With this guide, we’ll demystify agent building, and surface details on how to build agents that are not only cool, but practical and useful to you and your team.
The following few sections will cover everything you need to know about memory, context engineering, tool use, and end-to-end testing. You’ll also learn practical tips on how others have built their AI agents and how they’re using it
Overview
Get the latest information on:
The core components of any LLM agent: MCP, tool use, context engineering, memory The advantages and limits to different agent architectures The strategy that successful teams adopt to make agents work for them
Why this matters
While AI adoption is surging, a recent MIT Research report found that around 95% of GenAI pilots still fail to reach production. Instead of transformation, most organizations see AI as an expensive effort with little payoff.
Companies struggle to get agents working because they don’t have the know-how to design them in a way that’s both reliable and useful.
For context, the global LLM market surged from $5.6 billion in 2024 to a projected $36.1 billion by 2030 , while Mckinsey reports that AI adoption jumped from 55% to 78% of organizations in just two years . In a recent IBM survey , 99% of developers building enterprise AI applications were exploring or developing AI agents.
Now, the next wave is here: LLM agents.
Most organizations still struggle to answer the following questions:
What exactly are LLM agents and what's needed to build them? How do you make them work reliably? Should you build your own AI agent stack or use a platform/framework?
In the following few sections we'll try to provide answers and help make the process easier.
What is an LLM agent?
Using an LLM to call tools in a loop is the simplest form of an LLM agents, but these agent‘s capabilities exist on a spectrum of autonomy.
For example, a simple note generator might only need two tools and minimal planning, while a more complex research agent, will benefit from using subagents that add more layers of logic and a higher level of agentic behavior.
Different use cases often need different levels of agentic behavior and complexity along this spectrum. We wrote more about it here .
How can you use an LLM agent?
LLM agents are used to automate your work from simple workflows to complex workflows that require reasoning, decision-making, and tool use. Some may call this LLM automation interchangeably. Here are some of the top use cases:
Customer support automation: resolving tickets, troubleshooting issues, and escalating only when necessary. Research & knowledge retrieval: gathering, summarizing, and synthesizing data across multiple sources. Data analysis & reporting: pulling from structured/unstructured data to generate insights or dashboards. Software development assistance: generating code, debugging, and suggesting improvements. Process automation: orchestrating multi-step workflows like onboarding, compliance checks, or document processing. Personalized recommendations: adapting to user history, preferences, and past interactions. Decision support: running “what-if” scenarios, evaluating tradeoffs, and presenting structured options to teams.
{{templates}}
How do LLM agents work?
An LLM agent is basically an LLM (like GPT-5) that doesn’t just answer text, but it can also decide what to do next by calling tools, APIs, or other functions.
Here's an example of a flight planner LLM agent flow:
Step What Happens Example with “Book me a flight NYC → SF tomorrow” 1. User gives a task The user requests something. “Book me a flight from NYC to SF tomorrow.” 2. LLM interprets The model figures out what needs to be done. Understands: search flights, compare, then book. 3. Planner / Reasoning loop The agent breaks the task into steps and decides order of actions. Step 1: search flights → Step 2: pick best option → Step 3: book. 4. Tool calls The agent calls APIs, databases, or services. Calls flight search API, then payment API, then calendar API. 5. Check results Reads responses, checks if more work is needed, loops if required. Confirms available flights, checks payment success, verifies booking. 6. Finish Returns final answer to the user. “Your flight from NYC to SF is booked for tomorrow at 9am. I added it to your calendar.”
Controlling the behavior of a more complex agent will entail a lot more context engineering, tool and memory management.
Agents run on four things: the model, memory, context, and tools. To make them reliable in production, you need the right controls and guardrails on each. Here’s a quick checklist we’ll unpack next:
Component What it is What to do for production Short-term memory Context inside one LLM call Keep minimal context, cap tokens, normalize tool outputs before reinjection, drop irrelevant text, log key state to long-term store Episodic memory (long-term) Log of past events Write concise summaries, index by user and time, add TTL and redaction, permission checks, audit logs Semantic memory (long-term) General knowledge Use vetted sources, chunk and embed with versioning, add freshness tags, evaluate retrieval quality, auto-expire stale docs User-specific memory (long-term) Personal history and prefs Get consent, least-privilege access, PII redaction, clear retention rules, fast lookup keys, deletion on request Context engineering Control what info the agent sees Define state schema, carry only critical vars, prune on each turn, add cost and size guards, trace what was shown to whom Function calling Model emits a structured call you run Strict JSON schemas, runtime validation, idempotency keys, retries with backoff, timeouts, error handling, tests and mocks Model Context Protocol (MCP) Standard way to expose tools Version tools, strong auth per tool, scopes and rate limits, health checks, contract tests, deprecate safely, observability on calls
Memory management for agents
Agents rely on memory to maintain continuity, personalize behavior, and reason over past interactions. Memory typically comes in two forms: short-term and long-term. Here’s a quick overview:
Memory Type Purpose Example Short-term Holds context in a single call Current user input + last output Episodic (long-term) Stores logs of events “User asked about hotels in London on June 2” Semantic (long-term) Knowledge not tied to time Facts in a vector DB, definitions, knowledge graph entries User-specific (long-term) Personalized history/preferences “User compared UA flight prices on July 13, 2025”
Short-term memory
The context passed into a single LLM call. It includes the latest conversation or instructions, but gets wiped after each call unless explicitly retained.
For example, if a user asks “Summarize this article” and then immediately follows with “Make it bullet points,” the second prompt only works because the short-term memory still contains the article context.
Long-term memory
Persistent across sessions and allows the agent to “remember” past interactions, knowledge, and decisions. It’s broken into three main types:
Episodic Memory: Stores logs of specific past events or conversations. (e.g., “User asked about hotels in London on June 2”) Semantic Memory: Holds general knowledge that isn’t tied to a specific time. Vector databases for unstructured info (e.g., definitions, facts), structured databases or knowledge graphs for organized data. Complete, User-Specific Memory: Stores detailed, user-specific records. (e.g. Remembering that the user compared flight prices between UA 756 and UA 459 on July 13, 2025.)
For example, long term memory is used when a customer support agent recalls a user’s past issue with a payment method weeks later, and proactively suggests troubleshooting steps without the user repeating details.
How should LLM agents manage short-term and long-term memory?
For managing short term memory:
Keep only the minimum context needed for the next step. Normalize tool outputs before re-injection. Purge irrelevant details to control token cost. Commit important state changes into long-term storage.
For managing long-term memory:
Distill verbose logs into compact summaries before writing. Separate into episodic (events), semantic (facts), and user-specific (profiles). Use retrieval queries filtered by recency + relevance. Apply retention policies (expiration, redaction, consent) to prevent bloat or drift.
For a more comprehensive guide to handling LLM agent memory check out our resource: How Should I Manage Memory for my LLM Chatbot? .
Context engineering
Good agents only work with good context. This means more than just stacking information into the prompt, it’s about controlling what’s visible to each agent at the right time.
In a simple flow, that might mean carrying state between steps in a single session. In more advanced cases, like multi-agent systems or long-running tasks, context management becomes a core part of the design.
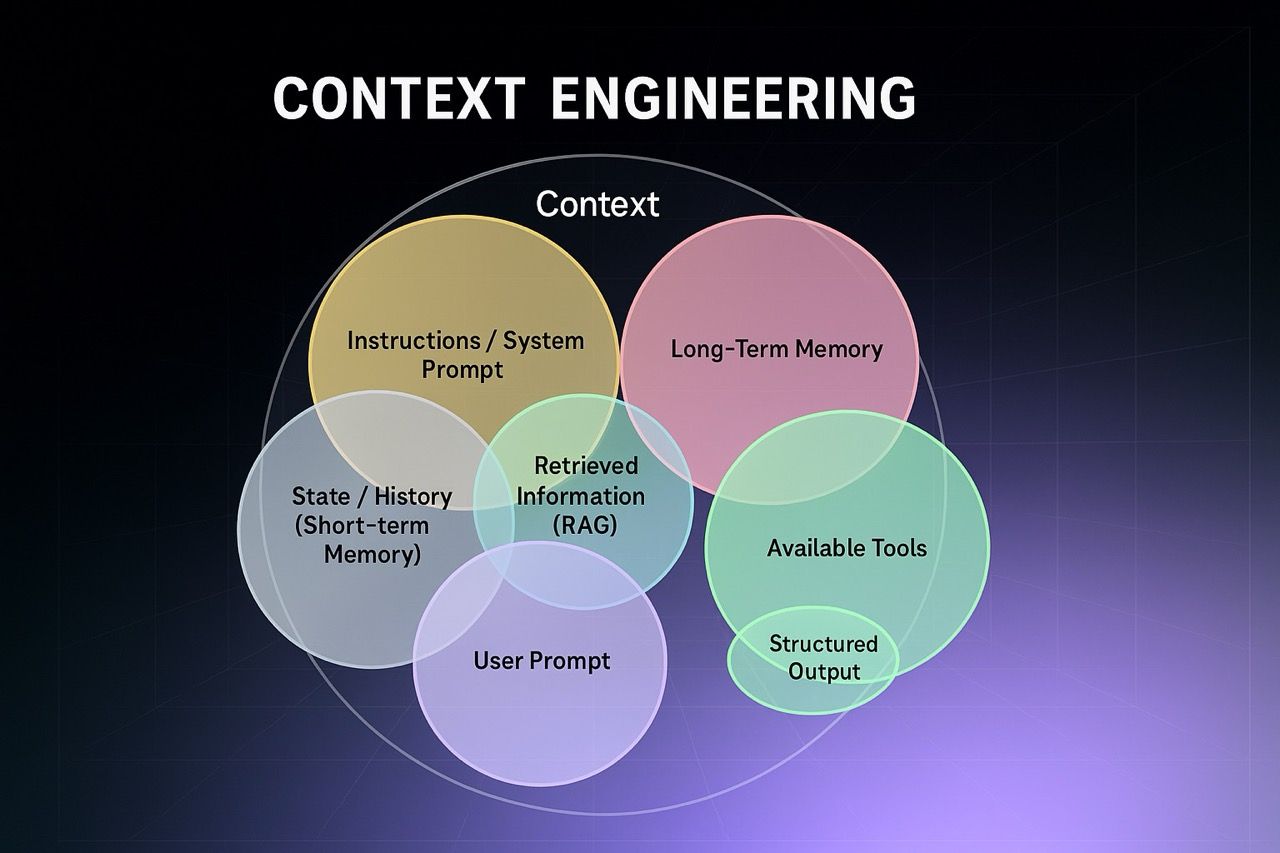
How do you engineer context for reliability and cost?
Context engineering is about controlling what information the agent sees at each step so it can make good decisions without wasting tokens or drifting off course.
Extra tips are to:
Carry state across steps: preserve only the critical variables or outputs between turns.
Use shared context for multi-agent workflows: provide each subagent only the slice of context it needs.
Limit irrelevant or stale inputs: actively prune outdated or non-essential content from the prompt.
Dive deeper into context engineering in our free resource guide to context engineering for LLM agents: Why ‘Context Engineering’ is the New Frontier for AI Agents .
Tool use for LLM agents
Agents using tools can mean calling an API, querying a database, running a function, or interacting with external systems that extend the agent’s capabilities beyond pure text generation.
The two main ways to integrate tools are through function calling and model context protocol (MCP) .
When combined, these components make it possible to build agents that are context-aware, act on external data, and improve over time.
What is function calling?
Function calling is when an LLM doesn’t just return plain text, but instead outputs a structured instruction (usually JSON) that tells your system what function to run, with what parameters.
But don't be mislead by the name. Function Calling will not automatically “call” your functions. It just lets you define them so the model can generate the right arguments for them.
How do LLM agents use function calling?
The model emits the function name and parameters in JSON, your system executes it, and the results flow back into the conversation for the agent to use.
Example :
When you send a prompt to the model (like What's the weather in Paris?) and include this function definition , the model might respond like this:
Function calling is not the literal LLM agent running the function, rather the agent is telling your client or backend system that the model wants you to run get_weather({ location: "Paris" }) . When the function is ran, the weather data is retrieved then used as results to be sent back into the chat as part of the next message.
Read more here: How does Function calling work.
Model context procotol (MCP)
Model Context Protocol (MCP) is an LLM standard for defining and connecting external tools, APIs, and data sources in a structured way that LLM agents can reliably understand and use.
Rather than building custom connectors for every integration, MCP lets you describe tools once and make them universally accessible to different models.
This standardization makes it easier to scale agents, maintain consistency, and plug into multiple systems without re-engineering each time.
Learn more about MCP and how to use it in our resource guide: How does MCP work .
MCP tool definition example:
At runtime, the LLM receives this tool definition along with the user prompt. If the user says something like:
"Can you check flights from JFK to LAX on September 15th?"
The LLM can:
Recognize that this matches the get_flight_prices tool Extract the parameters: origin=JFK , destination=LAX , date=2025-09-15 Call the tool (or emit the function call for the orchestration layer to execute) Use the returned data to generate a helpful response
When should LLM agents use tools function calling vs. MCP?
Function calling is a way for an LLM to tell your system “I want you to run this function with these arguments.” You define the functions up front (name, description, schema), the model emits a JSON call, and your backend executes it. It’s lightweight and great for a few tools, but every integration is custom.
MCP (Model Context Protocol) is a standard for exposing tools and data sources in a consistent way to any model. Instead of defining custom functions per integration, you describe the tool once in MCP, and it can be reused across agents and models. MCP scales better when you need to plug into many APIs, maintain versioning, enforce auth, and share definitions across systems.
Think of it like this:
Function calling = direct wiring. Works fast, but every new tool is manual setup. MCP = universal adapter. Standardized contracts so multiple agents and models can use the same tool definitions.
Approach Best For Tradeoffs Function Calling Quick, low-latency, task-specific calls Limited scalability; custom wiring for each integration MCP Standardizing many tools/data sources More setup overhead; less direct control per call Combined Fast execution plus scalable governance Slightly higher complexity to orchestrate both layers
LLM agent architecture patterns
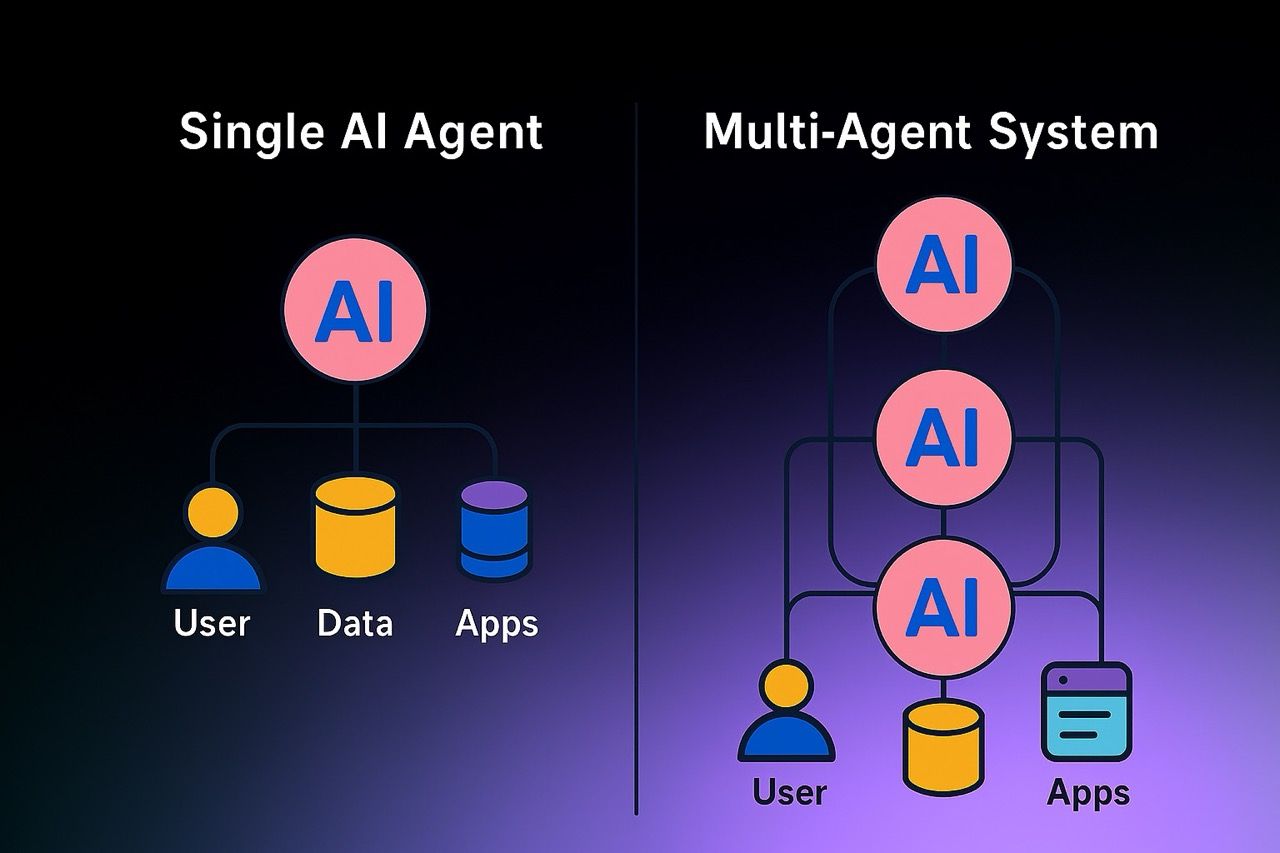
Multi-agent systems
A multi-agent system is an architecture where multiple specialized agents work together under the coordination of a lead agent.
This setup is especially well-suited for “deep research” tasks because:
Research is open-ended and cannot be hardcoded into linear steps. Multiple sources and tools must be queried in parallel. The workload often exceeds a single agent’s context window, requiring task splitting.
Efficacy of multi-agent systems
A recent Anthropic research report showcased a successful multi-agent research system that was organized with an Opus 4 lead agent managing coordinated Sonnet 4 specialized subagents that worked on tasks in parallel.
This system outperformed a Opus 4 single-agent by 90.2% on internal research evaluations, with token usage explaining 80% of performance variance in their BrowseComp analysis.
When multi-agent systems are the best fit
Task Type Why It Works Well Open-ended research You can’t hardcode the steps. Agents need to adapt and explore dynamically. Breadth-first queries Tasks that involve checking many sources or directions at once. Web + tool searches Each subagent can use a different tool or search strategy in parallel. Complex info gathering When info doesn’t fit into one context window, agents split up the load. High-token, high-value tasks Great for tasks where more effort (and tokens) = much better results. Dynamic workflows When the path depends on what’s found along the way—so agents must pivot. Large, multi-step lookups Example: “Find all board members of S&P 500 IT companies” — decomposed into parallel lookups.
Single-threaded LLM agents
A single-threaded agent runs linearly so every action sees the full, continuous context and prior decisions. This avoids conflicting assumptions between parallel workers and dramatically improves reliability in production.
Efficacy of single-thread LLM agents
According to Cognition , single-thread LLM agents are preferred over multi-agent systems because:
Shared context by default: One trace, no cross-agent context gaps. Coherent decisions: Fewer implicit conflicts than coordinating parallel subagents. Production reliability: Simpler orchestration reduces fragile failure modes.
When single-thread LLM agents are best fit
Scenario Why Simple fact-finding A single agent is faster, cheaper, and doesn't need overhead. Perfect for straightforward queries. Tightly coupled tasks When steps depend heavily on each other, a single agent keeps state and flow consistent. Shared context is essential If all decisions need the same background, one agent avoids duplication or misalignment. Small scope or short horizon For short tasks, spinning up subagents adds unnecessary complexity. Code generation and editing Most coding tasks need consistent memory and step-by-step logic—ideal for a focused, single agent. Real-time interactions Live chat, customer support, or assistant-style use cases benefit from one steady, responsive agent.
When to choose multi-agent vs. single-thread llm agent architecture patterns?
Single agents excel at short, tightly coupled tasks, while multi-agent systems excel at open-ended, parallel tasks.
Choose based on complexity, cost tolerance, and required adaptability.
Factor Single Agent Multi-Agent Best for Short, tightly coupled tasks Open-ended, parallelizable tasks Latency/Cost Lower Higher (parallel calls, more orchestration) Reliability Consistent, fewer moving parts Can fail if orchestration is brittle Context Sharing Easy — one agent maintains state Hard — must pass/shard context across agents Flexibility Limited adaptability Highly adaptive, breadth-first exploration
Steps to building an LLM agent
1) Start small, and outline goals
Clarity and alignment: define the problem, scope, and success criteria before any code is written. ( writing a detailed PRD is useful here) Reliability and safety: documenting memory, context, and compliance needs up front reduces failure modes in production. Faster iteration: clear goals and acceptance criteria make it easier to test, refine, and scale with confidence.
Spending significant time on this step is curcial in this process.
2) Choose the model and base rules
Set temperature, max tokens, and step limit System prompt: role, style, when to call tools, when to ask for help
3) Select the right LLM agent architecture
Architecture defines reliability, cost, and complexity so choosing wrong architecture adds unnecessary overhead or limits adaptability.
Single-threaded agents excel at linear, tightly coupled tasks Multi-agent systems shine in open-ended, research-heavy, or parallel work
4) Build the control loop
Thought → action → observation Stop when goal is met or on guardrail triggers Retries with backoff for flaky tools
- Plan LLM agent memory and context Good memory/context design drives accuracy, reliability, and cost.
Define short-term scratchpad rules and long-term stores, then set retrieval (recency + relevance) and retention/TTL policies.
5. Integrate the right tools
Tools turn the agent into an actor but can add latency and complexity.
Use function calling for fast, task-specific actions; use MCP to standardize many integrations; combine them when you need both speed and governance.
6. Add evaluations and guardrails
You need proof that changes improve real outcomes without regressions.
Track accuracy, latency, reliability, and cost with clear pass/fail gates, rollback paths, and human-in-the-loop checkpoints.
To learn more about LLM agent evaluations, approaches, and frameworks follow this guide: Introduction to Evaluations in Vellum
7. Prototype, test, and iterate
Small, instrumented pilots surface issues early and speed learning.
Build in a sandbox, review traces, A/B prompts/models against KPIs, and refine before scaling.
8. Roll out in stages
Gradual expansion limits risk and builds confidence with evidence.
Start with a pilot cohort, monitor SLOs and feedback, and scale as reliability and compliance standards are consistently met.
Steps Purpose Actions 1. Start with a PRD Aligns the team on problem, scope, and success criteria before any code. Define problem, users, KPIs (accuracy/latency/cost), constraints, and acceptance criteria. 2. Choose your build approach Sets speed/flexibility/ownership tradeoffs for delivery and maintenance. Pick Platform (best default), Framework (deeper control), or Raw APIs (full ownership) based on constraints. 3. Select the right architecture Determines reliability, cost, and orchestration complexity. Use single-threaded for tightly coupled tasks; use multi-agent for open-ended or parallel work. 4. Plan for memory and context Drives accuracy, reliability, and cost efficiency. Define short-term scratchpad rules and long-term stores; set retrieval (recency+relevance) and retention/TTL. 5. Integrate the right tools Turns agents into actors but can add latency/complexity. Use function calling for fast task calls; use MCP to standardize many integrations; combine when needed. 6. Add evaluations and guardrails Prevents regressions and keeps production safe and predictable. Track accuracy, latency, reliability, and cost with pass/fail gates, rollback paths, and HIL checkpoints. 7. Prototype, test, and iterate Surfaces issues early and accelerates learning cycles. Build in a sandbox, review traces, A/B prompts/models against KPIs, refine before scaling. 8. Roll out in stages Limits risk and builds confidence with evidence. Pilot with a small cohort, monitor SLOs and feedback, expand as reliability and compliance are proven.
Doing all of this takes a lot of effort, time, and learning. You can move faster by working with an agent platform or consultants who can help guide the process.
Agent platforms: Buy vs build
Since most enterprises still fail to get AI pilots live due to lack of tooling and strategic partnerships, the decision to build in-house vs. buy a framework or platform one of the most critical early calls in any AI program.
Here’s a list to help you decide the best option for your team:
Approach Pros Cons Build In-House Full control over orchestration, memory, and tool logic Tailored to exact compliance and security needs Flexibility to innovate beyond existing frameworks Heavy engineering lift to design evals, guardrails, observability Slower time to production; high TCO Higher risk of joining the 95% failure rate if infra isn’t mature Buy a Framework/Platform Faster path to production with built-in evals, governance, and rollout controls Lower engineering overhead; accessible to cross-functional teams Proven to reduce risk of pilot failure Less granular control over low-level agent logic Dependency on vendor roadmap/features May require compromises on customization
Build from first principles: define the problem, pick the right architecture (single vs. multi), and wire up memory, context, and tools. This guide shows how to choose a framework or platform and ship production-grade agents with evals, guardrails, and iteration.
Pick the lightest approach that delivers value fast:
Platform: Best default — ship quickly with evals, governance, and rollout controls built in. Framework: Use when you need deeper customization and control of agent logic. Raw APIs: Only when strict compliance or full ownership of orchestration is required.
Option Pros Cons Best Fit Platform Fast iteration Built-in governance Evaluations out of the box Less low-level control depending on platform Startups, PLG-driven teams Framework Flexible Integrates deeply Steeper engineering overhead Enterprise ML & product teams Raw APIs Full control Maximum compliance Long setup No guardrails Highly regulated industries, R&D labs
Best agent platforms
- Vellum : Fastest path to production with experiments, evals, versioning, routing, and governance in one place. Add custom logic via SDK/nodes.
Best for: collaborative teams that need all depths of orchestration, evaluations, and strong developer level control.
- n8n : Low-code automation with AI nodes and 1,000+ integrations , plus self-hosting.
Best for: stitching agent actions into broader business workflows with light engineering.
- Zapier Agent : No-code automations and embedded AI actions for quick prototypes and ops flows.
Best for: non-dev teams who need to stand up agent-powered processes fast.
Best agent frameworks
If you decide this approach, here’s a shortlist of the top 3 best frameworks to build LLM agents:
- LangGraph (LangChain): Graph/state-first orchestration with rich tool/memory/RAG primitives and a huge ecosystem
Best for: productionizable custom flows where you need fine control without rebuilding basics.
- CrewAI : Opinionated multi-agent roles and handoffs that make collaborative research/execution fast to prototype
Best for: when you need agents to specialize and coordinate out of the box.
- AutoGen : Conversation-as-program pattern for agent-to-agent collaboration with flexible tool use
Best for: iterative problem solving where dialogue drives planning.
FAQs
What’s the difference between an LLM agent and a chatbot?
Chatbots answer prompts directly; agents plan, use tools, and act. This makes agents adaptive for tasks like research, workflows, and automation.
What are the best model providers for LLM Agents?
According to LLM Leaderboard here’s the best model providers per category:
Reasoning & Problem Solving: GPT-4.1 (OpenAI) or Claude 3.5 Sonnet (Anthropic) Coding & Technical Tasks: GPT-4.1 or Claude 3.5 Opus often lead Knowledge & Research: Claude 3.5 Sonnet is consistently strong Speed / Cost Efficiency: GPT-4.1 Mini or Claude 3 Haiku usually top here
When should I use a single agent instead of multi-agent?
Single agents excel at short, tightly coupled tasks. They’re faster, cheaper, and more reliable when steps depend heavily on shared state.
When is a multi-agent system better?
Multi-agent wins for open-ended, research-heavy, or parallel tasks. Each subagent can specialize, search broadly, and combine results.
How do LLM agents use memory?
Agents use short-term memory for immediate context and long-term memory for persistence. Long-term splits into episodic, semantic, and user-specific stores.
What is context engineering in LLM agents?
Context engineering is controlling what data the agent sees at the right time. This reduces costs, improves reliability, and avoids irrelevant or stale prompts.
What’s the difference between function calling and MCP tools?
Function calling emits structured calls your system executes; MCP standardizes external tools. Function calls are quick to start; MCP scales across many connectors.
How do I measure LLM agent success?
Measure beyond accuracy: track latency, reliability, and cost. These determine if an agent can operate safely in production at scale.
What is an LLM agent framework?
An LLM agent framework is a developer toolkit (usually code-first) for building agent loops. Frameworks offer planning, tool use, memory, and orchestration, without reinventing the plumbing. It provides primitives (nodes/graphs, tool schemas, memory/retrievers, evaluators) so engineers compose custom agents in code and control runtime behavior end-to-end.
Do I need a framework to build an LLM agent?
Not always. APIs let you start quickly, but frameworks and platforms provide orchestration, memory, and evaluation features as complexity grows.
Should I build an LLM Agent using my own stack or a platform?
Platforms accelerate time-to-value; frameworks give control; raw APIs maximize flexibility. Your choice depends on team size, compliance, and experimentation needs.
Extra Resources
Looking to go deeper on building and scaling LLM agents? Check out these guides and research:
How to evaluate an LLM eval platform LLM Parameters Guide → LLM Memory Management Guide → LLM Prompt Agent Guide → LLM Leaderboard →