Replay Workflow from Node
Previously, you needed to run the entire workflow each time you needed to test the results of a particular Node and it’s downstream effect.
Now, you can re-run a Workflow from a specific Node, reusing results from previous executions from upstream nodes.
After running a Workflow for the first time, you’ll see this new play icon above each Node. Clicking it will re-run only that specific Node using the outputs that were generated from a previous run of the workflow.

This feature is vital for efficient workflow testing and iteration, saving you time and tokens while you’re experimenting with your architecture.
Guardrail Workflow Nodes
Incorporating Evaluation Metrics into Workflows was previously not possible, limiting the ability to enforce quality checks at runtime.
You can now run pre-defined evaluation metrics in your Workflows using the new Guardrail Node , and drive downstream behavior based on a specific metric’s score.
For example, when building a RAG application, you might determine whether the generated response passes some threshold for Ragas Faithfulness and if not, loop around to try again.

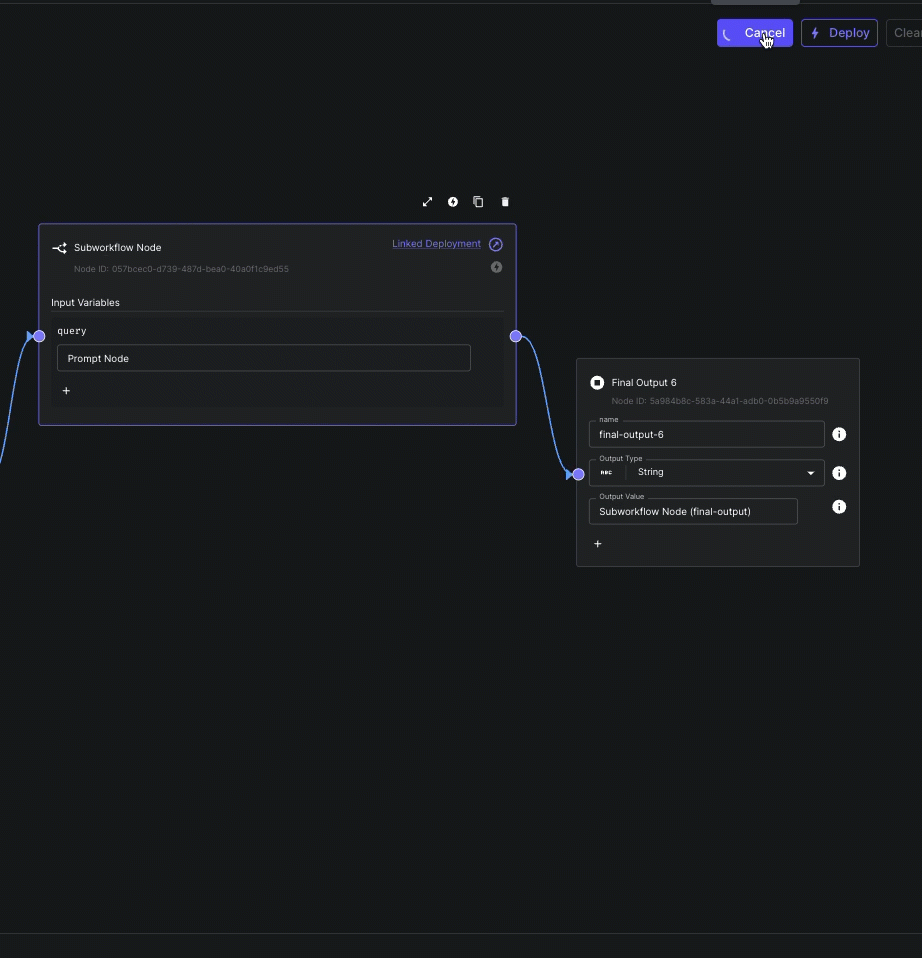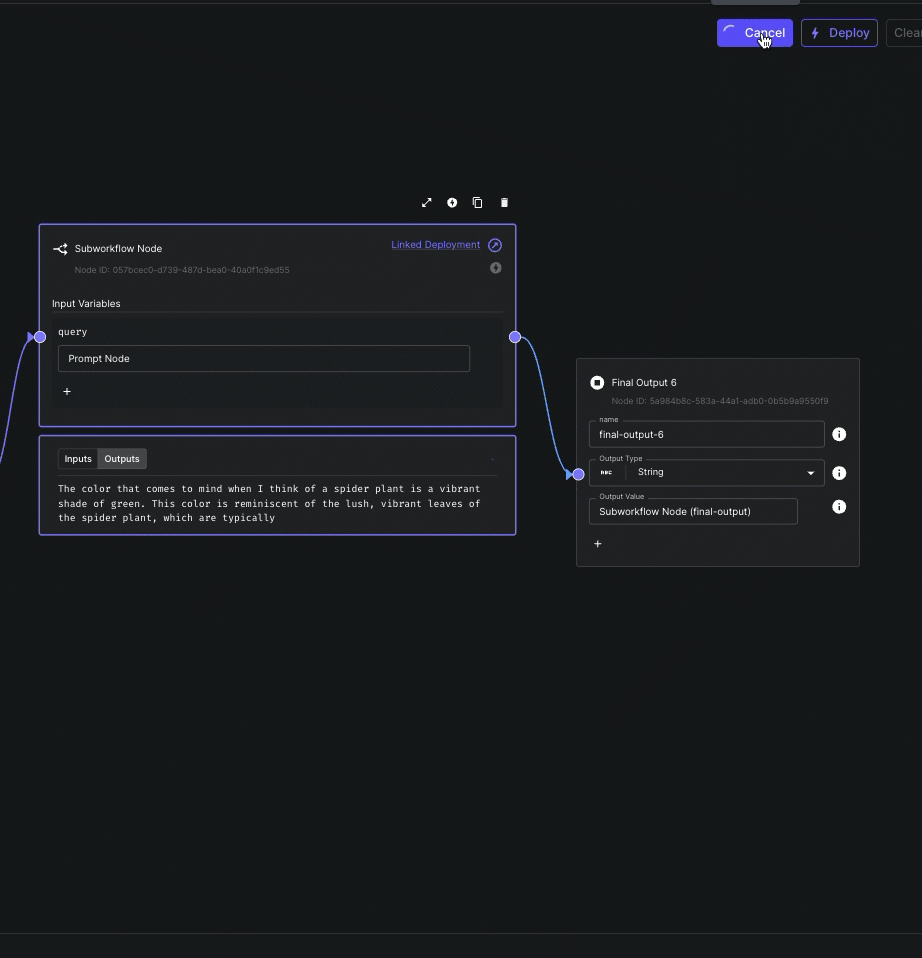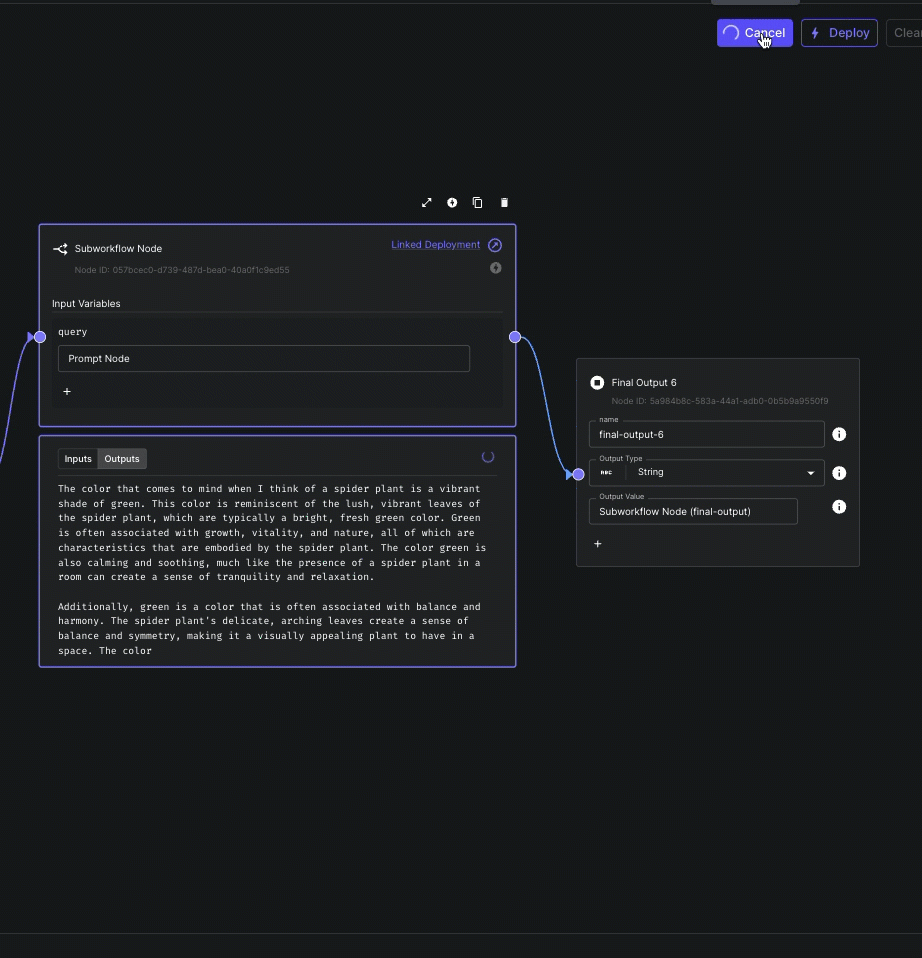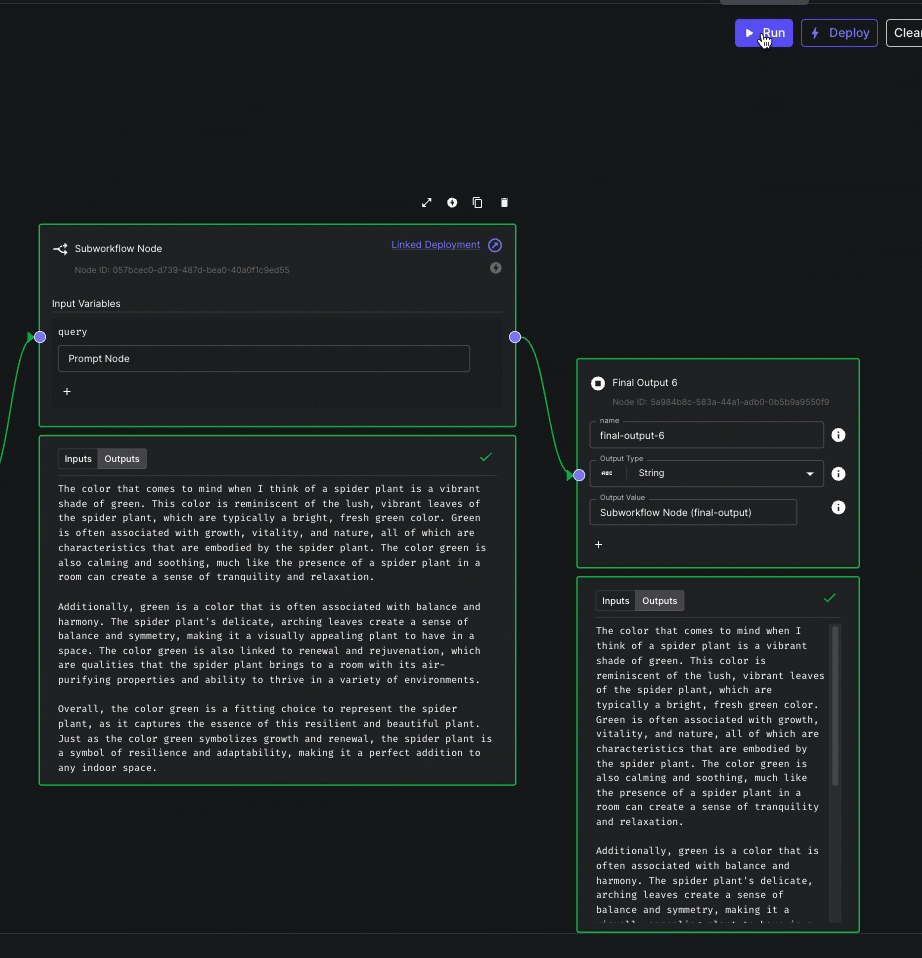
Subworkflow Node Streaming
You can now stream output(s) from Subworkflow Nodes to parent workflows.
This allows you to compose workflows using modular subworkflows without sacrificing the ability to delivery incremental results to your end user.
Improved Image Support in Chat History Fields
We’ve made several changes to enhance the UX of working with images.
Chat History messages now include an explicit content-type selector , making it easier to work with image content from supported models. Publicly-hosted images can be added in multiple ways : by pasting an image URL, pasting a copied image, or dragging and dropping an image from another window. Limited support for embedded images: You can now embed an image directly into the prompt by copy/pasting or dragging/dropping an image file from your computer’s file browser. This method has a 1MB size limit and is considered an interim solution as we continue to explore image upload and hosting options.

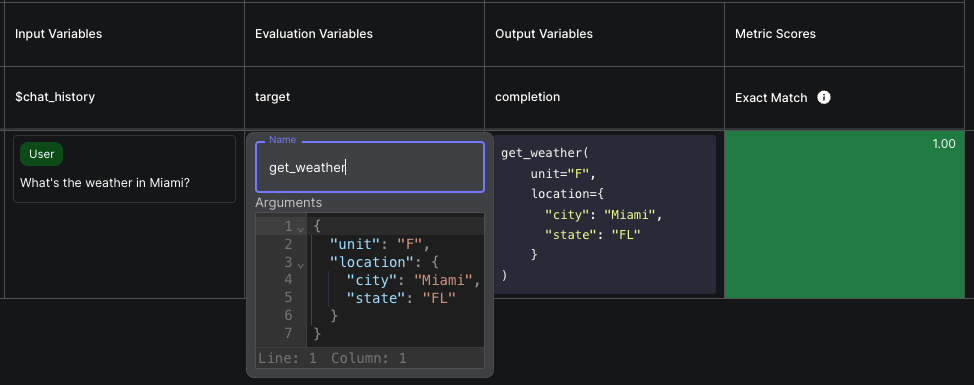
Function Call Assertions in Evaluations
Function call outputs are one of the most frequent uses in AI development that let you get structured output from the model. Although models have become very powerful in generating function call outputs with great accuracy, evaluation is still needed.
Previously, it wasn’t possible to evaluate Prompts that output function calls at scale, limiting the scope of testing for many use-cases.
Starting this month, you can evaluate Prompts that output function calls via Test Suites, enabling you to test their outputs at scale.
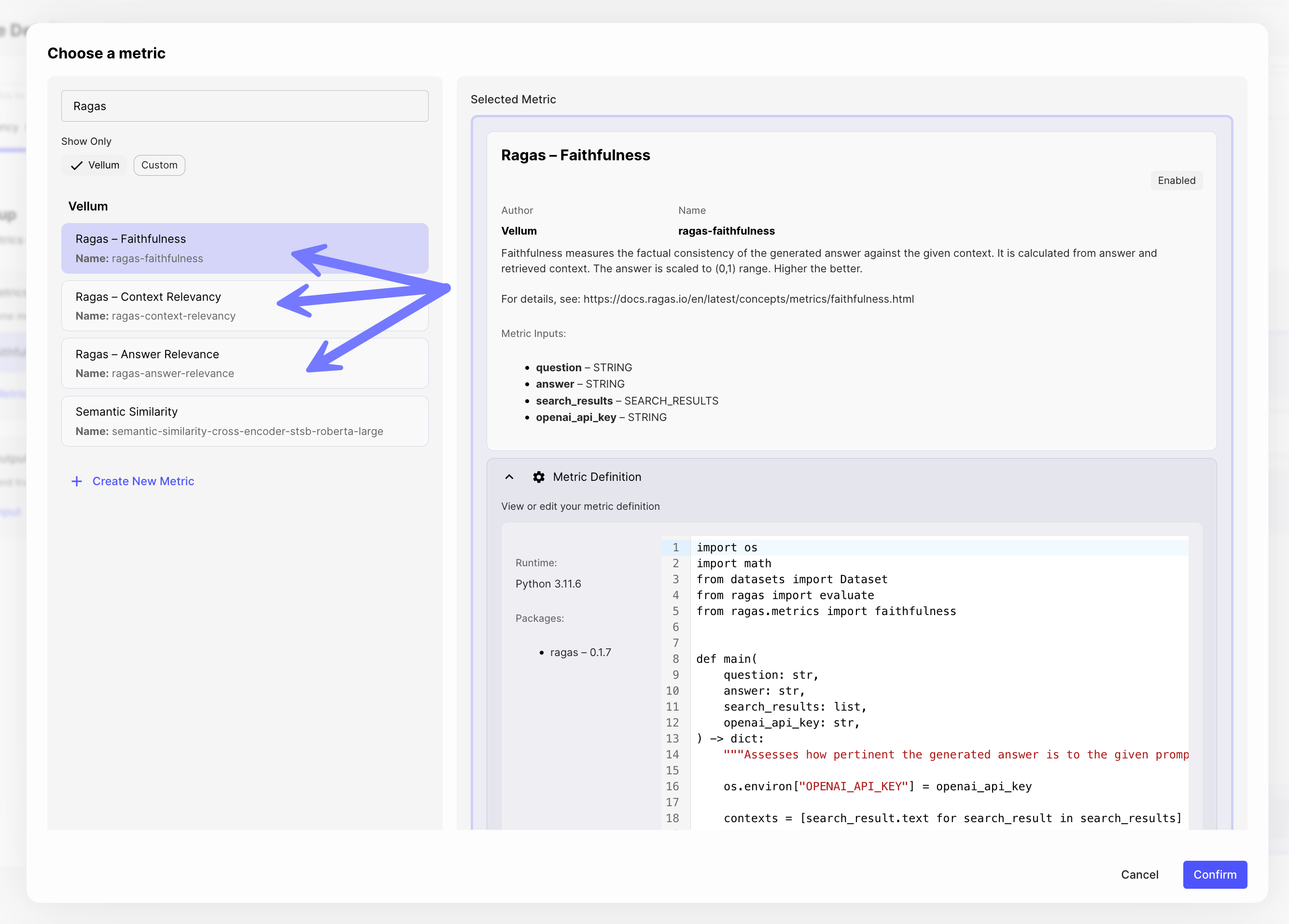
Out-of-Box Ragas Metrics
Ragas is a framework that helps you evaluate your Retrieval Augmented Generation (RAG) pipelines. Adding these Ragas metrics was limited, requiring custom implementation for each use case.
We now offer three new Ragas metrics available out-of-box in Vellum: Context Revelancy , Answer Relevance and Faithfulness . These can be used within Workflow Evaluations to measure the quality of a RAG system.
For more info, check out our new help center article on Evaluating RAG Pipelines .
Other Workflow Updates
Context Menu for Workflow Edges and Nodes
Previously, deleting Workflow Edges and Nodes required navigating through multiple steps.
You can now right-click to delete Workflow Edges and Nodes directly from the context menu.

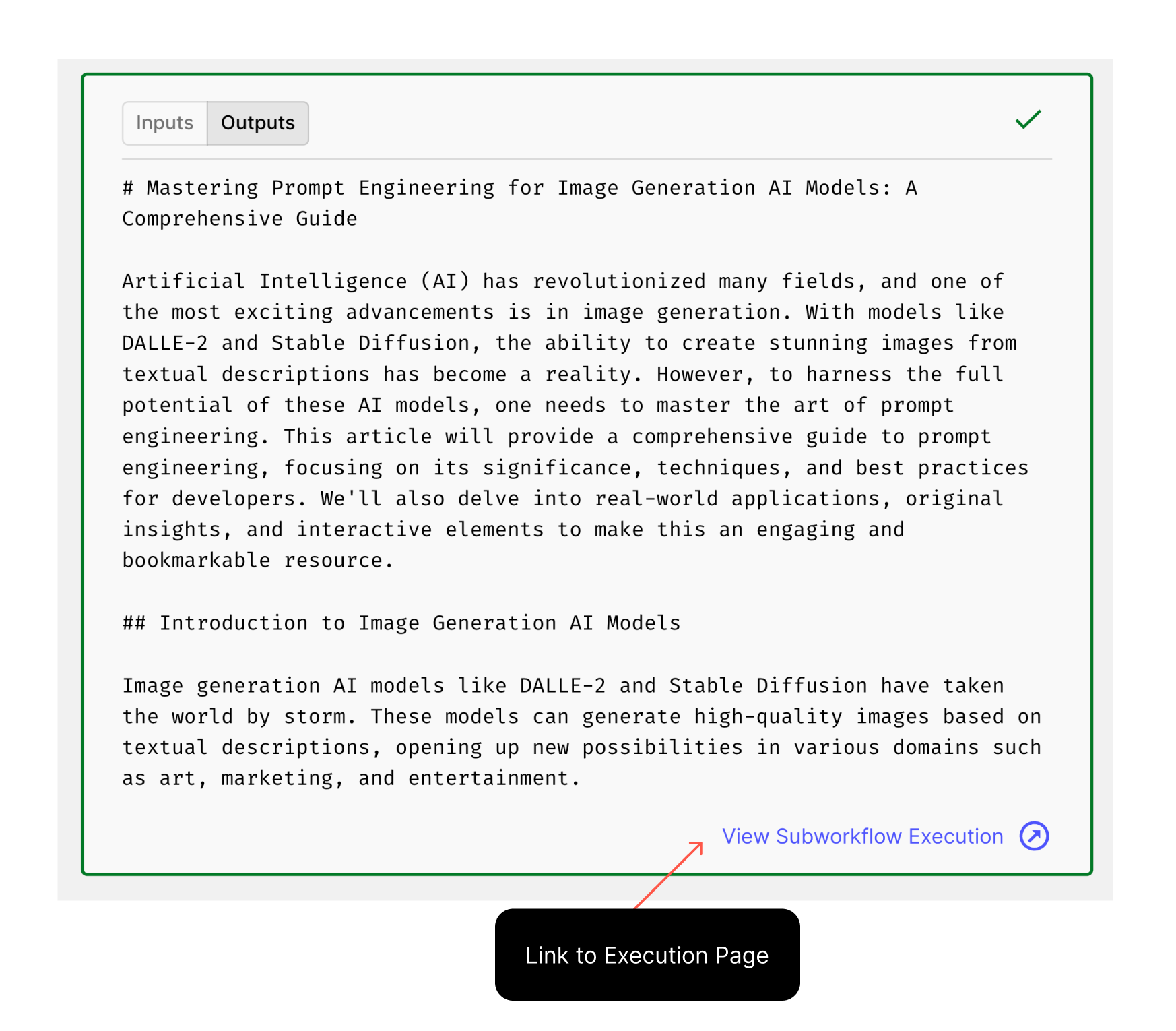
Subworkflow Node Navigation
Navigating to execution pages for Subworkflow nodes was cumbersome and time-consuming.
You now have a link to the execution page for each Subworkflow node directly from the main workflow interface where the Subworkflow is used.
Other Evaluations Updates
Improvements to Saving Executions as Scenarios & Test Cases
Saving Prompt/Workflow Deployment Executions from production API calls to an Evaluation dataset as Test Cases is a great way to close the feedback loop between monitoring and experimentation. However, this process has historically been time-consuming when you have many Executions to save.
We’ve made a number of improvements to this process:
You can now multi-select to bulk save Executions as Test Cases We now default to the correct Sandbox/Test Suite when saving Executions as Scenarios/Test Cases You’ll now see warnings if the Sandbox/Test Suite you’re saving to has required variables that are missing from the Execution
Check out a full demo on this link.
Default Test Case Concurrency in Evaluations
Configuring how many Test Cases should be run in parallel during an Evaluation was not possible, limiting control over the evaluation process.
You can now configure how many Test Cases should be run in parallel during an Evaluation, providing more control and flexibility.
You might lower this value if you’re running into rate limits from the LLM provider, or might increase this value if your rate limits are high.

Other Prompts Updates
Chat Mode Revamp
The Chat Mode in Prompt Sandboxes had an outdated interface, which hindered user experience and productivity.
We’ve given Chat Mode a major facelift, enhancing its visual appeal and usability.

Prompt Sandbox History Update
The history view for a Prompt Sandbox was editable, which could lead to accidental changes.
Now, the history view for a Prompt Sandbox is read-only . To edit a previous version, simply click the Restore button, and a new editable version will be created from that specific version.
This update ensures the integrity of your prompt history while still allowing you to revert to previous versions when needed.
Double-Click to Resize Rows & Columns in Prompt Sandboxes
You can now double-click on resizable row and column edges to auto-expand or reset their size, making adjustments quick and easy. If already at maximum size, double-clicking will reset them to their default size. Additionally, in Comparison mode, double-clicking on cell corners will auto-resize both dimensions simultaneously.
Other Deployments Updates
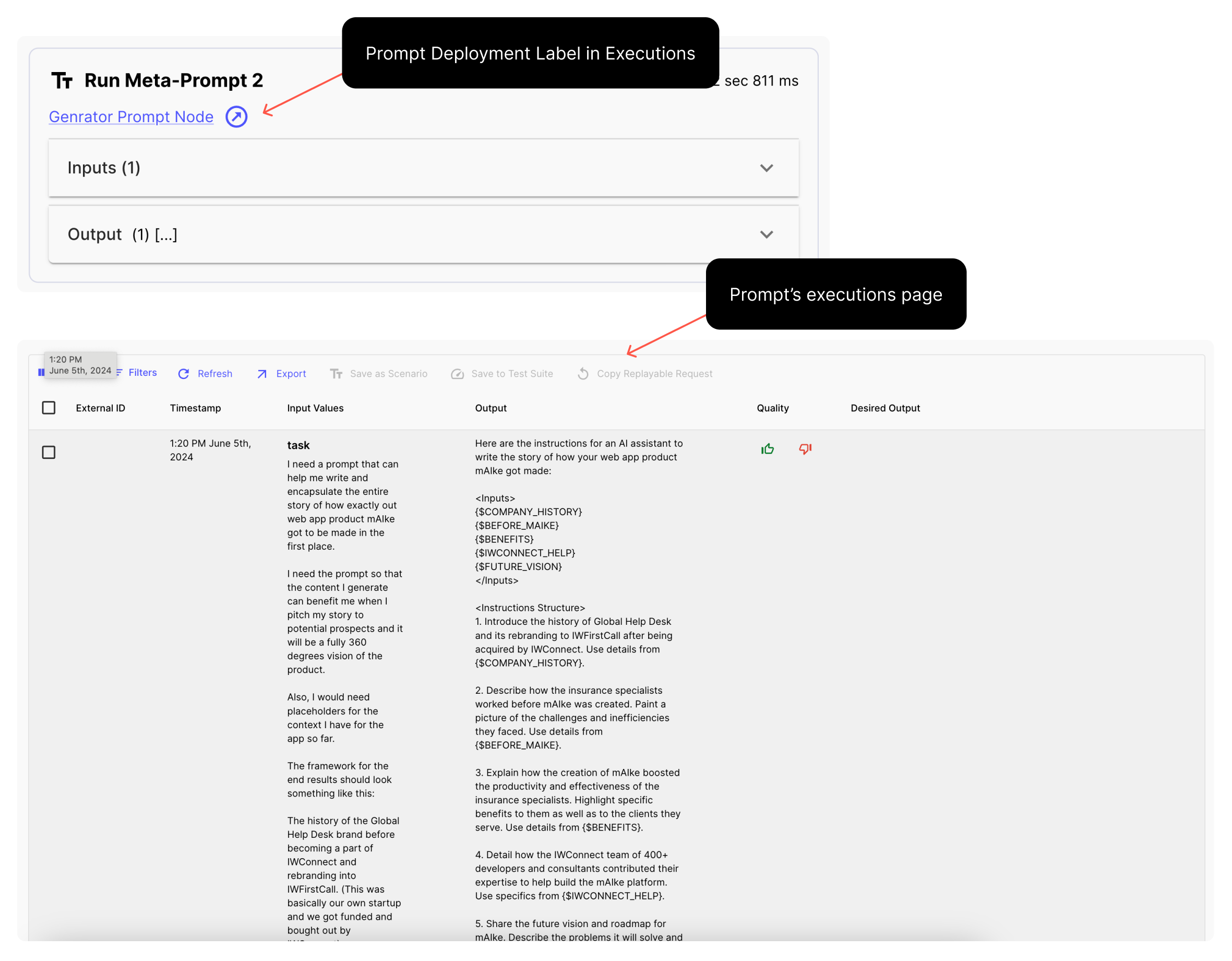
Prompt Node Monitoring
Vellum now captures monitoring data for deployed Prompt Nodes. Whenever a deployed Workflow invokes a Prompt Node, it will now show a link displaying the Prompt Deployment label.
Clicking on the link will take you to the Prompt’s executions page, where you can then see all metadata captured for the execution, including the raw request data sent to the model:
Prompt Deployment Actuals Metadata
Submitting execution Actuals for Prompts lacked the ability to include additional metadata, limiting the context available for analysis.
You can now optionally include a metadata field when submitting execution Actuals for Prompts, providing more detailed fwe’d back relating to each execution.
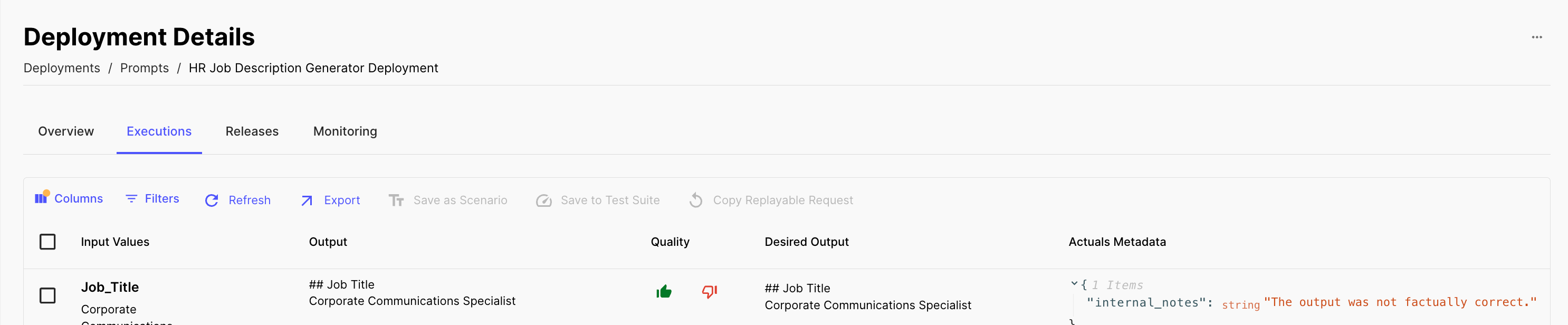
This is particularly helpful if you want to capture feedback/quality across multiple custom dimensions. Learn more in our API docs here .
Workflow Deployment Actuals Metadata
Similar to Prompts, submitting execution Actuals for Workflows lacked the ability to include additional metadata.
You can now optionally include a metadata field when submitting execution Actuals for Workflows, offering more detailed information for each execution.
Model Access and Providers
Groq Support
Vellum now has a native integration with the LPU Inference Engine, Groq . All public models on Groq are now available to add to your workspace. Be sure to add your API key as a Secret named GROQ_API_KEY on the API Keys page .
Three New Models
Three other state-of-the-art models are now available in Vellum:
Google’s Gemini 1.5 Flash; Llama 3 Models on Bedrock; and GPT-4o
Quality of Life Improvements
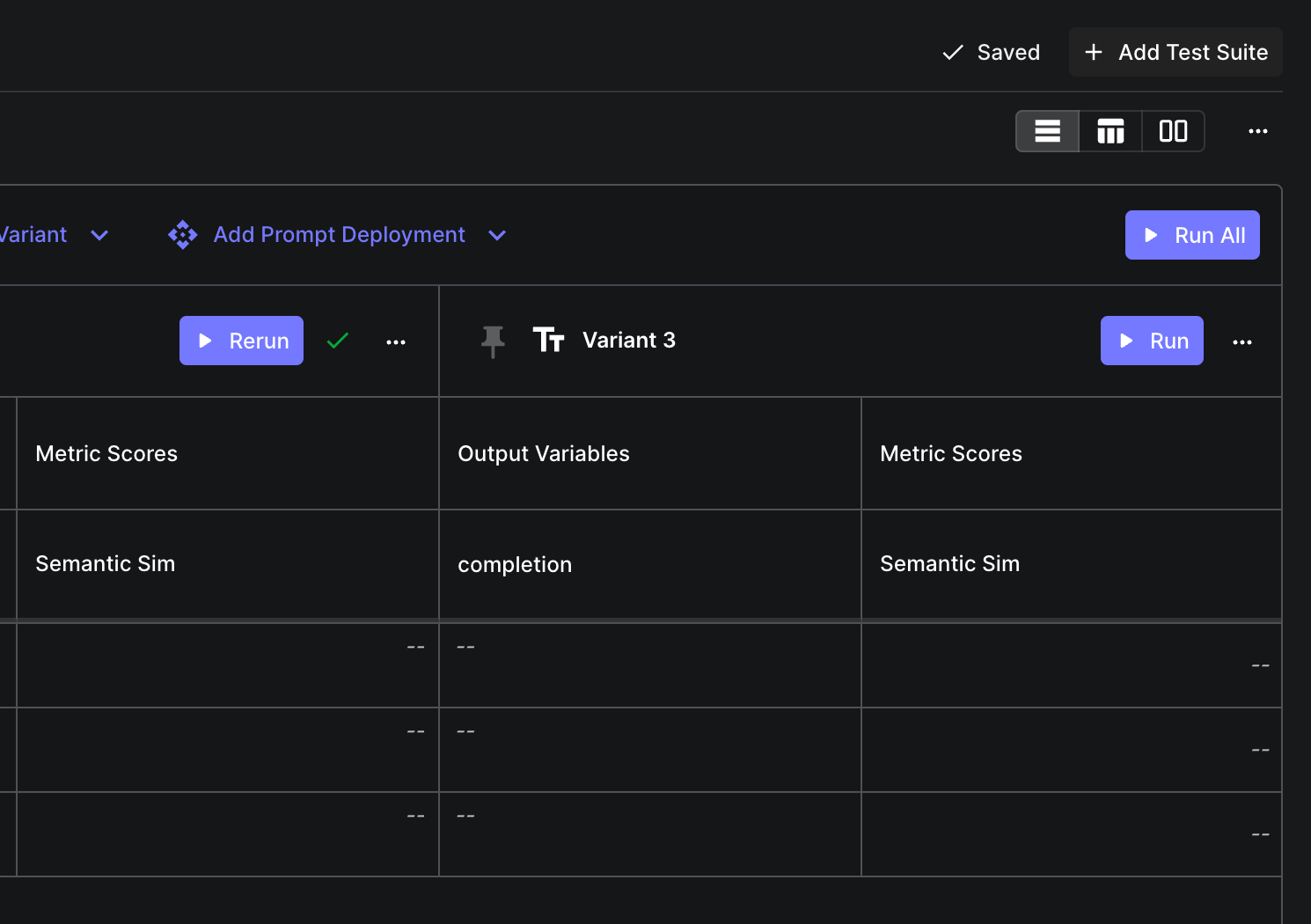
Run All Button on Evaluation Reports
There’s now a “Run All” button on evaluation reports that runs a test suite for all variants. Instead of running each variant individually, you can now run them all with one click.
Organization and Workspace Names in Side Nav
You can now view the active Organization’s name and the active Workspace’s name in the left sidebar navigation.
Breadcrumbs and Page Header Improvements
We’ve significantly improved folder and page breadcrumbs throughout the app. Prompts, Test Suites, Workflows, and Documents now display the entire folder path of your current page, making it much easier to navigate through your folder structure. We’ve also updated the overflow styling for breadcrumbs: instead of an ellipsis, you’ll now see a count of hidden breadcrumbs, which can be accessed via a dropdown menu.

As always, we value your feedback and look forward to hearing how these new features are making a difference in your workflows.
Happy building!



