
You switch to GPT-5 thinking it’s going to be a significant upgrade. Instead, you get slower responses, prompts that don’t work, and answers that feel verbose.
It’s not just you, people are noticing the same thing:
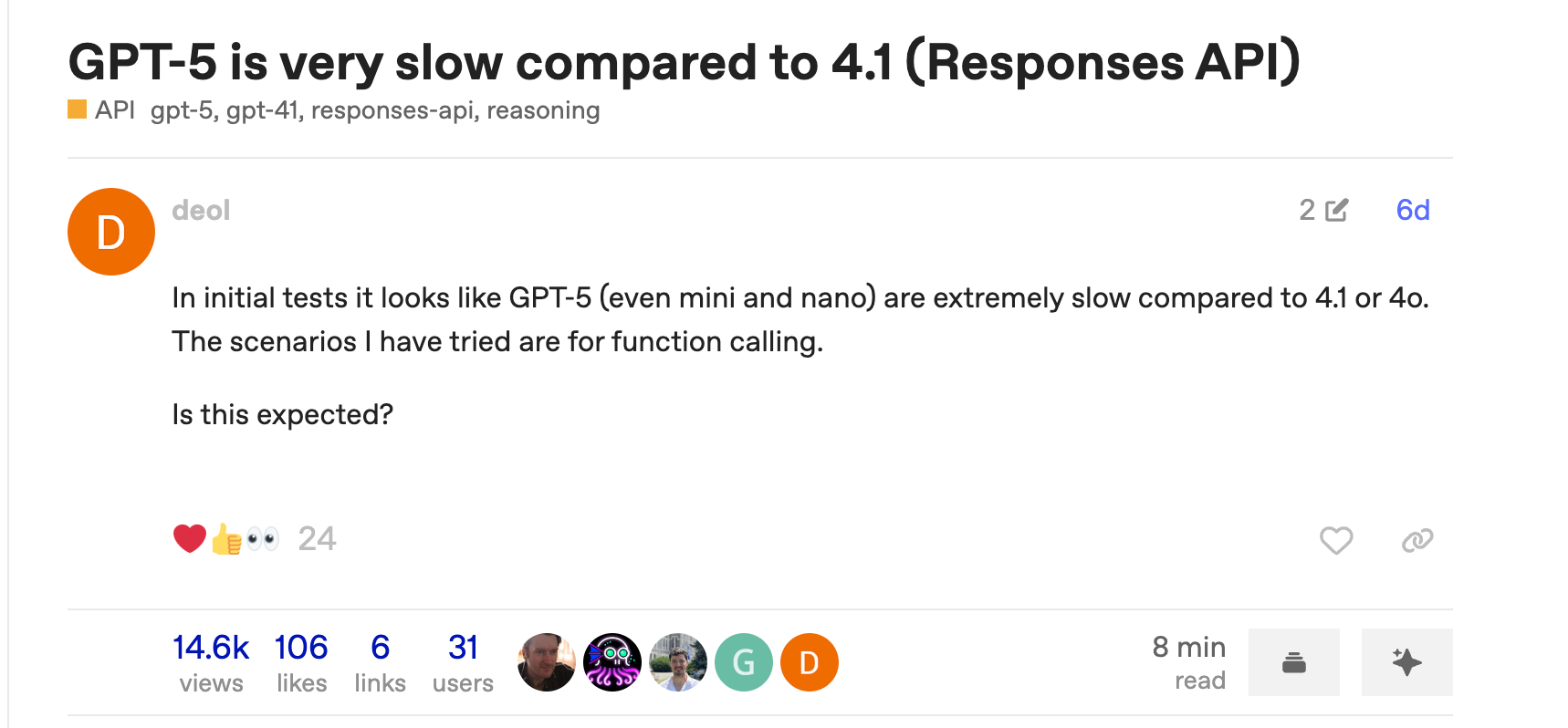
The reality is, however, that GPT-5 can be a great model for your use-case. But only if you know how to manage it’s new parameters.
This model is very adaptable, and comes with new settings like: reasoning options, verbosity controls, and specific prompting tips.
We wrote this guide, to help you learn:
Prompting techniques that actually get good results with GPT-5 How to speed things up without losing accuracy When it makes sense to switch from older models, and when to stick with them How to use GPT-5 to improve your own prompts
Let’s look at the changes in this model before we get to the prompting tips. After reading the article, head into Vellum to test this model with your new prompts.
GPT-5’s new controls
GPT-5 is built for any use-case, and it comes with exciting new layer of developer controls.
Here’s a quick overview:
Reasoning effort: This parameter controls the reasoning effort that a model takes before answering a question. Verbosity: With this parameter, you can control the amount of detail in the responses. Custom tools: Custom tools work in much the same way as JSON schema-driven function tools. But rather than providing the model explicit instructions on what input your tool requires, the model can pass an arbitrary string back to your tool as input (e.g. SQL queries or shell scripts) Tool preambles: These are brief, user-visible explanations that GPT-5 generates before invoking any tool or function, outlining its intent or plan (e.g., “why I'm calling this tool”). Useful for debugging and understanding how the model works.
Parameters / Tool What It Does When to Use It Verbosity Controls how many tokens to output per generation. As a result you get lower latency. low → Best for situations where you want concise answers or simple code generation, such as SQL queries. Or when you need latency to go down. high → When you want your model to perform thorough explanations of documents or perform extensive code refactoring. Reasoning effort This parameter controls how many reasoning tokens the model generates before producing a response. For tasks that require less reasoning you would like to use minimal reasoning, vs high for more reasoning-intense tasks. Custom tools The model can pass an arbitrary string back to your tool as input. This is useful to avoid unnecessarily wrapping a response in JSON, or to apply a custom grammar to the response by using. Tool preambles User-visible explanations that GPT-5 generates before invoking any tool or function. When you want to understand how the model works, and for debugging tool use.
For a complete breakdown of GPT-5’s new parameters and how to make them work for you, check out this OpenAI resource .
How to migrate from older models
When migrating to GPT-5 from an older OpenAI model, start by experimenting with reasoning levels and prompting strategies. Based on best-practices here's how you should think about migrating from older models:
o3 : gpt-5 with medium or high reasoning is a great replacement. Start with medium reasoning with prompt tuning, then increasing to high if you aren't getting the results you want. gpt-4.1 : gpt-5 with minimal or low reasoning is a strong alternative. Start with minimal and tune your prompts; increase to low if you need better performance. o4-mini or gpt-4.1-mini : gpt-5-mini with prompt tuning is a great replacement. gpt-4.1-nano : gpt-5-nano with prompt tuning is a great replacement.
Previous Model Recommended GPT-5 Model Starting Reasoning Effort o3 gpt-5 Medium → High gpt-4.1 gpt-5 Minimal → Low o4-mini gpt-5-mini Default gpt-4.1-mini gpt-5-mini Default gpt-4.1-nano gpt-5-nano Default
18 Prompting tips for GPT-5
GPT-5 is built to follow instructions with surgical precisions, meaning poorly structured prompts will almost always result in undesired outputs. You’ll need to be as explicit and specific as possible, and very conscientious of how you structure your prompts.
Below we cover the most useful practices we found to help you yield better results with GPT-5 for your use-case
1. Get the model to run faster, by lowering it’s reasoning effort
The new model comes with a very powerful parameter: reasoning_effort. Using this parameter you control how much reasoning tokens the model uses to get to an answer.
If you want your model to minimize the latency, you can set the reasoning to minimal or low . This will reduce the exploration depth and will improve efficiency and latency.
2. Define clear criteria in your prompt
Set clear rules in your prompt for how the model should explore the problem. This keeps it from wandering through too many ideas.
Make sure you follow the following:
Sets a clear goal: The model knows exactly what the outcome should be Provides a step-by-step method: It lays out a logical order: start broad, branch into specifics, run parallel queries, deduplicate, and cache. Defines stopping rules: The “early stop criteria” tell the model when to move from searching to acting, avoiding endless context gathering. Handles uncertainty: The “escalate once” step prevents the model from looping endlessly if results conflict. Controls depth: It limits how far the model should trace details, focusing only on relevant symbols/contracts. Encourages action over overthinking: The loop structure reinforces moving forward, only searching again if something fails or new unknowns pop up.
Here’s an example of a good prompt that follows the above structure:
- For fast, high-quality answers, use minimal reasoning with a short explanation If speed matters, you can run GPT-5 with minimal reasoning while still nudging it to “think.” OpenAI suggests asking the model to start its answer with a short summary of its thought process, like a quick bullet point list. This can improve performance on tasks that need more intelligence without slowing things down too much.
Example:
- Remove contradictory instructions and clearly define exceptions Since GPT-5 is really good at following instructions, prompts containing contradictory or vague instructions will be more damaging to GPT-5 than to previous models.
The model can easily get confused when two instructions pull in opposite directions, for example telling it “always wait for approval” but also “go ahead and do it right away.” Instead:
Set a clear instruction hierarchy so the model knows which rule overrides in each scenario Explicitly state exceptions (e.g., “skip lookup only in emergencies”) Review prompts for wording that could be interpreted in multiple ways
Here’s a bad prompt:
Here’s a prompt that will work better:
- Prompting for higher reasoning outputs On the other hand, if you want to give the model higher autonomy, can can increase the reasoning_effort to high .
Here’s an example prompt that can help aide with this:
- Provide an escape hatch As you provide more autonomy to GPT-5, you should instruct the model how to act in a case of uncertainty.
You can provide a context-gathering tag, and give the model explicit permission to proceed even if it’s uncertain. This prevents stalls when GPT-5 can’t be fully confident and ensures it acts on the best available information instead of halting.
Example:
- Use tool preambles to set context for tool calls In the GPT-5’s output you now have access to tool preambles . These are short explanations from the model on how it’s executing it’s tools.
The best part of this is that you can steer the frequency, style, and content of tool preambles in your prompt using a brief upfront plan. By controlling the tool preamble , you ensure that every tool call starts with a clear, predictable setup.
Example:
- Use Responses API over Chat Completions OpenAI recommends using the Responses API over the Chat Completions API because it can access the model’s hidden reasoning tokens, which aren’t exposed in the output of Chat Completions.
The Responses API can send the previous turn's CoT to the model. This leads to fewer generated reasoning tokens, higher cache hit rates, and less latency. In fact, Open AI observed an increase of the Tau-Bench Retail score from 73.9% to 78.2% just by switching to the Responses API and including previous_response_id to pass back previous reasoning items into subsequent requests. More info here .
#### Chat Completions API example
Responses API example 9. For higher safety, predictability and prompt caching use allowed tools The parameter allowed_tools lets you give the model a smaller “allowed right now” list from your full tools list. You can also set mode to "auto" (can use any allowed tool or none) or "required" (must use one allowed tool).
Here, the model knows about all three tools, but in this request it can only use get_weather or deepwiki:
- Planning Before Execution GPT-5 will work great if you ask it to plan it’s execution before actually generating the answer. Here’s an example from some community tests:
- Include validation instructions To prevent errors, you can include validation instructions in your prompt. Example from the community:
- Make instructions ultra-specific to get accurate multi-task results from one prompt While we suggest keeping instructions in separate prompts whenever possible, Pietro’s GPT-5 prompt guide shows that the model can also handle parallel tasks well. But only if you clearly define each one in the prompt.
Quick tips from his guide:
Instruct the model to first create a detailed plan outlining sub-tasks Check the results after each major step against your requirements Confirm that all objectives have been met before concluding.
Example: When building a multi-page financial report, tell GPT-5: “Plan each section and data source before writing, verify figures after each section is drafted, and confirm that the final report matches all stated requirements before sending.”
13. Keep few-shot examples light
In earlier, pre-reasoning models, this prompting method was the go-to for getting better results. With today’s reasoning models, clear instructions and well-defined constraints often work better than adding examples. In fact, research shows that few-shot prompts can reduce performance when the task requires heavy reasoning. That said, they can still be useful in certain cases..
Here’s how to think about this:
Use few-shot prompts for tasks needing strict formats or specialized knowledge. For more complex, reasoning tasks, start with prompts without examples and strong instructions, and iterate from there
14. Assign GPT-5 a persona & role
A role like “compliance officer” or “financial analyst” shapes vocabulary and reasoning.
Example: When reviewing a policy draft for compliance, start with “You are a compliance officer. Review the text for any GDPR violations” to ensure the response uses the right expertise and focus.
15. Break tasks across multiple agent turns
Split complex prompts into discrete, testable units. You’ll get best performance when distinct, separable tasks are broken up across multiple agent turns, with one turn for each task.
16. Controlling output length with Verbosity
Verbosity adjusts how much detail GPT-5 includes in the answer. Use low for concise answers, high for richer explanations.
Example: Set verbosity: low for a brief board summary; raise to high for a technical onboarding guide with step-by-step detail.
17. Ensure markdown output with specific instructions
By default, GPT-5 in the API does not format its final answers in Markdown. However this is a prompt that works really well to reinforce a markdown output from a GPT-5 model:
- Use GPT-5 to write prompts for itself Leverage GPT-5 as a meta-prompter to diagnose and fix issues in your existing prompts. It’s actually very successful in doing this.
Here’s an example prompt template that’s recommended by OpenAI:
Test driven prompting with Vellum Implementing these tips alone will not ensure accurate outputs for use of GPT-5 used in production. Prompts that break past edge cases are built through iteration.
Vellum makes this process faster and more reliable by giving you a dedicated workspace for prompt management to design, test, and refine your GPT-5 prompts across varied scenarios.
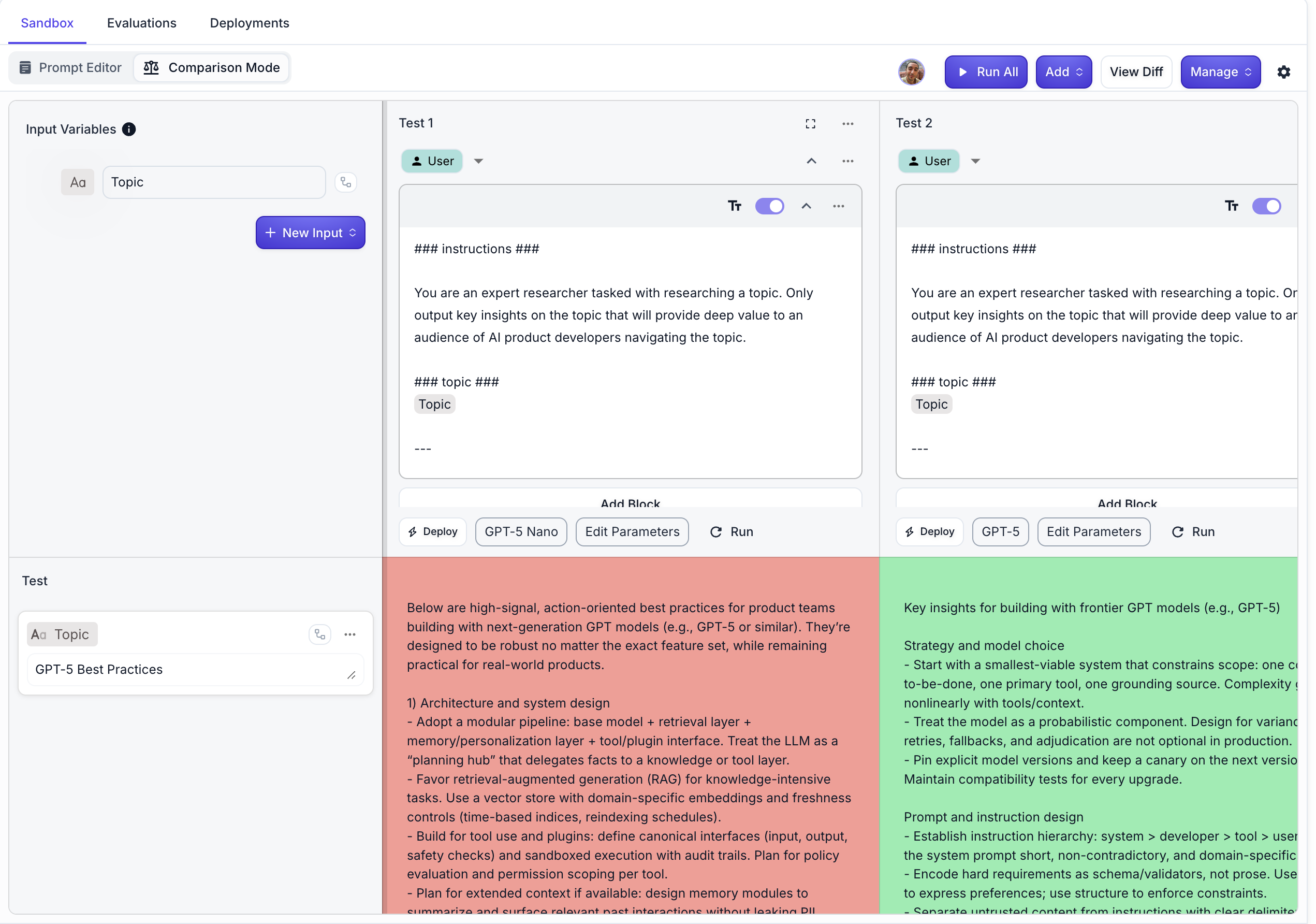
Purpose built for prompt evaluation , you can log performance, compare outputs, and track improvements over time, ensuring your prompts keep delivering consistent production grade outputs.
Efficiency maxing prompts is just the start, with Vellum providing an all encompassing platform for developing production grade AI for any use case.
Try Vellum for free today and see how quickly you can design, test, and optimize GPT-5 prompts that outperform anything you’ve built before!
Extra resources
Beginner’s Guide to Building AI Agents → Best Enterprise AI Agent Builder Platforms → Best Low code AI Workflow Automation Tools → Guide: No Code AI Workflow Automation Tools → Best AI Workflow Platforms →
{{general-cta}}






