OpenAI is having their DeepSeek moment! They've finally shipped an OSS model that's quite powerful.
Based on widely available benchmarks, GPT-oss 120b is landing close to some of the strongest reasoning models out there: OpenAI o3, Gemini 2.5 Pro, even Grok 4. And in many practical use-cases, I’d bet that you wont even notice the performance difference.
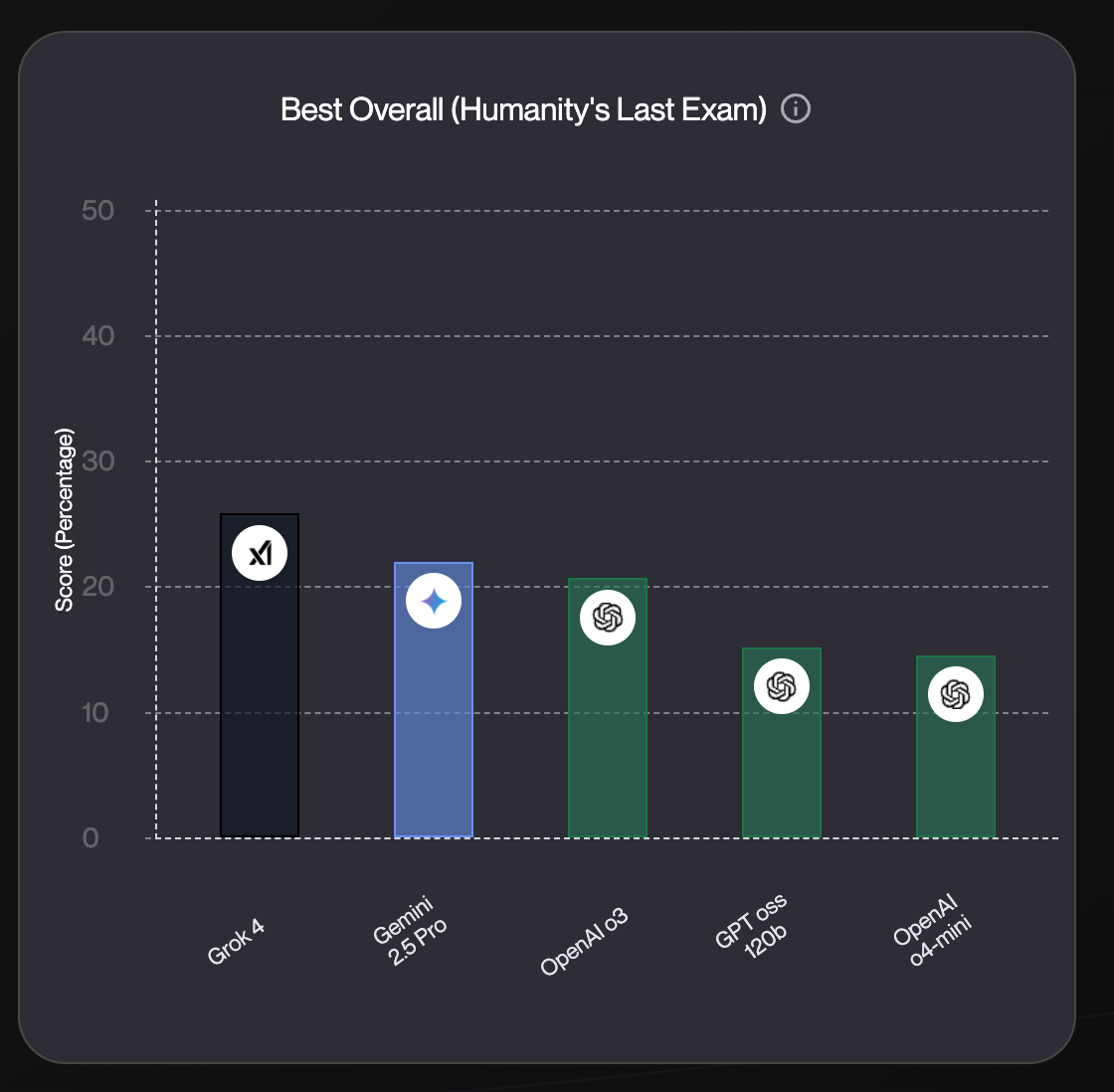
This begs the question: Can you actually run the OSS model and pay almost 90% less and still get the O3 performance?
The answer is pretty much yes.
In this article we’ll look at the cost, latency, speed comparisons but we’ll also run some of our home grown evaluations to test how well these models can adapt to new context, and work through math tasks.
Results
Here are the results from our analysis
Adaptive reasoning: When you modify famous puzzles, and add new context you’re making it very hard for any reasoning model to get to a correct answer. In our adaptive reasoning test, we used famous puzzles, but made them trivial. The models however weren’t really good at arriving to the right answer, no matter how much tokens they wasted to “reason through it”. GPT-oss got to 61% which is still on the lower end. The best model that we’ve had so far for this was OpenAI o3 with 68%. Math reasoning: We also ran a small math evaluation, to check if the GPT - oss 120b is actually as good as they’ve reported it. And it seems like it is. It had 63% accuracy, which is 11 points higher than OpenAI's o3 model. Price : he biggest advantage for gpt-oss 120b comes from it being OSS model and you can run it for free locally! But realistically, most prosumer apps will use infra providers like Groq, Cerebras, or SambaNova. And when you compare hosted costs, GPT-oss gives you similar performance to o3 at a fraction of the price. It’s actually 90% cheaper!! Speed: GPT-oss 120b is hands-down the fastest, it takes only 8.1s to first token and generates at 260 tokens/sec. Feels instant and smooth, even on longer outputs. OpenAI o3 is the second pick (15.3s / 158 tokens/sec). DeepSeek R1 , on the other hand, takes 86s to respond and crawls at 24 tokens/sec, not something you'd want in an interactive app.
Methodology
In this article we analyze two things:
Latency, cost and speed (e.g. How much faster is OpenAI o3 vs GPT-oss 120b?) Adaptive Reasoning evals Math evals
Evaluations with Vellum
To conduct these evaluations, we used Vellum’s AI development platform , where we:
Configured all 0-shot prompt variations for both models using the LLM Playground. Built the evaluation test bank & configured our evaluation experiment using the Evaluation Suite in Vellum. We used an LLM-as-a-judge to compare generated answers to correct responses from our benchmark dataset.
We then compiled and presented the findings using the Evaluation Reports generated at the end of each evaluation run.
🚀 If you want to compare this model on your own tasks, you can sign up to Vellum for free!
You can skip to the section that interests you most using the "Table of Contents" panel on the left or scroll down to explore the full comparison between OpenAI o3, and GPT OSS 120B.
Latency vs Speed
The graph below shows that GPT-oss 120b is actually the best model if speed is what matters for your use-case. It only needs8.1s to start and flies through output tokens at 260 tokens/sec.
OpenAI o3 is still a strong choice, with 15.3s latency, and 158 tokens/sec.
DeepSeek R1... not great. It took over 86 seconds to respond and crawled at 24 tokens/sec. Definitely not for anything interactive.

Pricing
Now obviously OSS models are free if you can run them on your local machine. You can follow this guide on how to spin it up with vllm.
But for most prosumer apps, you’ll probably end up running through infra providers like Groq, Cerebras, or SambaNova.
And when you look at the graph below, it’s kind of hilarious. GPT-OSS performs on par with OpenAI o3, but when you factor in cost, it’s not even close. Total no-brainer who wins here.

Adaptive reasoning evaluation
For this task, we’ll evaluate the models ability to adapt to new context. We are working with 27 very famoys puzzles, but modified .
For example, we added the Monty Hall problem in this set, but we changed one parameter:
Suppose you're on a game show, and you're given the choice of three doors: Behind one door is a gold bar; behind the others, rotten vegetables. You pick a door, say No. 1, and the host asks you, 'Do you want to pick door No. 2 instead?' What choice of door now gives you the biggest advantage?
In the original Monty Hall problem, the host reveals an extra door. In this case, it does not, and since there is no additional information provided, your odds remain the same.
The correct answer here is: “It is not an advantage to switch. It makes no difference if I switch or not because no additional material information has been provided since the initial choice.”
This is a very hard task for any reasoning model on the market right now. Let’s see how the GPT-oss 120b does!
We then ran all 27 examples in our Vellum evals:
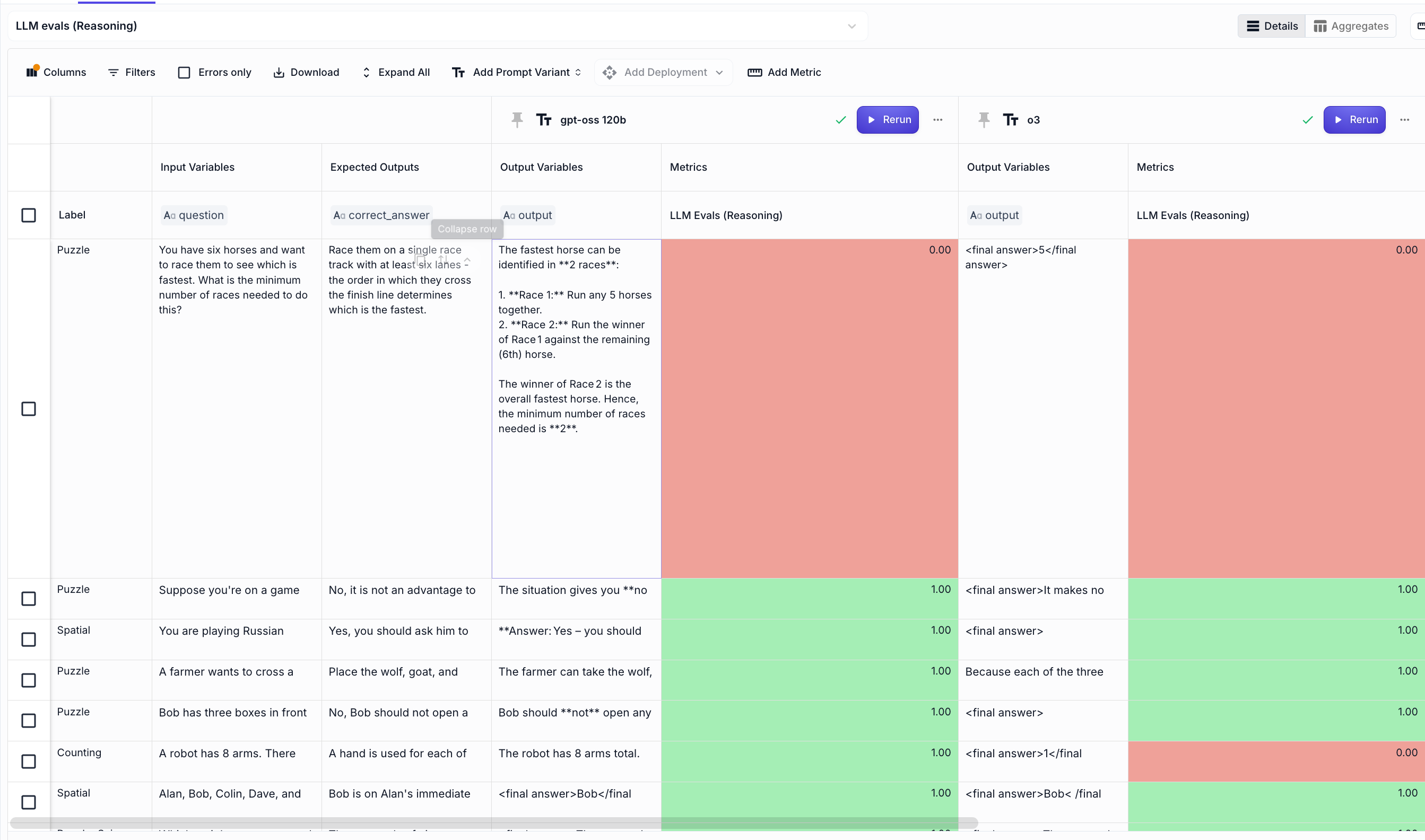
From there we got this accuracy:
GPT-oss 120b OpenAI o3 o4-mini DeepSeek Adaptive reasoning accuracy 61% 68% 50% 61%
From above we can see that GPT-oss is on par with DeepSeek, and OpenAI o3 is slignthly better. I’d say for this evaluation all of these models are close to a coin toss, and I’m excited to see if GPT-5 is going to be any better.
Some other observations:
Below we highlight two examples, where the model wastes a ton of tokens and then arrives at a completely wrong answer, without actually focusing the attention on the new context:
Example 1
Question: Suppose you're on a game show, and you're given the choice of three doors: Behind one door is a gold bar; behind the others, rotten vegetables. You pick a door, say No. 1, and the host asks you, 'Do you want to pick door No. 2 instead?' What choice of door now gives you the biggest advantage?
Correct Answer: No, it is not an advantage to switch. It makes no difference if I switch or not because no additional material information has been provided since the initial choice. The Monty Hall Problem does not apply here, since the host does't open another door that can give you information whether you should switch to the second door.
OpenAI O3: "This is essentially the “Monty Hall Problem” in disguise. The key is that the host’s offer to switch gives you new information—namely, that the other unmentioned door (door No. 3) is not the prize. By asking if you would like door No. 2, the host is implicitly ruling out door No. 3. • If you stay with your first choice (door No. 1), your chance of winning remains the 1 / 3 it was at the start. • If you switch (in this case, to door No. 2), the probability that you win jumps to 2 / 3. Hence, switching doors yields the higher probability of winning the gold bar."
Example 2
Question: A group of four people needs to cross a bridge at night. The bridge is very old and rickety. They have only one torch, and because it's nighttime, the torch is necessary to cross the bridge. Each person walks at a different speed:A takes 1 minute to cross,B takes 2 minutes,C takes 5 minutes, andD takes 10 minutes.What is the fastest time they can all get across the bridge?
Correct answer: 10 minutes, the speed of the slowest person as they cross the bridge together
- GPT-oss 120b: "...First, the constraints: the bridge can only hold two people at a time, and the torch is needed each time someone crosses. So, if two people go over together, one has to come back with the torch….*Thus the fastest possible total time for all four to get across the bridge is 17 minutes. "
Math evals
For this task, we’ll compare the models on how well they solve some of the hardest SAT math questions . This is the 0-shot prompt that we used for both models:
You are a helpful assistant who is the best at solving math equations. You must output only the answer, without explanations. Here’s the <question>
We then ran all 50 math questions:
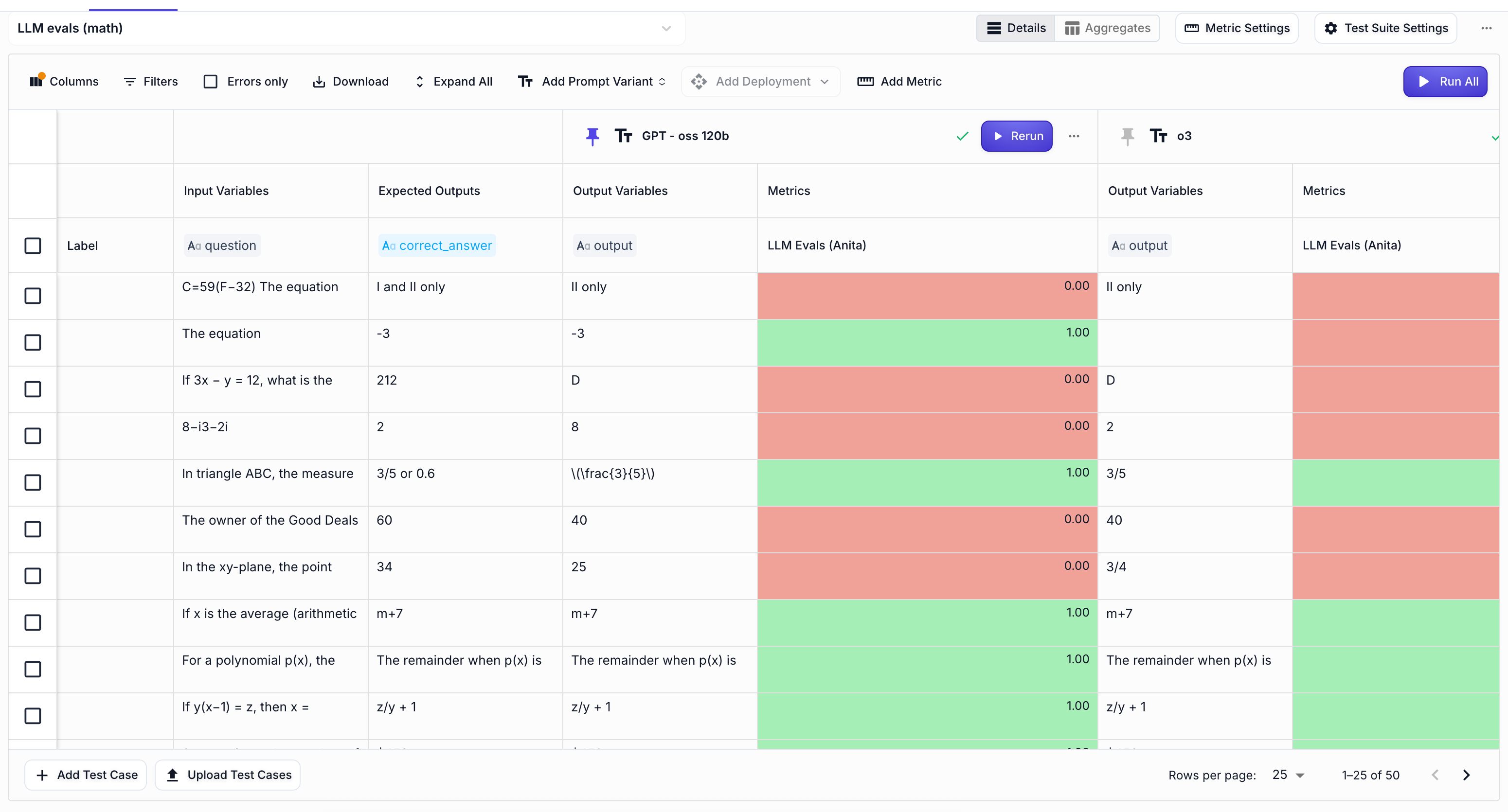
And here are the results we got:
GPT-oss 120b OpenAI o3 o4-mini DeepSeek Math reasoning accuracy 63% 52% 60% 60%
Conclusion
So here’s the TL;DR: GPT-oss 120b holds its own.
If you’re shipping AI products, this might be the most practical tradeoff you can make right now.