.webp)











What Our Customers Say About Vellum
Loved by developers and product teams, Vellum is the trusted partner to help you build any LLM powered applications.
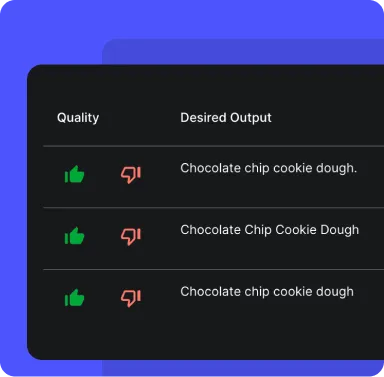
10x the frequency of shipping AI updates with an easy integration and one-click deploy. Seize control of how your AI behaves in production by easily making micro adjustments without the overhead of redeploying your entire application.









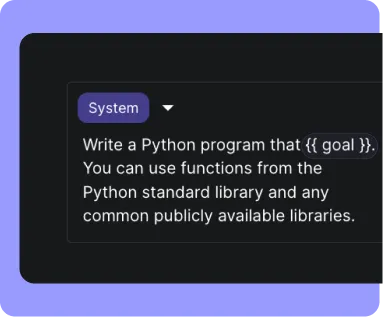
Use any model seamlessly with Vellum and leave the hassle of integrating with LLM provider APIs to us. Define and interact with prompts across closed-source, open-source, and even self-hosted models, all from unified API.


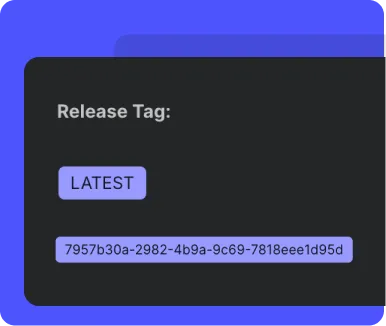
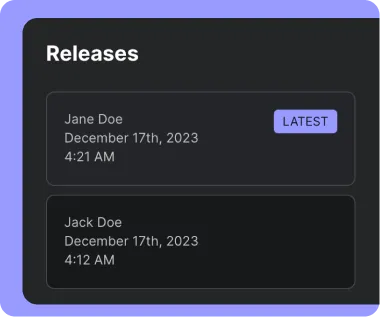
Great AI systems require a frequent release cycle that lets you adapt to how the AI is performing in the wild and ship improvements rapidly. Vellum helps you decouple your AI release processes from that of your application layer so that you can ship changes to your AI, without re-deploying your entire application.
.avif)
Great AI systems require a frequent release cycle that lets you adapt to how the AI is performing in the wild and ship improvements rapidly. Vellum helps you decouple your AI release processes from that of your application layer so that you can ship changes to your AI, without re-deploying your entire application.
Keep your production deployments stable while you experiment safely. Test new ideas risk-free, and promote changes to production only once you’re confident, using Vellum’s interface or your own CI/CD pipelines.


Big workload? High throughout? No problem. Vellum’s inference endpoints horizontally scale to meet your demands and are hosted separately to avoid fate sharing with other parts of the Vellum platform.





We sped up AI development by 50% and decoupled updates from releases with Vellum. This allowed us to fix errors instantly without worrying about infrastructure uptime or costs.

We've cut latency by 50% and reliably handle 90,000+ monthly production requests with Vellum. The flexibility of the platform and their first-class support transformed how we deliver real-time features without performance trade-offs.

AI development doesn’t end once you've defined your system. Learn how Vellum helps you manage the entire AI development lifecycle.