Today, we’re excited to share the new additions and improvements to Evaluations .
Our new, more powerful Evaluations product allows you to compare any prompt or workflow output with a baseline of your choice, using any number of metrics you choose. Additionally, Evaluations now include an increased number of metrics and offers greater flexibility for developing any metric type you might need.
On top of all that, we're introducing our new Evaluation Reports that enables you to analyze aggregate metrics like Median, P90 & track improvements / regressions across your bank of test cases.
The Problem
In 2023, developers and companies dove headfirst into leveraging LLMs for creating innovative apps. This rush for development emphasized the need for rapid prototyping but often overlooked the critical aspect of ensuring these applications could perform reliably in real-world scenarios.
This oversight led to notable mishaps. Only this year, we had car dealership that accidentally sold a car for $1, and a major airline had to honor a refund policy that their chatbot made up — all due to a lack of thorough evaluation prior to launching their chatbots.
As we step into 2024, the landscape has shifted.
The focus is now on developing AI apps that are not just innovative but also robust, reliable, and ready for production.
However, ensuring an AI application's readiness for deployment is no small feat.
Evaluations: The Backbone of AI Reliability
Given our vantage point of working with thousands of companies building AI systems in production, we’ve seen evals as a core component of the development lifecycle (read more here ).
For your AI apps to remain reliable, a dynamic and comprehensive evaluation framework is essential . It should scrutinize every facet of your AI logic, allowing for comparisons across a multitude of scenarios and providing detailed performance metrics. Evaluation metrics differ based on the task and whether you have access to labeled data, read more here .
Embracing test-driven development is crucial in the process of building production quality applications.
It empowers developers to swiftly pinpoint and rectify unforeseen behaviors in LLMs, and fix bottlenecks before they become a nuisance.
Impact so Far

The original Evaluations product that we launched in May of last year supported unit testing for LLMs, with the ability to test the quality of your prompts using out-of-the-box metrics and a bank of test cases.
Since then, we’ve seen the Evaluations product used by over 200 companies who have run over 5,000 different unique evaluations. These evals have spanned hundreds of thousands LLM runs.
Today, evaluating LLMs is more important than ever, extending beyond prompt testing in the prototyping phase.
Vellum’s Evaluations are critical for helping us make sure changes we make to our model deployments don’t cause performance regressions. Trying out new models or upgrading to the latest versions of models would have been painful without being able to backtest easily using different eval criteria for different deployments. - Advith Chelikani, Co-Founder at Pylon
That’s why we’re excited to share more details about the improved, more powerful Evaluations and our brand-new Evaluation Reports.
More Powerful Evaluations
Previously, Evaluations enabled you to run your Prompts in bulk to ensure their reliability prior to deploying them to production. While this was very useful, you asked for more options, especially when updating deployed Prompts, or more advanced multi-step applications ( Workflows ).
Baseline Comparison
Now, you can compare any Prompt/Workflow against a baseline Prompt/Workflow of your choice. This feature is valuable for determining the clear winner when prototyping. In production, you can add the currently deployed Prompt/Workflow as a baseline and compare new draft Prompts/Workflows accordingly.
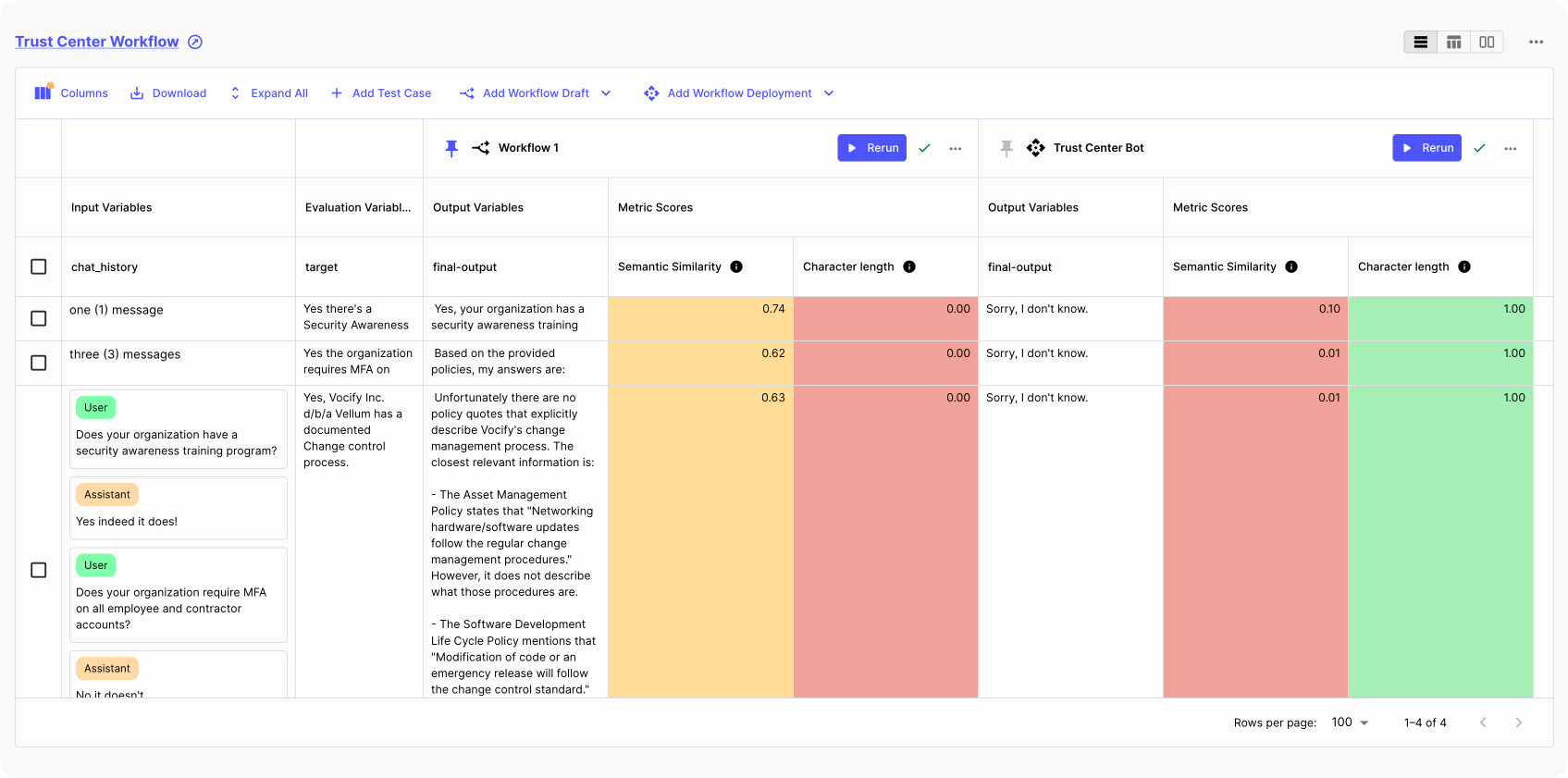
Unit testing
It’s now easier to perform unit testing on each step of your AI app logic.
For example, if you’re building a customer support chatbot, it's crucial to perform unit testing on various components to ensure the chatbot functions properly. You’d like to evaluate every step, from intent recognition, truthfulness, context retrieval precision, to escalation to human agent.
But, to perform these end-to-end evaluations, you need to utilize a mix of unique and, at times, several metrics designed to evaluate the specific steps of your logic.
Multi-Metric Evaluation
As outlined earlier, different kind of LLM tasks have different evaluation approaches. We suggest compiling a basket of metrics while evaluating your app.
Speaking of multiple metrics: Evaluations now offers the capability to compare these variations using a variety of out-of-the box or custom made evaluation metrics.
For example, you can evaluate a prompt based on both Semantic Similarity (built-in evaluator) and C orrectness .
In this context, Correctness refers to a custom LLM-based evaluation metric that can now be easily built with Vellum — which leads us to the next announcement…
LLM-Based Evaluation
Researchers showed that strong LLM models like GPT-4 can achieve over 80% agreement with human evaluators, thus making LLM-based eval a scalable and explainable way to approximate human preferences.
So in cases where you don’t have access to ground truth data, using an LLM to evaluate the output of another is an excellent alternative.

Today, we’re introducing a flexible LLM based evaluation metric which enables one LLM to evaluate the outputs of another.
This approach enables LLM-based evaluation for outputs that may be hard to score via traditional methods. This is useful in cases when you’d like to use your own AI-driven evaluation criteria to check for things like correctness, readability, relevance etc. Several out of the box LLM eval metrics are already supported — let us know if you want to try them!
But that’s not the only custom option.
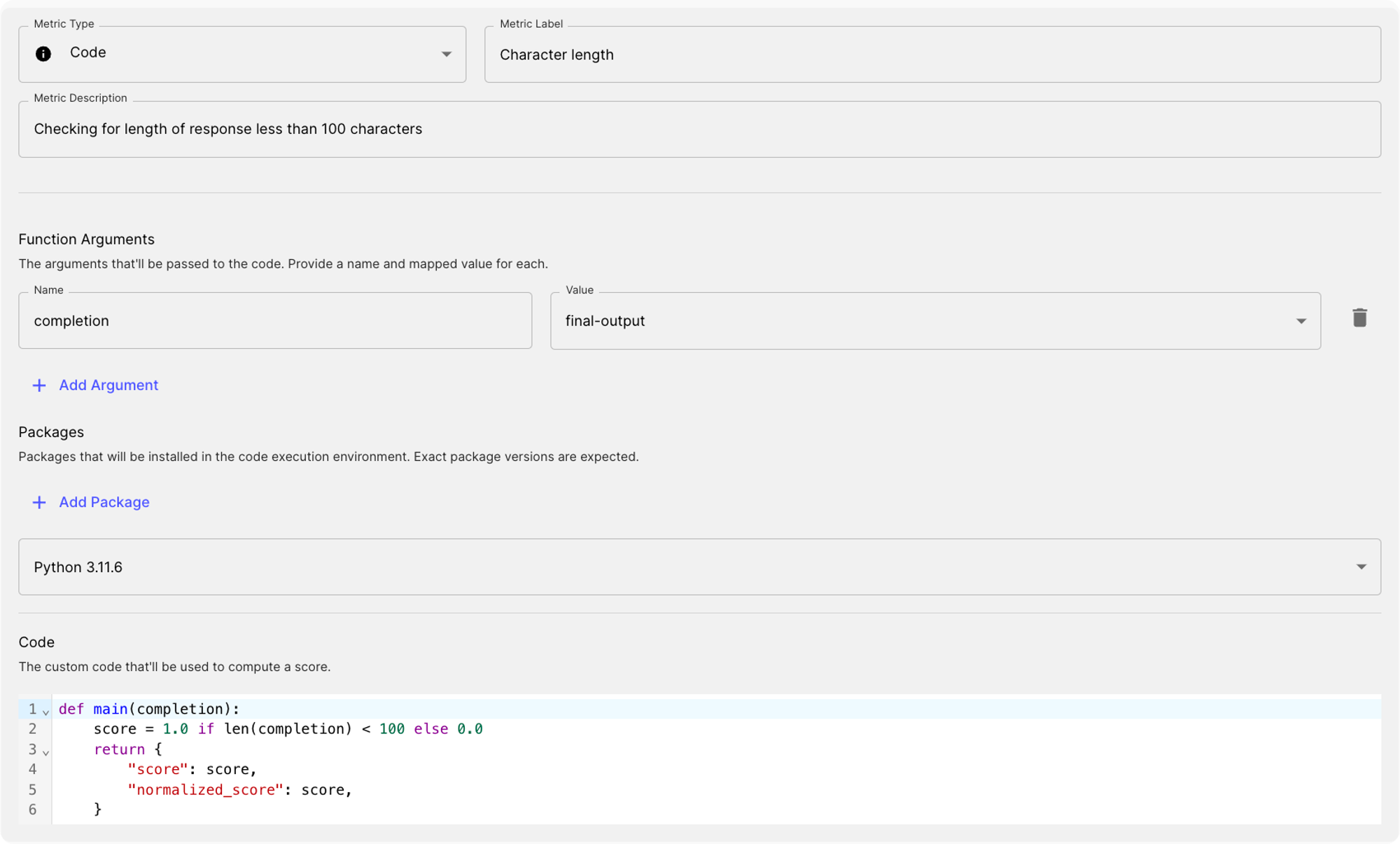
Code and Webhook Evaluation Metrics
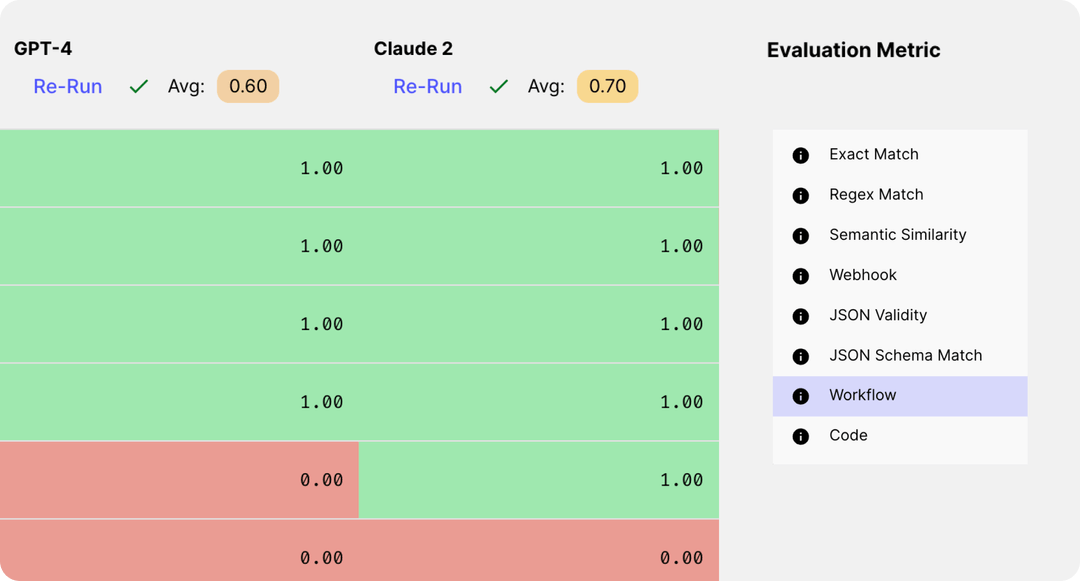
LLM-based evaluation is super useful, but sometimes you’d like to use out-of-the-box evaluators. Up to now, we’ve provided support for five built-in evaluators, each serving its unique purpose effectively:
Exact Match : Checks if the output is exactly equal to the target; Regex Match : Checks if there’s a match between the specified regular expression and the output; Semantic Similarity : Checks if the output is semantically similar to the target; JSON Validity : Checks if the output is valid JSON; JSON Schema Match : Checks if the output matches a specific JSON Schema.
However, we recognize that there will always be the need for custom evaluation logic. With this release, we're introducing increased flexibility in building and utilizing your own custom evaluation metrics using:
Webhook Eval: Useful when you want to hit a home-grown API that’s responsible for determining whether an LLM’s output is “good” or “bad”; Code Eval: Write and run arbitrary Python code execution to be used to produce scores for LLM outputs. Typescript and custom pip packages are supported as well
Let us know if you want to try the new custom evaluation options.
Today, we have one more thing to show you!
Introducing Evaluation Reports
Before, Evaluations were limited to using just the "mean" as the sole aggregate performance metric to analyze how a prompt was performing for a given evaluation metric.
While this was extremely useful to evaluate your prompts, we’re excited to announce the launch of Evaluation Reports, which gives you more dimensions to analyze the performance of your prompts.

Aggregate Metrics to Analyze Overall Performance
Today, you can use Evaluation Reports to analyze the performance of draft and deployed Prompt and Workflow outputs for specific evaluation metrics.
This report shows four aggregate metrics that will aid in understanding the model's robustness and reliability, including:
Mean : The average performance across all test cases; Median : Represents the middle value when all test cases are sorted, which is helpful to understand the central tendency of the data, especially if there are outliers. P10 (Percentile 10) : Indicates the value below which 10% of the data falls. It helps assess the performance at the lower end of the spectrum, identifying cases where the model performs particularly poorly. P90 (Percentile 90) : Shows the value below which 90% of the data falls. This helps assess the performance at the higher end of the spectrum, highlighting cases where the model performs exceptionally well.
These can be very useful to analyze the overall performance, for example, the median performance might show the typical user experience, while P10 and P90 can indicate the range of outcomes users might expect, highlighting the model's consistency or variability. By examining the spread between metrics like P10 and P90, you can identify if there are many outlier responses (either very good or very bad), which might not be apparent if only looking at average (mean) performance.
But that’s not all.
Relative Performance, Improvements and Regressions
With v1 of Evaluations, you could compare the absolute “mean” performance between a baseline prompt with other prompts, but with Evaluation Reports you can compare the relative performance too, across four different aggregate metrics.
This is particularly useful in cases when you want to check if new prompts/workflows are performing better or worse than your deployed prompt/workflow. To help with that scenario, you can also capture the number of improvements or regressions compared to the baseline prompt. In the future we’re planning to add options for you to drill down into those improvements or regressions and further analyze them.
Wanna try the Evaluation Reports? Let us know here.
What's Next?
We’re already working on bringing more support for LLM evaluations, like:
Ability to drill down on the improvements/regressions and analyze them; Compound filters so that you can narrow in on test cases of interest; More plug-and-play evaluators for various scenarios; Graphical visualizations of your evaluations;
Want to Evaluate your AI Apps with Vellum?
Fill out this form , and we'll set up a custom demo for you.






