If you follow news from major model providers, you've likely noticed a trend: longer context windows.
Google recently announced that Gemini 1.5 Pro now supports a staggering 2-million token context window. Other providers are also advancing, with Anthropic’s Claude 3 model family supporting a 200K token window and OpenAI’s GPT-4o supporting 128K tokens.
Long-context prompts are vital for specific use-cases, but maintaining coherence is tough. This highlights the need for better prompting techniques.
In this article, we’ll explore one such technique: Corpus-In-Context (CiC) prompting.
According to new research by Google, long-context prompts that adopt the CiC format, can dramatically improve text, audio and video data retrieval accuracy.
In one test, CiC prompting improved retrieval accuracy by 21% on online forum questions compared to traditional RAG pipelines — proving it can be a game-changer for improving long prompts.
What is Corpus-in-Context (CiC) prompting?
Corpus-in-Context (CiC, pronounced "seek") is a new prompting format that helps LLM models understand, reason, and find information in long prompts (128K+ tokens).
This prompting method was rigorously evaluated by Google Deepmind on a few different tasks, and showed impressive results for content creation, summarization, or paraphrasing large documents.
Let’s look at how you can design a CiC prompt.
Formatting a CiC Prompt
Imagine you're working on a document analysis workflow. At a certain point in the workflow, you decide not to use a vector retrieval component. Instead, you want to write a longer prompt to analyze a specific set of documents from upstream tasks.
Write this prompt poorly, and you risk having a model that can't follow instructions or find the right information.
For long-context prompts, formatting matters a lot more, and the proposed Corpus-In-Context (CiC) prompting seems like a step in the right direction.
Let’s see how to structure an effective CiC prompt:

Instruction
Instructions come at the top, giving the model clear guidance on its task.
The basic formatting of this section includes:
What information will the model receive. What the model needs to do with the provided information.
Corpus The corpus comes as a second segment in this prompt, and should be carefully formatted.
It should contain all the background information and documents the LLM needs to answer the query. It should be presented in a structured manner with headers or labels to help the model easily identify different sections or types of information.
Insight: They found out that the model is able to locate the information better if the ID’s are sequential numeric instead of unique random alphanumeric ID. This specific structure of the corpus significantly impacts retrieval performance.
Examples
Examples demonstrate what a desired response format is, and improves task accuracy.
They found that performance increases as you add more examples: Increasing the number of examples improves the quality on the retrieval task, from 0.76 at zero-shot to 0.81 at 5-shots.
You can use a “few-shot” or “many-shot” approach, i.e. providing either a few or many examples. Including more examples is not always helpful, as we’ll discuss later. Additionally, including chain-of-reasoning in your examples can be beneficial for tasks that require complex multi-hop compositional reasoning.
Insight: Unlike typical methods where few-shot examples are independent of the corpus, Google used examples grounded in the corpus to help the model learn better.model to also learn more details about the specific corpus it needs to use.
Query
Finally, they query is formatted similar to the few-shot examples:
With all of the above pieces in place, your long-context prompt for analyzing documents is now ready to go.
Model-Specific Considerations
It’s important to note here that different models may require different prompting techniques. While Google’s model achieves great performance with this specific format, you can further optimize your prompts depending on the model of your choice.
For example, Anthropic suggests putting the corpus before the instructions and using specific XML tags for documents. Google recommends using keywords like BEGIN and END to differentiate sections of your prompt. You should experiment with different approaches depending on what model you are using.
Results from Benchmarking
To evaluate the performance of long-context models using the CiC technique, Google developed the LOFT benchmark .
This benchmark generates reliable tests on real-world tasks requiring context up to millions of tokens, unlike other benchmarks, like the needle-in-haystack test.
Using LOFT, researchers evaluated three long-context models: Google’s Gemini 1.5 Pro, OpenAI’s GPT-4o, and Anthropic’s Claude 3 Opus. They compared each model's performance against a specialized model that has undergone extensive fine-tuning or pipelining for the target task. Tasks like content retrieval, RAG, SQL-like querying, and many-shot in-context learning (ICL) were evaluated.
A 128K context window size was used, as that is the window size supported across all three of the long-context models.
Below, we explore the results.

Cases Where CiC is Preffered
There are two types of situations where CiC outshines specialized models.
Retrieval
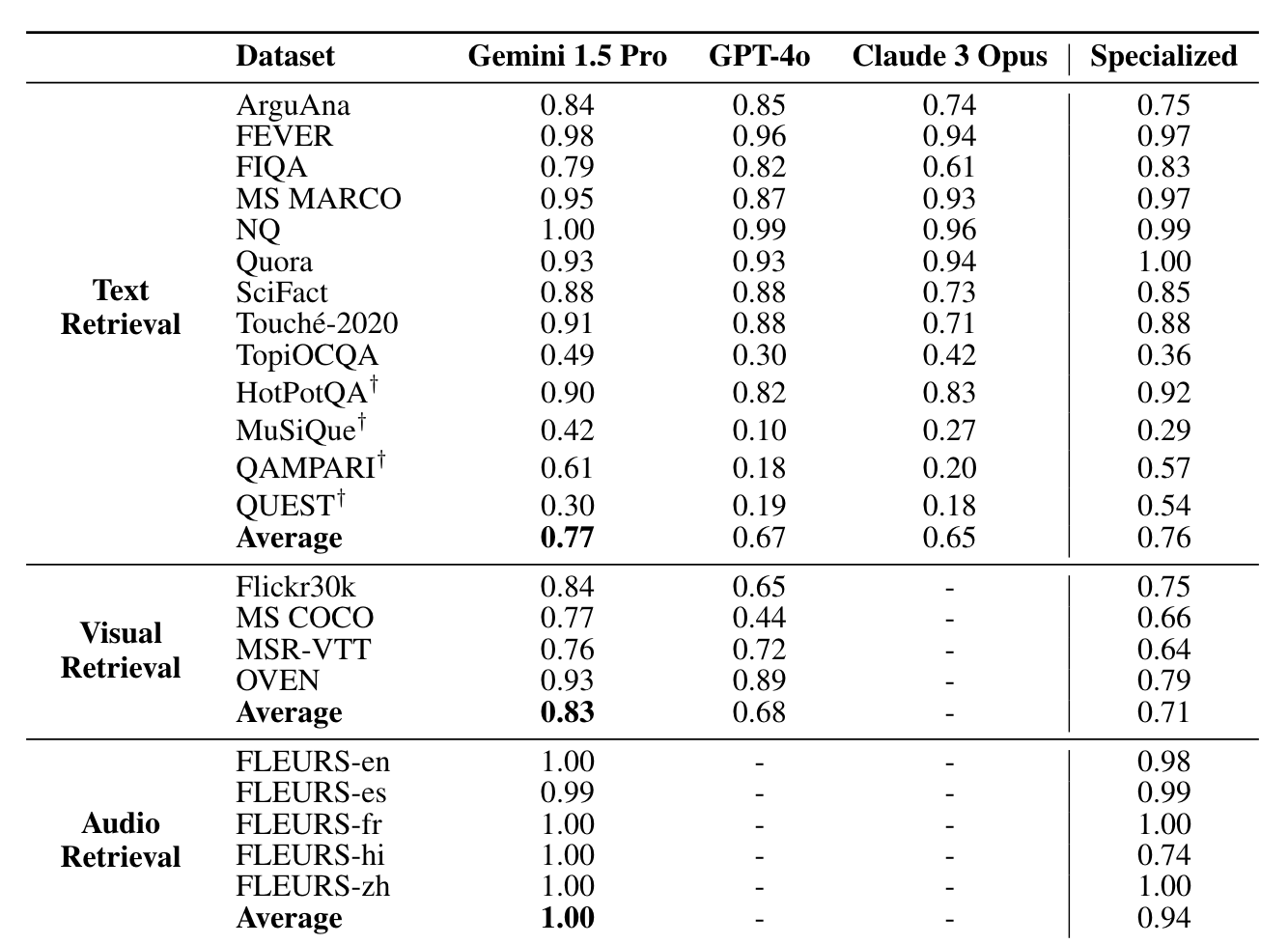
The researchers compared three long-context models with specialized models Gecko for text retrieval, CLIP-L/14 for visual retrieval, and PaLM 2 DE for audio retrieval.
Their results show that Gemini 1.5 Pro outperformed all other long-context models and specialized models across all tasks.
RAG
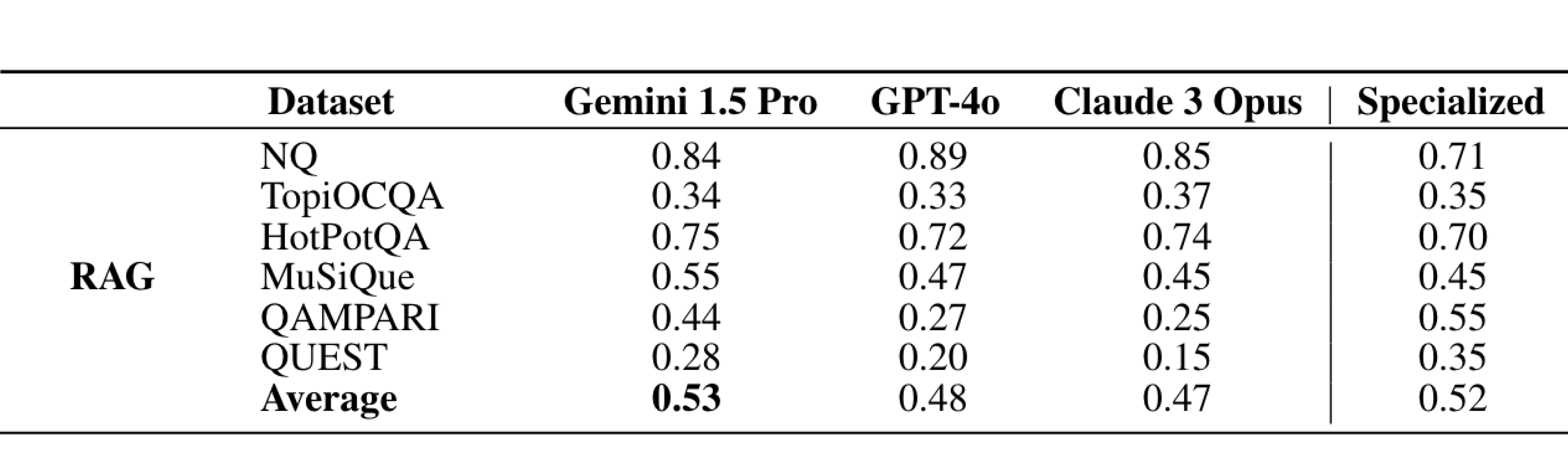
For this use-case, they created a RAG pipeline using Gecko to retrieve the top-40 documents, which were then used by Gemini 1.5 Pro to generate answers based on the question and retrieved documents.
Here are their results:
Performance : Gemini 1.5 Pro, with the entire corpus in context, outperformed the RAG pipeline on multi-hop datasets (HotpotQA and MusiQue) due to its ability to reason over multiple passages using Chain-of-Thought, which RAG pipelines typically lack. Specialized Retriever : Gecko excelled at ranking relevant passages from a corpus, beneficial for multi-target datasets like QUEST and QAMPARI.
Insight: LCLMs matched RAG performance at a 128k context length but showed a drop at 1M tokens, similar to their text retrieval performance drop.
Cases Where CiC is Limited
SQL-Like Reasoning
The SQL-like reasoning benchmark evaluated a model’s ability to process entire databases as text, enabling natural language querying without converting to a formal language like SQL.
Here, long-context models are significantly behind the specialized pipeline, which isn’t too surprising given the strong research into specialized SQL modeling. This shows there is a lot of room to improve the compositional reasoning capabilities of long-context models.

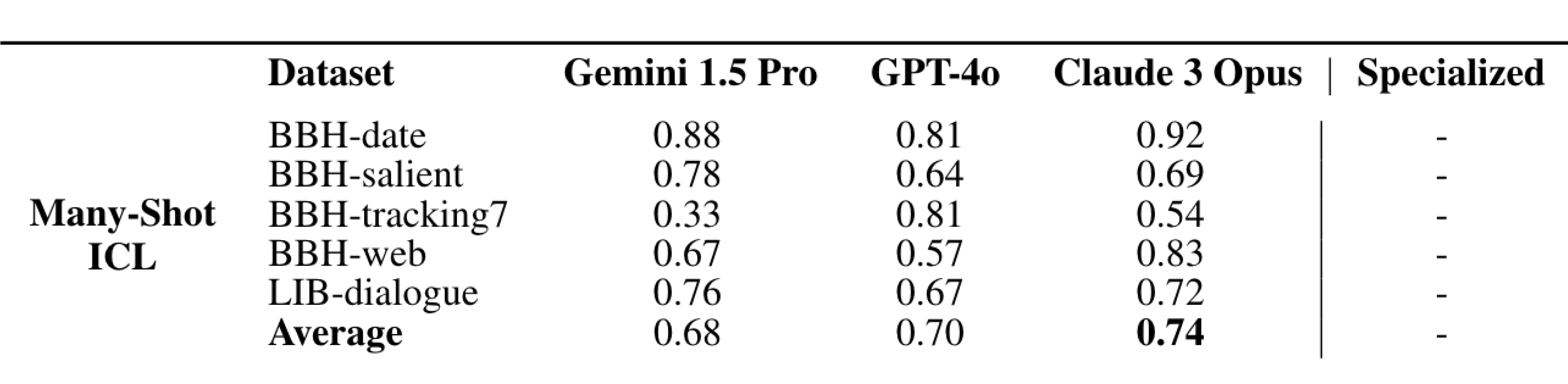
Many-Shot ICL
Many-shot in-context learning (ICL) involves providing a model with numerous examples within the input context to improve its performance on a given task. Here, Claude 3 Opus proved to have the best performance. Notably, increasing the number of examples did not improve model performance after a certain point. In other words, adding more in-context examples does not always improve performance for more complicated tasks.
Open Questions
Support for long-context prompts is relatively new, and research into effective long-context techniques is even newer. We’ll also need more independent evaluations, because this type of formatting might be optimized for the Gemini models.
Apart from this, there are many open questions that still need to be answered, including:
What criteria should be used to select the corpus to ensure the most relevant and high-quality information is provided? What is the appropriate way to combine CiC with other techniques like RAG? How does the order of the documents in the corpus affect the performance of the model? How can we improve the performance of CiC at the 1-million+ token level?
Conclusion
With ever-increasing context windows, long-context prompting can be an effective tool for improving model performance. Long-context prompting techniques, like CiC prompting, are particularly well-suited for areas requiring in-depth analysis and sustained contextual understanding, like multi-hop reasoning tasks.These use cases benefit from the ability to process and integrate extensive information within a single context.
Additionally, this prompting format might be most impactful with Gemini models, and better results for other models could be obtained by following their best practices.