LLMs have opened up a whole new class of software applications .
However, evaluating the quality of their outputs at scale is hard.
Despite the great versatility demonstrated in side projects / hackathons, we’ve seen companies struggle to put LLMs in production.
One of the common reasons is that there’s no framework to evaluate quality of these models. LLMs are inherently probabilistic in nature — the same input can have different outputs depending on the probabilities assigned by the model when using a temperature of > 0, and seemingly small changes can result in vastly different outputs.
Having built applications on LLMs for more than 5 years now , we know how important measuring output quality is for creating a great user experience. There needs to be sufficient unit testing before going into production and regression testing to make changes once in production.
In this post we’ll share our learnings on the best ways to measure LLM quality both before and after deploying to production. In order to measure quality, you have to carefully consider your use case to decide which evaluating metrics are relevant.
What are LLM evaluation metrics?
LLM evaluation metrics help you see how well your prompt, model setup, or workflow is working based on the goals you’ve set.
We use evaluation metrics because LLMs can be unpredictable, and we need to know how well they’re performing for our specific use case before going live. Without proper evaluation, an LLM could behave unreliably in production—generating offensive content, confusing users, or sharing incorrect information.
Today, some of the most frequent evaluation metrics can measure things like context recall for RAG applications, *exact match for classification tasks, JSON validators for structured output extraction, semantic similarity for creative output and more.
Before we dive into specific use cases and the metrics to use, let’s first understand where in your workflow and at what stage you should evaluate your system.
Offline vs Online vs Inline Evaluation
In this section, we’ll explore how these evaluation strategies work and how to apply them for your LLM workflows.
Offline evaluation: Unit testing before production
With Offline evaluation, you create a unit test bank before deploying LLMs to production. This is a proactive approach to ensure your AI system performs reliably in production.
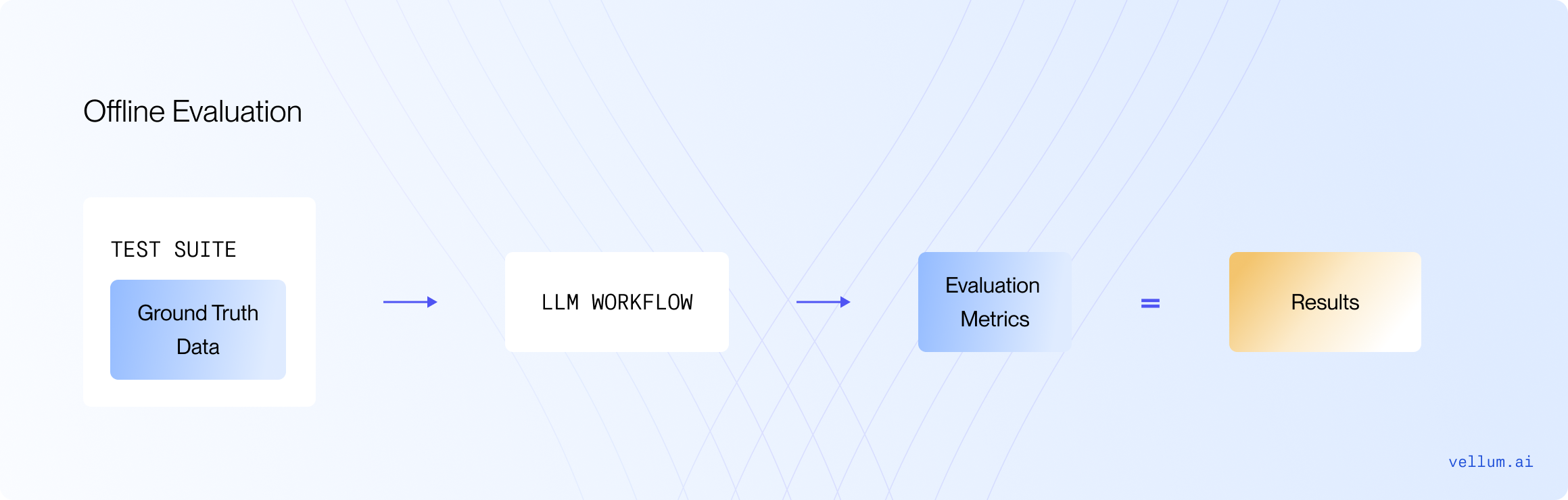
The test bank should comprise scenarios anticipated in production, think of this as QAing your feature before it goes to production. Each step of your AI system & the whole system end-to-end should "pass" these test cases based on your evaluation criteria.
Work backwards from a goal in mind and optimize your quality, cost and latency.
Inline evaluation / Guardrails: Ensure good system performance at run-time
For critical steps in your AI architecture, consider adding your metrics at run-time to measure quality and consider changing logic if the metric fails.
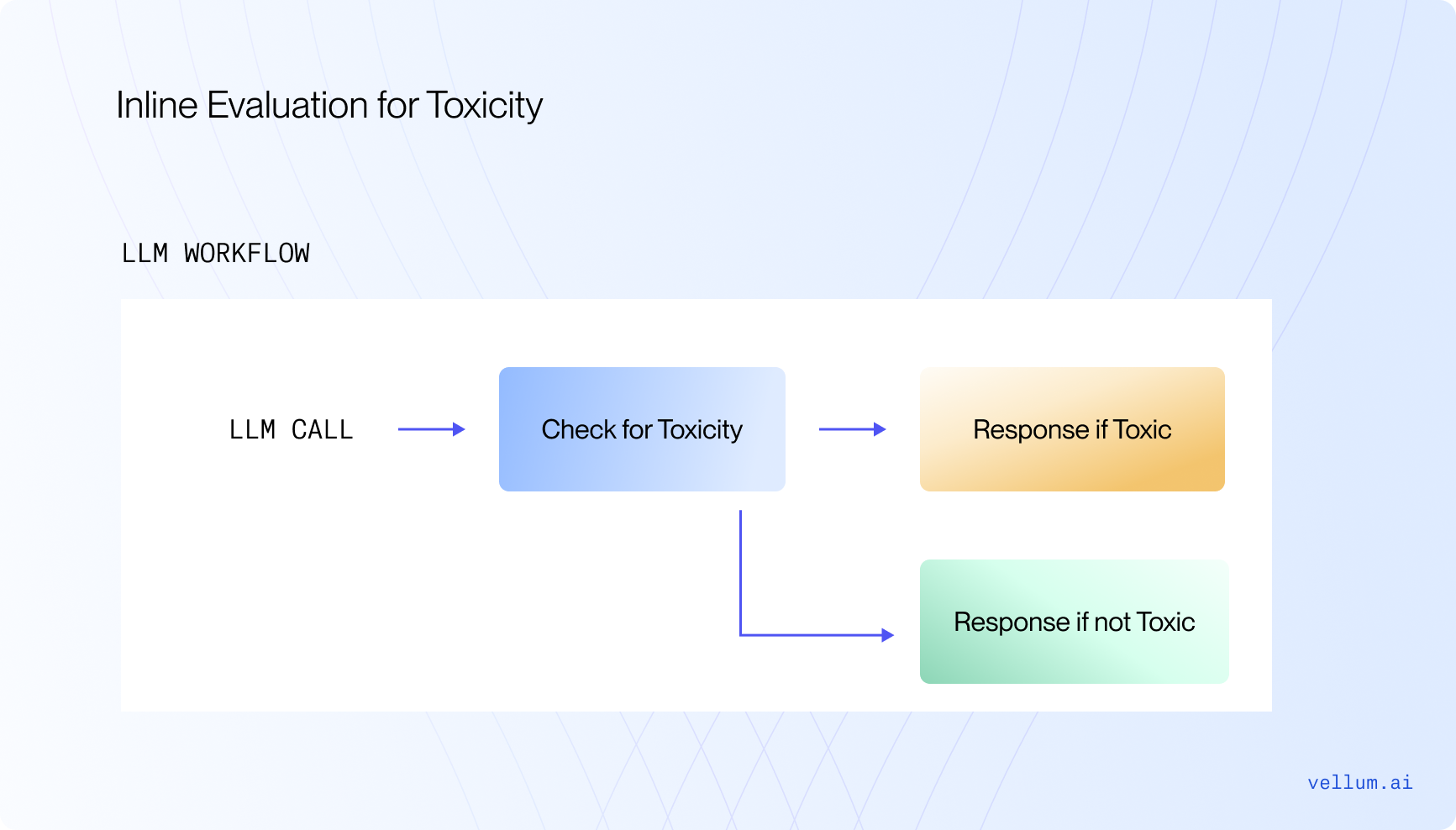
Say you’re building a consumer facing chatbot and have a toxicity evaluator, the goal being that the chatbot shouldn’t send any harmful messages.
Given the potential risk, running this evaluator at run-time before the final completion is made could be a good idea (remember to keep costs and latency low!). If the evaluator says that the response is toxic, a different response could be shown to the user instead of the original response. That’s the power of guardrails / in-line evaluation.
Online evaluation - measuring quality in production
Once your AI system is live, you could be making thousands of production requests per day.
But how do you know the system is performing as intended?
A successful approach we see here is taking a random sample of production requests and running them against the same evaluators built during offline evaluation. We call this approach Online Evaluation:
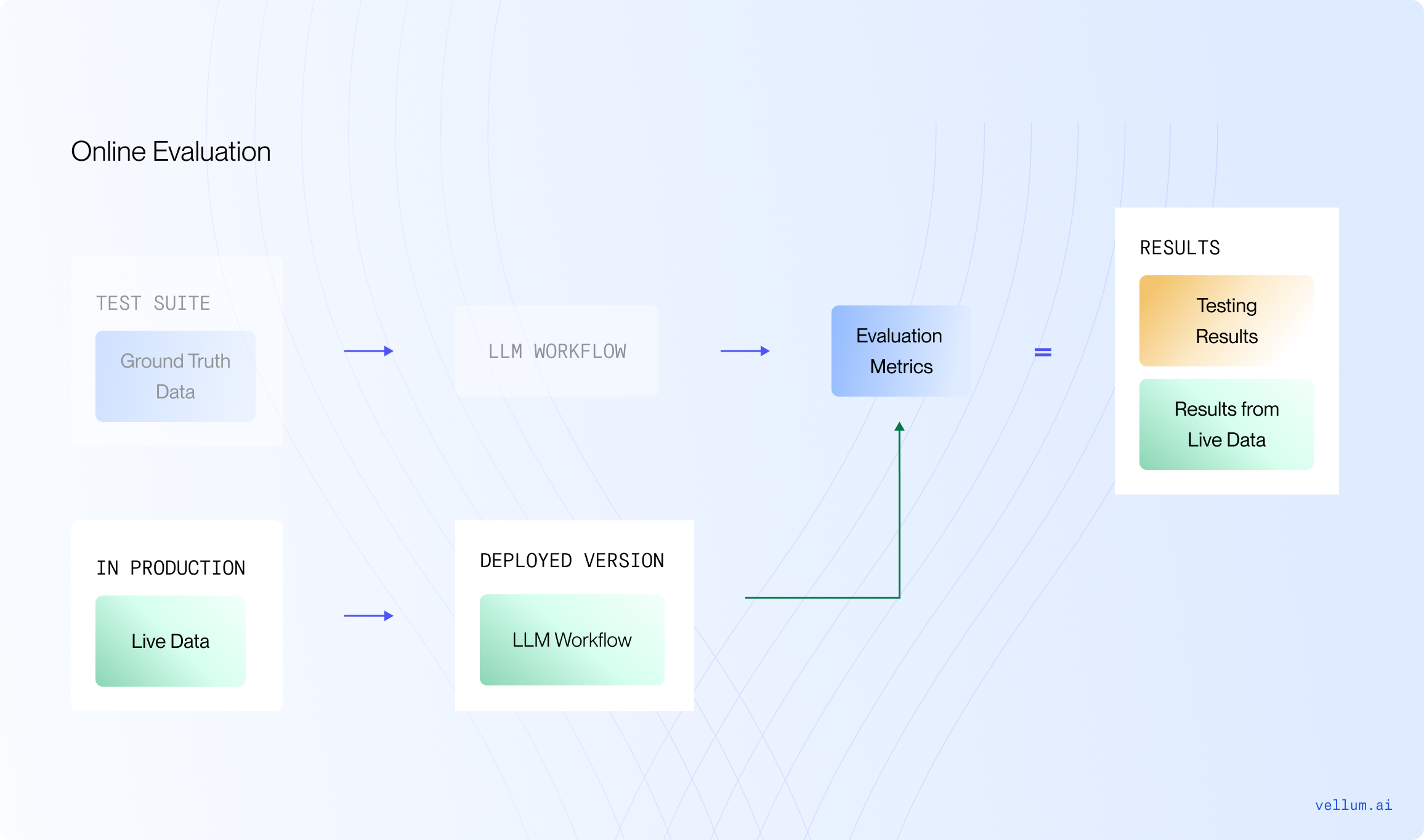
This helps you measure system performance over time and identify inputs that produce an undesirable result in production. Remember to add these edge cases to your test bank! Each time you edit your system you should be able to make changes with confidence.
With this evaluation, you can perform regression testing to validate updates to prompts once in production. In this case, make sure to run backtesting scripts when changing prompts in production, you don’t want to break any existing behavior! Back-testing is possible if you’re capturing the inputs/outputs of production requests. You can “replay” those inputs through your new prompt to see a before and after.
But how can you capture this data?
Capturing User Feedback as Test Cases
User feedback is the ultimate source of truth for model quality — if there’s a way for your users to either implicitly or explicitly tell you whether they the response is “good” or “bad,” that’s what you should track and improve! High quality input/output pairs captured in this way can also be used to fine tune models (you can read more about our thoughts on fine tuning here ).
Explicit user feedback is collected when your users respond with something like a 👍 or 👎 in your UI when interacting with the LLM output. Asking explicitly may not result in enough volume of feedback to measure overall quality. If your feedback collection rates are low, we suggest using implicit feedback if possible.
Implicit feedback is based on how users react to the output generated by the LLM. For example, if you generate a first draft of en email for a user and they send it without making edits, that’s likely a good response! If they hit regenerate, or re-write the whole thing, that’s probably not a good response. Implicit feedback collection may not be possible for all use cases, but it can be a powerful gauge of quality.
Now that we know how to evaluate your setup in pre or post production, let’s see what kinds of evaluation metrics you can use for various use-cases.
Recommended Metrics by Use-Case
In order to measure quality, the metrics you choose depend on the type of use case. There are various options:
Classification: Input text is classified into 2 or more categories. For example, a binary classifier might decide whether a user message should be escalated to a human for review or if the LLM can handle the response. Structured data extraction: Unstructured data from PDFs usually converted to JSON files, to minimize hours of manual data entry work. An example here is converting PDF invoices to JSON. SQL/Code generation: Natural language instructions given to an LLM to produce data that machines can run and usually has a correct answer. Text to SQL is the best example here. Generative/creative output: This is what LLMs are best known for, blog posts, sales emails, song lyrics — there’s no limit here!
Following the described use-cases, we will explore the relevant evaluation metrics to apply for each scenario.
Evaluation metrics for Classification
This is the easiest use-case to quantitatively measure quality because there’s usually a correct answer!
For classification use cases, it’s a good idea to create a bank of a few hundred test cases. Each test case would be something like: “Given this input, I expect this specific output.” These examples help you evaluate how well your model is performing.
When you’re analyzing the results, the key metrics to focus on are:
Accuracy : How often the model gets it right overall. Recall : Out of all the relevant instances, how many did the model actually catch? Precision : When the model says something is relevant, how often is it correct? F1 Score : A balance between precision and recall, showing how well the model is performing overall.
To dive deeper into the results, you may also want to see confusion matrices to understand where the model is making mistakes.
We compared four state of the art model to see which ones are best for text classification, and you can read the technical report here . Nowadays, models like OpenAI O1 and GPT-4o do great on classification tasks as well.
Evaluation metrics for RAG
Figuring out the best ways to measure success for your RAG systems is always evolving and still a big area of research. However, there are a few metrics that have proven to be valuable for AI apps in production — we wrote more about this here , but here’s a TLDR of the metrics:
Context Retrieval Evaluation
To evaluate which retrieval setup produces the best results, you can use the following evaluators:
Context relevance - How relevant is the context to the question? Context adherence - Are the generated answers based on the retrieved context and nothing else ? Context recall - Is the context accurate compared to the ground truth data to give an answer?
Content Generation Evaluation
Once you have a good semantic search process, you can start testing different prompts and models. Here are some frequent evaluation metrics:
Answer Relevancy : How relevant is the answer to the question at hand? For example, if you ask: “What are the ingredients in a peanut butter and jelly sandwich and how do you make it?" and the answer is "You need peanut butter for a peanut butter and jelly sandwich," this answer would have low relevancy. It only provides part of the needed ingredients and doesn't explain how to make the sandwich Faithfulness : How factually accurate is the answer given the context?You can mark an answer as faithful if all the claims that are made in the answer can be inferred from the given context. This can be evaluated on a (0,1) scale, where 1 is high faithfulness Correctness : How accurate is the answer against the ground truth data? Semantic similarity : How closely does the answer match the context in terms of meaning (semantics)?
Evaluation metrics for Structured Data Extraction
The output here is usually a machine readable format. JSON is a good choice here. There are various kinds of tests you can perform to measure quality while testing:
JSON Validator: Validate that the output is syntactically valid Keys Validator: Ensure expected keys are present in the generated response Value Validator: Flag which keys do/don’t have correct values/types
While most models today like GPT-4o and Gemini 1.5 support out-of-the-box features like JSON mode and Structured Outputs to enforce the model to output JSON — you can always reinforce the model to check your structured output.
Evaluation metrics for SQL/Code Generation
For this use-case, you usually want the LLM to generate some SQL/Code generation.
Validate that the output is syntactically valid SQL Validate that it can be executed successfully Confirm that the queries return the expected values for defined test cases
Evaluation metrics for Creative Output
The challenge with evaluating creative output is that there is no one correct answer.
When you have an example of a good output, semantic similarity can be used as a proxy for quality before productionizing your use case. “How similar in meaning is this response to the target response?” Cross-encoders are best suited to measure the similarity between the expected and actual output. If the temperature for these prompts is > 0, make sure to run each model/prompt/test case combination multiple times so you can see the variance in semantic similarity.
One approach we’re excited about and just in the early stages of testing is using one LLM to evaluate the quality of another. This is definitely experimental, but a good prompt can check for tone, accuracy, language etc.
LLM as a judge
Another approach is to use another LLM to evaluate the quality of another LLM output.
But are LLM models as good as human evaluators?
The latest research on this topic suggests that using LLMs like GPT-4 to evaluate outputs is a scalable and explainable way to approximate human preference. You can currently use our Workflow Evaluation Metric feature in Vellum to do just that.
Human in the Loop / Human Evaluation
Finally you should always evaluate your system by involving human-experts to review the answers — especially for more open ended outputs.
For example, OpenAI recently tested their O1 models with human experts and found that while the model excelled at complex reasoning tasks, it didn’t rank as highly for creative output generation.
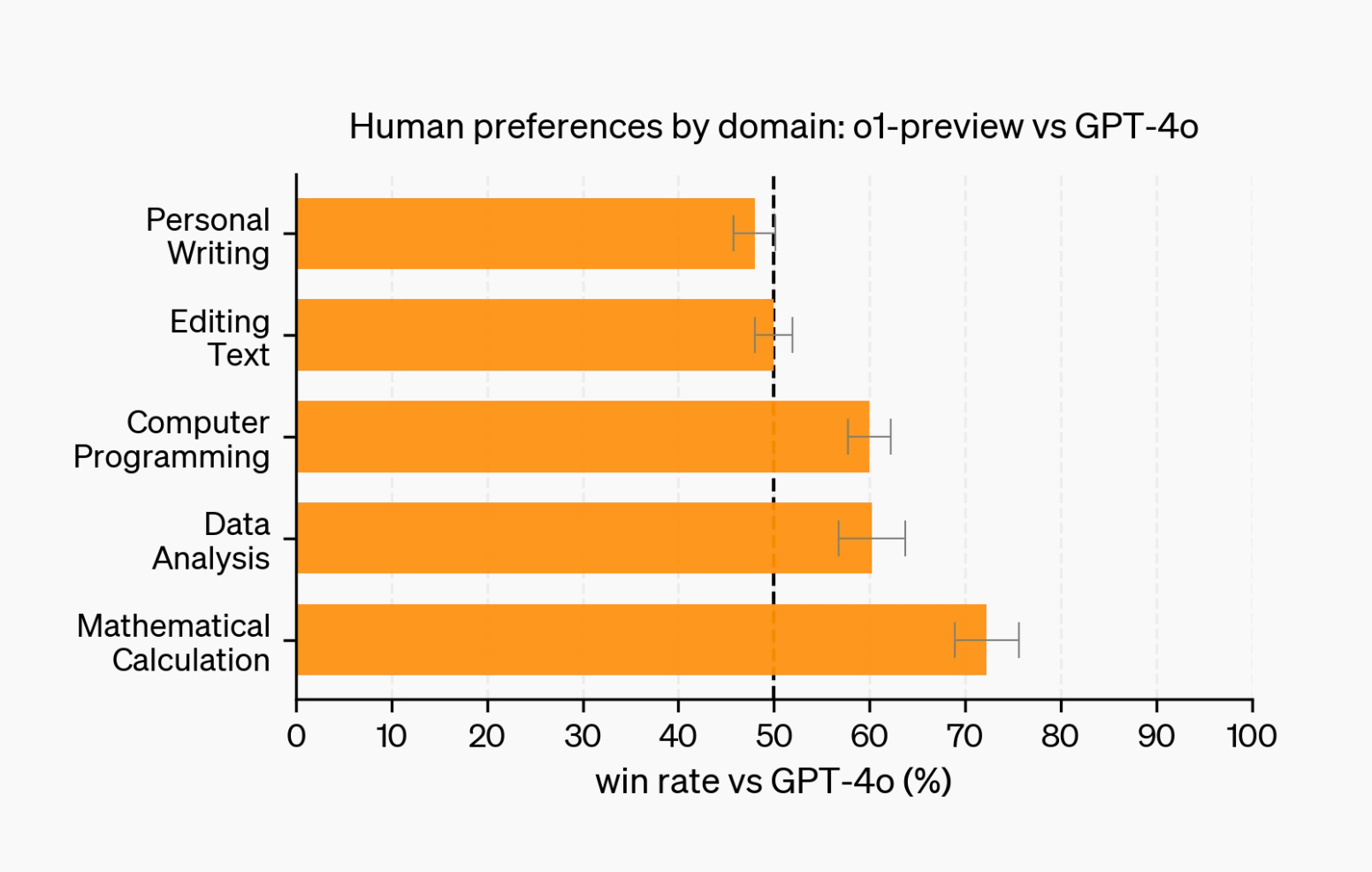
As agentic workflows become more complex, human evaluation in the loop will be even more important, since humans will still need to guide these workflows and prevent them from going off track.
Evaluation Frameworks
This might all sound very complex — but fortunately for you, there are plenty of evaluation frameworks available to help with this process. You don’t need to write complicated evaluation functions just to test your model’s performance — simply build your system and integrate it with one of these frameworks to ensure it runs reliably:
1/ Vellum helps engineering and product teams to easily measure your AI system at scale. It helps you spot regressions, errors or improvements — and you can add online, offline and/or inline evaluators when needed. (Plus you can build your workflows there too!)
2/ SupperAnnotate let’s you build your evaluation datasets and fine-tune your models with a customizable editor.
3/ LangSmith helps developers to get better visibility into their AI system — to spot errors and performance bottlenecks in real time.
Need Help With Testing and Evaluation?
Measuring LLM quality is challenging.
Unit testing with a large test bank, choosing the right evaluation metric, and regression testing when making changes to prompts in production are all worthwhile strategies. Unfortunately, the tooling and infra needed to do this at scale usually requires significant engineering resources dedicated to building internal tooling.
Vellum’s platform for building production LLM application aims to solve just that. We provide the tooling layer to experiment with prompts and models, evaluate their quality, and make changes with confidence once in production. If you’re interested, you talk with our AI experts here ! You can also subscribe to our blog and stay tuned for updates from us.