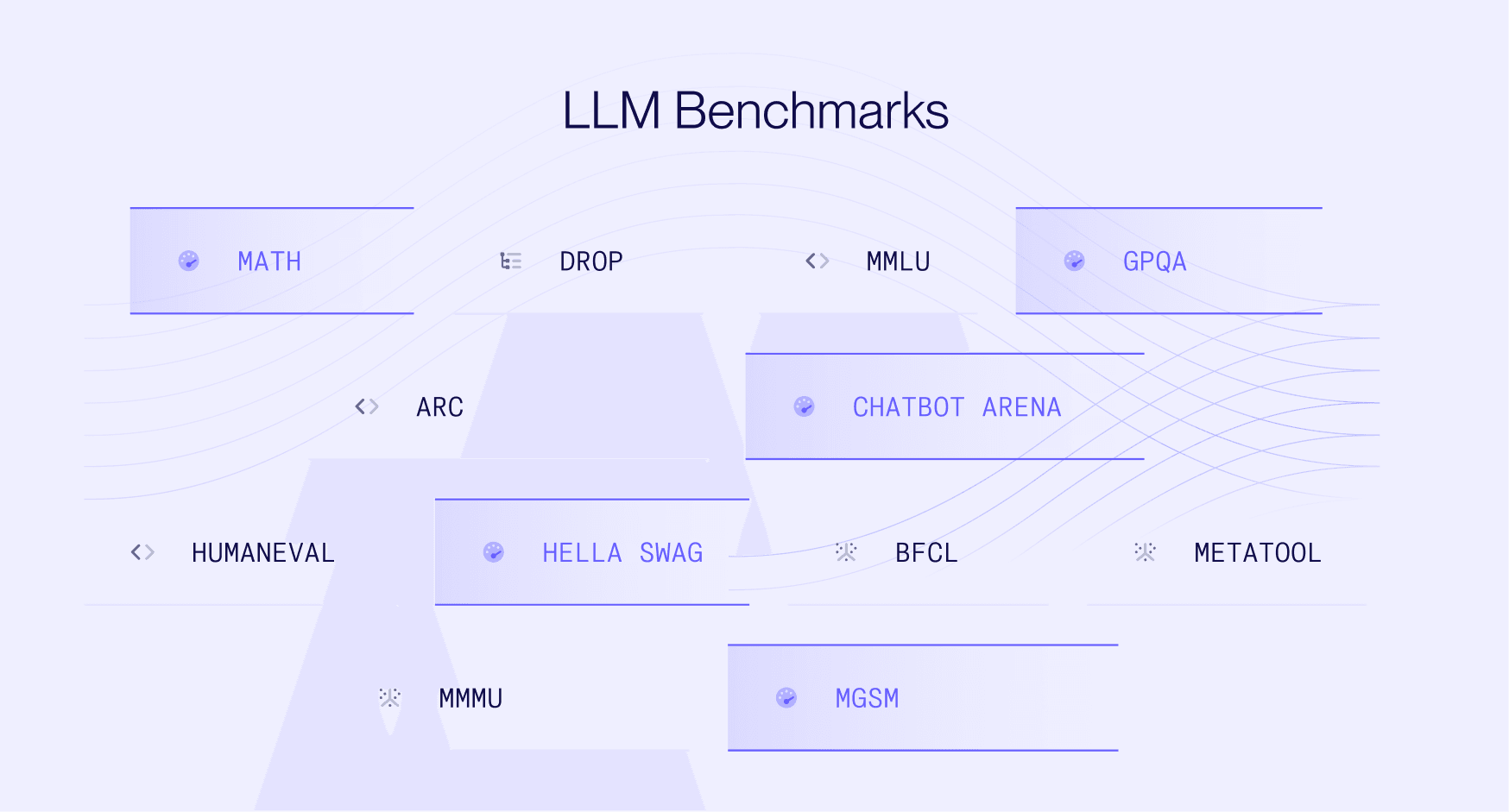
Why do we need LLM benchmarks?
They provide a standardized method to evaluate LLMs across tasks like coding, reasoning, math, truthfulness, and more.
By comparing different models, benchmarks highlight their strengths and weaknesses.
Below we share more information on the current LLM benchmarks, their limits, and how various models stack up.
Model Performance Across Key LLM Benchmarks
These are the most commonly utilized LLM Benchmarks among models’ technical reports:
MMLU - Multitask accuracy GPQA - Reasoning capabilities HumanEval - Python coding tasks MATH - Math problems with 7 difficulty levels BFCL - The ability of the model to call functions/tools MGSM - Multilingual capabilities
Here's how the top LLM models rank on these benchmarks (as today, September 8th 2024). We’ve highlighted the top-performing models: Green for the highest rank, Blue for second, and Orange for third:
| Model | Average | Multilingual | Tool Use | Math | Reasoning | Code | General |
|---|---|---|---|---|---|---|---|
| Claude 3.5 Sonnet | 82.10% | 91.60% | 90.20% | 71.10% | 59.40% | 92.00% | 88.30% |
| GPT-4o | 80.53% | 90.50% | 83.59% | 76.60% | 53.60% | 90.20% | 88.70% |
| Meta Llama 3.1 405b | 80.43% | 91.60% | 88.50% | 73.80% | 51.10% | 89.00% | 88.60% |
| GPT-4 Latest | 78.12% | 88.50% | 86.00% | 72.60% | 48% | 87.10% | 86.50% |
| Claude 3 Opus | 76.70% | 90.70% | 88.40% | 60.10% | 50.40% | 84.90% | 85.70% |
| OpenAI GPT-4 | 75.52% | 85.90% | 88.30% | 64.50% | 41.40% | 86.60% | 86.40% |
| Meta Llama 3.1 70b | 75.48% | 86.90% | 84.80% | 68% | 46.70% | 80.50% | 86% |
| Google Gemini 1.5 Pro | 74.13% | 88.70% | 84.35% | 67.70% | 46.20% | 71.90% | 85.90% |
| GPT-4o mini | 61.10% | 87.00% | n/a | 70.20% | 40.20% | 87.20% | 82.00% |
| Meta Llama 3.1 8b | 62.55% | 68.90% | 76.10% | 51.90% | 32.80% | 72.60% | 73% |
| Claude 3 Haiku | 62.01% | 71.70% | 74.65% | 38.90% | 35.70% | 75.90% | 75.20% |
| Google Gemini 1.5 Flash | 66.70% | 75.50% | 79.88% | 54.90% | 39.50% | 71.50% | 78.90% |
| GPT-3.5 Turbo | 53.90% | 56.30% | 64.41% | 34.10% | 30.80% | 68.00% | 69.80% |
| Google Gemini Ultra | 41.93% | 79.00% | n/a | 53.20% | 35.70% | n/a | 83.70% |
In summary, at the time of writing this blog post, the TL;DR of this leaderboard indicates that the best model is Claude 3.5 Sonnet with average performance across all these benchmarks of 82.10%. It has the highest results across multiple benchmarks. It achieved 91.60% in Multilingual (MGSM), 90.20% in Tool Use (BFCL), and an impressive 92.00% in Code (HumanEval). It also performed well in Math (71.10%) and Reasoning (59.40%), making it a strong all-around performer across key categories.
For some of these benchmarks, we have other models who are relatively close to Claude 3.5 Sonnet. Especially we're seeing big results from open sourced models, specifically Llama 3.1 405b. From this table we can summarize that:
For the Multilingual use (MGSM) Claude 3.5 Sonnet and Meta Llama 3.1 405b have tied results for first place with 91.60% accuracy. For Tool Use (BFCL) :Claude 3.5 Sonnet led with 90.20%, followed by Meta Llama 3.1 405b with 88.50%. For Math tasks (MATH) : GPT-4o scored the highest with 76.60%, while Meta Llama 3.1 405b was runner-up at 73.80%. For reasoning (GPQA) Claude 3.5 Sonnet led with 59.40%, followed by GPT-4o with 53.60%. High-reasoning performance was always a characteristic of GPT-4o and it's interesting to see that Claude 3.5 Sonnet is leading here. For Coding tasks (HumanEval) , Claude 3.5 Sonnet was top with 92.00%, followed closely by GPT-4o at 90.20%. Expected results here! For General capabilities (MMLU) : GPT-4o leads with 88.70%, followed by Meta Llama 3.1 405b (88.60%).
A note on open-source models
Meta’s open-source models, particularly Llama 3.1 405b, performed impressively across benchmarks, competing closely with top proprietary models like Claude 3.5 Sonnet. It tied for first in Multilingual tasks and led in the General benchmark (MMLU) with 88.60%. Meta’s models offer a competitive alternative, especially in tasks like Code and Math, where Llama 3.1 405b consistently placed as a runner-up, proving that open-source models can deliver strong performance while offering more flexibility. Although not accessible for wider use, we definitely see a pattern where open-source models are starting to get similar results to top-tier proprietary models.
In the next sections we'll look at each of these benchmarks and some others, their datasets, and how they work.
Benchmarking LLMs for Reasoning
HellaSwag - Measuring Commonsense Inference
paper | dataset [released 2019]
This test measures the c ommonsense reasoning of LLM models. It tests if an LLM model could complete a sentence by choosing the correct option with common reasoning among 4 options.
For example:

Questions that seem simple to humans often posed challenges for state-of-the-art (SOTA) models released in 2019, as they had difficulty with commonsense inference, achieving only about 45% accuracy. By 2024, GPT-4 has achieved the highest benchmark score with 95.3% accuracy in this area, while among open-source models, Mixtral 8x7B leads with an accuracy of 84.4% (check more models )
ARC - Reasoning benchmark
paper | dataset [released 2019]
ARC can be used to measure a human-like form of general fluid intelligence and that it enables fair general intelligence comparisons between AI systems and humans. The ARC dataset contains 7787 non-diagram , 4-way multiple-choice science questions designed for 3rd through 9th grade-level standardized tests.
DROP - A Reading Comprehension + Discrete Reasoning Benchmark
paper | dataset [released 2019]
DROP evaluates models on their ability to pull important details from English-language paragraphs and then perform distinct reasoning actions, such as adding, sorting or counting items, to find the right answer. Here’s an example:

In December 2023, HuggingFace noticed that there is an issue with the normalization step with the DROP benchmark. This normalization discrepancy showed issues with handling numbers followed by certain types of whitespace and the use of punctuation as stop tokens, which led to incorrect scoring. Additionally, models that generated longer answers or were supposed to handle floating point answers did not perform as expected. An attempt to improve scoring by changing the end-of-generation token showed potential for better alignment with overall performance, but a full solution would require a significant rerun of the benchmark, which was deemed resource-intensive.
QA and Truthfulness Benchmarks
MMLU - Measuring Massive Multitask Language Understanding
paper | dataset [released 2021]
This test measures model's multitask accuracy. It covers 57 tasks including elementary mathematics, US history, computer science, law, and more at varying depths, from elementary to advanced professional level . To get high accuracy on this test, models must have extensive world knowledge and problem solving ability. Check how the top models (proprietary/open-source) stack up on this benchmark.
TruthfulQA
paper | dataset [released 2022]
This benchmark measures whether a language model is truthful in generating answers to questions. The benchmark comprises 817 questions that span 38 categories, including health, law, finance and politics. For this benchmark, GPT-4 seems to perform the best.
Math Benchmarks
MATH - Arithmetic Reasoning
paper | dataset [released 2021]
MATH is a new benchmark, that has a dataset of 12,500 challenging competition mathematics problems. Each problem in MATH has a full step-by-step solution which can be used to teach models to generate answer derivations and explanations. The authors of this benchmark found out that increasing budgets and model parameter counts will be impractical for achieving strong mathematical reasoning, if scaling trends continues. Check how current models stack up on this benchmark.
GSM8K - Arithmetic Reasoning
paper | dataset [released 2021]
This dataset consists of 8.5K high quality linguistically diverse grade school math word problems. These problems take between 2 and 8 steps to solve, and solutions primarily involve performing a sequence of elementary calculations using basic arithmetic operations (+ - / *) to reach the final answer. A bright middle school student should be able to solve every problem, but some models find these tasks still challenging.
Chatbot Assistance Benchmarks
There are two widely used benchmarks for evaluating human preference when it comes to chatbot assistance.
Chatbot Arena
paper | dataset
Developed by the LMSYS organization, the Chatbot Arena is a crowdsourced open platform for LLM evals. So far they’ve collected over 200K human preference votes to rank LLMs in with the Elo ranking system.
How it works: You ask a question to two anonymous AI models (like ChatGPT, Claude, or Llama) without knowing which is which. After receiving both answers, you vote for the one you think is better. You can keep asking questions and voting until you decide on a winner. Your vote only counts if you don't find out which model provided which answer during the conversation.
MT Bench
dataset | paper
MT-bench is a set of challenging multi-turn open-ended questions for evaluating chat assistants with LLM-as-a-judge. To automate the evaluation process, they prompt strong LLMs like GPT-4 to act as judges and assess the quality of the models' responses.
Coding Benchmarks
HumanEval - Coding Benchmark
paper | dataset [released 2021]
This is the most used benchmark to evaluate the performance of LLMs in code generation tasks.
The HumanEval Dataset has a set of 164 handwritten programming problems that evaluate for language comprehension, algorithms, and simple mathematics, with some comparable to simple software interview questions. Each problem includes a function signature, docstring, body, and several unit tests, with an average of 7.7 tests per problem. Learn how LLMs compare on this task.
MBPP - Coding Benchmark for Python problems
paper | dataset [ released 2021]
The benchmark consists of around 1,000 crowd-sourced Python programming problems, designed to be solvable by entry level programmers, covering programming fundamentals, standard library functionality, and so on. Each problem consists of a task description, code solution and 3 automated test cases ( see how LLMs compare)
Tool Use Benchmarks
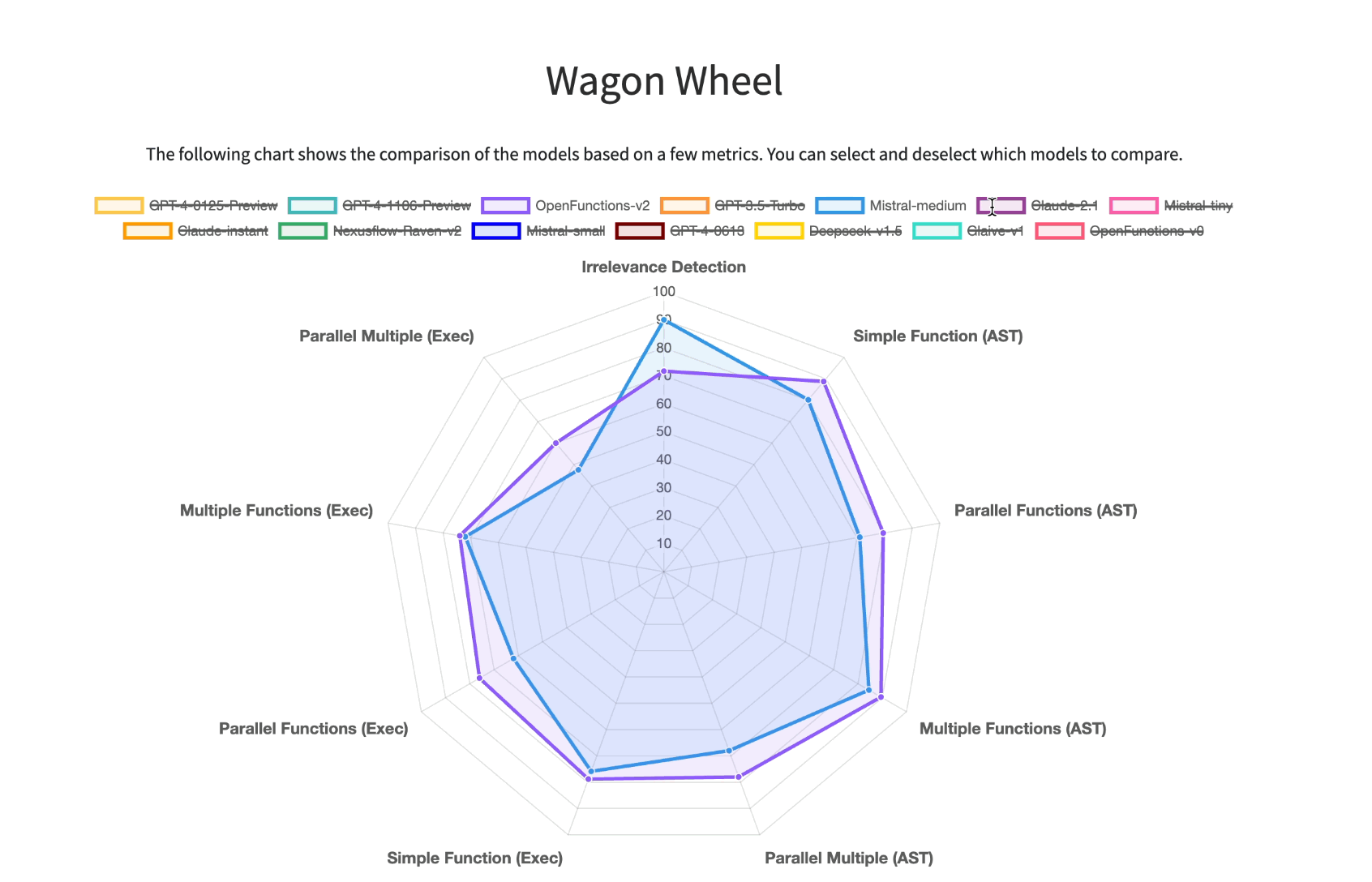
Berkeley Function Calling Leaderboard
paper | dataset | leaderboard [released 2024]
The Berkeley Function-Calling Leaderboard (BFCL) is designed to thoroughly evaluate the function-calling capabilities of different LLMs. It features 2,000 question-function-answer pairs across various languages and application domains, with complex use cases. The BFCL also tests function relevance detection, determining how models handle unsuitable functions.
Key features of BFCL include:
100 Java, 50 JavaScript, 70 REST API, 100 SQL, and 1,680 Python cases. Scenarios involving simple, parallel, and multiple function calls. Function relevance detection to ensure appropriate function selection.
They have also created a visualization of the outcomes to help with understanding this data:
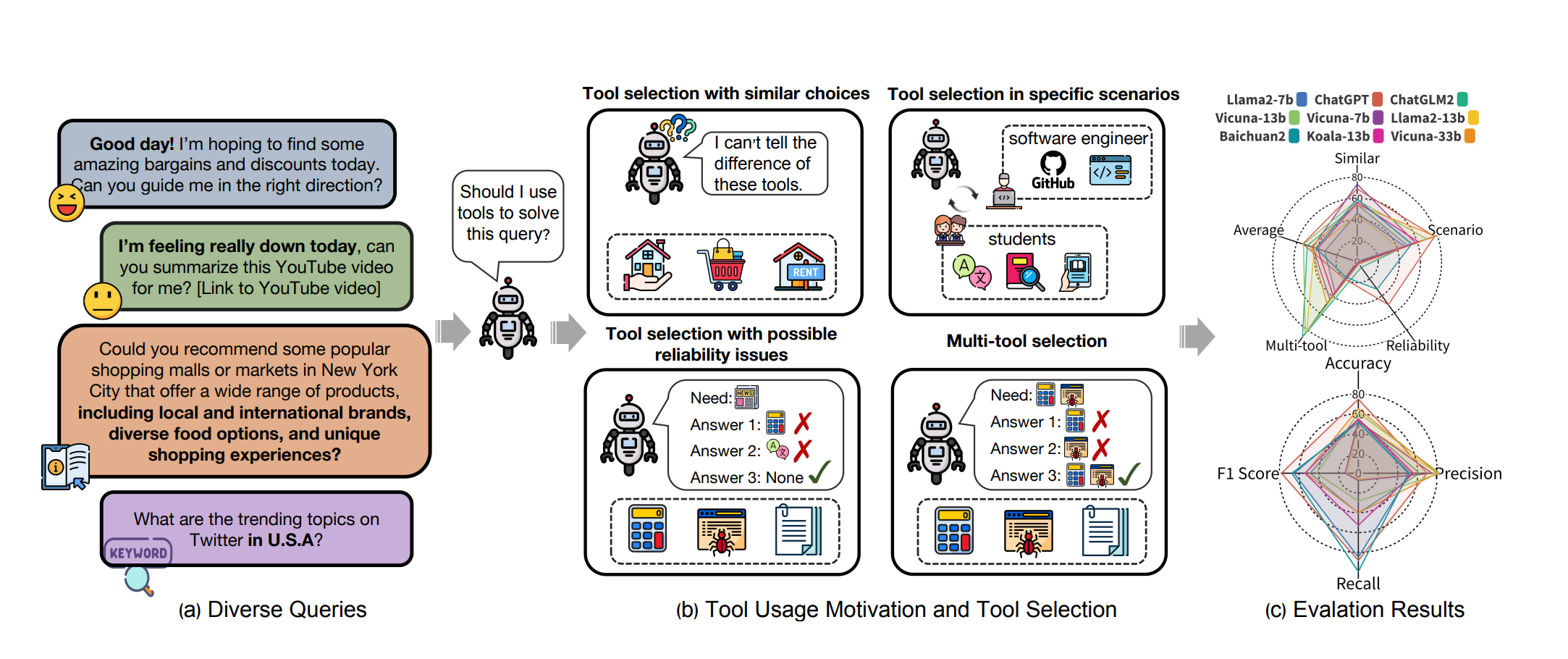
MetaTool Benchmark: Deciding Whether to Use Tools and Which to Use
paper | dataset [released 2023]
MetaTool is a benchmark designed to assess whether LLMs possess tool usage awareness and can correctly choose tools. It includes the ToolE Dataset, which contains prompts triggering single-tool and multi-tool scenarios, and evaluates tool selection across four subtasks. Results from experiments on nine LLMs show that most still face challenges in effective tool selection, revealing gaps in their intelligent capabilities.
MultiModality Benchmarks
MMMU Benchmark
paper | leaderboard
MMMU (Massive Multimodal Multidiscipline Understanding) is a benchmark for evaluating multimodal models on complex, college-level tasks requiring advanced knowledge and reasoning. It features 11.5K multimodal questions from six core disciplines, spanning 30 subjects and 183 subfields, with diverse image types like charts, diagrams, and maps. MMMU challenges models in both perception and reasoning. Testing on 14 open-source models and GPT-4V(ision) showed even GPT-4V achieved only 56% accuracy, highlighting significant room for improvement in multimodal AI models.
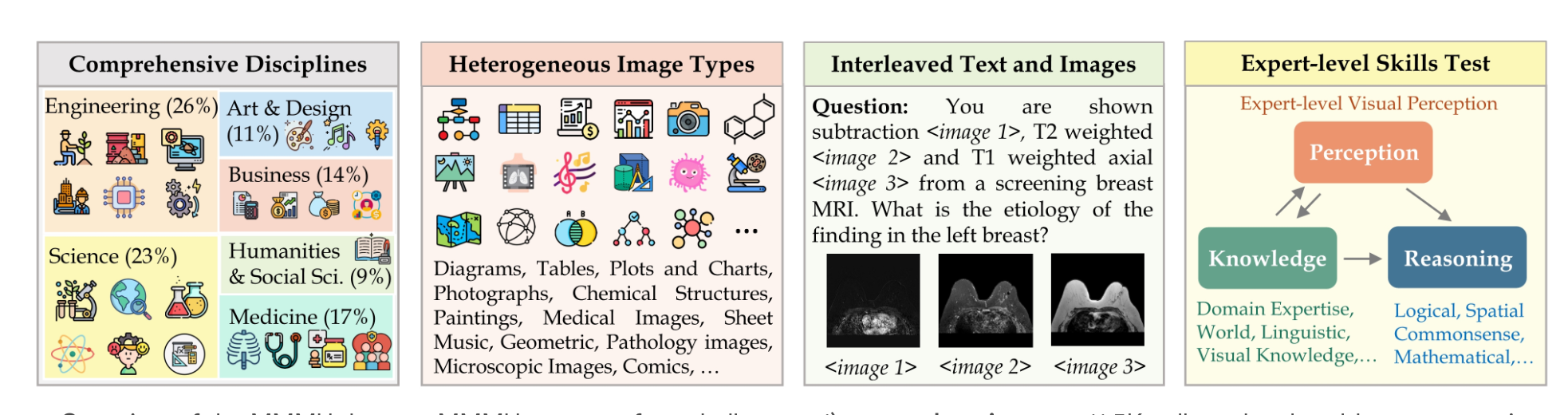
Multilingual Benchmarks
MGSM - Multilingual Benchmark
paper | dataset
The Multilingual Grade School Math Benchmark (MGSM) is a collection of 250 grade-school math problems from the GSM8K dataset, translated into 10 languages by human annotators. GSM8K consists of 8.5K high-quality, linguistically diverse math word problems designed to evaluate models' ability to answer basic mathematical questions that involve multi-step reasoning.
Limitations of LLM Benchmarks
There are two major limitations of current LLM benchmarks:
- Restricted scope
Many benchmarks have restricted scope, usually targeting capabilities on which LLMs have already proven some proficiency. Because they focus on areas where language models are known to be good, they're not great at finding new or unexpected skills that may emerge as language models get more advanced.
- Short life span
Also, benchmarks for language modeling often don't last long in terms of usefulness. Once language models reach a level of performance that's as good as humans on these benchmarks, the benchmarks are typically either stopped and swapped out or updated by adding harder challenges.
This short lifespan is likely because these benchmarks don't cover tasks that are much harder than what current language models can do.
It’s clear that as models continue to improve, they will achieve increasingly similar and higher scores on current benchmarks. So, we'll need to test models on future capabilities that are not possible now - with benchmarks like BBHard.
Testing Future Potential
BigBench - Predicting future potential
paper | dataset [released 2023]
BIG-bench is created to test the present and near-future capabilities and limitations of language models, and to understand how those capabilities and limitations are likely to change as models are improved.
This evaluation currently consists of 204 tasks that are believed to be beyond the capabilities of current language models. These tasks were contributed by 450 authors across 132 institutions, and the topics topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond.
In summary, at the time of writing this blog post (March 2024), the TL;DR of this leaderboard indicates:
Claude 3 Opus has the best average score across all benchmarks, and Gemini 1.5 Pro is right after (although this model isn't yet released); GPT-4 is starting to fall behind Gemini and Claude models (I guess we're waiting for GPT-5); Claude 3 Sonnet and Haik u are showing better results than GPT-3.5 (they're in the same category of cheaper and faster models); Mixtral 8x7B is the open-source model that has best average scores across all benchmarks for open source models;
Want to evaluate your AI apps?
This data is useful when choosing a model for a general task, but if you’d like to evaluate with your own benchmark data, then we can help!
Vellum has the tooling to support the entire lifecycle management of prompts from prototyping to production. The Evaluation feature can help with testing prompts in the prototyping phase, and then evaluating with the deployed prompt, and checking for any regressions.
If you’re interested to setup your own Evaluation suite, let us know at support@vellum.ai or book a call on this link.