As a developer working with OpenAI's language models, it's essential to understand how tokenization works and how to count tokens programmatically.
For those who prefer to handle tokenization this way, there are several libraries tailored for this purpose.
Tiktoken stands out as a swift BPE (Byte Pair Encoding) tokenizer(more on this below) designed specifically for OpenAI's models.
In this article, we'll explain how tokenization works, and how to use the Tiktoken library to count tokens before you send an OpenAI API request with Vellum.
LLM Tokenization
Tokenization is the process of splitting a text string into a list of tokens. OpenAI's models, such as GPT-3 and GPT-4, process text in the form of tokens rather than raw characters. By breaking down text into tokens, the models can better understand and generate human-like text.
To perform this, we use BPE tokenizers, in this case Tiktoken (because it’s the fastest one).
BPE , or byte pair encoding, changes text into these numbers and it helps the model to recognize common parts of words, helping it learn grammar and understand language better.
So, how can we count these tokens?
Introducing Tiktoken
Tiktoken is an open-sourced tokenizer developed by OpenAI, that’s 3-6x faster than other open source tokenIzers. It provides a convenient way to tokenize text and count tokens programmatically.
Different OpenAI models use different encoding models, or:
cl100k_base : Gpt-4 , Gpt-3.5-turbo , and Text-embedding-ada-002 . p50k_base : Codex models , text-davinci-003 and text-davinci-002 . r50k_base : GPT-3 models .
Using Tiktoken in Python
To get started with Tiktoken in Python, follow these steps (or run this Collab notebook )
1. Install or upgrade Tiktoken:
pip install --upgrade tiktoken
2. Import Tiktoken in your Python script:
import tiktoken
2. Count tokens using one of the following options:
Option 1: Use tiktoken.encoding_for_model() to automatically load the correct encoding for a given OpenAI model
def num_tokens_from_string(string: str, model_name: str) -> int: encoding = tiktoken.encoding_for_model(model_name) num_tokens = len(encoding.encode(string)) return num_tokens print(num_tokens_from_string("Hello world, let's test tiktoken.", "gpt-3.5-turbo"))
Option 2: Specify the encoding directly
def num_tokens_from_string(string: str, encoding_name: str) -> int: encoding = tiktoken.get_encoding(encoding_name) num_tokens = len(encoding.encode(string)) return num_tokens print(num_tokens_from_string("Hello world, let's test tiktoken.", "cl100k_base"))
Both options will output the number of tokens in the given text string.
You can try this script and check how does OpenAI count tokens for each model, but what happens when you want to do this programmatically to determine whether or not to send a request to OpenAI?
Let’s show you how you can do that with Vellum.
Counting Tokens Programmatically with Vellum
To decide when to send a request to OpenAI, you can use Vellum, an AI product development platform. With Vellum, you can set up a Workflow that checks if your input prompt is too long for a specific model's limit. It will flag any input that's too large before the request is sent to OpenAI.
Here's how to do it:
1. Create a Code Execution Node
In this node, we'll insert the code that runs Tiktoken. We’re using Option 2, where we’ll be working with a specific encoder ( cl100k_base ), as we’re using GPT-3.5-turbo for this example.
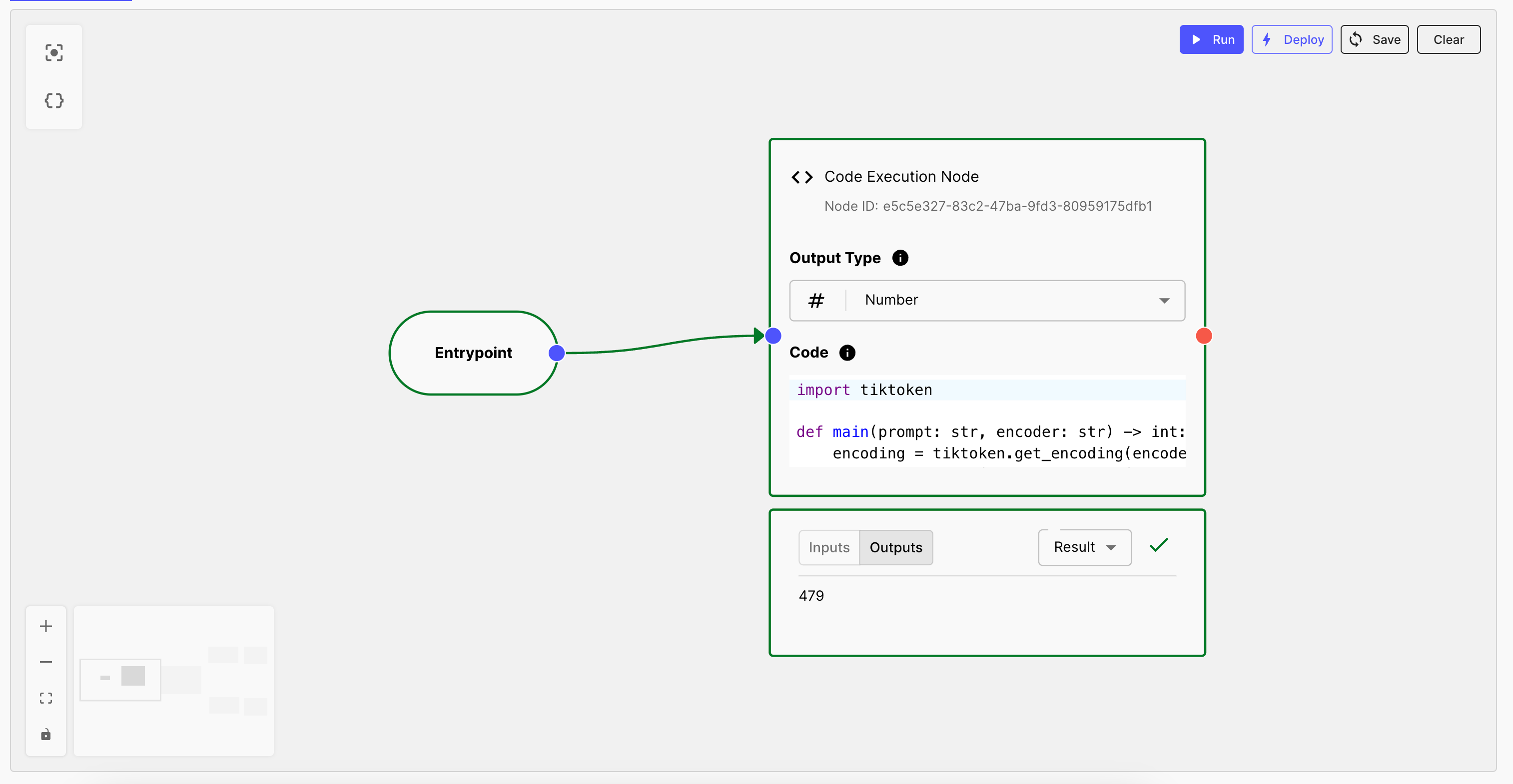
Here’s how we define this node:
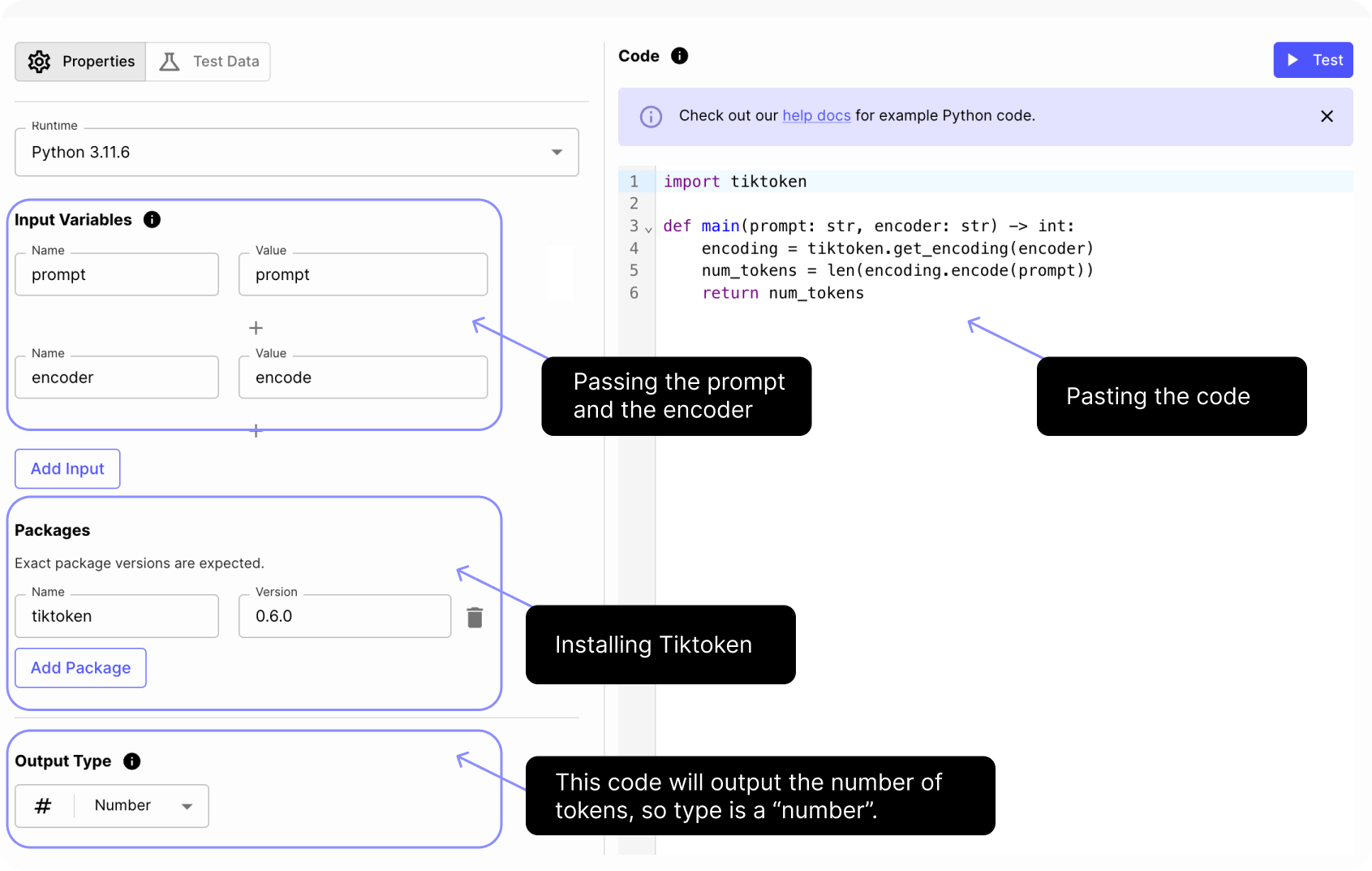
2. Create a Conditional Node
To capture if a given prompt input size is beyond a certain token limit, we’ll attach a conditional node to the code execution node . This node will check if the token count is higher or lower than the expected limit.
In this example, since the context limit for GPT-3.5-turbo is 16k, the node will proceed with the API call if the token count is under this limit. If the count exceeds 16k the node will run a fallback prompt node instead. The fallback prompt in our example uses GPT-4 Turbo to run the prompt because it has higher token limit (128k), but you can set your fallback prompt to be whatever you want.
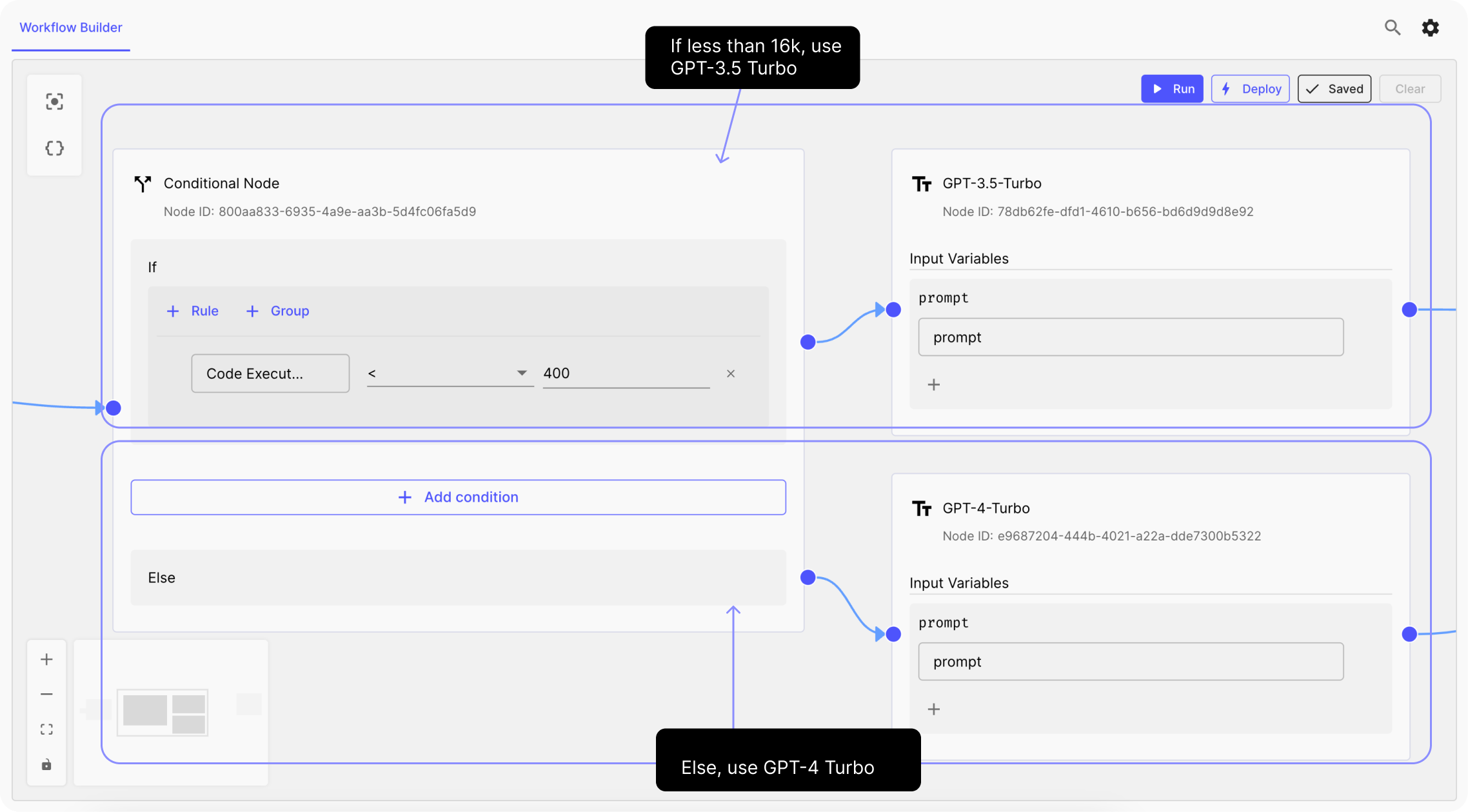
3. Add Final Output
Finally we attach a final-node to our Workflow, that will pass the selected prompt output.
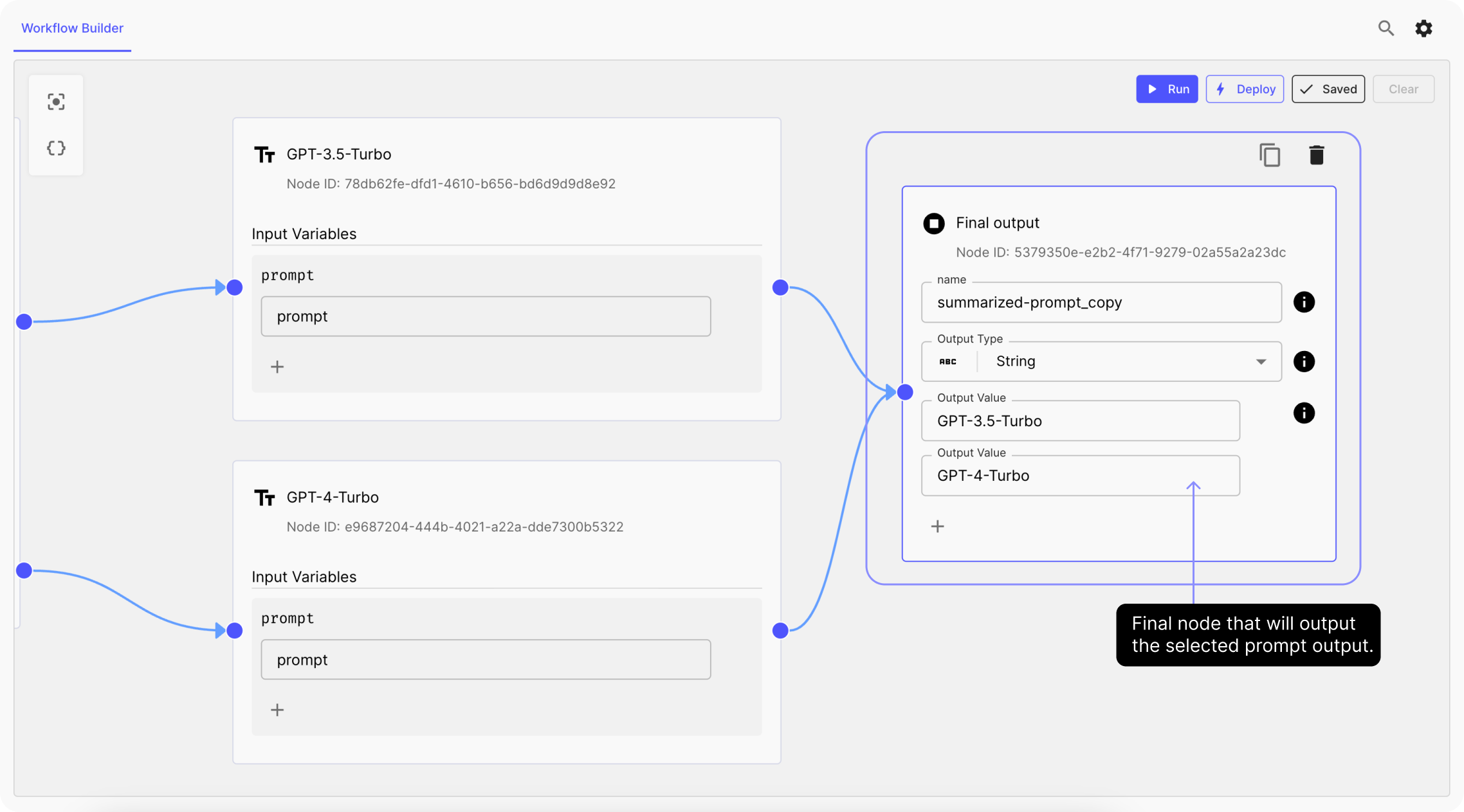
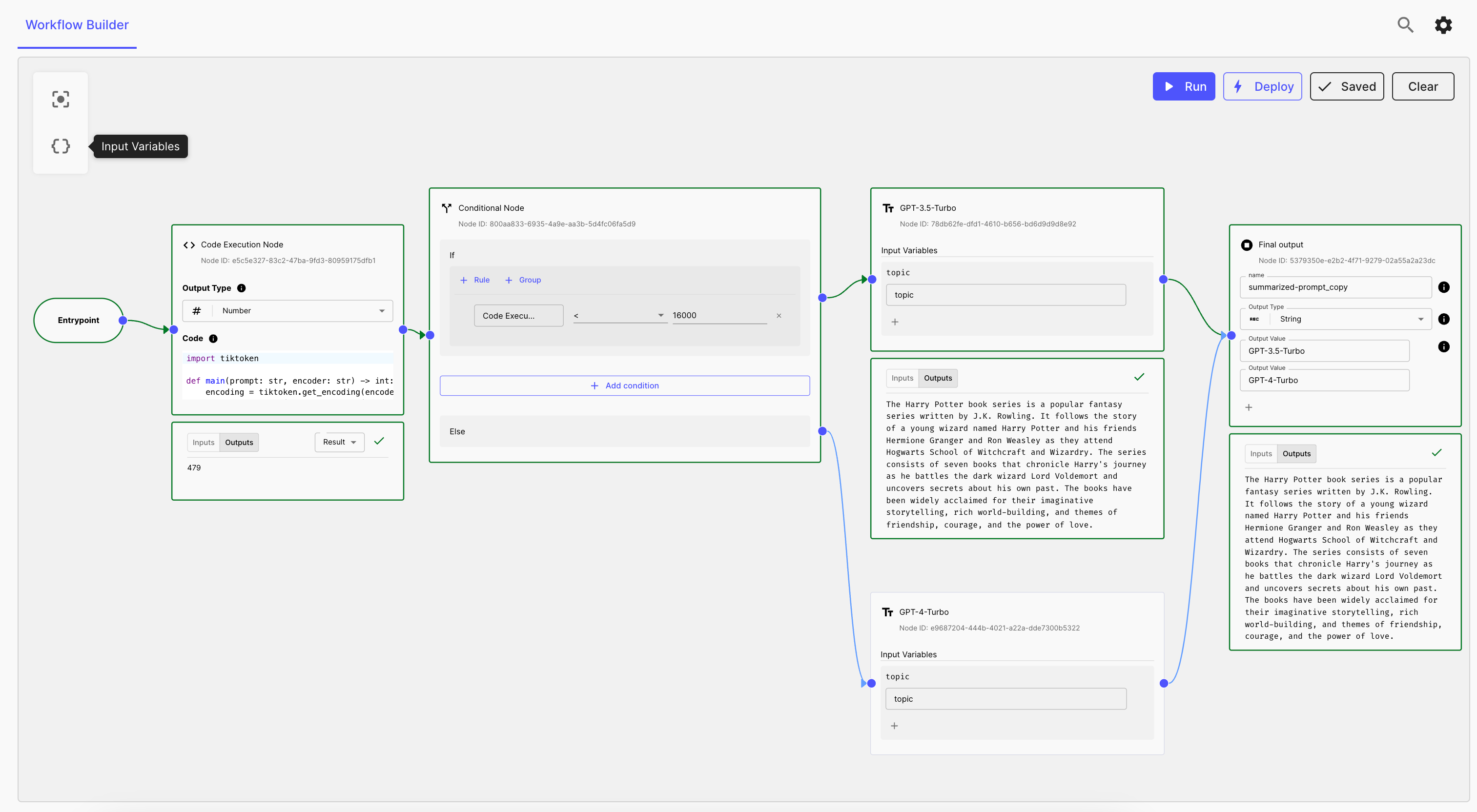
4. Run the Workflow & Test
Here’s how the workflow looks like when it passes the token limit:
And here’s how the workflow will run when the prompt size is beyond the token limit (for simplicity we use a token limit of 400):
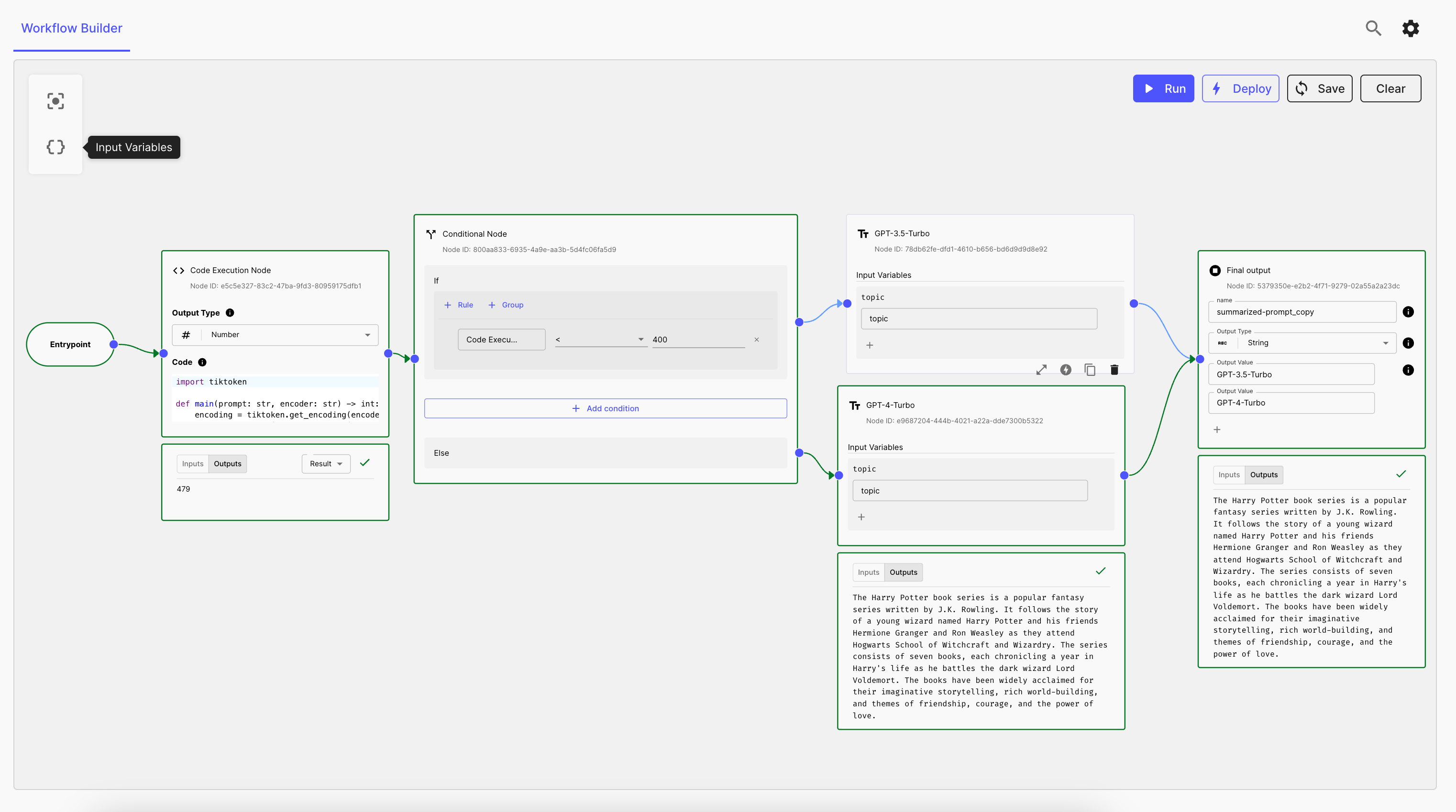
If you want to programmatically count the tokens in your prompts, book a call here to get started with Vellum.
Why Count Tokens Programmatically?
Counting tokens is crucial for two main reasons:
Text Length Limit: OpenAI models have a maximum token limit for input text. By counting tokens programmatically, you can determine whether a given text string exceeds the model's capacity before you send the API request. API Usage Costs: OpenAI's API usage is priced based on the number of tokens processed. Knowing the token count helps you estimate and manage the cost of your API calls. In the example above for example, we showed that you can revert to a more expensive model that has higher context size in unique cases where your prompt size won’t fit the context input limit for a cheaper model like GPT-3.5 Turbo model.
Tokenization in Other Languages
Tiktoken and other tokenizer libraries are available in various programming languages, including:
For cl100k_base and p50k_base encodings:
Python: tiktoken .NET / C#: SharpToken , TiktokenSharp Java: jtokkit Golang: tiktoken-go Rust: tiktoken-rs
For r50k_base ( gpt2 ) encodings, tokenizers are available in many languages.
Python: tiktoken (or alternatively GPT2TokenizerFast ) JavaScript: gpt-3-encoder .NET / C#: GPT Tokenizer Java: gpt2-tokenizer-java PHP: GPT-3-Encoder-PHP Golang: tiktoken-go Rust: tiktoken-rs
(Vellum makes no endorsements or guarantees of third-party libraries.)
Tokenization in Chat Mode
Chat models like gpt-3.5-turbo and gpt-4 use tokens in the same way as other models.
However, due to their message-based formatting, counting tokens for a conversation can be more challenging. If a conversation exceeds the model's token limit, you'll need to truncate, omit, or shrink the text to fit within the limit.
Keep in mind that very long conversations are more likely to receive incomplete replies. For example, a gpt-3.5-turbo conversation that is 4090 tokens long will have its reply cut off after just 6 tokens.
Conclusion
Understanding tokenization and how to count tokens is essential for working effectively with OpenAI's language models.
By using the Tiktoken library or other tokenizer libraries in your preferred programming language, you can easily count tokens and ensure that your text input fits within the model's limitations while managing API usage costs.