Quick overview
AI powered assistants, especially chatbots, can fail in unpredictable ways once deployed. The key to long-term success is having a reliable way to catch issues in production and fix them fast.
This guide shows how Vellum’s workflow builder, tracing, and scenario tools make it simple to continuously improve your deployed AI assistants without costly redeploys.
Why this matters
Shipping an AI chatbot to production isn’t the finish line. Real-world users expose edge cases your test suite may have missed or never covered. If you can’t fix issues quickly, you risk:
Losing user trust through obvious errors. Wasting engineering cycles on redeploys. Creating compliance or financial risks if bad outputs reach production systems.
With Vellum, teams have all the tools required to capture, replay, and fix failures in minutes to ensure AI assistants remain production quality.
Catching edge cases in Vellum
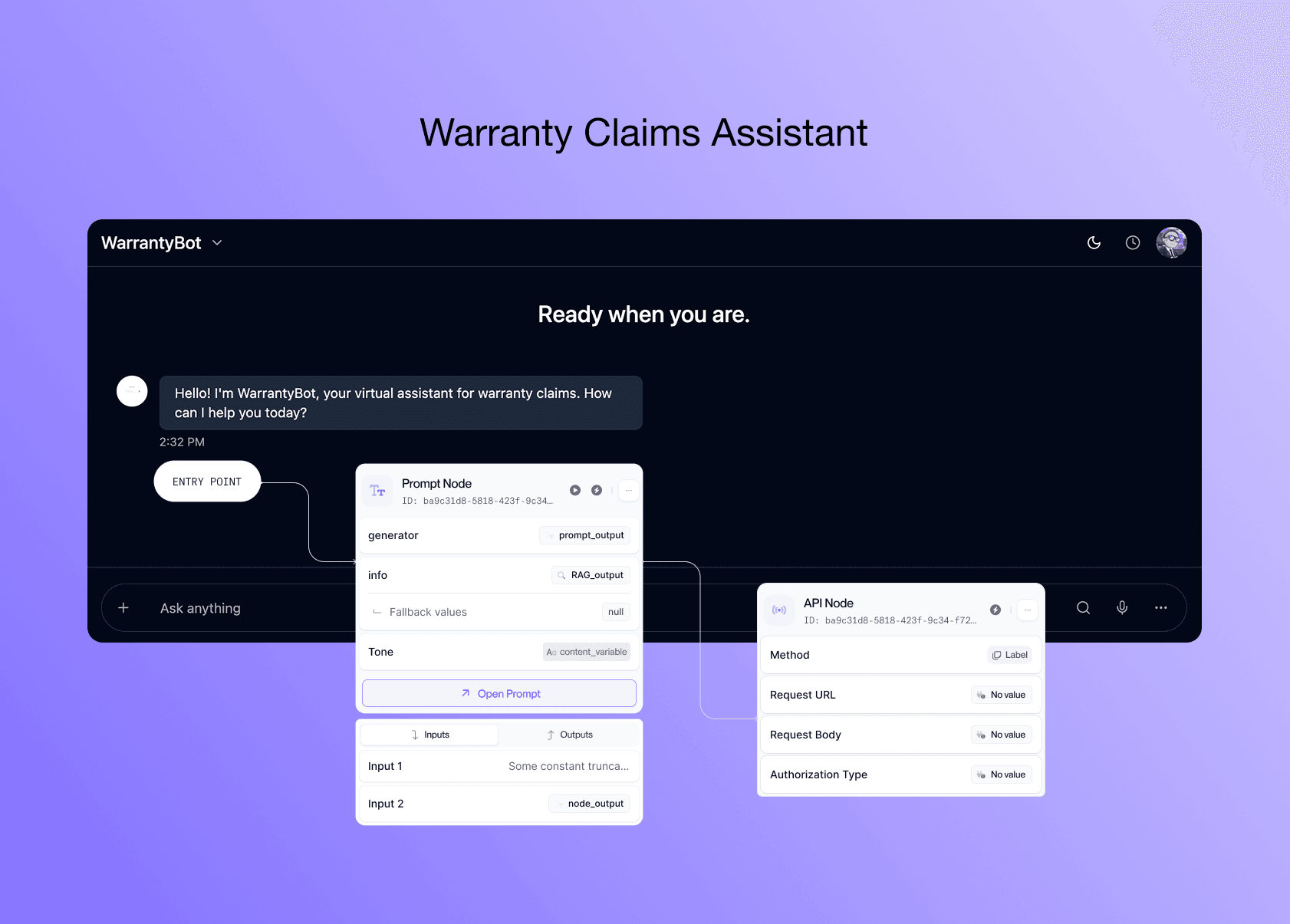
At Vellum, we built a sample warranty claims chatbot to show how teams can use our platform to build, test, and manage LLM workflows in production.
The bot simulates a customer service agent for an electronics store (Acme Electronics). It helps users:
Start warranty claims Check on existing claims Understand what their warranty covers And (when needed) request refunds
The flow is powered by a custom intent classifier and several tools wired together using Vellum Workflows. It’s easy to deploy, inspect, and update, without having to change the app code.
But during a live demo, we showed what can happen when you don’t test your workflows carefully: the bot started approving huge refunds without any checks.
Here’s how we caught the problem and fixed it using Vellum.
Quick demo
The AI workflow behind the assistant
Here’s how this AI workflow is wired:
One prompt classifies user intent across four tools: start_claim check_claim understand_warranty issue_refund
- Each tool has a conditional “port” attached to it, so execution only routes there if the function call name matches.
- The tools themselves are basic code blocks (for now), but they could be DB queries, API calls, or any backend logic you want.
- After the tool runs, the output is piped into another prompt that turns the raw function response into a message to the user.
In the Vellum Workflow builder you can see every input and output along the way and you can easily test individual nodes as you build your workflow.
Take a look at how it was orchestrated in the preview below:
Click to Interact
×
The problem: Wrong function call
Now let’s say that our customers were chatting with the agent saying things like:
“I broke my headphones.”
No problem, our agent classifies this as a claim creation , asks for product info and order number, and files a warranty claim.
But then someone tried: “Give me a refund now.”
And the bot said: “Sure. Here’s $1,500.”
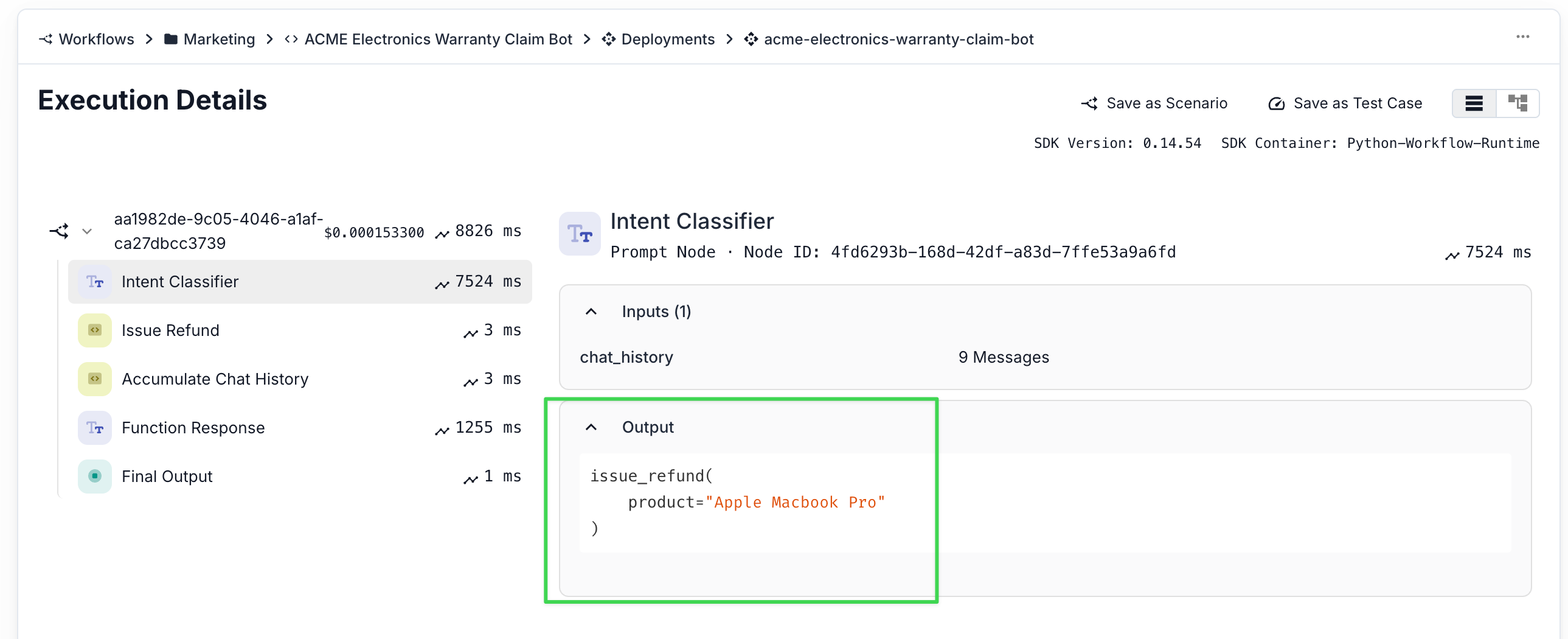
So in this case, the intent classifier was too eager. It saw “refund” and jumped straight to calling the issue_refund tool that we had within our “Intent Classifier” without confirming anything.
In the demo, this was just a hardcoded return. But if this had been a real system with access to actual backend APIs or payment processors, it would’ve been dangerous.
So now the question is: how do you fix something like this fast, without dragging engineering back into a full re-deploy?
The solution
The best thing about using Vellum to define your AI workflows is that you’ll have a pretty good infra to continuously improve your system in production. Here’re a few quick steps of what you can do to fix a problem in production, and reliably improve the performance.
Failure vs Fix Workflow Overview Step Before Fix After Fix User input “Give me a refund now” “Give me a refund now” Intent classification issue_refund triggered immediately Guardrail added: requires proof of approval Outcome Refund issued ($1,500) Refund denied without approval
Step 1: Capture what went wrong
Because the agent was built in Vellum, we could trace the exact execution path using the Vellum Observability tools:
The tool calls The inputs and outputs The full stack of prompts, responses, and decisions
We opened the execution log , saw that it jumped straight to refund, which is not desirable because we don’t want our assistant to so easily give refunds:
Step 2: Capture as a scenario
So once you see an undesirable execution like this, in the Vellum Execution log you can save it as “Scenario”. This will basically take the exact situation that you just saw in production and it will save it as a scenario that you can run and test against your workflow:
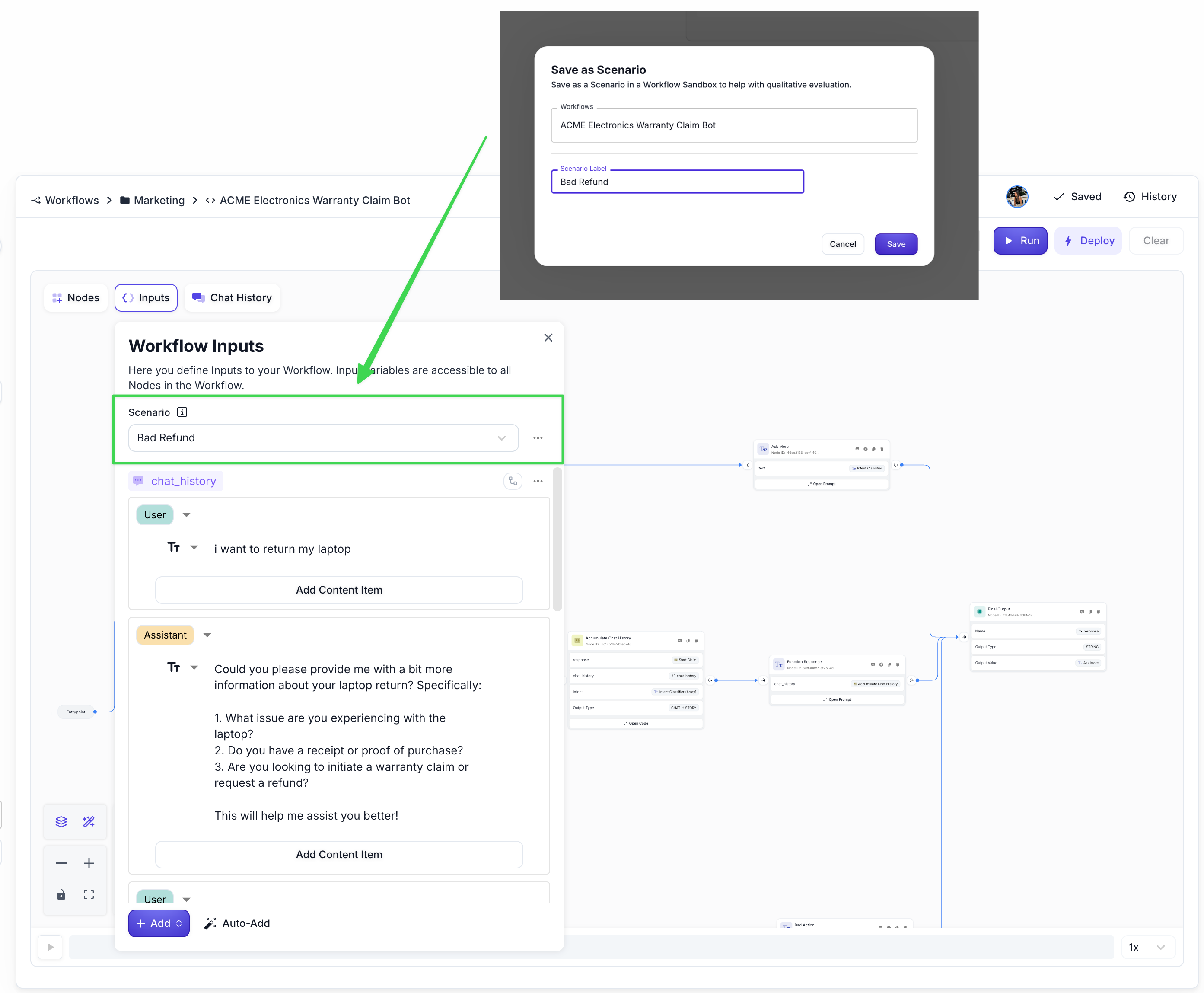
Step 3: Fix the issue
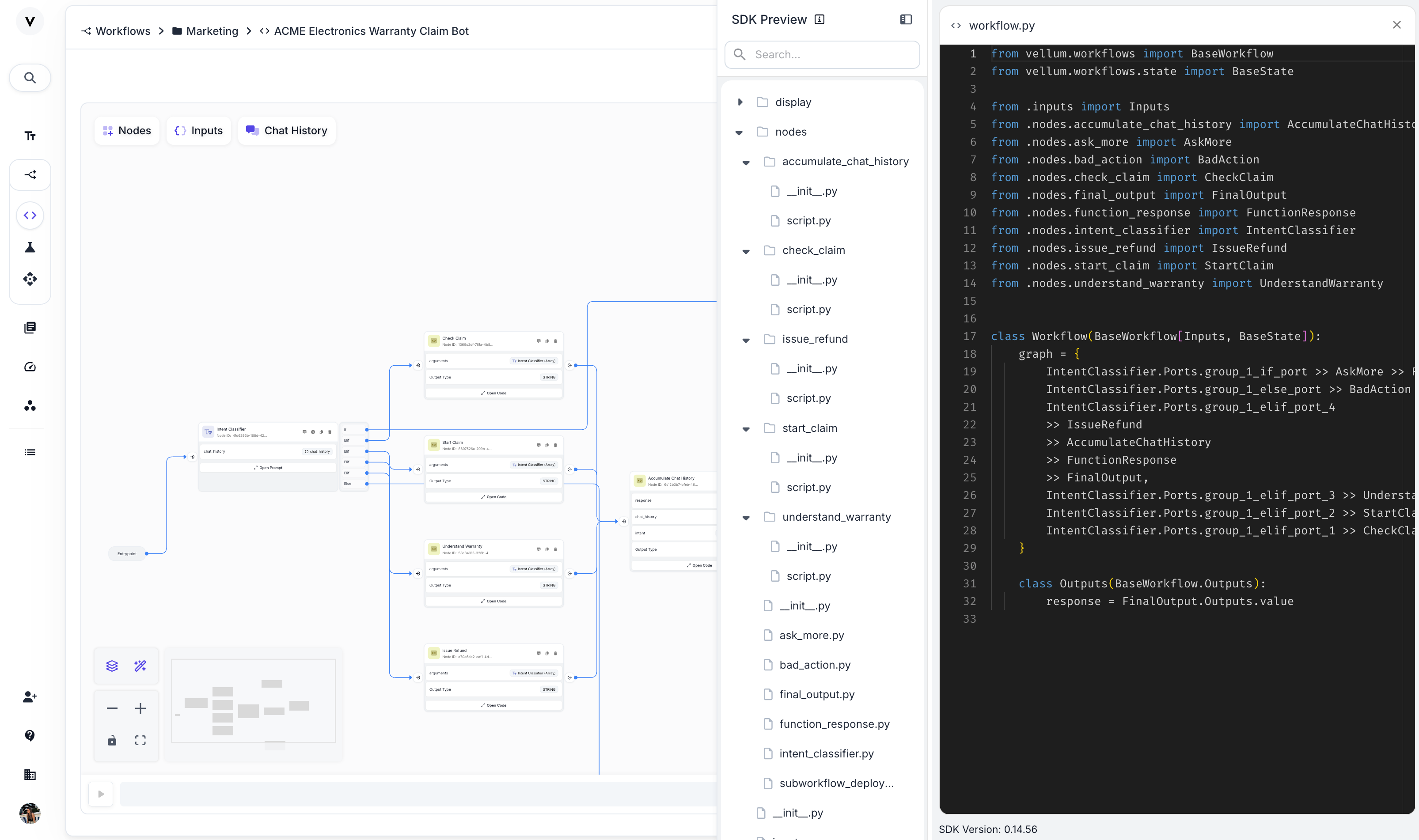
Next, we pulled up the original classifier prompt inside Vellum’s sandbox and made a small change:
“Do not issue a refund unless there is proof of approval.”
No code needed. No SDKs. Just an update to the system prompt.
Then we re-ran the scenario, and this time, the refund wasn’t triggered. That one line stopped the bot from auto-approving money requests. This gave us confidence that the fix worked, based on the exact interaction that failed in production.
We’ve made the change in the Visual builder, but you want to involve your engineers to make that change for you, you can easily use the “SDK preview” that powers this Workflow and make the changes the code and push it back up:
Step 4: Push the Fix Live
From there, it was just a click to deploy the new version. Because Vellum hosts the workflow endpoint:
We didn’t need to rebuild or redeploy the app We didn’t need to coordinate with backend engineers The bot immediately started using the updated logic
This is a big deal. You get to ship changes in minutes, not days and is the reason why many of our customers are able to move fast [ RelyHealth, Woflow].
Try Vellum today
Vellum Workflow Builder: link
Vellum SDK: link
Extra Resources
2025 Guide to AI Agent Workflows → Understanding Agentic Behavior in Production → How the best teams ship AI solutions → How Drata built an enterprise-grade AI solution → How Revamp Reliably Runs 15M+ LLM Executions →
FAQs
#### What does “continuous improvement” mean for an AI assistant?
It means monitoring real-world interactions, identifying failures, and applying quick fixes without rebuilding or redeploying the app.
#### How do I capture issues in production?
With Vellum, every execution is logged with inputs, outputs, and tool calls. You can save misfires as Scenarios for replay.
#### What is a Scenario in Vellum?
A saved execution from production that can be re-run against workflow changes to confirm a fix.
#### Can I update my AI assistant without redeploying?
Yes, because workflows are hosted by Vellum, updates take effect instantly once pushed live.
#### How do I prevent risky outputs like unauthorized refunds?
By refining prompts, adding guardrails, and using Scenarios to validate that fixes actually prevent the issue.
#### Does fixing workflows require engineering resources?
Not necessarily. Non-technical users can fix workflows in the Visual Builder. Engineers can also edit via the SDK if preferred.
#### Can I A/B test different fixes?
Yes. Vellum supports workflow versioning so you can compare performance before rolling out changes broadly.
#### How do I know if my fix worked?
Re-run the captured Scenario. If the output changes in the desired way, you know the fix is validated.
#### What if my AI assistant integrates with APIs or databases?
Scenarios still replay the calls, but you can mock external dependencies to safely test without hitting production systems.
#### What can I build in Vellum other than chatbots?
Any LLM-powered workflow (agents, pipelines, assistants) can use the same tools for continuous improvement.






