deep and evaluate these models for your use-case.
Now, let’s compare these models on three tasks that might be useful for your project.
Task 1: Data extraction
For this task, we’ll compare Claude 3.5 Sonnet and GPT-4o’s ability to extract key pieces of information from legal contracts. Our dataset includes Master Services Agreements (MSAs) between companies and their customers. The contracts vary in length, with some as short as 5 pages and others longer than 50 pages.
In this evaluation we’ll extract a total of 12 fields like Contract Title, Name of Customer, Name of Vendor, details of Termination Clause, whether Force Majeure was present or not etc.
You can check our original prompt and the JSON schema we expected the model to return:
You're a contract reviewer who is working to help review contracts following an Merger & Acquisition deal. Your goal is to analyze the text provided and return key data points, focusing on contract terms, risk, and other characteristics that would be important. You should only use the text provided to return the data. From the provided text, create valid JSON with the schema: { contract_title: string, // the name of the agreement customer: string, // this is the customer signing the agreement vendor: string, // this is the vendor who is supplying the services effective_date: date, // format as m/d/yyyy initial_term: string, // the length of the agreement (ex. 1 year, 5 years, 18 months, etc.) extension_renewal_options: string, // are there extension or renewal options in the contract? automatic_renewal: string, // is this agreement set to automatically renew? termination_clause: string, // the full text in the contract containing information about how to terminate the agreement termination_notice: string, // the number of days that must be given notice before the agreement can be terminated. only include the number. force_majeure: string, // is there a clause for force majeure present in the agreement? force_majeure_pandemic: string, // does force majeure include reference to viral outbreaks, pandemics or epidemic events? assignment_allowed: string, // is there language specifying whether assignment is allowed? answer in only one sentence. jurisdiction: string, // the jurisdiction or governing law for the agreement (ex. Montana, Georgia, New York). if this is a state, only answer with the name of the state. } Contract: """ {{ contract }} """
We gathered ground truth data for 10 contracts and used Vellum Evaluations to create 14 custom metrics. These metrics compared our ground truth data with the LLM's output for each parameter in the JSON generated by the model.
Then, we tested Claude 3.5 Sonnet and GPT-4o using Vellum’s Evaluation suite:
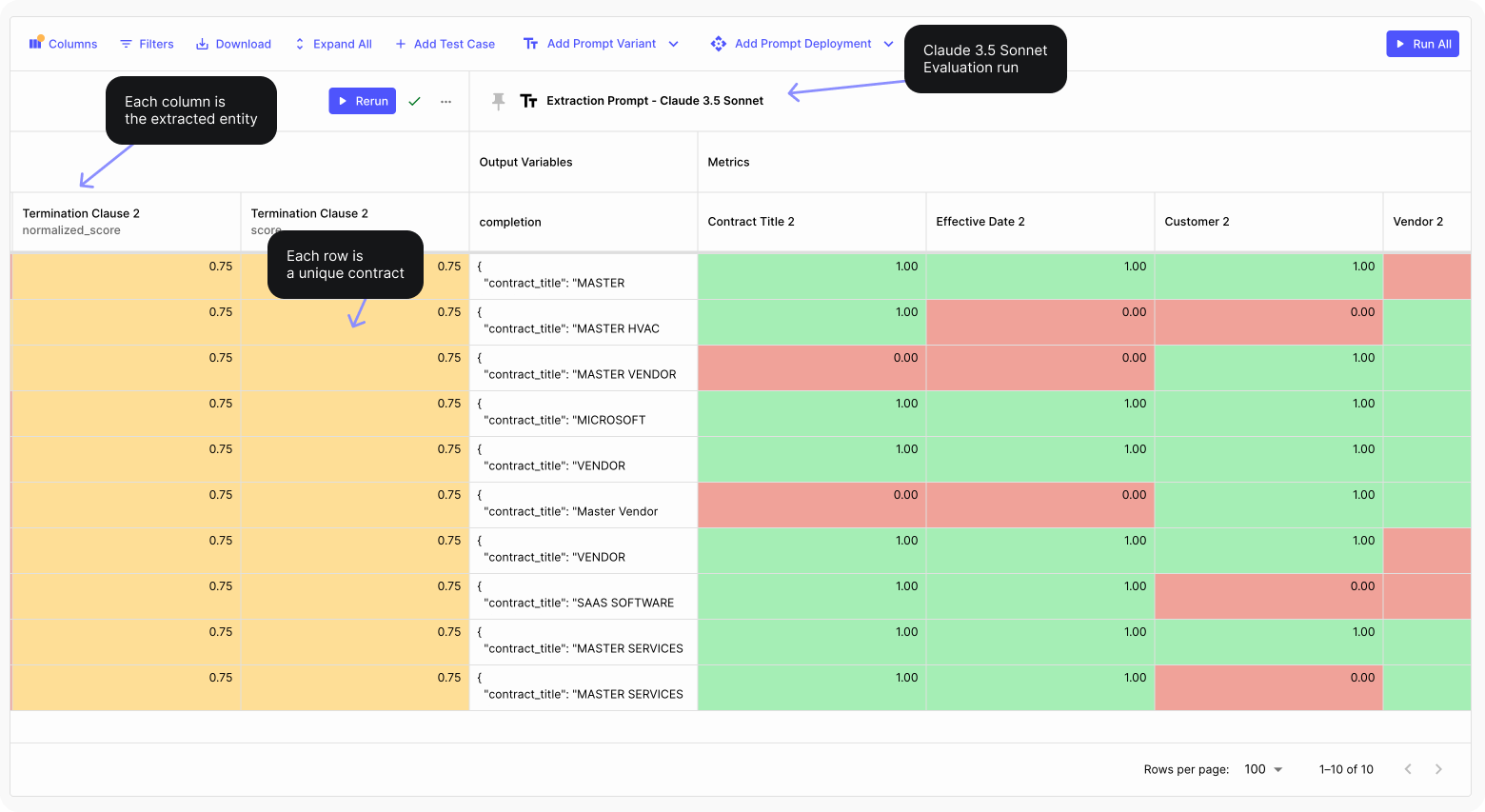
Then we compared how well each model extracted the correct parameters, by looking at the absolute and relative mean values for each entity, using Evaluation Reports:
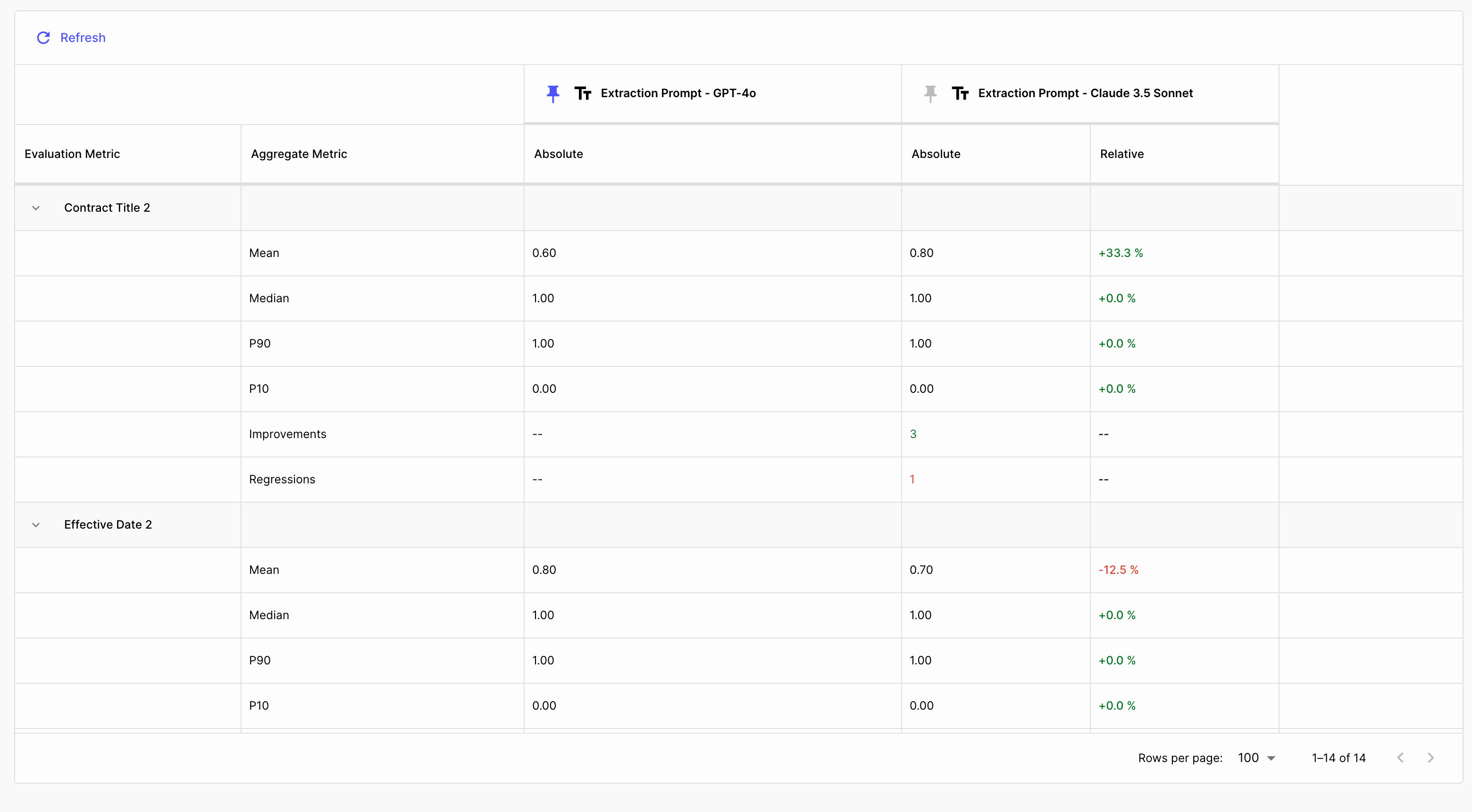
Here’s what we found:
GPT-4o outperformed Claude 3.5 Sonnet on 5 of the 14 fields, maintained similar performance on 7 fields and showed degraded performance on 2 fields. From an absolute perspective, both Claude 3.5 Sonnet and GPT-4o only identified 60-80% of data correctly in most fields. For a complex data extraction task where accuracy is important both models fall short of the mark, indicating that advanced prompting techniques like few-shot or chain of thought prompting are still necessary.
Winner: GPT-4o is performing better, but both models fail short of the mark for this data extraction task.
##### Other evaluations from the community:
Hanane D. ran her own multi-modal evaluations for extracting data from financial reports, and Claude 3.5 Sonnet accurately extracted all information, even the most complicated parts of the chart. See her notebook here . It's possible that Claude 3.5 Sonnet with images can do a better job at data extraction than GPT-4o, that we yet need to test.
Task 2: Classification
In this evaluation, we had both Claude 3.5 Sonnet and GPT-4o determine whether a customer support ticket was resolved or not. In our prompt we provided clear instructions of when a customer ticket is closed, and added few-shot examples to help with most difficult cases.
We ran the evaluation to test if the models' outputs matched our ground truth data for 100 labeled test cases. For good measure we added GPT-4 and Claude 3 Opus to the mix.
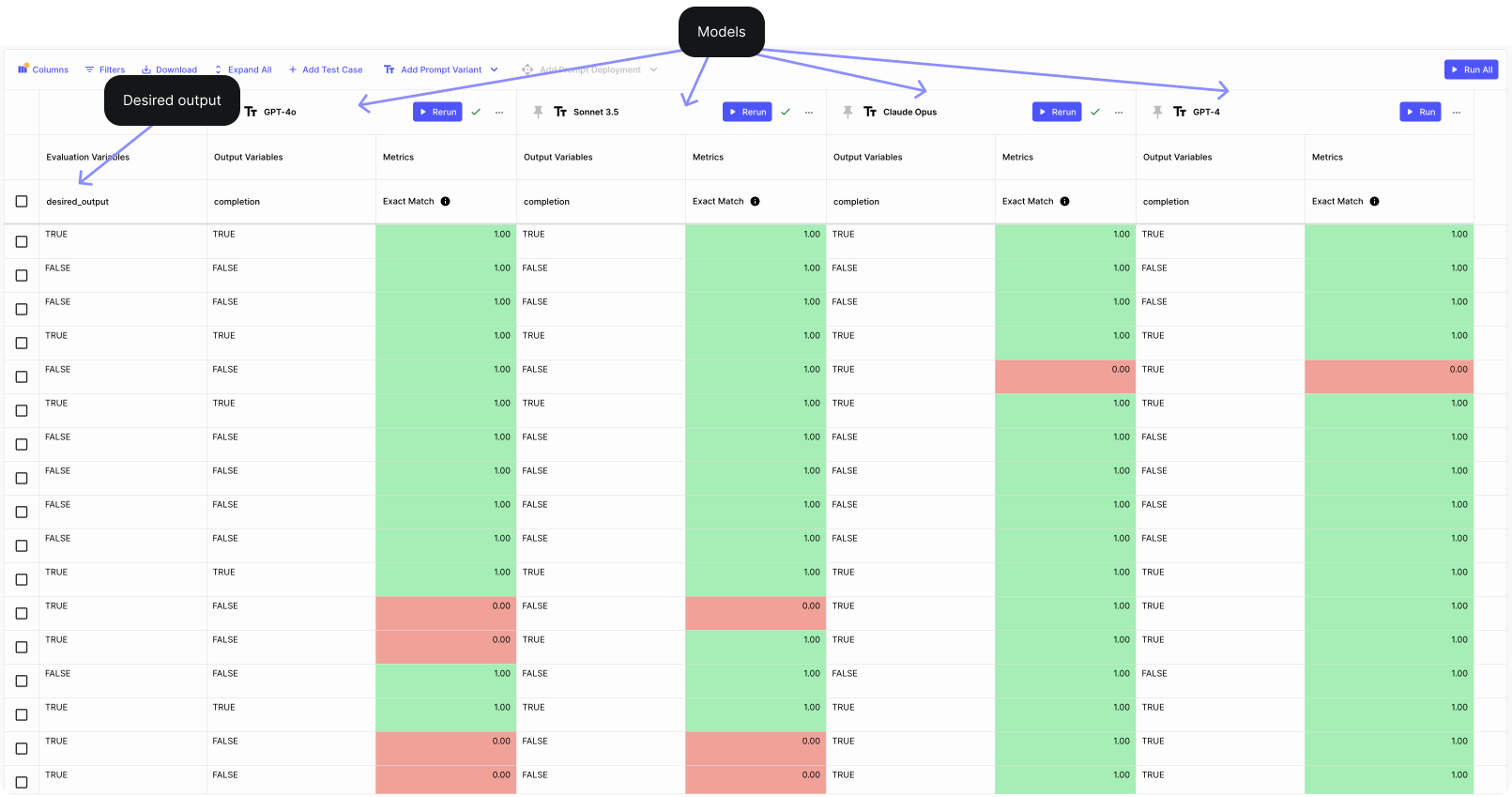
In the Evaluation Report below you can see how all models compare to GPT-4o:
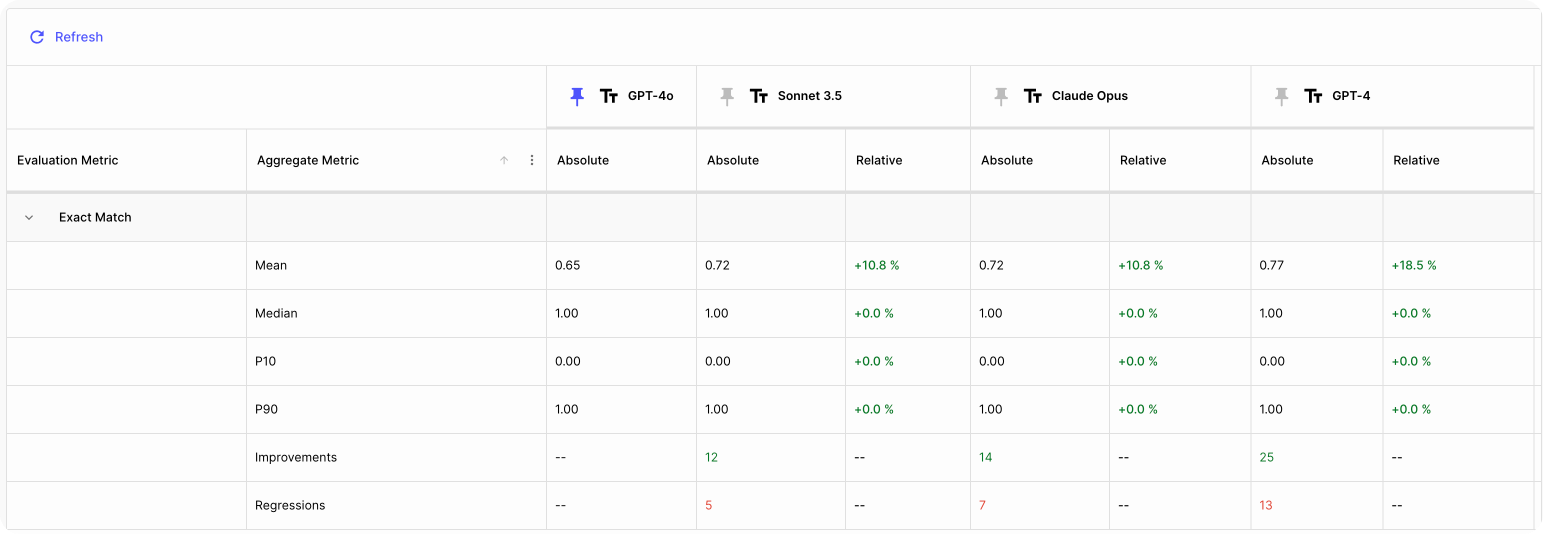
In the Evaluation Report above we compare Claude 3.5 Sonnet to GPT-4o. For good measure we compare GPT-4 and Claude 3 Opus against GPT-4o as well.
We can see from the report that:
Accuracy Comparison: Claude 3.5 Sonnet (0.72) does better than GPT-4o (0.65), but GPT-4 has the highest mean absolute score (0.77) when it comes to accuracy. Regressions: Despite the overall better performance, Claude 3.5 Sonnet has 5 specific cases where it performs worse than GPT-4o, showing that the model introduced issues in certain areas. However, there are not very significant. Improvements: We do see that Claude 3.5 Sonnet shows 12 improvements compared to GPT-4o, which signals that more improvements were achieved than regressions. More research & working with the prompt is needed here to eliminate the regressions but maintain these improvements. GPT-4 however had the most improvements when compared to GPT-4o.
Accuracy is important but not the only metric to consider, especially in contexts where false positives (incorrectly marking unresolved tickets as resolved) can lead to customer dissatisfaction.
So, we calculated the precision, recall and f1 score for these models:
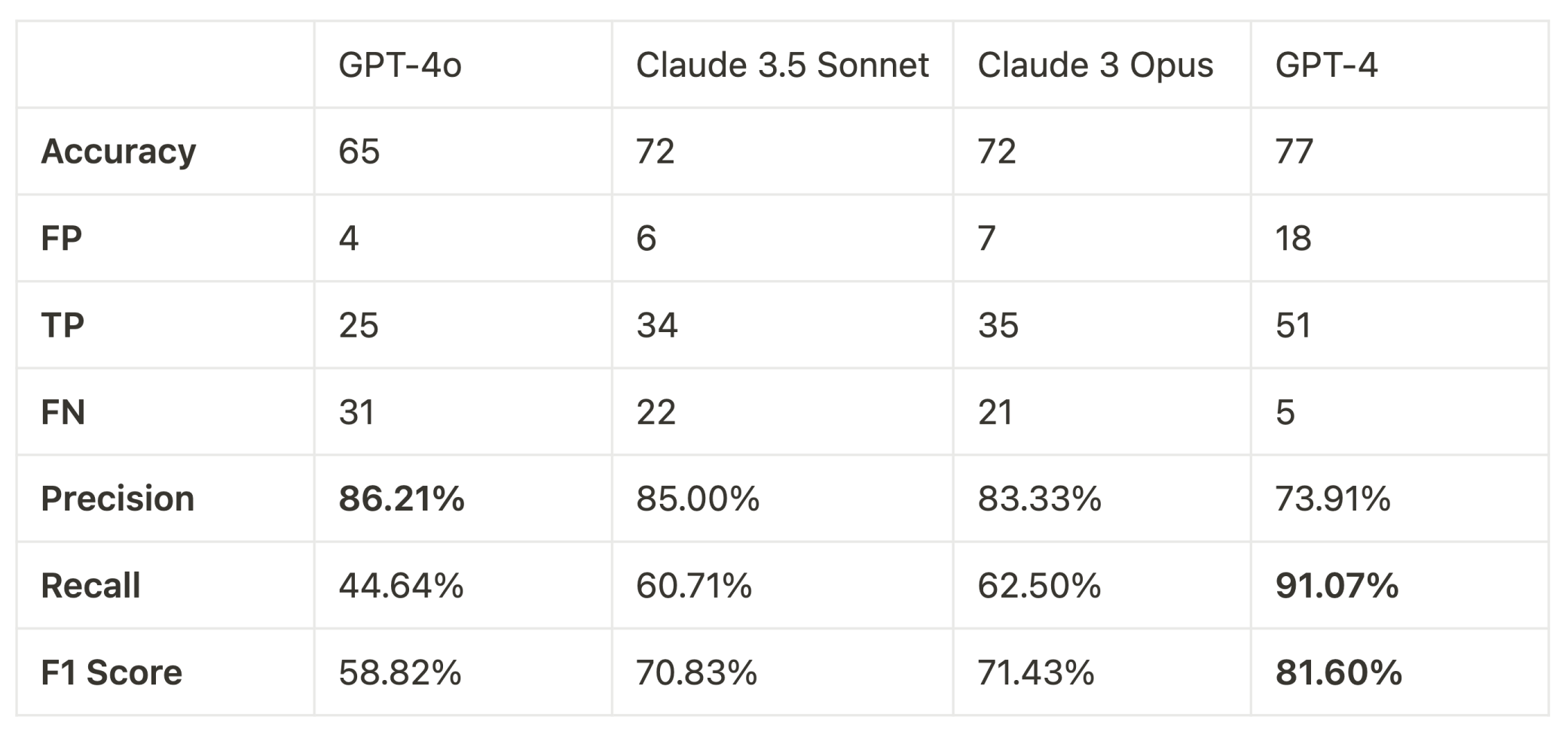
Key takeaways:
GPT-4o has the highest precision at 86.21%, indicating it is the best at avoiding false positives. This means when GPT-4o classifies a ticket as resolved, it is more likely to be accurate, thus reducing the chance of incorrectly marking unresolved tickets as resolved. Claude 3.5 Sonnet is climbing the ranks for precision, with 85%, and a good alternative for GPT-4o.
Winner: GPT-4o has the highest precision across the board (86.21%), and GPT-4 offers the best overall reliability with F1 score at 81.60%.
💡 Have in mind that prompting techniques can help increase these numbers. We can manually analyze the misclassified scenarios, and use those insights to prompt the model better. When it comes to AI development it’s all about iterative improvements.
##### Other evaluations from the community:
Nelson Auner and his team ran their own evaluations for their Banking Task Benchmark which measures the ability to correctly categorize customer support inquiries using zero-shot (0S), few-shot (FS), or cleanlab-curated few-shot (FS*) examples from a messy training dataset. The improvement over GPT-4o is slight but consistent.
Task 3: Reasoning
GPT-4o is the best model for reasoning tasks — as we can see from standard benchmarks and independently ran evaluations.
But, how does Claude 3.5 Sonnet compare?
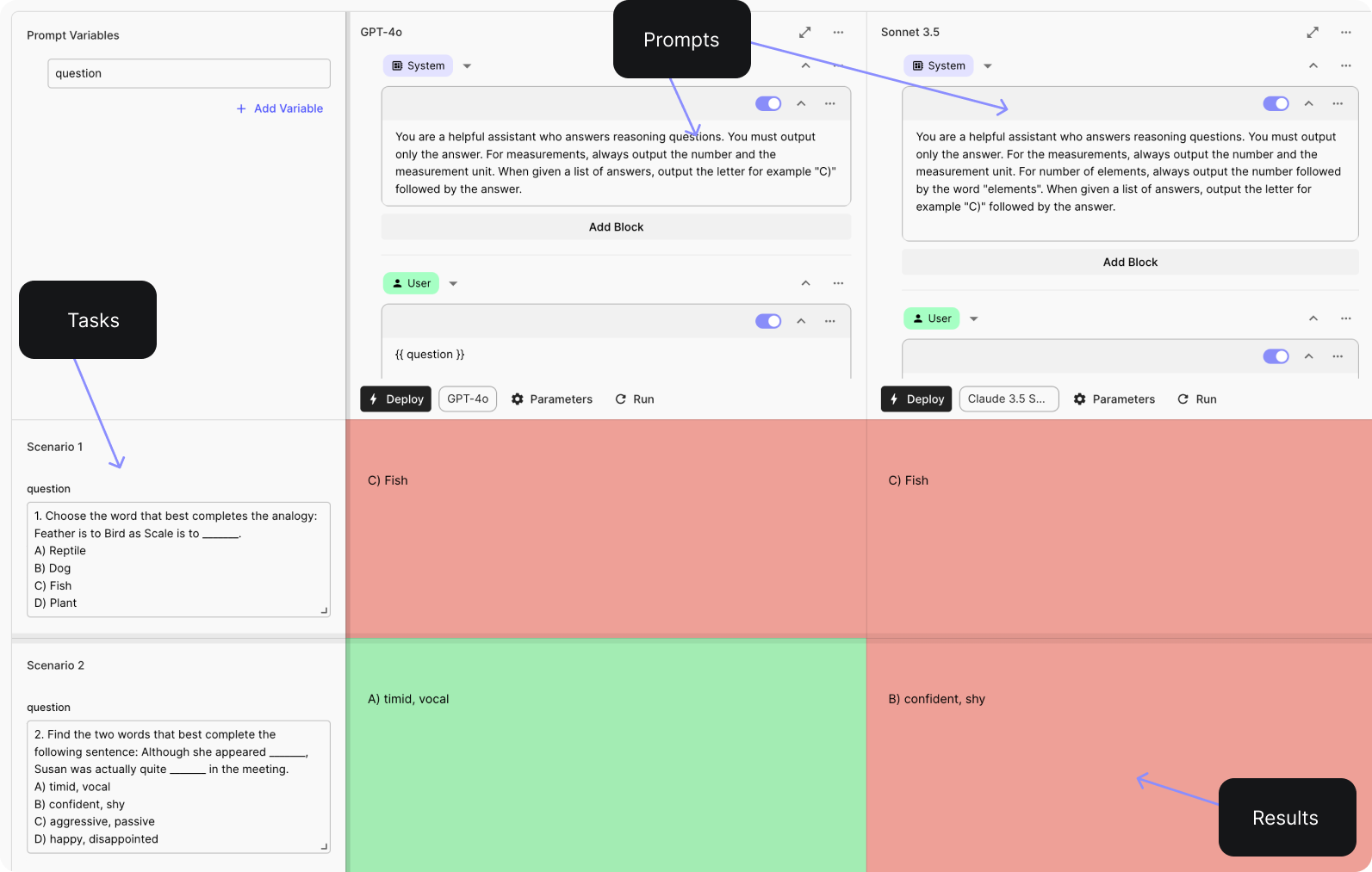
To find out, we selected 16 verbal reasoning questions to compare the two. Here is an example riddle and its source :
💡 Verbal reasoning question: 1. Choose the word that best completes the analogy: Feather is to Bird as Scale is to _______. A) Reptile B) Dog C) Fish D) Plant Answer: Reptile
Below is a screenshot on the initial test we ran in the prompt engineering environment in Vellum:
Now, let’s run the evaluation across all 16 reasoning questions:
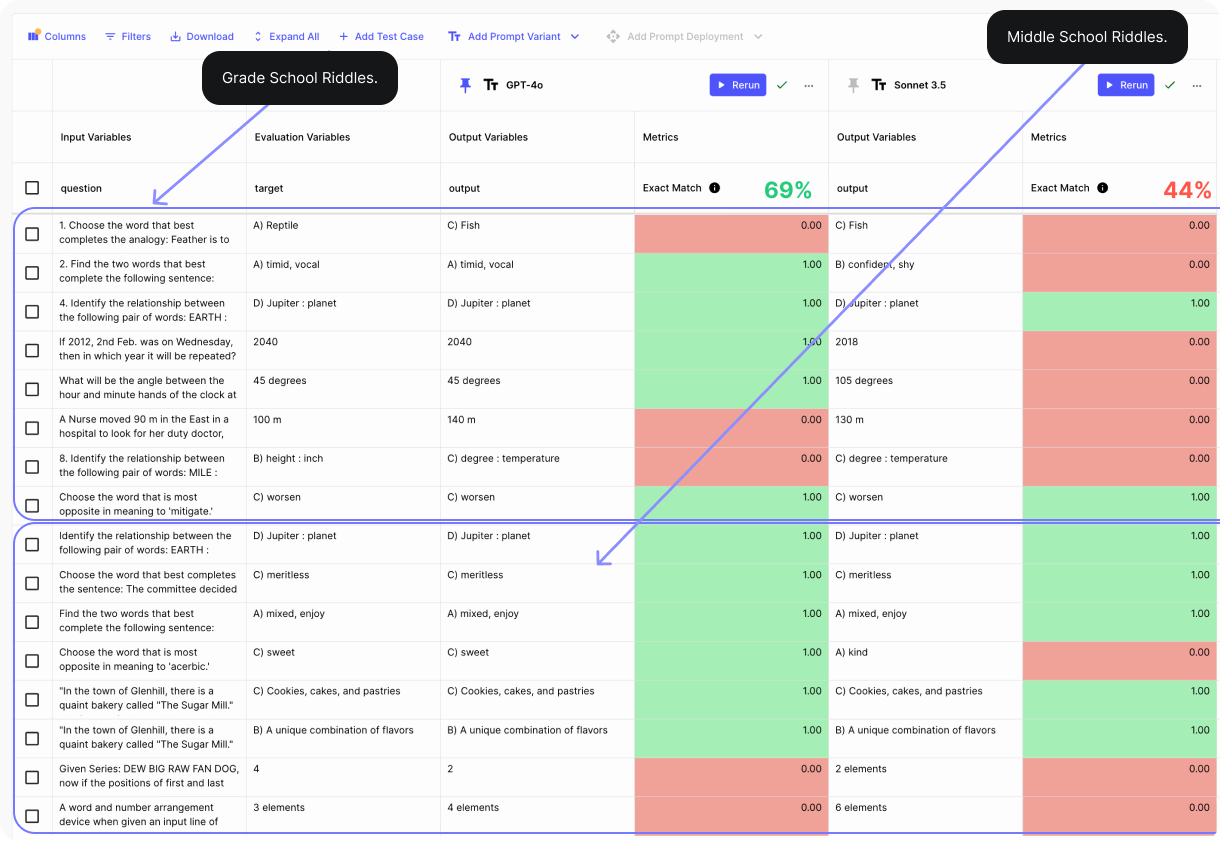
From the image above we can see that:
GPT-4o outperformed Claude 3.5 Sonnet with 69% accuracy, versus 44%. Claude 3.5 Sonnet struggles with Grade School Riddles, and is not a reliable model for those tasks. Both models did well on analogy and relationship questions. GPT-4o does really well on identifying word relationships and finding opposites but struggles with numerical and factual questions. Claude 3.5 Sonnet does well on analogy questions but struggles with numerical and date-related questions.
Winner: GPT-4o is the absolute winner here.
Summary
Below is a summary table of all insights from this analysis:
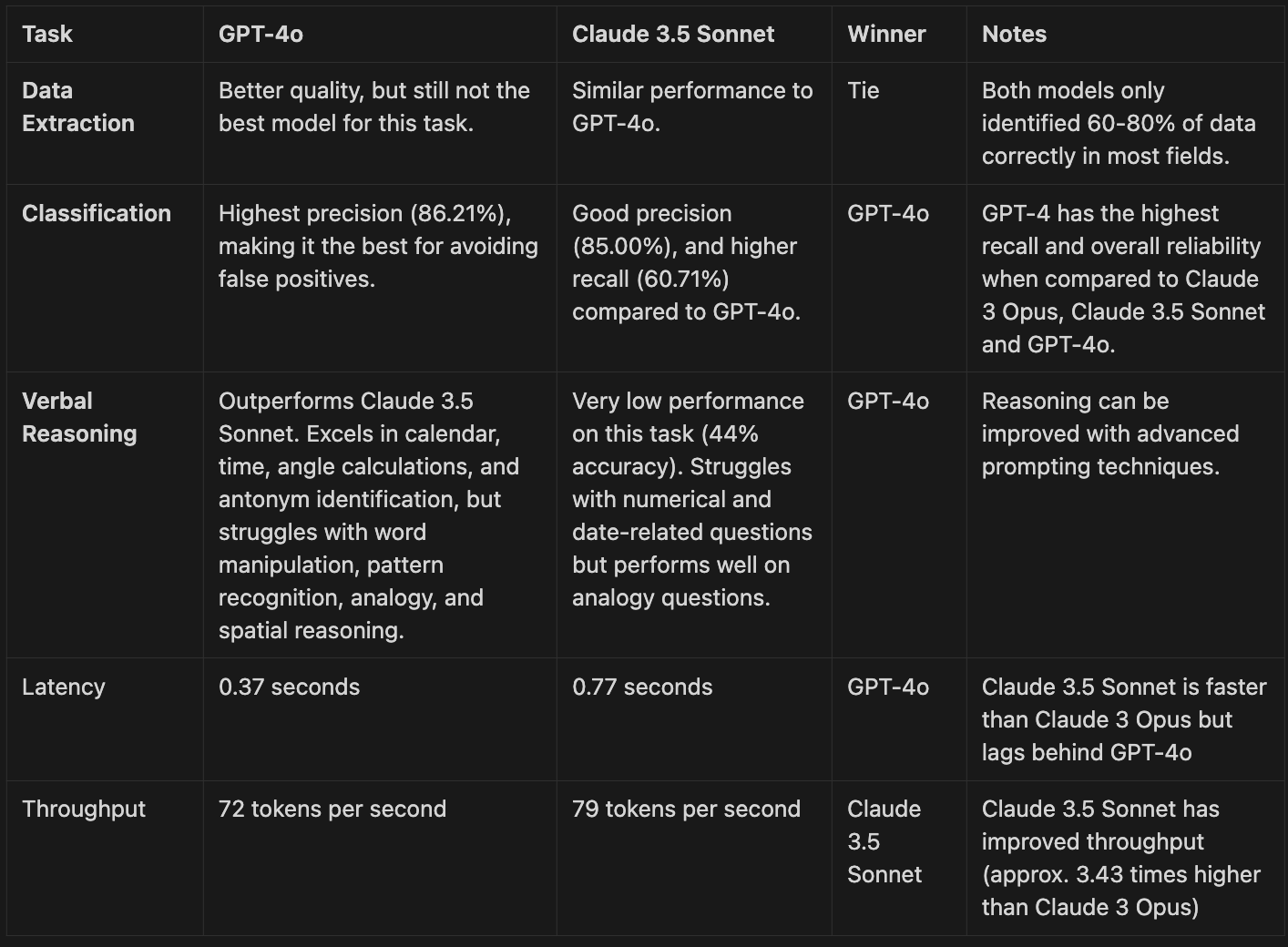
Conclusion
While GPT-4o leads in most areas, further evaluation and prompt testing on your specific use case is essential to fully understand the capabilities of these models. Building production-ready AI systems requires careful trade-offs, meticulous architecture, prompt curation, and iterative evaluation.
To try Vellum and evaluate these models on your tasks, book a demo here.



