How Rate Limits are Enforced
Let’s begin by discussing how rate limits are enforced, and what tiers exist for different providers.
Rate limit measurements
OpenAI and Azure OpenAI enforce rate limits in slightly different ways, but they both use some combination of the following factors to measure request volume:
Requests per minute (RPM) Requests per day (RPD) Tokens per minute ( TPM) Tokens per day (TPD)
If any of the above thresholds are reached, your limit is hit and your requests may get rate limited.
For example, imagine that your requests per minute is 20 and your tokens per minute is 1000. Now, consider the following scenarios:
You send 20 requests, each requesting 10 tokens. In this case, you would hit your RPM limit first and your next request would be rate limited. You send 1 request, requesting 1000 tokens. In this case, you would hit your TPM limit first and any subsequent requests would be rate limited.
Notably, rate limits can be quantized , where they can be enforced over shorter periods of time via proportional metrics. For example, an RPM of 600 may be enforced in per-second iterations, where no more than 10 requests per second are allowed. This means that short activity bursts may get you rate limited, even if you’re technically operating under the RPM limit!
What’s New / Updated for 2026
OpenAI’s latest rate limit increases (for GPT-5 and GPT-5-mini)
As of early 2026, OpenAI raised TPM for GPT-5 Tier 1 from ~30,000 to 500,000 TPM . OpenAI Community+1
GPT-5-mini also saw similar big increases at its higher tiers. OpenAI Community+1
Azure OpenAI quotas & defaults
Azure OpenAI defines TPM and RPM quotas per region , per subscription , per model or deployment . Microsoft Learn+1 Example: GPT-4.1 (default level) has a TPM quota of 1,000,000 TPM in many regions for standard/default subscriptions. Microsoft Learn+1 When you allocate TPM to a deployment, an RPM limit is set proportionally (i.e. increasing TPM raises RPM). Microsoft Learn+1
How to Avoid Rate Limit Errors (Updated Advice for 2026)
Set max_tokens closely to what you need, not too high. Because TPM counts the max of your input tokens and the max_tokens you set. Microsoft Learn+1 Use retries with exponential backoff when you get 429 errors. Wait, then try again, increasing wait time up to a limit. Spread out requests rather than sending many in a quick burst, even if under average minute limits. Monitor your usage : see how much TPM & RPM you’re using, in the region, for that model. If you’re close to your limit, you might need to request more quota. Microsoft Learn+1
Add retries with exponential backoff
A common way to avoid rate limit errors is to add automatic retries with random exponential backoff. This method involves waiting for a short, random period (aka a “backoff”) after encountering a rate limit error before retrying the request. If the request fails again, the wait time is increased exponentially, and the process is repeated until the request either succeeds or a maximum number of retries is reached.
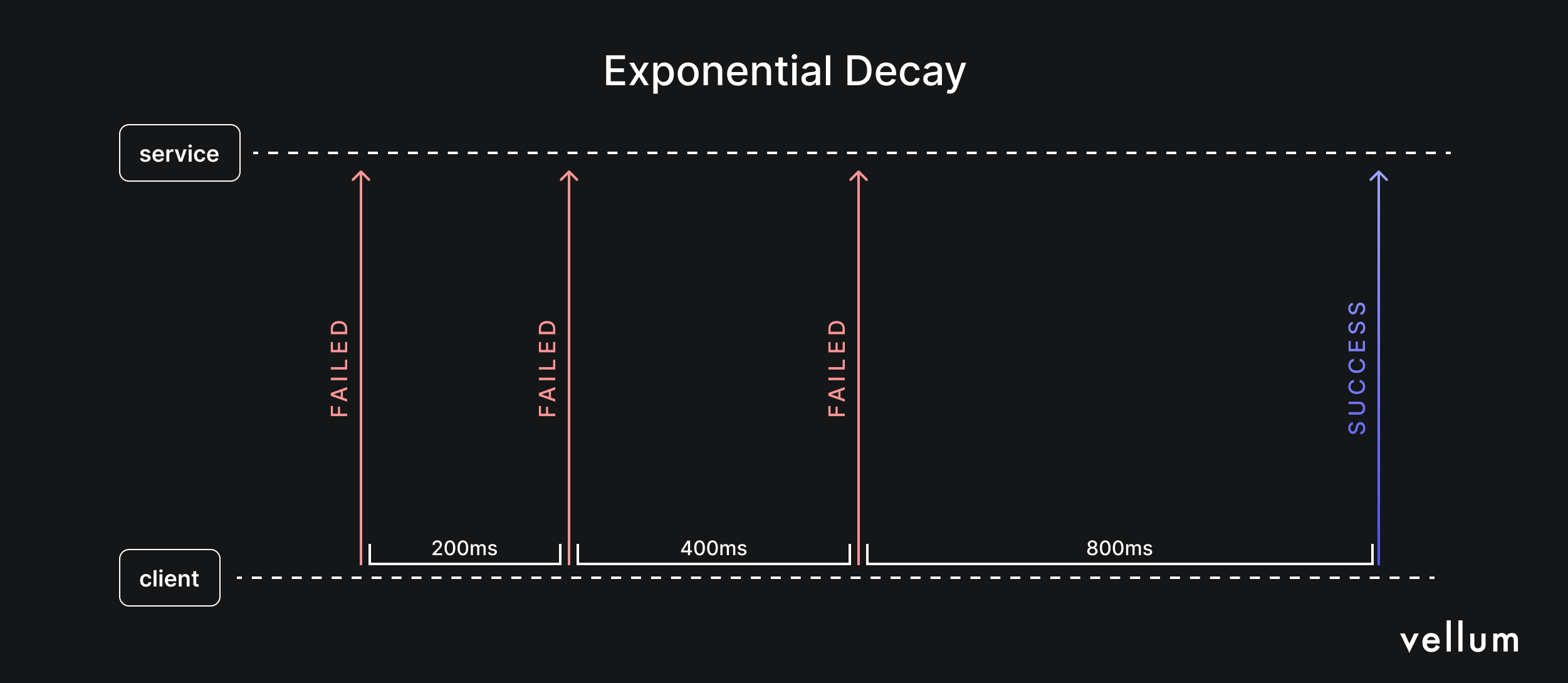
Here’s an example of how to implement retries with exponential backoff using the popular backoff Python module (alternatively, you can use Tenacity or Backoff-utils ):
This strategy offers several advantages :
Automatic recovery : Automatic retries help recover from rate limit errors without crashes or data loss. Users may have to wait longer, but intermediate errors are hidden. Efficient retries : Exponential backoff allows quick initial retries and longer delays for subsequent retries, maximizing chance of success while minimizing user wait time. Randomized delays : Random delays prevent simultaneous retries, avoiding repeated rate limit hits.
Keep in mind that unsuccessful requests still count towards your rate limits for both OpenAI and Azure OpenAI. Evaluate your retry strategy carefully to avoid exceeding rate limits with unsuccessful requests.
Adding Exponential Backoff Logic in Vellum
Below is an interactive preview of a Vellum Workflow implementing exponential backoff logic. If the prompt node encounters an error, the workflow waits for 5 seconds and retries up to 2 times:
Responsive Embed
Optimize your prompts and token usage
While it’s straightforward to measure your RPM, it can be trickier to measure your TPM. By its simplest definition , a “token” is a segment of a word. When you send a request to an OpenAI API, the input is sliced up into tokens and the response is generated as tokens. Therefore, when thinking about TPM, you need to consider the amount of input and output tokens getting generated.
Not sure how to measure your inputs and outputs in terms of tokens? Learn about OpenAI's Tiktoken Library and how to calculate your tokens programmatically here .
OpenAI provides a parameter max_tokens that enables you to limit the number of tokens generated in the response. When evaluating your TPM rate limit, OpenAI and Azure OpenAI use the maximum of the input tokens and your max_tokens parameter to determine how many tokens will count towards your TPM. Therefore, if you set your max_tokens too high, you will end up using up more of your TPM per request than necessary. Always set this parameter as close as possible to your expected response size.
Prompt chaining
Additionally, instead of using very long prompts for a task, consider using prompt chaining.
Prompt chaining involves dividing a complex task into more manageable subtasks using shorter, more specific prompts that connect together. Since your token limit includes both your input and output tokens, using shorter prompts is a great way to manage complex tasks without exceeding your token limit.
We wrote more on this strategy in this article .
Use caching to avoid duplicate requests
Caching stores copies of data in a temporary location, known as a cache, to speed up requests for recent or frequently accessed data. It can also store API responses so future requests for the same information use the cache instead of the API.
Caching in LLM applications can be tricky since requests for the same information may look different. For example, How hot is it in London and What is the temperature in London request the same information but would not match in a simple cache.
Semantic caching solves this by using text similarity measures to determine if requests are asking for the same information. This allows different prompts to be pulled from the cache, reducing API requests. Consider semantic caching when your application frequently receives similar requests; you can use libraries like Zilliz’s GPTCache to easily implement it.
Model providers are also recognizing the need for native caching features in complex workflows. Google’s new context caching for Gemini models lets users cache input tokens and reuse them for multiple requests. This is particularly useful for repeated queries on large documents, chatbots with extensive instructions, and recurring analysis of code repositories. While OpenAI and Azure OpenAI don't support this yet, be on the lookout for future caching features to improve token efficiency.
How to increase your rate limits
If you’re still finding it hard to stay within your rate limits, your best option may be to contact OpenAI or Microsoft to increase your rate limits. Here’s how you can do that:
OpenAI: You can review your usage tier by visiting the limits section of your account’s settings. As your usage and spend on the OpenAI API goes up, OpenAI will automatically elevate your account to the next usage tier, which will cause your rate limits to go up. Azure OpenAI: You can submit quota increase requests from the Quotas page of Azure OpenAI Studio. Due to high demand, Microsoft is prioritizing requests for customers who fully utilize their current quota allocation. It may be worth waiting for your quota allocation to be hit before submitting a request to increase your quota
Strategies for Maximizing Throughput
If you care more about throughput — i.e. the number of requests and/or the amount of data that can be processed — than latency, also consider implementing these strategies:
Add a delay between requests
Even with retrying with exponential backoff, you may still hit the rate limit during the first few retries. This can result in a significant portion of your request budget being used on failed retries, reducing your overall processing throughput.
To address this, add a delay between your requests. A useful heuristic is to introduce a delay equal to the reciprocal of your RPM. For example, if your rate limit is 60 requests per minute, add a delay of 1 second between requests. This helps maximize the number of requests you can process while staying under your limit.
Batch multiple prompts into a single request If you’re reaching your RPM limit but still have capacity within your TPM limit, you can increase throughput by batching multiple prompts into each request. This method allows you to process more tokens per minute.
Sending a batch of prompts is similar to sending a single prompt, but you provide a list of strings for the prompt parameter instead of a single string. Note that the response objects may not return completions in the same order as the prompts, so be sure to match responses to prompts using the index field.
Closing Thoughts
Dealing with OpenAI rate limits can be tough.
They can obstruct honest uses of the API even if they were created to prevent abuse. By using tactics like exponential backoff, prompt optimization, prompt chaining, and caching, you can reasonably avoid hitting rate limits.
You can also improve your throughput by effectively using delays and batching requests. Of course, you can also increase your limits by upgrading your OpenAI or Azure tier.
{{general-cta}}
Extra resources
Beginner’s Guide to Building AI Agents → Best Enterprise AI Agent Builder Platforms → Best Low code AI Workflow Automation Tools → Guide: No Code AI Workflow Automation Tools → Best AI Workflow Platforms →
FAQ: Managing rate limits across providers
1. What are rate limits, and why do they matter?
Rate limits cap how many requests or tokens you can send to a model within a certain timeframe. They prevent server overload, ensure fair use, and control infrastructure costs. For teams scaling apps, hitting these limits can cause delays, errors (429 responses), or downtime.
2. How do OpenAI rate limits work in 2026?
OpenAI still enforces requests per minute (RPM) and tokens per minute (TPM) across all GPT-5 tiers. As of early 2026, GPT-5 Tier 1 typically offers around 500k TPM and roughly 1,000 RPM, with higher tiers providing substantially more capacity. Token usage includes both input and output tokens, so setting a large max_tokens can drain your quota faster than expected.
3. How does Azure OpenAI handle quotas?
Azure uses per-region quotas . You’re allocated a TPM budget (e.g., 1,000,000 TPM in many regions for GPT-4.1). You divide that quota across deployments. RPM scales automatically with TPM. If you need more, you must request a quota increase via the Azure portal.
4. What about Anthropic?
Anthropic enforces RPM and TPM limits much like OpenAI. As of early 2026, Claude 4.5 models can reach around 1M+ TPM for approved enterprise accounts, while most developer accounts start with lower limits that scale based on usage and review. Anthropic continues expanding its context caching capabilities, helping reduce repeated token costs across multi-turn conversations and large-context workflows.
5. What’s the best retry strategy if I hit a limit?
Use exponential backoff with jitter (random delay). Example: wait 1s, then 2s, then 4s, up to ~30s max. This prevents a “thundering herd” of retries. Libraries like backoff (Python) or built-in retry utilities help automate this.
6. How can I plan workloads to avoid rate limit pain?
Batch requests when TPM > RPM. Pre-chunk documents so one request doesn’t blow past your TPM. Cache frequent queries (semantic caching is better than keyword caching). Delay between requests (e.g., if 60 RPM, add ~1s pause).
7. Can I increase my limits?
OpenAI : usage tiers rise automatically with spend. Higher tiers = more TPM/RPM. Azure : submit a quota increase request in the Azure portal. Anthropic : enterprise contracts get priority for higher limits.
8. How does Vellum help with rate limit issues?
Vellum workflows let you:
Add retries with exponential backoff visually, no custom code. Monitor token + request usage across models in one place. Switch between providers when one hits limits, without rewriting your app. This means your team can ship faster without worrying which vendor’s limit is slowing you down.
9. What’s the risk of relying only on retries?
Retries help, but every failed attempt still counts toward your quota. If you retry too aggressively, you may burn through TPM faster. With Vellum , you can simulate workflows, test prompt size, and optimize before deploying so you waste fewer tokens.
10. Should I standardize on one provider or spread across many?
One provider = simpler, but you’re locked into their limits. Multi-provider setup = flexibility. If OpenAI caps you, you can route some traffic to Anthropic or Azure. Vellum makes this approach easier — you can configure workflows to automatically fall back to another provider if one gets rate limited.