
Deploying AI systems comes with unique challenges that traditional software deployment practices don't fully address. For example, how do you ensure consistency when so many variables (from data to prompts to model parameters) can impact your system's performance? What happens when something goes wrong in production? How can you iterate confidently without introducing regressions?
I’ve seen teams either get stuck in slow, cautious release cycles or, on the flip side, push updates without enough guardrails. Neither is ideal.
We’ve helped hundreds of companies to ship to production and we’ve narrowed down 5 core practices every modern AI team needs to ship improvements faster, without sacrificing reliability.
Teams that follow these practices often cut deployment times from weeks to days (sometimes minutes), moving up to 100x faster while keeping production versions stable.
In this article, I’ll walk you through each practice, show how your team can put them to use, and explain how Vellum can help along the way.

1. Rigorous Versioning
The unique challenge with AI products is that changes often need more detailed release versioning.
With AI development, you’ll want to have more detailed, smaller versions that you can fully control and revert back to in the case of a regression. These might be as small as tweaking a prompt or adding a guardrail, or as big as adding a new tool or agent. All these changes need to be logged and saved as separate versions of your AI solution, so you can actually control the nuanced behavior of your models.
For example, to better manage these releases, Vellum’s integrated release management controls offer custom release tags.
These tags can be re-assigned to update your production, staging, or custom environment to a new prompt or workflow, without 0 code changes. Additionally, Vellum offers release reviews, where similarly to Github reviews, an admin can leave reviews on a Prompt or Workflow Deployment Release after it has been deployed. This is of high priority for many companies.
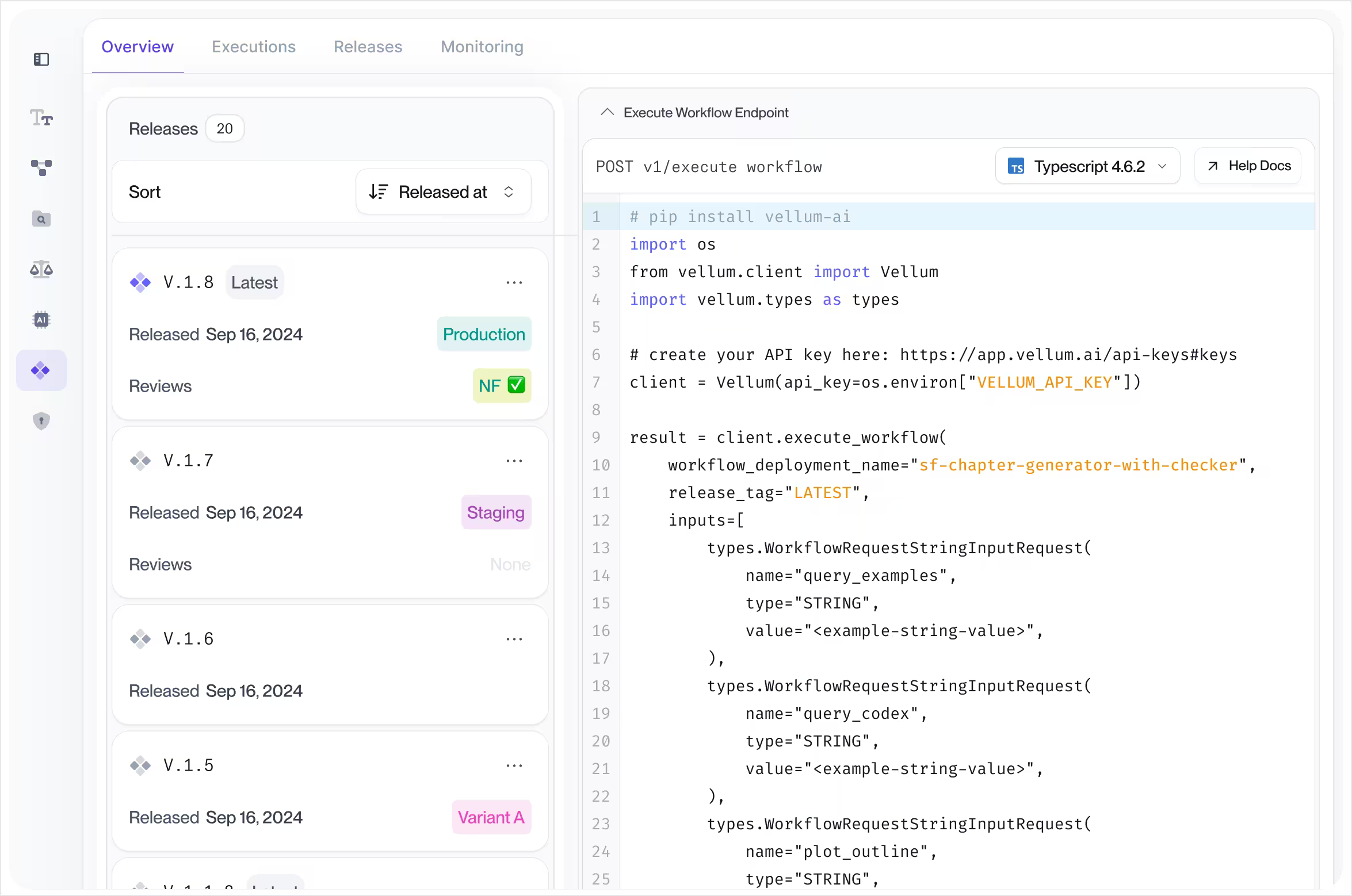
Now that we know we need more detailed version control, how do we actually release all these smaller updates if our app deploys are on a set schedule?
That takes us to core practice #2.
2. Decoupled AI Deployments
AI features should be updated independently from the main application. So, you’ll need to decouple your AI deployments from the rest of the app.
This approach will enable everyone on the team to push updates and improvements as often as needed. AI development is a cross-functional activity, you can greatly unblock your engineers, and let domain experts tweak prompts, and update the production without asking for code changes. With decoupled deployments your team can reduce time-to-production from days to hours.
Vellum offers features like one-click deployment for promoting validated changes to production.
This is extremely useful: The engineering team at Woflow, Michael and Jordan, roll out up to 20 AI updates a week, all without redeploying their core system or disrupting the rest of the app. As soon as there’s user feedback or a need for a fix, the product team can deploy updates immediately.
"Using Vellum, we can now update our AI up to 20 times a week without re-deploying our main application," - Jordan Nemrow, CTO at Woflow
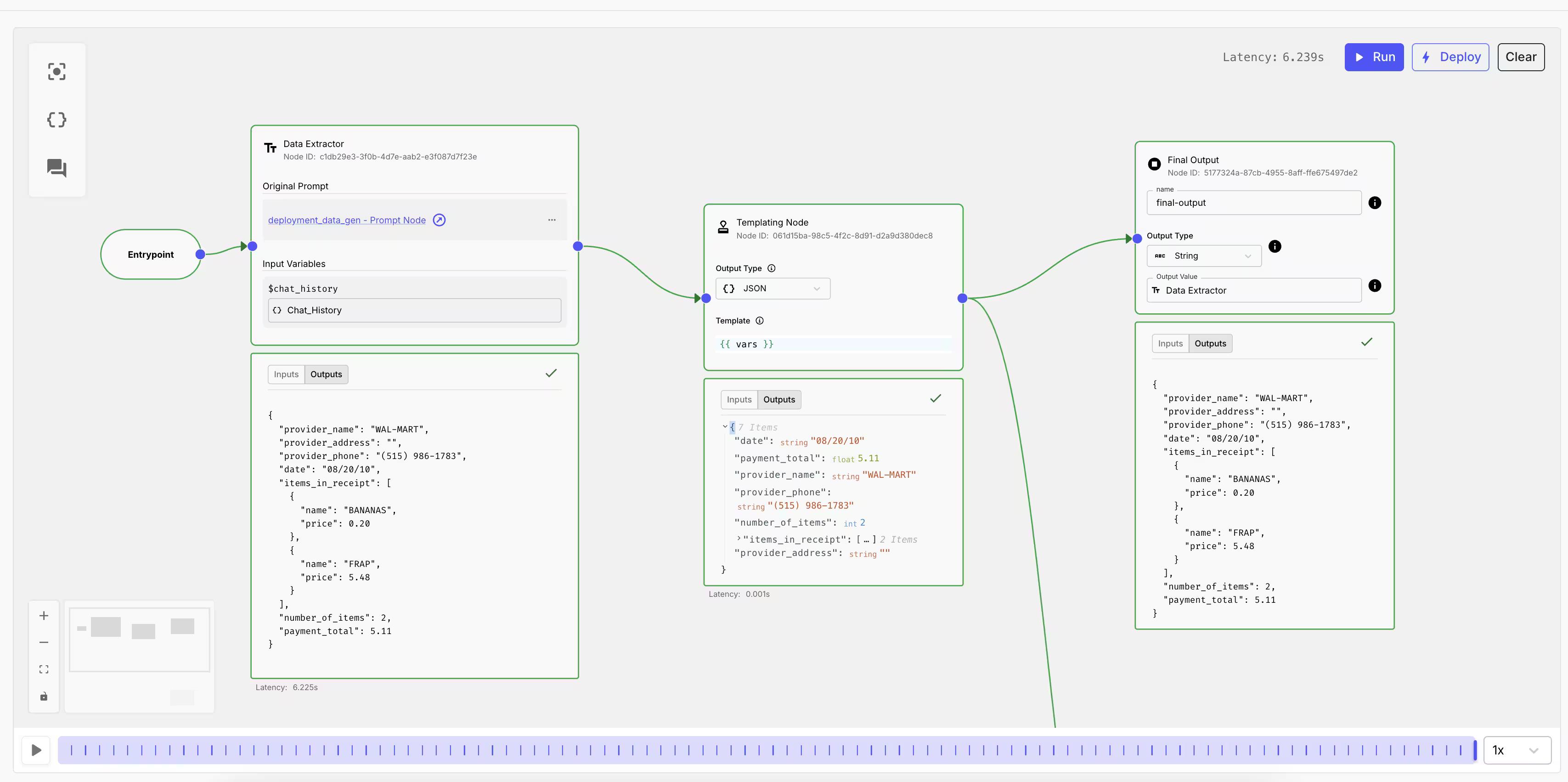
3. Automated Testing
For your normal CI/CD process, your code must pass through a suite of tests before getting merged into main. You expect the same outputs given a known set of inputs.
With AI solutions, it's not that simple. Outcomes vary, so tests need flexibility . Instead of exact answers, you're evaluating behaviors, reasoning, and decision-making (e.g., tool selection). This requires nuanced success criteria like scores, ratings, and user satisfaction, not just pass/fail tests. Notably, it’s common for an update to improve performance for one type of user query but degrade performance for another.
That’s why you need to test your whole workflow from start to finish, as well as each AI component on its own.
Here's where Vellum really shines: our release mechanism is tightly integrated with our evaluation suite. Before promoting a new version to production, teams can automatically run predefined test cases against the release candidate and compare its performance metrics directly against the currently deployed version.
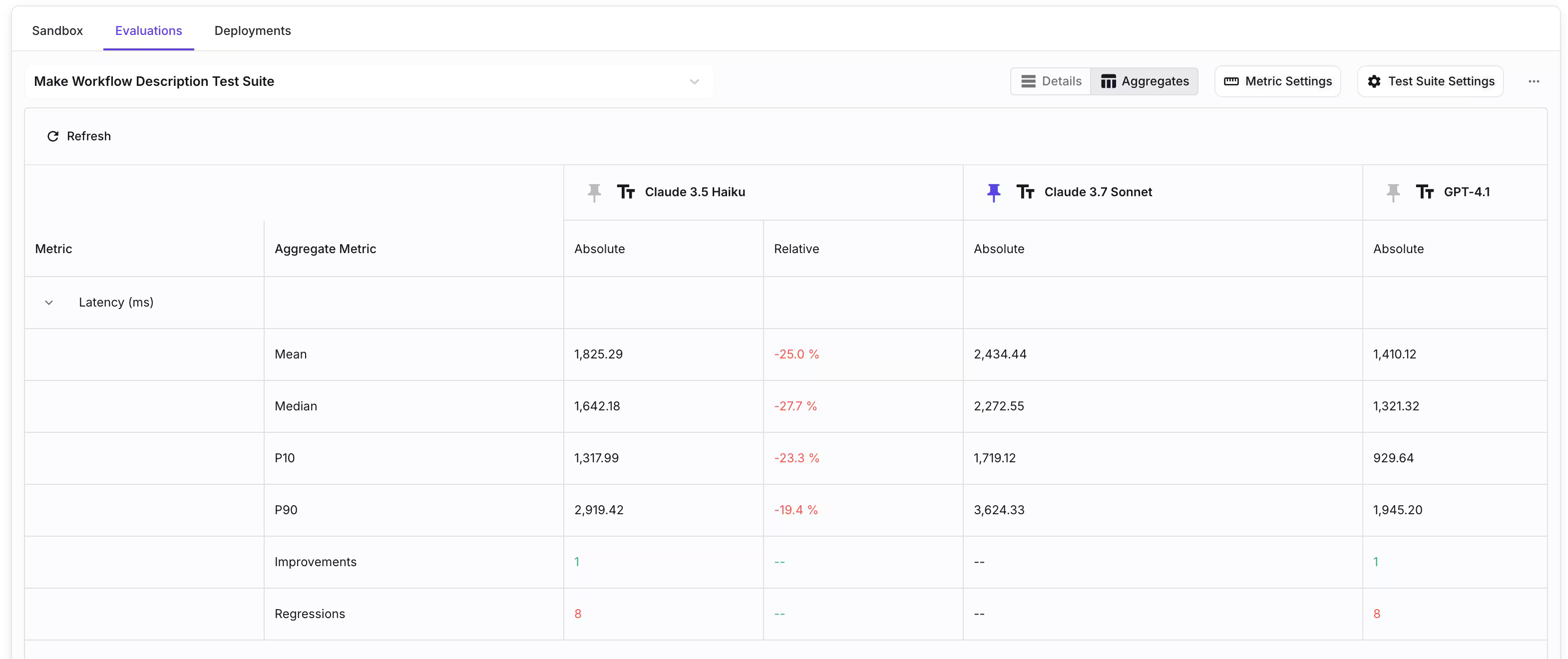
Redfin saved hundreds of hours , by evaluating their “Ask Redfin” chatbot rigorously, before they deployed it in 14 markets across the U.S.
Using Vellum to test prompts and model setups let us move way faster—no waiting on engineering or code changes. More people could experiment, and once things worked, engineers took it live. The Vellum team saved us hundreds of hours. - Sebi Lozano, Senior Product Manager at Redfin
This process will prepare you for production, but expect to have a lot of edge-cases in production and that brings us to the last thing: detailed tracing.
4. Detailed Tracing
With AI products, small changes like tweaking a prompt, model, or your RAG setup can have a big impact on the output. Traditional version control or logging doesn’t catch those nuances. You need to trace at the level of inputs, outputs, model versions, and even evaluation results to understand what actually changed and why the behavior shifted.
Check out the preview below to see how Vellum solves this. You can trace every step your AI takes in production for any workflow. This will enable you to capture errors in production, and solve for user-feedback much faster.
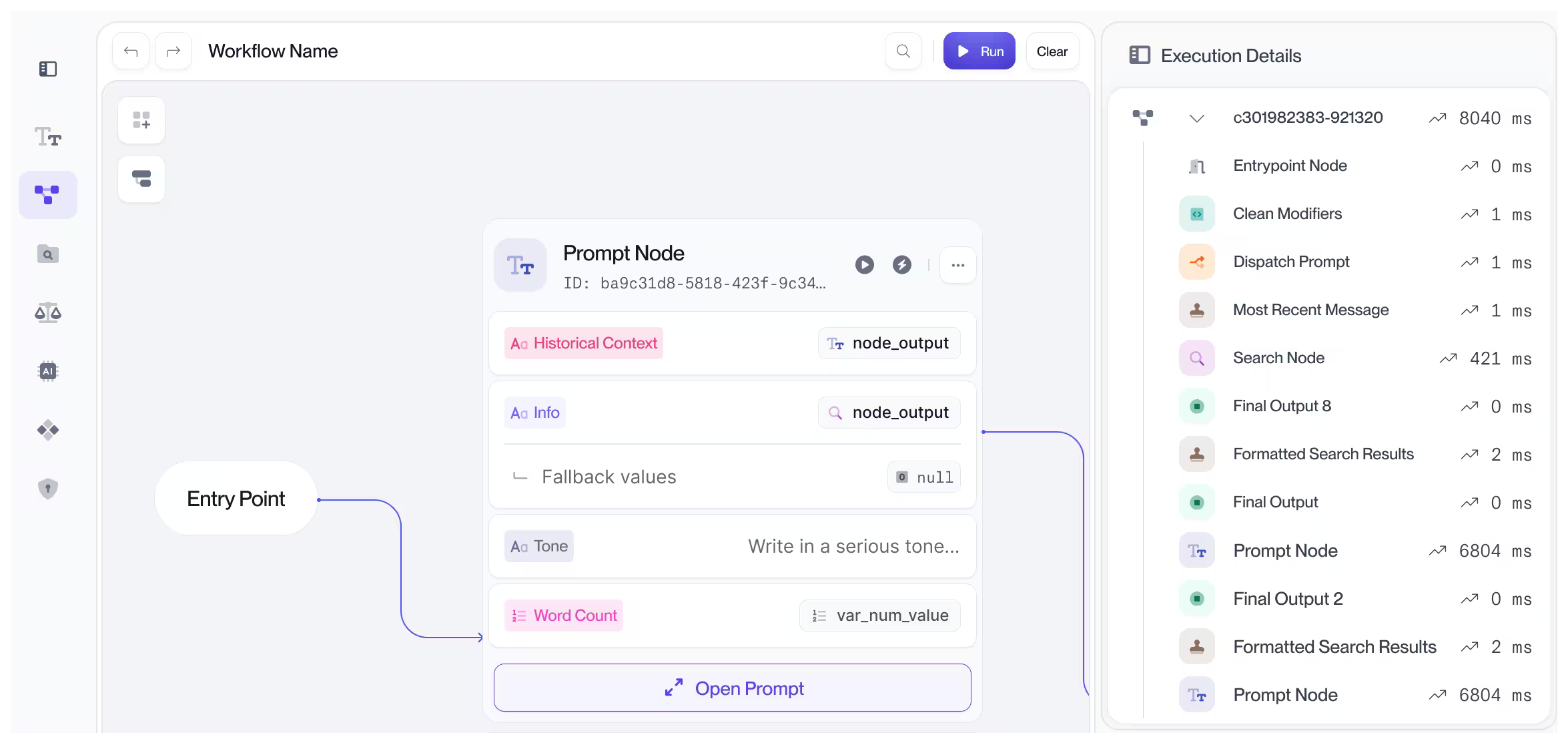
Rely Health, a health-tech company is able to push updates 100x faster using the tracing view , enabling them to customize their healthcare solutions for every clinic or hospital they work with.
"We create dozens of AI workflows—easily 7-8 per client, covering patient phone calls, provider calls, and more. Vellum has been a huge help because we need to rapidly iterate and deploy. We can take a given execution, drop it into our evaluation table, and keep moving fast." - Prithvi, CTO at Rely Health.
Results: 100x faster AI updates
Let’s take a look at how applying these core principles are driving value for our customers today.
Woflow
Take Woflow , for example. They use Vellum to manage critical AI pipelines for ingesting structured data from product catalogs (images/pdfs) during merchant onboarding. By using Vellum’s product, they’ve reported:
Value Metric Outcome with Vellum Improvement AI Development Cycle Faster Build and Iterate ⚡️ 50% Faster Error Resolution Instant Fixes 🛠️ Real-Time Updates Inference Latency 50% Lower ⏱️ 50% Reduction Production Reliability 90,000+ Requests/Month ✅ High Volume, No Issues
Rely Health
Or let’s take Rely Health as another example . They equip care navigators with the latest AI technology to deliver personalized voice AI agents to automate tens of thousands of routine, lower acuity calls for navigation teams.
By leveraging Vellum’s complete suite, they’ve reported:
Value Metric Outcome Improvement AI Update Speed 100x Faster AI Updates ⚡️ Much Faster Clinician Trust Higher Trust from Clinicians 👍 More Confidence Issue Detection Spot Issues Almost Instantly 🔍 Real-Time Visibility
These results aren’t outliers. They showcase why following these practices will enable the whole team to move faster, and ship more reliably.
Summary
I encourage technical teams and leaders to think through your current AI deployment strategy. Ask yourself: How long does it take to update an AI component in production? How confident are you in those updates? What happens today if you notice regressions in production?
If the answers to these questions reveal gaps in your process, it may be time to consider modernizing your approach. The organizations that master AI release management will be the ones that can iterate faster and deliver more reliable AI experiences.





