We’ve learnt a ton about best practices for LLM development since we first launched close to a year ago. We’ve spoken to over 1,500 people at varying maturities of using LLMs in production and want to distill some of our learnings in this post for you.
It’s easy to whip together a prototype of an AI-powered feature using popular open source frameworks, but we repeatedly see people having difficulty crossing the prototype-to-production chasm. They deploy to production and then quickly run into countless edge cases and wonder why their AI application isn’t working well.
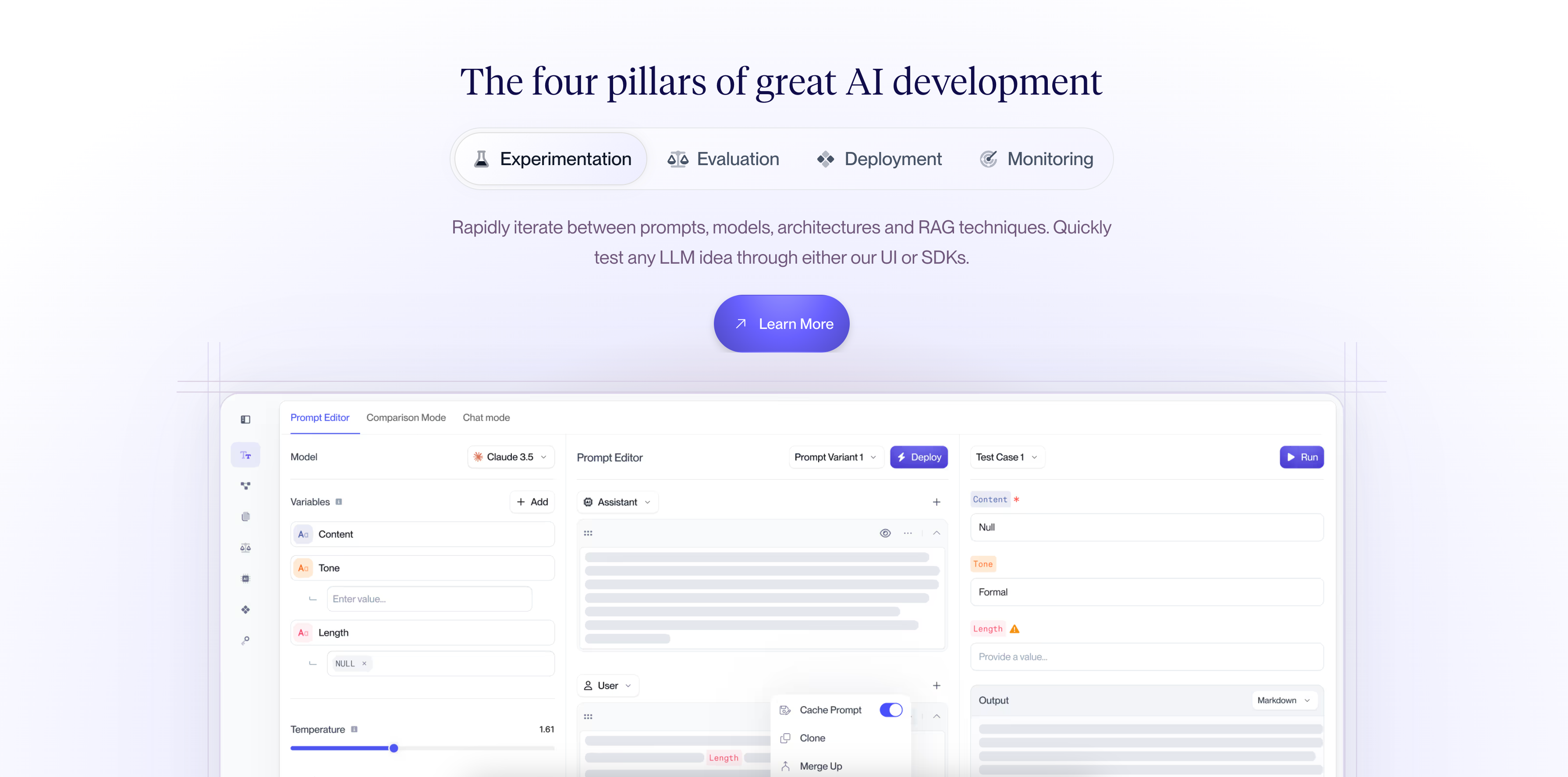
A common pattern among successful companies has emerged – they’ve invested in 4 key areas to help with their AI development process.
Data
LLMs are trained on the general internet and don’t have access to your proprietary data.
LLMs are also inherently stateless.
They’re only as good as the context you provide to them at run-time. Companies who try to use AI to create personalized experiences without providing the AI with personalized data struggle.
Those that invest in providing data unique to their company, their industry, or their customers fare much better.
Here are some questions to keep in mind while thinking about the data you pass into your LLM:
What data is unique to you, your company, industry, or customers? How can you best structure and query for this data at runtime, such that it can be included in a prompt that’s sent to an LLM? What is the best prompt/model to wrap that data resulting in a meaningful output?
Retrieval Augmented Generation via embedding models and vector DBs are a common architecture best suited for unstructured text. If you’ve built a RAG system before, you already know the challenges:
Which Vector DB should I use? OpenAI just released a new embedding model – is it better for my task? Now I need to make a document ingest pipeline? What are my reranking options?
Keep in mind though that you likely already have a bunch of great structured data and can lean on good ol’ SQL queries as a starting point.
Experimentation
Unlike traditional software engineering, LLMs are non-deterministic, unpredictable, and getting them right requires a lot of trial and error.
While trying to pick the right approach for a task, we see people optimizing between quality, cost, latency and privacy requirements.
Here’s how we see customers thinking about experimentation:
First, what’s the right architecture for my application? Single prompt + single completion, chat or a multi-step chain with custom business logic tying the prompts together. RAG? OpenAI or Anthropic or Mistral? One big prompt for GPT-4 or multiple specialized GPT 3.5 prompts? Questions regarding experimentation are best answered when you have a clear evaluation process and metrics. The eval process depends on the task at hand and whether you have access to “ground truth” data or “expected outputs”. Exact match or Regex match could be good for classification tasks, Semantic similarity is good for Q&A or generative responses. LLM and code-based eval based metrics (e.g., is this valid JSON schema?) may not require ground truth and could be useful additional metrics to add in your testing process. Next, think about how many test cases you want to test against? High bar for accuracy and low risk tolerance in case something goes wrong? Make sure to have a large number of test cases in your test bank. Finally, think about who will do the testing and experimentation? Does it have to be your engineering team? Often non technical people who are closer to customers may be a better fit to modify prompts until they clear test cases. Find a way to get this experimentation out of your code to make the whole team move faster.
Experimentation is potentially the most important pillar while building your AI application. Effective experimentation and a good testing framework gives you the confidence needed to bring your AI prototype to production.
Those companies that don’t invest in experimentation frameworks waste time, get frustrated, and ultimately land on less-than-ideal solutions.
Lifecycle Management
After wrangling your data, feeding it into a prompt, and performing your experimentation, you’re ready to ship your AI application to production – congratulations!
However, you’ll inevitably need to make changes…
Software engineering as a profession has existed for decades and with it, a whole industry of tooling for lifecycle management has matured. We have Github for version control, Datadog for monitoring, CircleCI for CI/CD, the list goes on... But the age of robust AI tooling is only just beginning.
Regardless of whether you buy a solution or build your own, safely making changes once in production is critical.
Here are the common actions performed by the most successful companies we work with:
Log all the calls you make to the LLM provider: inputs, outputs, exact provider payload, latency. If your application uses chained prompts, track the inputs, outputs and latency at each step for full traceability. If you’re a chart junkie like us, throw this raw data in a visualization tool for better observability: number of tokens over time, latency over time, errors over time etc. Use your creativity and make charts to track whatever trends are most important to you. Set up alerts. If latency exceeds a set limit, your system should alert you rather than the user. If possible, capture implicit or explicit user feedback for each completion. Explicit user feedback is collected when your users respond with something like a 👍 or 👎 in your UI when interacting with the LLM output. Implicit feedback is based on how users react to the output generated by the LLM. For example, if you generate a first draft of en email for a user and they send it without making edits, that’s likely a good response! Measuring quality over time becomes a lot easier if you keep track of user feedback.
While making changes to your AI application (either single prompt or multi-prompt):
Maintain good version control and version history. Pin to stable versions in production and use staging environments for testing where possible. Maintain the ability to quickly revert back to an old version. Replay historical requests with your new prompt / prompt chain and make sure nothing breaks. Regression testing is vital to give you peace of mind that your AI application won’t degrade.
If software never had to change, things would be easy!
That’s rarely the case.
Good tooling for Lifecycle Management is necessary as you iterate, evolve, and make changes. Get the basics right and you’ll sleep more easily.
Continuous Improvement
You’ve instrumented monitoring, logging and are maybe even capturing user feedback. This data is incredibly valuable because you can create a feedback loop back to Pillar 1 – Data and continuously improve the quality of your application over time.
Embed the right feedback loops and your competitive data moat deepens automatically.
Any time you find an edge case where the model didn’t perform well, add it to your bank of test cases. Make sure your application clears that edge case next time you make a change to your AI application. If you apply advanced techniques like dynamic few shot prompting via RAG, good completions can be added to your vector DB to provide better context to the model next time the model sees a similar request. Build a caching layer if you’d like to save cost or lower latency. Each time your AI application sees an input similar to what it has seen before you can get the response from cache instead of calling the LLM again. Once you have a large enough bank of good quality completions, use that data to fine tune a custom model (either OpenAI or open source) to further reduce cost and latency and increase accuracy.
Summary
Data, Experimentation, Lifecycle Management, and Continuous Improvement – these are the four pillars of building a production-grade AI application.
Invest in them and you’ll be amazed at how quickly you can cross the prototype to production chasm.
Need help getting started?
All this may sound daunting, but luckily, you don’t have to build it all yourself.
Vellum is a production-grade AI development platform that gives you the tools and best practices needed across all four pillars without needing to build complex internal tooling.
Reach out to me at akash@vellum.ai or book a demo if you’d like to learn more.