LLMs have made huge progress in reasoning. Many of the newest “reasoning models” — like OpenAI’s o1/o3 series or Anthropic’s Claude 3.5+ — already include step-by-step reasoning as a built-in component. That means you often get structured answers without having to prompt for them explicitly.
But Chain-of-Thought (CoT) prompting is still very useful. For non-reasoning models , or in tasks where you want more control over how the reasoning is surfaced, CoT can boost accuracy and transparency. The key is knowing when it adds value and when it just adds cost.
In this article, we’ll cover:
What CoT is and how it works — from basic examples to zero-shot and automated variants. When to use CoT — and when reasoning-native models make it less necessary. New developments in 2025 — including Layered CoT, Trace-of-Thought for smaller models, and LongRePS for long-context reasoning. Limits and trade-offs — why CoT can sometimes mislead and how to manage cost and latency. Practical guidance — how to evaluate CoT in your own workflows, plus how Vellum helps you test, monitor, and deploy these techniques in production.
If you’re building apps where reasoning quality matters, from finance to healthcare to enterprise ops, this guide will help you understand when Chain-of-Thought prompting makes sense, and how to get the most out of it.
What is Chain-of-Thought Prompting?
Chain-of-Thought (CoT) prompting is a technique that guides LLMs to follow a reasoning process when dealing with hard problems. This is done by showing the model a few examples where the step-by-step reasoning is clearly laid out. The model is then expected to follow that "chain of thought" reasoning and get to the correct answer.
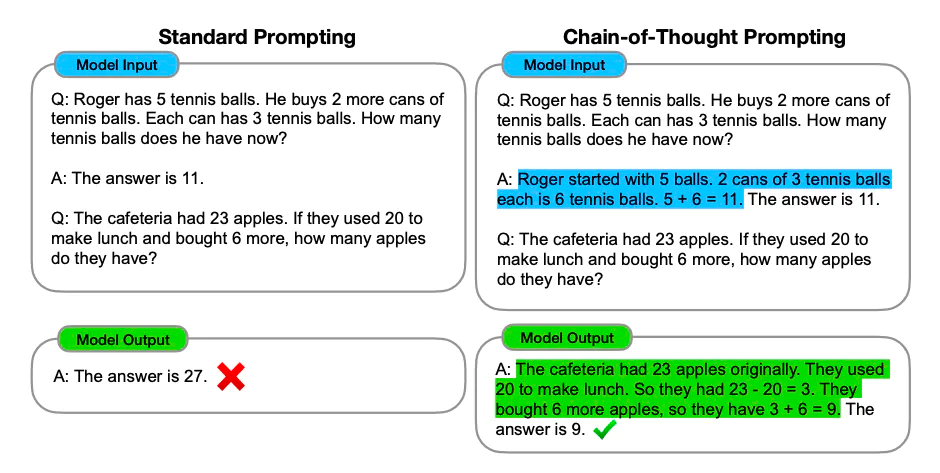
This technique is highly effective because it breaks down complex problems into more manageable parts. The approach allows models to focus on solving each part step-by-step, which boosts their accuracy.
Given its success with complex tasks, newer models like OpenAI o1 now embed this approach natively, making them even better at handling challenging problems, but require different set of prompting techniques.
Standard CoT example
Solving a Linear equation
LLM models are getting better at math, but it’s still one of their biggest challenges. When you use a LLM to solve for math problem, it helps to guide the model through the steps it should take before reaching the final answer. Check the example below:
System message: You’re the best mathematician in the world and you’ll help me solve linear equations. Example: For the equation 5x - 4 = 16 1. Add 4 to both sides: 5x - 4 + 4 = 16 + 4 → 5x = 20 2. Divide both sides by 5: 5x / 5 = 20 / 5 → x = 4
User Message: Now solve 2x + 3 = 7
And we get this output from GPT-4o:
- Subtract 3 from both sides: 2x + 3 - 3 = 7 - 3 → 2x = 4 2. Divide both sides by 2: 2x / 2 = 4 / 2
The model followed the intermediate steps and arrived to the correct answer. Usually, you might want the model to think through steps but only display the final result.
Now, usually, in your use-case you might want to let the model think (follow a step-by-step process) but you only want to surface the final output.
You can do this by either chaining your prompts or using techniques like placing the thinking process in a separate XML tag (e.g., <thinking> ) and the answer in another (e.g., <answer> ). Afterward, you can apply data transformation to filter and display only the answer to the end user. You can read about some of these techniques here .
This might look very similar to few-shot prompting , but there is a significant difference.
Difference between Few-Shot prompting and Chain-of-Thought?
Few-shot prompting is when you give a few examples so the language model can understand want it should do. So the previous examples will not go into the intermediate steps. The math example will look more like: "For the equation 5x - 4 = 16, The result is: x = 4."
On the other hand, Chain-of-Thought prompting is about showing the step-by-step thinking from start to finish, which helps with “reasoning” and getting more detailed answers.
Bottom line: It's about showing the work, not just the answer.
When should you use Chain-of-Thought prompting?
CoT is ideal when your task involves complex reasoning that require arithmetic, commonsense, and symbolic reasoning; where the model needs to understand and follow intermediate steps to arrive at the correct answer. Just look at the benchmarking report in the image below that Claude release a few months ago. For all benchmarks that evaluate for reasoning (GPQA,MMLU,DROP, Big Bench) they use 3-shot or 5-shot CoT prompting!
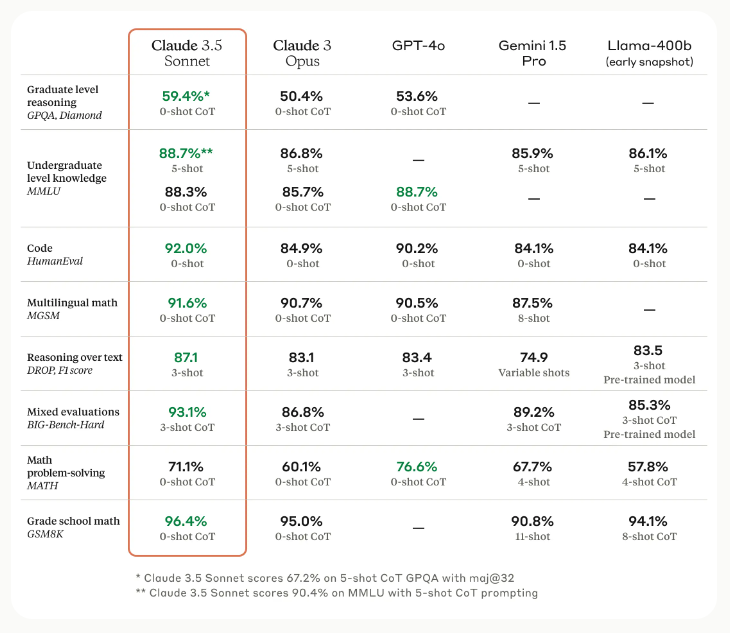
In terms of model sizes, this technique works really well with bigger models (>100 billion parameters); think PaLM , and GPT-4o .
On the flip side, smaller models have shown some issues , creating odd thought chains and being less precise compared to standard prompting.
In other specific cases, you don’t even need to show the intermediate steps; you can just use Zero-Shot CoT prompting.
What is Zero-Shot Chain-of-Thought prompting?
Zero-shot chain-of-thought (Zero-Shot-CoT) prompting involves adding "Let's think step by step" to the original prompt to guide the language model's reasoning process. This approach is particularly useful when you don't have many examples to use in the prompt.
Let's say you're trying to teach the AI about a new concept, like "quantum physics," and you want it to generate some explanations. Instead of just saying, "Explain quantum physics," you can just say "Let's think step by step: Explain quantum physics."
That’s it.
By including the "Let's think step by step" part, you help the AI break down complex topics into manageable pieces.
And you can do this on auto-pilot.
Automatic chain of thought (Auto-CoT)
Automatic Chain of Thought or Auto-CoT automatically generates the intermediate reasoning steps by utilizing a database of diverse questions grouped into clusters.
Auto-CoT goes through two main stages:
Question Clustering: First, they partition questions of a given dataset into a few clusters. So, if people asked the computer program a bunch of questions about baking, like "How do I mix the ingredients?" and "What temperature should I bake a pie at?" these would go into different groups. Demonstration Sampling: Once they have these question groups, they pick one question from each group and use Zero-Shot CoT prompt (basically the “Let’s think step by step” prompt). This way, the computer program generates clear and straightforward instructions on auto-pilot.
The process is illustrated below:

What's considered complex reasoning for LLMs today?
If we ask GPT-4o today to solve for x in the equation (64 = 2 + 5x + 32), it will solve it without any examples given. This may look like a simple math problem, but at the beginning of 2023 this was a very challenging problem even for GPT-4.
These days, it seems like the model automatically provides step-by-step answers to most reasoning questions by default . Go ahead, try it!
Now, just think about how much smarter an LLM can become when you provide it with a step-by-step guide to optimize your code, restructure your databases, or develop a game strategy for popular games like "Minecraft.”
And imagine how powerful this technique can be when scientists teach an AI to follow detailed step-by-step diagnosis for complex medical conditions.
The possibilities are endless, and that’s where these techniques come in handy, especially when we introduce the “visual” element to the mix.
Multimodal Chain-of-Thought prompting
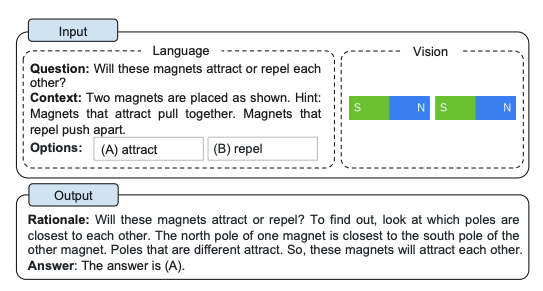
Multimodal Chain-of-Thought prompting uses both words and pictures to showcase the reasoning steps, to help guide the LLM to showcase its “reasoning”, and the right answer.
And if you were following the latest AI news, multi-modality is coming to an LLM near you.
ChatGPT can now see and talk utilizing GPT-4V(ision) ; and it can help you fix a bike seat if you share a picture of your bike, the manual, and your tools.
Well, with MultiModal Chain-of-Thought prompting you can lay out the reasoning tasks, share the photos upfront and get to the answer right away.
But, what are the limits to CoT prompting?
The biggest limit is that there is no guarantee of correct reasoning paths, and since we don’t really know if the model is really “reasoning” with us, this can lead to both correct and incorrect answers.
There are other prompt techniques like Self-Consistency which incorporate different “reasoning examples” for a single task and Tree of Thoughts (ToT) that has like a map of possible paths, and self-calibrates if it goes towards the wrong path. Apart from this prompting technique, you can follow some best practices on how to prompt these models - we've outlined all on this link.
How to make the most of your CoT prompts?
No matter the prompt engineering technique you pick for your project, it's important to experiment, test, and understand what your end users think.
With Chain of Thought (CoT) prompting, it tends to do better with bigger models and tricky reasoning tasks. If you're making an app and this sounds like what you need, we can help.
Vellum.ai gives you the tools to try out different Chain of Thought prompts and models, check how good they are, and tweak them easily once they're in production — no custom code needed! Request to talk with our AI experts if you have any questions!
When Chain-of-Thought isn’t worth it
Recent studies show that CoT isn’t always a free win. While it can help on tricky tasks, it often adds extra tokens, latency, and cost. For many newer reasoning-ready models, the gains are modest — and sometimes accuracy even goes down because the model “overthinks” and produces a wrong path. In other words, you pay more but don’t always get better results.
If you’re using reasoning-native models like OpenAI’s o1/o3 series or Anthropic’s latest Claude, test carefully. They already handle many reasoning tasks without explicit CoT, so you may not need to add it at all. ( The Decreasing Value of Chain of Thought in Prompting, 2025 ).
New prompting strategies
Researchers are experimenting with ways to push CoT further:
Layered CoT : breaks reasoning into multiple passes or “layers,” with chances to review or adjust. Useful in high-stakes areas like healthcare or finance ( Layered Chain of Thought, 2025 ). Trace-of-Thought : designed for smaller models (~7B parameters), it creates subproblems to improve arithmetic reasoning ( Trace-of-Thought, 2025 ). LongRePS : built for long-context tasks, this framework supervises reasoning paths across very large inputs ( LongRePS, 2025 ).
These techniques show that prompting is moving beyond plain CoT into structured, task-specific strategies
Faithfulness of reasoning steps
One of the biggest open questions: do the reasoning traces actually reflect what the model “thought”? Just because you see a neat step-by-step path doesn’t mean that’s how the model solved it internally.
This matters because users may over-trust flawed reasoning. Research highlights that models sometimes generate convincing but unfaithful steps, especially when the data is different from what they were trained on ( On the Faithfulness of Chain-of-Thought Explanations, 2025 ). For production systems, you may need extra checks — like self-consistency or external validators — before exposing reasoning traces to end users.
The cost trade-off
Chain-of-Thought almost always means more tokens and slower responses. For small tests, this doesn’t matter. But in production, costs add up fast. If you’re serving thousands of users, every extra reasoning step eats into latency and budget ( The Decreasing Value of CoT, 2025 ).
A practical rule: use CoT when the task clearly benefits (complex math, symbolic logic, multi-step decisions). Skip it when the model is already strong enough to answer directly.
Chain of thought prompts in Vellum
Chain-of-Thought prompting isn’t just theory — it’s a tool you can experiment with today. Whether you’re working with reasoning-native models that already think step by step, or non-reasoning models where CoT still makes a big difference, the key is testing, measuring, and refining.
With Vellum , you can:
Compare prompts side by side across multiple models. Track cost, latency, and accuracy in real time. Capture full reasoning traces for observability — while showing only the final answer to end users. Safely deploy updates without rewriting code.
👉 Talk to our AI experts and see how Vellum can help you get the most out of Chain-of-Thought prompting in production.
FAQ: Making Chain-of-Thought Work in Practice
Q1. How do I know if Chain-of-Thought is actually helping my use case?
The best way is to test. Run the same task with and without CoT prompts and compare accuracy, latency, and cost. Vellum makes this easy by letting you A/B test different prompts and models in one place, then measure which setup gives the best trade-off for your workload.
Q2. Isn’t CoT expensive to run at scale?
Yes, it usually costs more tokens and time. But you don’t have to guess if it’s worth it. With Vellum , you can monitor how much CoT improves outcomes versus how much it adds to cost. If the lift in accuracy is tiny, you’ll see that clearly and can switch to simpler prompting.
Q3. What if I don’t want users to see the messy reasoning steps?
That’s a common scenario. In Vellum, you can capture the model’s reasoning trace for observability while only showing the final answer to end users. This way, your product stays clean, but your team still has visibility into why the model made a decision.
Q4. How do I stop CoT from “hallucinating” wrong reasoning paths?
CoT doesn’t guarantee the reasoning is correct. That’s why teams often pair it with self-consistency checks or tree-of-thought approaches . Vellum helps here by letting you orchestrate these variations — for example, running multiple reasoning paths in parallel and picking the most consistent output.
Q5. Do smaller models benefit from CoT, or is it just for big ones like GPT-4?
CoT generally shines with large models, but new research (like Trace-of-Thought for smaller 7B models) shows you can still get a boost. Vellum lets you try both small and large models side by side — useful if you want to save on cost without losing too much accuracy.
Q6. How do I combine multimodal input (text + images) with CoT?
Models like GPT-4V can already reason across text and images. With Multimodal CoT , you show both the problem and visual context step-by-step. In Vellum , you can prototype these workflows directly: pass images, apply structured CoT prompts, and measure whether the model uses the visuals effectively.
Q7. How do I avoid “overprompting” now that newer models already reason by default?
Great question — with OpenAI o1/o3 and Anthropic Claude 3.5+, too much prompting can actually hurt results. Vellum gives you observability across runs so you can see when extra prompting helps and when the model does fine on its own. That way, you don’t waste tokens or time.
Q8. What’s the safest way to deploy CoT in production with Vellum?
Start small: test prompts, evaluate outputs, and add monitoring. With Vellum you can:
Track every reasoning trace in production (latency, cost, output quality) Run evaluations to see if accuracy is improving or drifting Roll out updates safely without rewriting code
That combination gives you confidence to use CoT techniques in real-world systems without surprises.