
TLDR: Unit testing for LLMs is here! Vellum Test Suites allows you to test the quality of Large Language Models (LLMs) before sending them to production. You can upload test cases via CSV or API, quickly identify the best prompts for your use case (via exact match, regex, semantic similarity and bespoke business logic through webhooks) and the specific test cases that fail evaluation. Gain confidence before sending prompts to production!
Evaluating the quality of large language models is difficult and one of the big reasons that prevent people from putting LLMs to production. For instance, do you ever wonder how you can take this amazing demo you created on OpenAI’s playground and reliably put it in production? Maybe you’re worried about the unpredictable responses the model might provide when faced with real user data? The practical solution here is unit testing, if the prompt/model can “pass” a large number of test cases, that should give you more comfort before putting it in production.
However, the two main challenges companies face here are:
It’s difficult to measure the quality of LLM output; and Building the infrastructure for robust LLM unit testing is time consuming
That’s where Vellum Test Suites come in. Once you have a prompt/model combination that seems to provide generally good results with a few test cases you can upload tens or hundreds of test cases to see where your prompt shines and where it falls short. The prompt can then be further tweaked to clear the test cases that failed. We’ve had customers conduct extensive testing using our Test Suites to confirm the prompts look good before they are sent to production.
Why is it difficult to test LLM quality in bulk?
There’s no framework to evaluate quality of Large Language models. LLMs are inherently probabilistic in nature — the same input can have different outputs depending on the probabilities assigned by the model when using a temperature of > 0, and seemingly small changes can result in vastly different outputs. We wrote a blog about this topic a few weeks ago, but in summary, the evaluation approach depends on type of use case
Classification: accuracy, recall, precision, F score and confusion matrices for a deeper evaluation Data extraction: Validate that the output is syntactically valid and the expected keys are present in the generated response SQL/Code generation: Validate that the output is syntactically valid and running it will return the expected values Creative output: Semantic similarity between model generated response and target response using cross-encoders
Each of these evaluation methods today is done either by eyeballing the results, in Jupyter notebooks or by writing custom code.
Even after setting up the tooling needed for an evaluation metric, it’s still a non-trivial task to test hundreds of test cases in bulk and measure which cases fail. Results have to be stored in an Excel spreadsheet, you might come up against OpenAI rate limits and it’s not clear which cases fail the evaluation criteria.
Introducing Vellum Test Suites
With Vellum Test Suites, you can choose your evaluation metric, specify values for input variables and target outputs, and run your prompts through all those test cases within minutes. All this is done in our UI or API, no custom code needed. From there, you can quickly identify which test cases are failing. The evaluation metrics we support today are:
Exact match: Best used for classification tasks Regex match: Best used for data extraction Webhook support: Best used when you have some bespoke business logic that’s capable of determining whether an LLM’s output is “good” or “bad” Semantic similarity: Best used for creative output
Here’s a guide to how Test Suites work:
Step 1: Create a test suite, this is a bank of test cases that will be sent to the prompt for evaluation. Remember to use the same variables as you have in your prompt!

Step 2: Add test cases with target responses either in our UI, upload via CSV, or via an API endpoint . These test cases should be representative of the types of inputs your LLM application is expected to see in production.
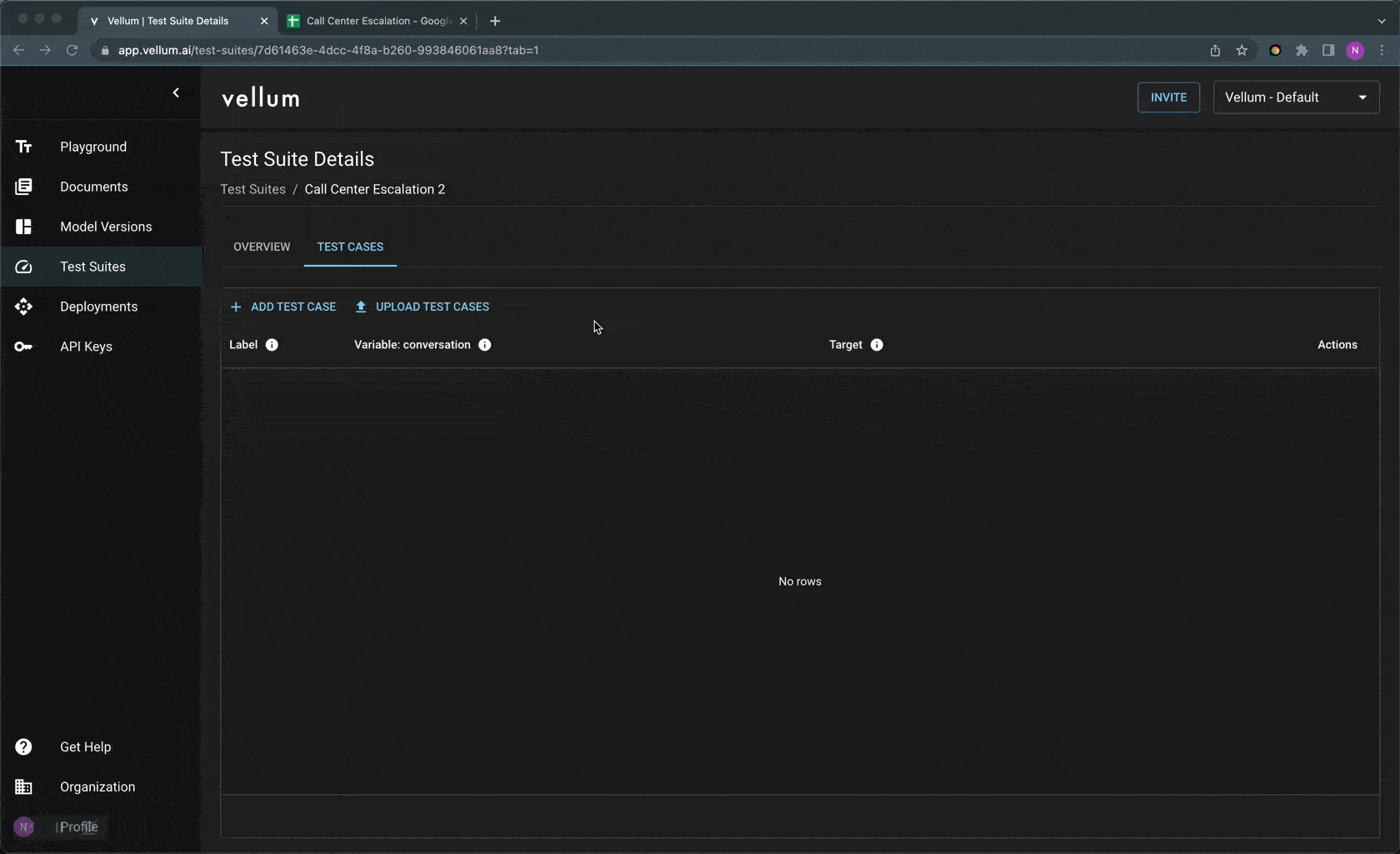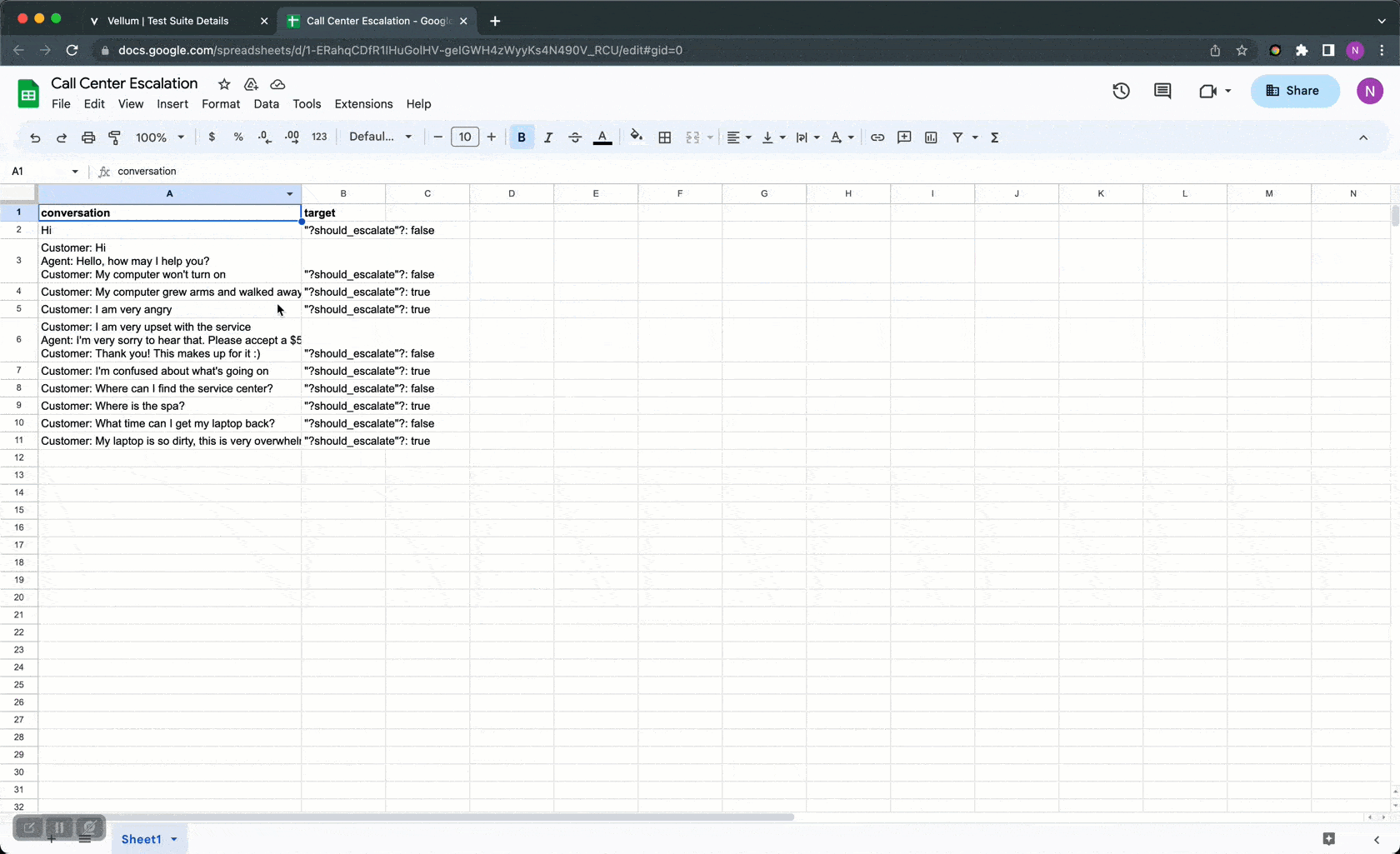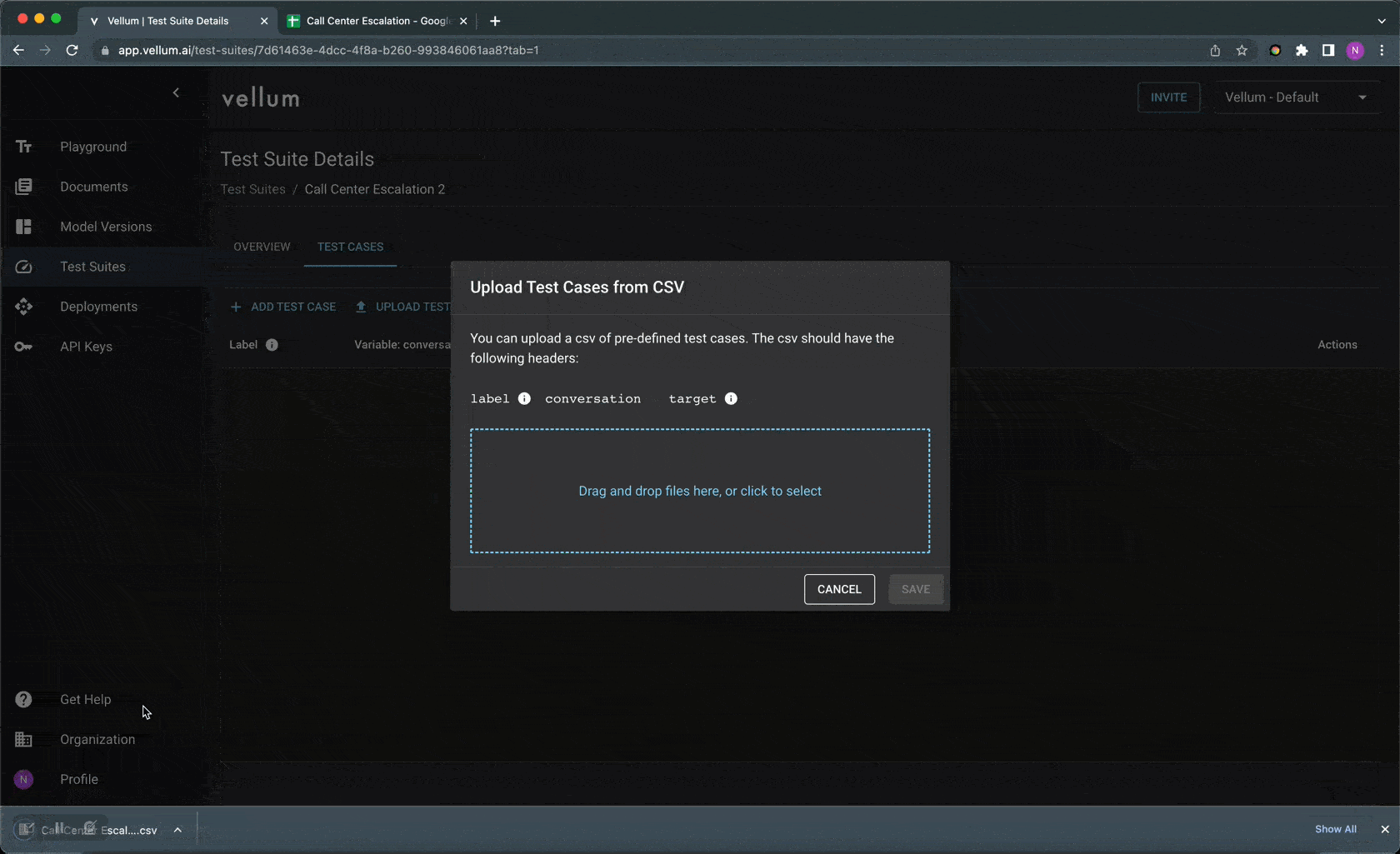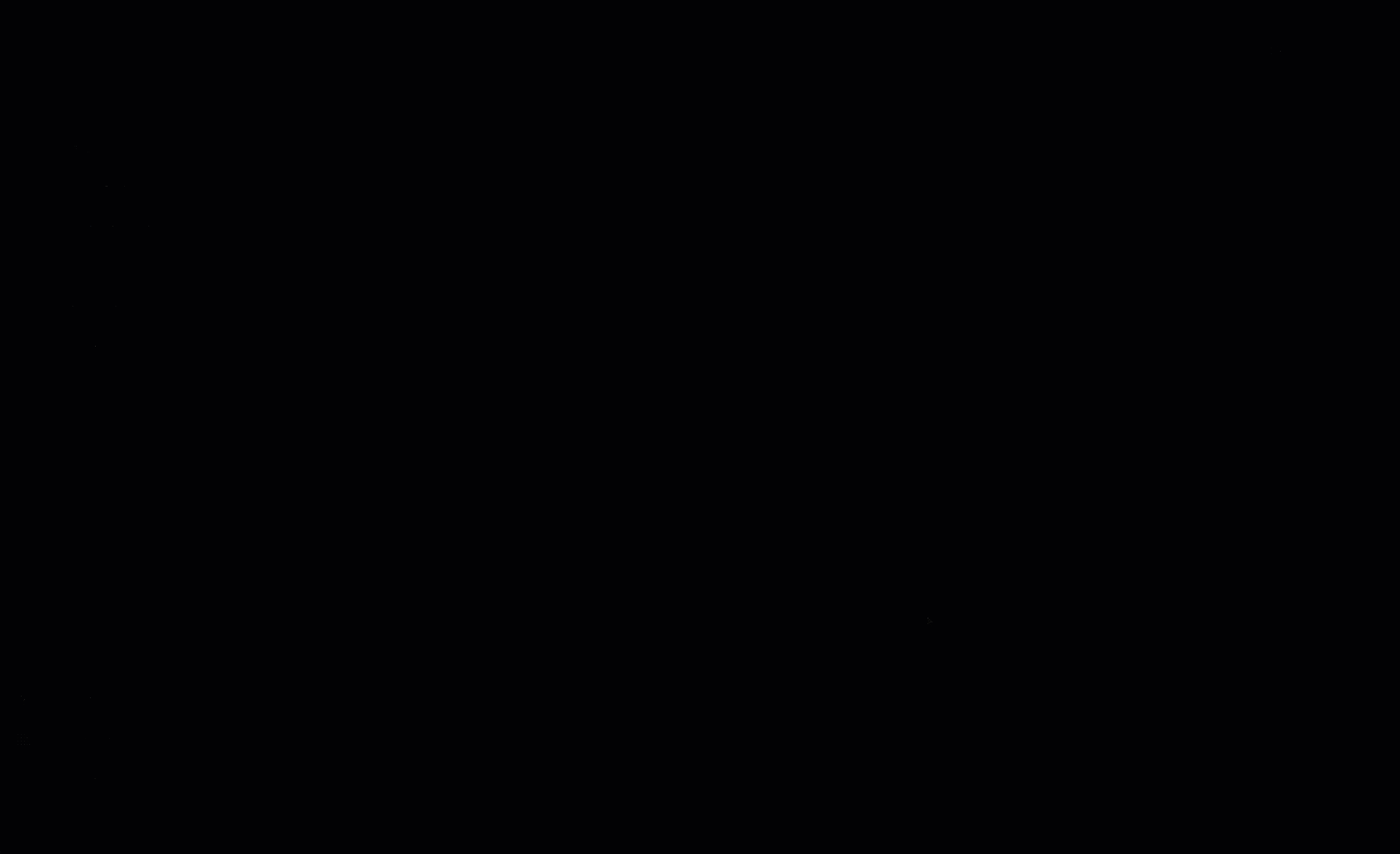
Step 3: Go to Vellum Playground, run the test suite and quickly identify which test cases are failing

Now that you know which test cases fail for your prompt(s), you can continue tweaking the prompt until you get a better result! Once ready, deploy your prompt through Vellum to get all the benefits of our Manage product.
What’s next?
We’re excited to continue building tools that help companies evaluate the quality of their models and prompts. We’ve seen promising early signs of using one prompt to evaluate the output quality of other prompts and hope to productize some of this soon!
Our asks
If you’re interested in using Vellum for any of your LLM use-cases, please sign up here Subscribe to our blog and stay tuned for updates from us. We will soon share more updates to our testing and evaluation suite soon Please share your experience in creating production use cases of LLMs in the comments below. We would love to learn more!






