LLMs are incredibly powerful and easy to use right out of the box.
However, their outputs are not deterministic and have specific knowledge limitations. So, developers adopt specific methods to increase the knowledge, reduce errors, and steer model responses.
Prompt engineering can help to an extent—advanced techniques like few-shot and chain-of-thought prompting or function calling can greatly improve the quality of output. However, advanced methods like retrieval augmented generation (RAG) or fine-tuning can help you build context-aware apps that are easily steerable and more reliable once in production.
This article compares RAG and fine-tuning to help you determine which approach—or possibly both—is best for your project.
Quick Intro to RAG
Retrieval Augmented Generation (RAG) is a technique that enhances the responses of large language models by using external knowledge that wasn't part of the model's initial training data.
It is non-parametric , which means it doesn't change the model's parameters. Instead, it uses external information as context for the large language model.
How Does RAG Work
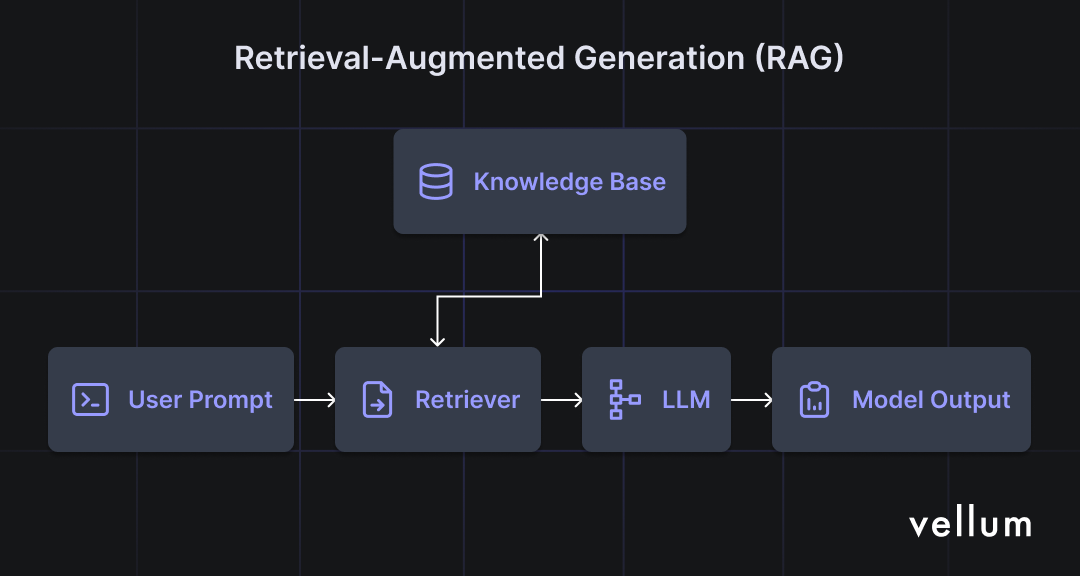
There are many different RAG architectures, but a very basic naive RAG pipeline consists of the following steps:
- Knowledge base creation The first step involves uploading our proprietary data in a vector database. We upload the documents by converting them into vector embeddings using embedding models (for example: text-embedding-ada-002 )
- Retrieval component In this phase, when a user enters a query, the large language model turns the query into a vector and finds the closest matching vectors in the knowledge base. It then retrieves the most relevant document chunks or vectors related to the query.
- Augmentation Next, the retrieved chunks from the previous step are used to add " context " to our prompts.
- Generation Finally, the model uses the retrieved “ context ” and our instructions to generate an answer that is more accurate for the task at hand.
- Evaluation But there is a step after the final step, and that’s evaluations. In this phase we measure the RAG performance, and check things like “context recall” and/or “context relevance”. You can read about how to evaluate your RAG on this link .
When Should I Use RAG?
RAG is a great option for the following use-cases:
Question-answering systems : For example, customer support chatbots are currently powered by a RAG architecture, that uses product documentation and other proprietary data to generate better responses to user questions. Knowledge Extraction: If your application requires user interaction with documents or the extraction of specific details, RAG is a highly effective choice. It allows users to efficiently sift through large number of documents to find and utilize the information they need. Critical Applications: In domains where hallucination is not an option, such as medical or legal systems, RAG can help ensure factually accurate and reliable responses. Dynamic Data Integration: RAG is perfectly suited for applications that depend on the most up-to-date and constantly refreshed data. This approach ensures that users access the latest information by dynamically retrieving content through RAG processes, keeping the data current and relevant.
Pros and Cons of RAG
RAG systems have their advantages and disadvantages.
Pros:
Reduces Hallucinations: RAG reduces hallucinations by referencing proprietary information that grounds the LLM response. External data in real-time: RAG enables the LLM to access external data in real-time, providing up-to-date information. Easier to debug and improve: It's simpler to debug and assess each step in the process to make improvements. Cost-Effective to set up: Setting up a RAG infrastructure has minimal initial costs, as it does not require fine-tuning the model or curating a labeled dataset. Fast Prototyping: You can quickly build a simple RAG pipeline. This can help test various ideas and determine whether RAG is the best solution for a given use case.
Cons:
Complexity: A typical RAG pipeline involves numerous components (indexing, retriever, generator), introducing additional complexity. For instance, you must devise an optimal chunking strategy, which can vary depending on the task. Increased Latency: The additional steps involved in the RAG process tend to result in higher latency. Context Size Limitation: Dynamically retrieving data from a vector database increases the token count in your prompt, which can be challenging when dealing with large documents within a constrained context window. Utilizing prompt chaining can mitigate this issue by allowing for a more manageable distribution of data. Read about it here . Inference Cost: Although very cheap to set up, RAG models introduce higher inference cost due to factors such as increased prompt size from the added context.
Quick Intro to Fine-Tuning
Fine-tuning a language model involves training it on a smaller, specialized dataset that's designed for a specific task or domain. This approach is particularly effective if you're dealing with a standardized task and aim to enhance the performance of your large language model.
How Does Fine Tuning Work
This method involves two main steps:
Curating the dataset: Collect existing data or generate new examples to compile a high-quality, diverse dataset relevant to the target task. Use other models, like GPT-4 , for generating new test cases. Ideally, this dataset should represent various examples and edge cases to ensure comprehensive learning. Update the base LLM’s parameters: Use comprehensive fine-tuning, which affects all model parameters, or opt for Parameter-Efficient Fine-Tuning ( PEFT ) techniques like Low-Rank Adaptation ( LoRA ). We actually cut model costs by >90% by swapping LoRA weights dynamically - read about it here . During this phase, various foundation models can be experimented with. Hyperparameters, such as the learning rate and epoch, can be tuned to achieve the desired output.
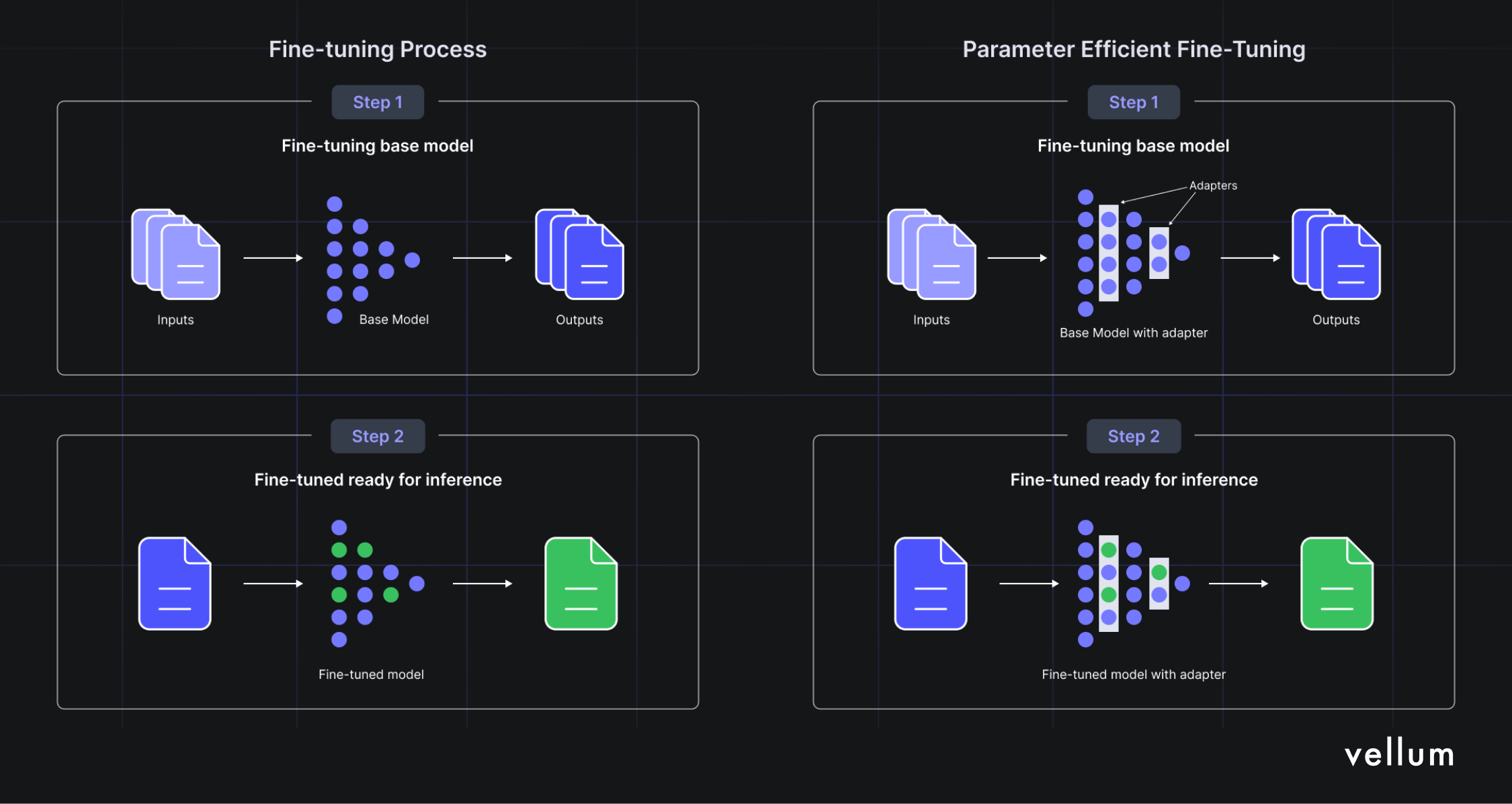
These fine-tuned models can be evaluated by human annotators, or more recently, developers use LLMs as evaluators ( LLM-as-a-judge ) to save on costs, and speed up evaluation drastically.
When Should You Fine-Tune Your Models?
Task-Specific : If you want your LLM to be capable of handling a specific task, fine-tuning is perfect. The model will excel at the desired task by adapting its parameters accordingly. Domain-Specific : Fine-tuning is a suitable approach if you want your LLM to develop expertise in a particular domain, such as law. By fine-tuning the model based on relevant data from the target domain, it can better understand and generate responses related to that domain. Extending Base Model's Capability: Fine-tuning is the perfect option to enhance the base model's capabilities or adapt it to new tasks it was not initially trained for. This allows the model to maintain its general knowledge while acquiring new skills. Defining a Custom Style or Tone: Fine-tuning is ideal for establishing a unique response style or tone for your LLM, which can be challenging to achieve through prompting alone.
Pros and Cons of Fine-Tuning
Fine-tuning has its benefits and drawbacks.
Pros:
Task-Specific Optimization: Fine-tuned models exhibit superior performance on targeted tasks compared to their base versions. Efficient Contextualization : No need for prompt engineering, the model is already fine-tuned on relevant context. Low Latency: Fine-tuned models produce results much quicker than other alternatives like RAG. Reduced Cost: Fine-tuning a model also helps with cost reduction. A fine-tuned model, in particular, would generally outperform a more powerful model, which would be more expensive.
Cons:
Needs a dataset: Fine-tuning a model requires a dataset, which can be a hassle to create since the quality of the dataset can significantly impact the model's performance. Catastrophic Forgetting: There's a risk that fine-tuning for a specific task might degrade the model's performance on previously capable tasks. Prone to overfitting: Fine-tuned models fit too closely to the training data, resulting in poor generalization to even small discrepancies in real-world examples.
Choosing Between RAG and Fine-Tuning
Each method has pros and cons, and the choice between them often depends on the project's needs. Here’s a quick guide to get even more clarify regarding your goals:
#### 1. Analyze your problem
Start with a comprehensive analysis of the problem, to understand what are the needed parameters to solve for it. For example, analyze whether the problem requires:
leveraging vast external data dynamically (suited for RAG); or it requires deep, nuanced understanding of a narrower dataset (suited for fine-tuning).
#### 2. Assess your data
Fine-tuning works best when you have a rich, well-labeled dataset related to your task. RAG works best when you have lots of unstructured data but relevant external knowledge, making it ideal for tasks with little or expensive task-specific data.
#### 3. Evaluate Team Skills
RAG and fine-tuning require team expertise. While it has become easier to fine-tune models, the process still demands considerable expertise in machine learning and data preprocessing. RAG, however, requires knowledge of information retrieval, vector databases, and possibly more complex system integration.
#### 4. Experiment
We always recommend achieving good results with prompt engineering, chaining, and/or function calling. If these techniques do not yield satisfactory outcomes, then consider moving to RAG, and finally to fine-tuning. If you're looking to test and compare different configurations of your setup, Vellum provides a comprehensive set of tools that can help with these evaluations. Below you can find more info on how yo leverage Vellum to set up experiments, and develop a production-ready system.
While you'd usually find one approach sufficient, in some cases the best user experience comes from combining both RAG and fine-tuned models.
Mixing Both Techniqes with RAFT
Recent research introduces Retrieval Augmented Fine-Tuning (RAFT), a method that trains large language models to be more precise on specific topics and i mproves their ability to use relevant documents to answer questions.
This technique is often compared to studying for an open-book exam , where you not only have access to external resources but also know exactly which subjects or materials to consult. For example, when presented with a question and multiple documents, the model is instructed to ignore any documents that don't help answer the question, focusing only on the relevant ones.

Evaluate RAG vs Fine-Tuning with Vellum
Vellum is an ideal tool for experimenting and prototyping with LLMs. It can also aid your decision-making when choosing between RAG and fine-tuned models.
Quickly Set Up a RAG Pipeline: Setting up a RAG pipeline can be complex and time-consuming, which may hinder experimentation. With Vellum Workflows and their fully managed retrieval, you can efficiently create an RAG pipeline and evaluate its performance against your tasks. Experiment with Prompts: Vellum's prompt engineering tool allows you to easily experiment with different prompt techniques, and models. Evaluate Your Models: Vellum's evaluation allows you to set up test cases to assess the LLM’s performance. You can compare various model configurations using test cases and custom metrics. For example, you can continuously iterate on your RAG to make it reach the success criteria. Essentially you might end up using both RAG and fine-tuned models to create an exceptional user experience.
Here are some more resources:
How to evaluate your RAG system? When to use fine tuning? RAG vs Long Context?





