Quick overview
LangChain is a popular framework for developers building AI applications. This guide compares the best LangChain alternatives for building, deploying, and managing AI agents and workflows, including open-source frameworks, cloud-native platforms, low-code builders, and the newer open-source personal AI assistant category where the runtime and memory are already wired in.
Top LangChain alternatives shortlist
Open-source personal AI assistant: Vellum (one assistant with persistent memory, seven native surfaces, skills in Python or TypeScript). Cloud-native: Vertex AI Agent Builder, Azure Copilot Studio, AWS Bedrock AgentCore. Open-source frameworks: Haystack, LlamaIndex, Flowise, Superagent, CrewAI. Workflow automation: n8n, Zapier, Gumloop. Vendor-managed: Lindy AI, Stack AI, Dust, Relevance AI.
What is an AI agent framework?
An AI agent framework is software that helps teams, especially developers build, orchestrate, and deploy autonomous or semi-autonomous agents. It provides workflow automation, memory, tool integrations, and runtime controls to run reliable multi-step processes.
Why use AI agent frameworks?
AI agent frameworks quickly turn scattered prototypes into production systems. Here are the benefits you can expect from using an AI agent framework:
Accelerate time-to-market Ship reliable, observable production workflows Enable multi-agent collaboration and orchestration Gain enterprise governance, versioning, and audit-ability
Who needs AI agent frameworks?
Any developer team moving from AI idea to AI agents with deep business impact benefits. Ideally your AI agent framework can support more teams in your org, rather than just catering to developers. Teams like FP&A, Product, Data Science, etc. should be able to collaborate with developers to make AI agents.
What makes an ideal AI agent framework?
The best frameworks are modular and observable, with governance you can take to audit and deployment options that fit your stack.
An AI agent platform often offers a richer agent building experience with SDKs and visual builder, so both technical and non-technical teams can ship quickly without producing more overhead for engineers.
Here’s what to look for in an ideal AI agent framework/platform:
Cross-team collaboration: Shared workspaces and role-based access that enable teams to co-build, review, and deploy agents without silos. Developer Necessities: Unified SDKs, custom code features, and strong documentation Observability: Logs, traces, and evaluation tools Governance: RBAC, audit logs, and compliance features Flexible Deployment: Cloud, VPC, or on-prem Integrations: Connectors for tools and APIs
Key trends shaping 2026
Multi-agent orchestration: Enterprises are scaling from single-agent pilots to dozens of coordinated agent systems, with initiatives like Salesforce and Google’s Agent-to-Agent (A2A) standard showing the push toward collaboration at scale [1] . Enterprise governance: Regulatory pressure is forcing enterprises to emphasize RBAC, audit trails, and compliance logging as core features of AI platforms [2] . Visual/low-code: Low and no-code platforms remain a top enterprise investment category for 2025, helping accelerate AI prototyping and delivery across teams [3] . Open-source dominance: OSS underpins most production workloads, with surveys showing 90%+ of enterprises depend on open-source software in production [4] . Vendor-managed runtimes: Vendor-managed AI platforms are gaining traction in regulated industries where compliance burden is highest, even if adoption multiples vary by sector [5] .
Why use LangChain alternatives?
Choosing the right LangChain alternative is about finding a platform that better fits your team’s compliance, deployment, and integration needs. Here’s the top reasons to choose an alternative:
Faster building for developers, and un-gating agent building for non-technical teams Built-in observability and evaluation for safe rollouts Broader ecosystem integration (M365, AWS, GCP) Enhanced security and governance protocols(RBAC, audit logs) Flexible deployment (SaaS, VPC, on-prem)
Who Needs LangChain Alternatives?
Teams focused on collaborative AI building across technical and non-technical roles Organizations aiming to become AI-native Enterprises with strict data residency and compliance Teams deploying agents across multiple clouds or regions IT leaders requiring strong monitoring and versioning Developers seeking model/tool neutrality Regulated industries (finance, healthcare) needing auditability
How to Evaluate LangChain Alternatives
Use these criteria to select the right LangChain alternative for your organization:
Criterion Description Why It Matters Cross-Team Collaboration Shared workspaces, role-based access, review/approval flows, and visual builders for non-devs Aligns product, data, and business to co-build, and ship agents faster with fewer handoffs Modularity Swappable, composable components for models, tools, memory, and routing Enables customization and scaling without rewrites Observability Tracing, logs, metrics, eval harnesses, and regression alerts Shortens MTTR; builds trust in outputs Governance RBAC, audit logs, change history, approvals, HITL Mandatory for enterprise and regulated use Deployment Options Cloud, VPC, or on-prem; secrets and data residency controls Fits diverse IT and compliance requirements Integration Connectors/SDKs for internal tools, RAG, and external APIs Reduces glue code and maintenance Developer Experience Unified SDKs, clear docs, visual builder, CI hooks Speeds onboarding and iteration Performance Latency, throughput, horizontal scaling patterns Impacts UX and cost Cost Pricing model and total cost of ownership (infra + people) Determines long-term feasibility
How We Chose the Best LangChain Alternatives
We evaluated platforms on:
Ease and depth of building Collaboration enablement Enterprise deployment and security features Observability and evaluation capabilities Breadth of ecosystem integrations Scalability and operational maturity Balance of open-source flexibility and managed support
Expected trade-offs:
Managed vs self-hosted: ease vs control Open-source vs proprietary: flexibility vs SLAs Depth of integration vs neutrality: ecosystem fit vs portability Feature richness vs simplicity: capability vs complexity
Top 15 LangChain Alternatives in 2026
1. Vellum, open-source personal AI assistant framework
Quick overview
Vellum is an open-source personal AI assistant that runs as a native Mac app on your machine or in Vellum Cloud, with iOS, web app, voice, email, Telegram, and Slack surfaces that share one memory. For developers, Vellum is an agent framework where the runtime, memory, and surface fan-out are already wired, you extend it with skills written in Python or TypeScript and ship a working assistant the same day. Most LangChain alternatives still hand you primitives. Vellum hands you a working operator-level agent. Vellum never has access to your data on any deployment path.
Best for: Developers building one operator-level assistant rather than a multi-agent production stack.
Pros
Open source with on-device option Working assistant on day one Persistent memory shared across seven native surfaces Skill system in Python or TypeScript
Cons
- Brief learning curve as your assistant builds context on you.
Pricing
Free Base plan. Pro from $50/mo with pay-as-you-go credits, configurable compute and storage, and your assistant's own email and subdomain.
2. Vertex AI Agent Builder (Google Cloud), Cloud-Native Agent Platform
Quick overview: Vertex AI Agent Builder is part of Google Cloud’s AI stack, offering scalable deployment with native GCP integrations. Strong fit for enterprises standardizing on Google infrastructure.
Best for: Organizations using Google Cloud for AI agent deployment
Pros:
Deep integration with Google Cloud services Managed infrastructure and scalability Access to Vertex AI models and tools
Cons:
Limited deployment flexibility (cloud-only). Less control over observability than dedicated agent platforms.
Pricing: Usage-based (compute, storage, API).
3. Microsoft Azure Copilot Studio, Agentic AI in the Microsoft Ecosystem
Quick overview: Microsoft Azure Copilot Studio is deeply tied into Microsoft 365 and Azure services, with enterprise security and compliance. Designed for organizations already embedded in the Microsoft ecosystem.
Best for: Enterprises leveraging Microsoft 365 and Azure
Pros:
Smooth integration with Microsoft 365 and Teams Enterprise security and compliance Visual builder for agent workflows
Cons:
Locked into Azure ecosystem Limited model/tool neutrality
Pricing: Enterprise licensing.
4. AWS Bedrock AgentCore, Scalable Agent Orchestration on AWS
Quick overview: AWS Bedrock AgentCore provides native agent orchestration on AWS with managed runtimes and access to multiple foundation models. It’s ideal for enterprises already standardized on AWS, though limited to cloud-only deployment with fewer built-in evaluation tools.
Best for: Teams building AI agents on AWS infrastructure
Pros:
Native AWS service integration Managed runtime and scaling Access to multiple foundation models
Cons:
Azure-only deployment. Fewer built-in evaluation tools than dedicated agent platforms.
Pricing: Usage-based; varies by model and compute
5. n8n, Open-Source Workflow Automation with Agent Extensions
Quick overview: n8n is an open-source automation platform that combines AI agents with traditional SaaS workflows. With a low-code visual builder and hundreds of integrations, it’s a versatile option for both developers and operations teams. It can run self-hosted or in the cloud, though advanced AI features often require scripting.
Best for: Developers wanting open-source workflow automation with AI
Pros:
Open-source and self-hostable Large library of integrations Flexible workflow builder
Cons:
Lacks enterprise-grade observability Manual scaling and governance setup
Pricing: Free (OSS); Cloud from $20/month; Enterprise pricing available
6. Zapier, No-Code Automation with AI Capabilities
Quick overview: Zapier is a no-code automation leader that connects thousands of apps, now with AI integrations. It’s designed for business users to quickly set up workflows without technical expertise. While great for simple automations, it lacks deep agent orchestration capabilities.
Best for: Business users automating workflows with minimal coding
Pros:
Huge app ecosystem Easy-to-use, no-code interface Quick setup for simple automations
Cons:
Limited agent orchestration depth Lacks advanced evaluation and governance
Pricing: Free tier; paid plans from $19.99/month; Enterprise pricing available
7. Lindy AI, Personal AI Assistant Platform
Quick overview: Lindy AI is a lightweight platform to spin up conversational or workflow agents fast. Comes with templates and SaaS integrations, making it accessible for non-technical teams.
Best for: Individuals and teams building personal AI assistants
Pros:
Prebuilt agent templates Integrates with calendar, email, and more Simple onboarding
Cons:
Limited enterprise controls Fewer deployment options
Pricing: Starts at $25/month; Enterprise pricing available
8. Gumloop, Visual Agent Builder for Prototyping and Deployment
Quick overview: Gumloop is focused on rapid prototyping and sharing custom AI agents. Ideal for experimentation, proof-of-concepts, and testing agent ideas quickly.
Best For : Rapid prototyping and deploying custom AI agents.
Pros:
Visual builder for fast prototyping RAG support out of the box Collaboration features
Cons:
Limited enterprise deployment options Fewer governance features
Pricing : Free tier, paid plans from $37/month; Enterprise pricing available
9. Stack AI, SDK for Custom AI Agent Development
Quick overview: Stack AI provides a visual interface to connect databases, APIs, and workflows. Tailored for building internal AI-powered tools that support business operations.
Best for: Developers needing a flexible SDK for custom agent logic
Pros :
Visual workflow editor Connects to databases and APIs Simple deployment options
Cons :
Limited observability and evaluation features Fewer governance controls
Pricing : Free tier; Enterprise plan
10. Flowise AI, OSS Visual LLM Orchestration
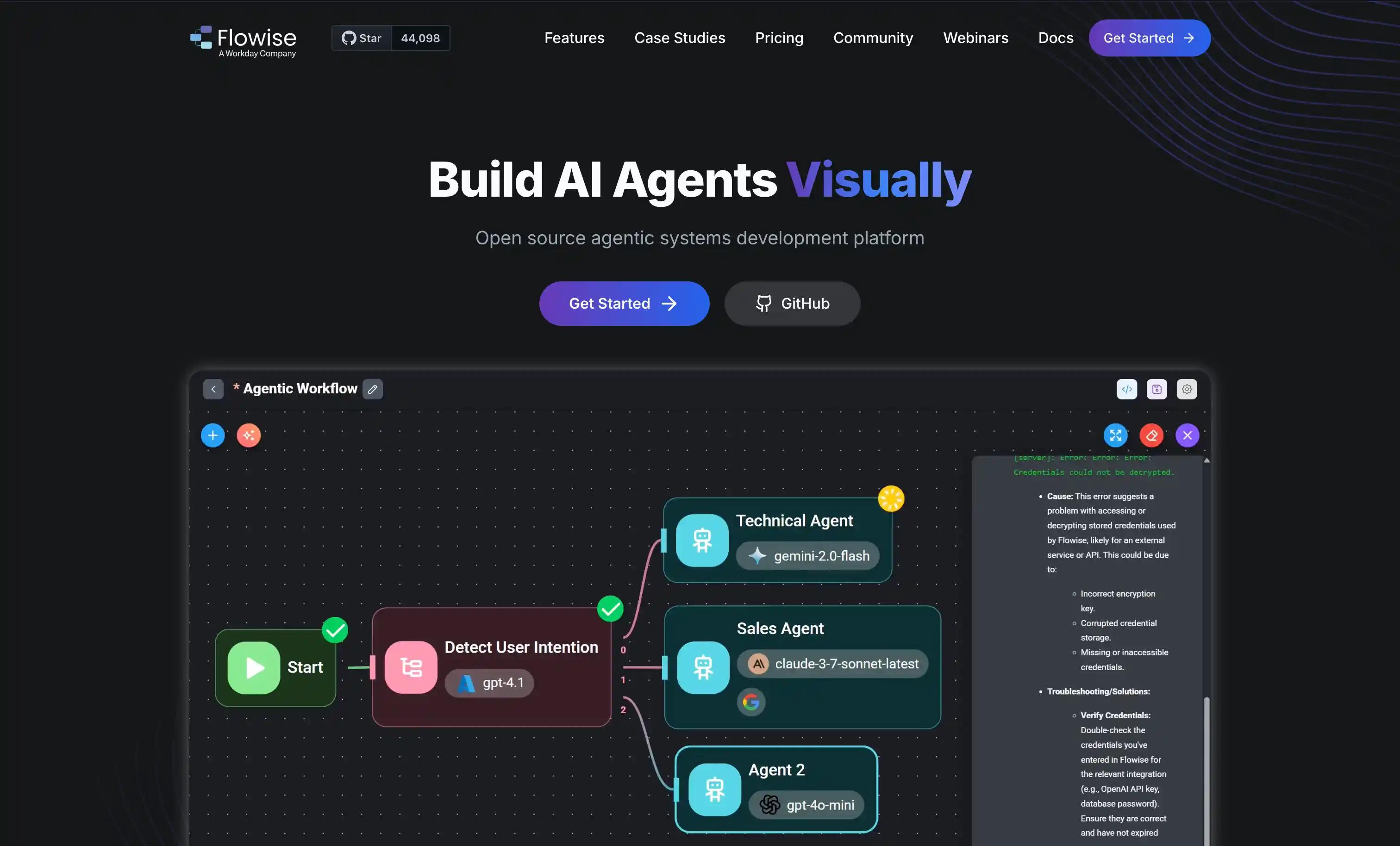
Quick Overview: Flowise AI is an open-source, drag-and-drop LLM orchestration tool best for rapid prototyping and OSS control.
Best for: Teams wanting open-source, visual LLM orchestration
Pros:
Open-source, self-hostable Visual workflow builder Active community
Cons:
Fewer enterprise controls Manual scaling and monitoring
Pricing: Free (OSS); paid plans from $35/month; Enterprise pricing available
11. Superagent, OSS Agent Framework for Developers
Quick overview: Superagent is a developer-first, open-source agent framework with plugin support. Ideal for engineering-heavy teams wanting maximum customization.
Best For : Developers building custom agent solutions.
Pros:
Modular agent framework Community plugins Flexible deployment
Cons:
Lacks built-in governance Limited observability
Pricing: Free (OSS)
12. CrewAI, Visual Builder for Multi-Agent Orchestration

Quick overview: CrewAI specializes in designing teams of role-based agents through a visual workflow interface. It helps teams prototype and deploy collaborative agent flows quickly, without heavy coding. While easy to use, advanced observability and governance features are limited.
Best for: Designing collaborative agent teams with roles
Pros:
Visual workflow builder Role-based agent collaboration Quick prototyping
Cons:
Limited advanced observability Freemium model restricts some features
Pricing: Enterprise only.
13. Dust, AI Workflow Builder for Enterprises
Quick overview: Dust is an enterprise AI platform for building custom, contextual agents that connect to your company’s data and tools in a shared workspace, with a model-agnostic approach and security/compliance features.
Best for: Security-conscious enterprises to roll out data-connected, agents without heavy engineering.
Pros:
Visual workflow builder Integrations with enterprise data sources Managed hosting
Cons:
Limited open-source options Fewer observability features
Pricing: $29/month; Enterprise pricing available
14. Relevance AI, Multi-Agent Orchestration with Analytics
Quick overview: Relevance AI helps teams build and manage multi-agent workflows with built-in RAG, analytics, and dashboards for visibility.
Best for: Teams that want low-code agent workflows powered by data and real-time analytics.
Pros:
Built-in analytics and tracing RAG and agent orchestration Cloud deployment
Cons:
Limited deployment flexibility Fewer governance controls
Pricing: Free tier; paid plans starting at $19/month; Enterprise pricing available
15. OpenPipe, OSS Agent Orchestration for LLMs

Quick overview: OpenPipe is an open-source platform for fine-tuning and optimizing LLM prompts and agents, with tools for regression testing, evaluation, and versioning. It’s best for developers who want full control over agent orchestration and improvement in a self-hosted setup.
Best for: Developers seeking open-source agent orchestration
Pros:
Open-source Flexible agent building Community support
Cons:
No managed hosting Lacks enterprise-grade features
Pricing: Free (OSS); Enterprise pricing available
LangChain Alternatives Comparison Table
| Tool Name | Starting Price | Key Features | Best Use Case | Rating |
|---|---|---|---|---|
| Vertex AI Agent Builder | GCP usage-based | Managed runtime; memory bank; sessions; Google ecosystem | GCP-standardized agent dev | 4.4 |
| Azure Copilot Studio | Enterprise licensing | M365 integration; Entra ID; governance | Microsoft-standardized orgs | 4.3 |
| AWS Bedrock AgentCore | AWS usage-based | Serverless patterns; deep AWS integration | AWS-native scale workloads | 4.3 |
| n8n | Free OSS; paid cloud | Self-host; 400+ apps; LLM nodes | Open-source workflow automation | 4.4 |
| Zapier | Free; paid tiers | 7,000+ apps; AI actions | Connecting SaaS apps | 4.5 |
| Lindy AI | Free; paid plans | No-code AI agents; tool use | Personal AI agents | 4.2 |
| Gumloop | Free; paid plans | Visual node builder; LLM nodes | Visual agent prototyping | 4.2 |
| Stack AI | Enterprise | LLM nodes; RAG; evals; SDK | Enterprise-strict agent dev | 4.3 |
| Flowise AI | Free OSS; paid cloud | LangChain-based visual builder | OSS visual LLM orchestration | 4.2 |
| Superagent | Free OSS | Agent framework for devs | OSS agent dev | 4.0 |
| CrewAI | Free OSS; enterprise | Multi-agent orchestration | Team-of-agents setups | 4.3 |
| Dust | Paid plans | Compliance-oriented assistants | Compliance-heavy teams | 4.2 |
| Relevance AI | Paid plans | Multi-agent orchestration with analytics | Analytics-driven agent flows | 4.2 |
| OpenPipe | Free OSS | Agent orchestration for LLMs | OSS LLM orchestration | 4.1 |
FAQs
1) What is the main limitation of LangChain for enterprise teams?
LangChain is strong for developer prototyping but light on built-in governance, observability, and deployment flexibility. Look for alternatives that ship these out of the box so teams can move from pilot to production faster.
2) Do LangChain alternatives make collaboration easier?
Yes. Platforms with shared workspaces, RBAC, audit trails, and approval flows let PMs and SMEs co-build with engineers. Cloud-native picks (Vertex AI, Azure Copilot Studio) and managed platforms (Stack AI, Dust) all market this explicitly.
3) How do LangChain alternatives reduce engineering overhead?
Pick a tool that bundles testing, versioning, tracing, and rollback in one place. Managed platforms (Stack AI, Vertex AI) centralize these controls so engineers spend less time on scaffolding.
4) Why does deployment flexibility matter when choosing an alternative?
Some industries require strict data residency or on-prem hosting. Platforms that offer SaaS, VPC, and on-prem deployment prevent compliance issues down the line.
5) Can non-technical teams build agents without coding?
Yes, low-code builders help, but quality hinges on guardrails. Look for tools that pair a visual builder with eval gates and approval steps so non-technical teams can ship safely; Stack AI, Gumloop, and Lindy AI lean into this.
6) How do LangChain alternatives handle security and compliance?
Look for RBAC, audit logs, environment isolation, and approvals as core primitives, not plugins, especially for heavily regulated and compliance reliant industries.
7) Are open-source options better than managed platforms?
Open-source tools offer flexibility and control, but managed platforms often save time with built-in monitoring, governance, and enterprise support.
8) How do evaluation tools in alternatives improve reliability?
Built-in evals allow teams to test agents before rollout, compare changes over time, and prevent regressions from reaching production.
9) What role does observability play in scaling agents?
Logs, traces, and cost tracking help teams quickly debug issues and manage performance, which becomes critical as usage grows.
10) When should you pick a managed platform over an OSS framework?
Choose a managed platform when you need developer-grade SDK control plus cross-team collaboration, with evaluations, observability, governance, and deploy-anywhere options built in. Pick OSS when you have engineering time and want maximum customization.
Extra Resources
How the Best Product and Engineering Teams Ship AI Solutions →
The 2026 Guide to AI Agent Workflows →
The Ultimate LLM Agent Build Guide →
Understanding your agent’s behavior in production →
The Best AI Agent Frameworks For Developers →
Citations
[1] Google Cloud. (2025). Agent2Agent protocol is getting an upgrade .
[2] KPMG. (2025). Ten Key Regulatory Challenges: 2025 Mid-Year .
[3] Forrester. (2025). The State Of Low-Code, Global 2025 .
[4] OpenLogic. (2025). 2025 State of Open Source Report .
[5] Productive/edge. (2025). Gartner’s Top 10 Tech Trends Of 2025: Agentic AI and Beyond .






