Building AI agents has never been easier
Build, debug, and deploy AI agents with Vellum’s agent builder or low-code editor. Automate high-impact use cases, build your agent team, or power customer-facing features.
All from one place.









From idea to working agent in minutes
The Vellum agent builder lets you create AI agents, connect them to the tools they need, and debug them with natural language.

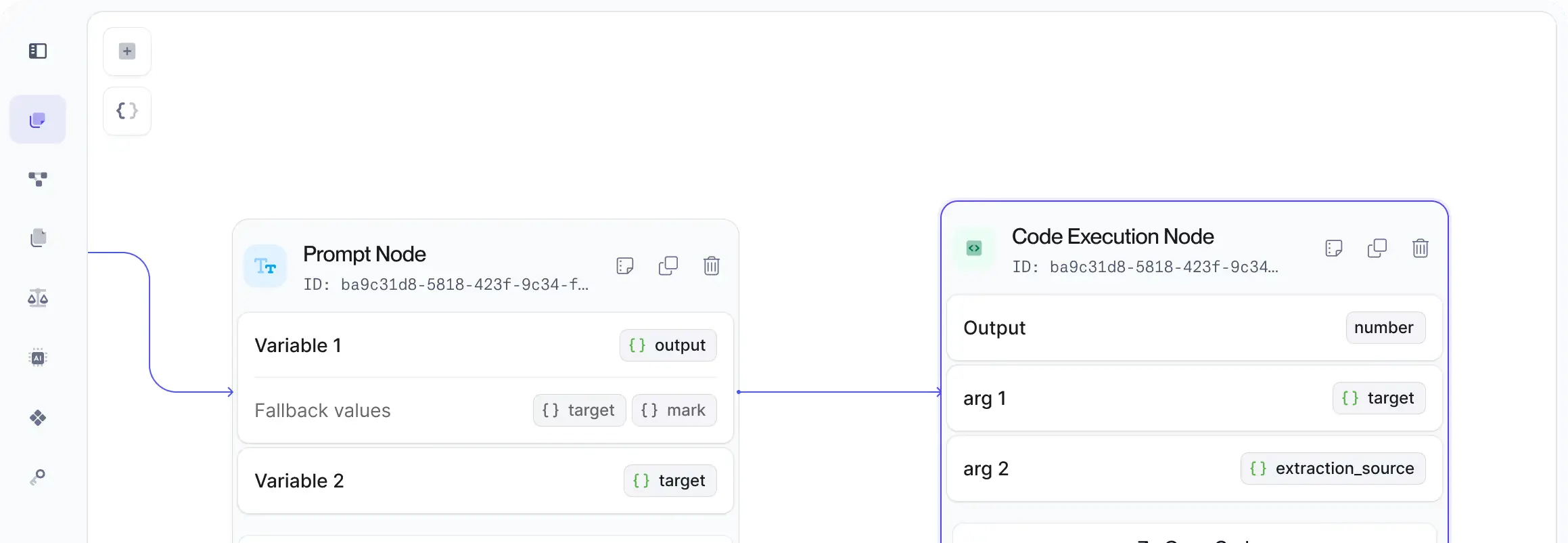
All the building
blocks you need
Vellum offers essential low-level abstractions for even the most sophisticated AI backends. Build provider-agnostic graphs with nodes that call models, run Python/Typescript code, perform map/reduce on LLM output, and more.
Rapidly define and debug any AI system
Develop any AI architecture from simple prompt pipelines to complex agentic workflows using Vellum's production-grade graph builder.
.webp)
How it works
Build composable systems and define team-wide standards
Workflows in Vellum are composable — once defined, they can be re-used as nodes in other parent workflows. This allows for defining shared tools and enforcing team-wide standards. Start from Vellum’s library of pre-built tools and create your own as you go.


Easily deploy and iterate with confidence
Use Vellum Evaluations to perform assertions on intermediate results as well as final outputs. Once happy, deploy with one click to invoke your Workflow via API. Debug problematic requests with
advanced trace views.





Your submission has been received!
Vellum made it so much easier to quickly validate AI ideas and focus on the ones that matter most. The product team can build POCs with little to no assistance within a week!


We accelerated our 9-month timeline by 2x and achieved bulletproof accuracy with our virtual assistant. Vellum has been instrumental in making our data actionable and reliable.

Experiment, Evaluate, Deploy, Repeat.
AI development doesn’t end once you've defined your system. Learn how Vellum helps you manage the entire AI development lifecycle.



