
Another exciting development in the AI wars just happened with Claude Opus 4.5 launching out of the blue today! Anthropic’s latest flagship model is making a serious bid for the top of the leaderboard, delivering massive jumps in coding, reasoning, and agentic robustness that push the boundaries of what next generation AI systems can do.
It is available now through the Claude API and supports Anthropic’s expanded tool use and agentic capabilities. What had been a steady, reliability-focused model line is now stepping directly into the race for state-of-the-art performance, surpassing competitors like GPT 5.1 and Gemini 3 Pro in several of the benchmarks that matter most.
Opus 4.5 is showing standout gains in software engineering, abstract reasoning, something no one else is talking about - safety. Let’s jump into this breakdown.
Key observations of reported benchmarks
While benchmarks have their limits and don't always reflect real-world performance, they are the best tool we have for measuring progress in AI. Based on Anthropic's system card for Claude Opus 4.5, we can draw several key conclusions:
Coding beast: Opus 4.5 is without doubt the best for software engineering tasks, and especially for planning. Vibe-coding tools have integrated with this model almost instantly. With a score of 80.9% on SWE-bench Verified, it surpasses both GPT-5.1 and Gemini 3 Pro, demonstrating a strong ability to resolve real-world software issues from GitHub repositories. High reasoning: The model shows a pretty interesting leap in abstract reasoning, scoring 37.6% on ARC-AGI-2, more than doubling the score of GPT 5.1 and beating Gemini 3 Pro by ~6%. Though very formidable performance, Opus 4.5 still gets beat out by Gemini 3 Pro on Humanity’s Last Exam by ~7% without search and ~2% with search enabled. Financial savant: While Opus 4.5's Vending-Bench 2performance resulted in a balance of $4,967.06, a 23% increase over Sonnet 4.5, but still falling short to Gemini 3 Pro’s net wroth of $5,478.16. Safer than the rest: Concerns around AI safety have been gaining prevalence in the space since bad actors and actors have slowly been penetrating the AI security measures. So on agentic safety evaluations, Anthropic emphasized Opus 4.5’s industry-leading robustness against prompt injection attacks and exhibiting ~10% less concerning behavior than GPT 5.1 and Gemini 3 Pro.
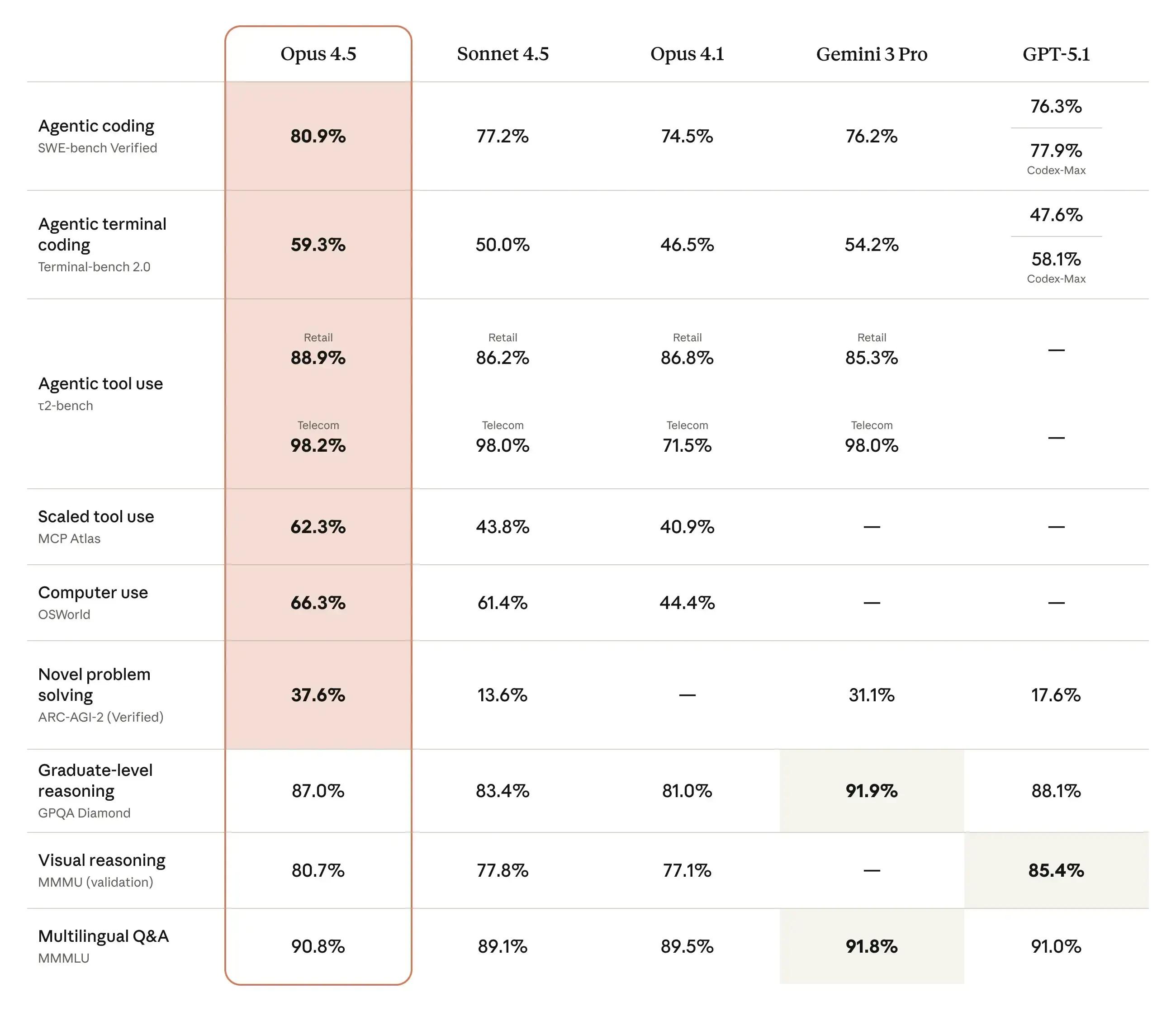
Coding capabilities
Coding benchmarks test a model’s ability to generate, understand, and fix code. They are crucial indicators of a model’s utility in software development workflows, from simple script generation to complex bug resolution.
SWE-bench evaluates real-world GitHub bug fixing, while Terminal-Bench tests command-line proficiency needed for development and operations work.
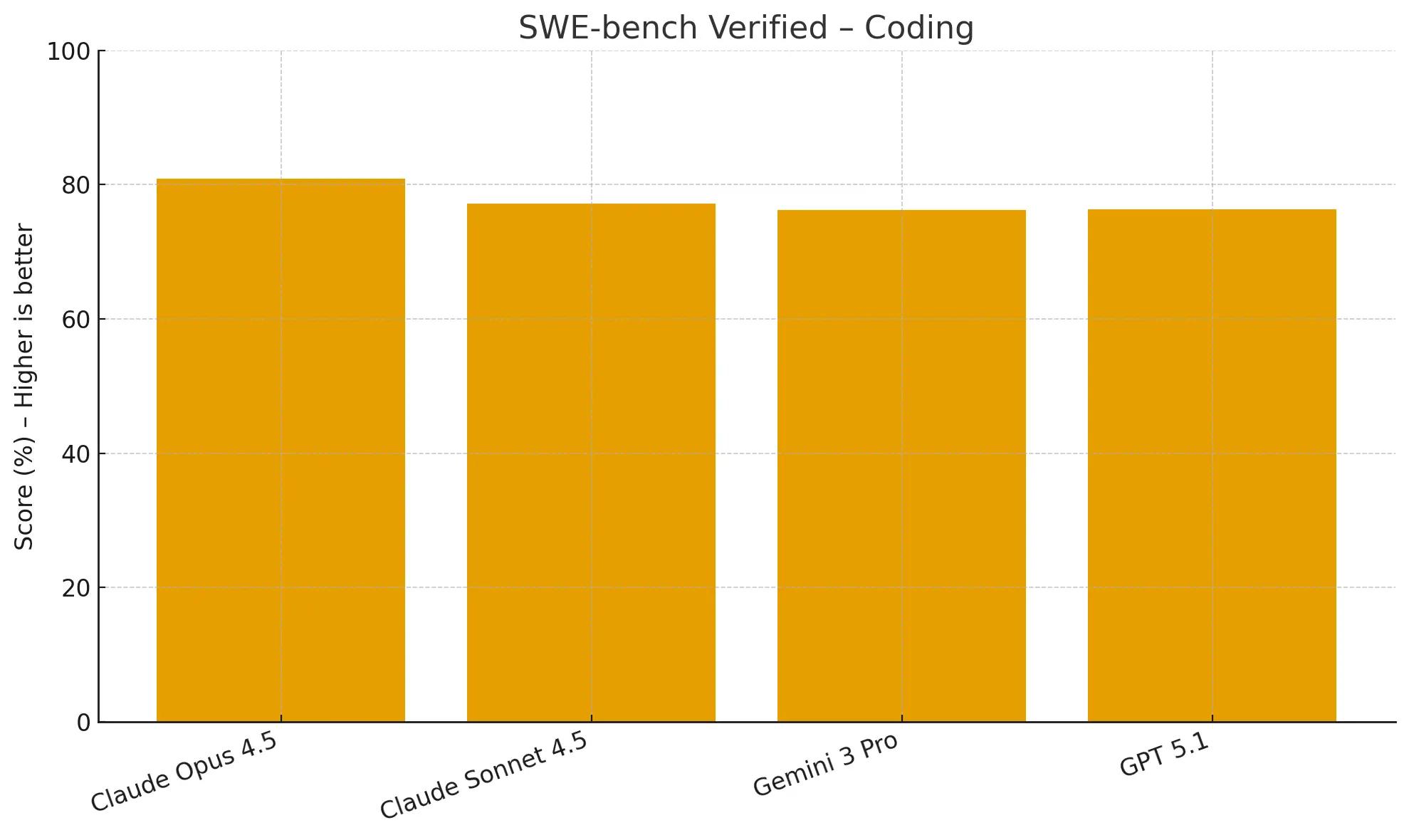
Claude Opus 4.5 delivers a state-of-the-art 80.9% on SWE-bench, outperforming Gemini 3 Pro (76.2%) and GPT 5.1 (76.3%), which makes it one of the strongest models for real bug resolution.
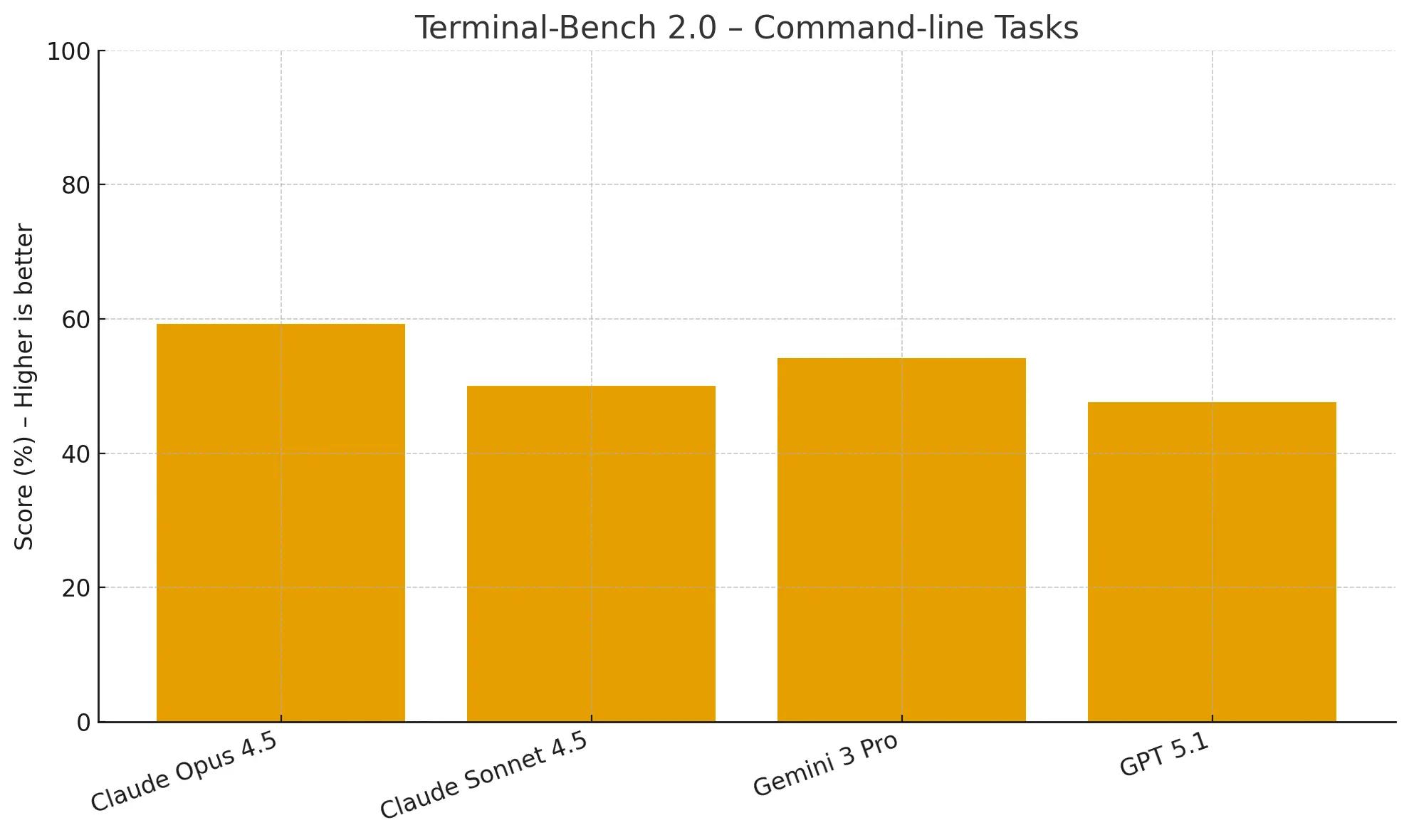
On Terminal-Bench, Opus 4.5 scores 59.3%, ahead of Gemini 3 Pro (54.2%) and significantly outperforming GPT 5.1 (47.6%), confirming its superior capability in command-line environments.
Reasoning capabilities
Reasoning benchmarks are designed to evaluate a model's ability to think logically, solve novel problems, and understand complex, abstract concepts. Strong performance here is essential for building agents that can handle multi-step, intricate workflows.
The Abstract Reasoning Corpus (ARC-AGI-2) is a test of fluid intelligence, requiring the model to solve novel visual puzzles from just a few examples. It's designed to be resistant to memorization.
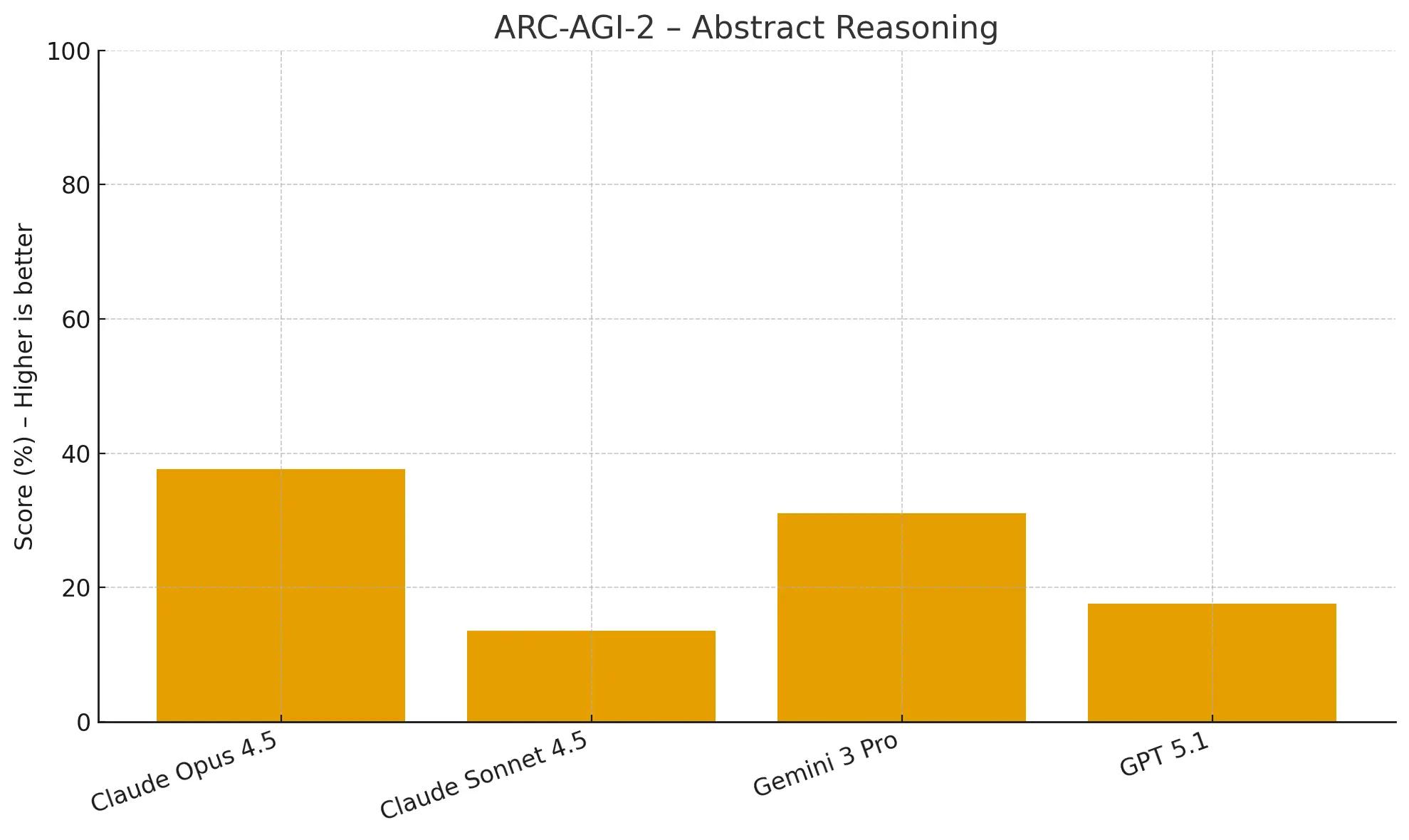
Claude Opus 4.5 achieves a remarkable score of 37.6% , a massive improvement that is more than double the score of GPT-5.1 (17.6%) and significantly higher than Gemini 3 Pro (31.1%). This points to a fundamental improvement in non-verbal, abstract problem-solving skills.
GPQA Diamond assesses knowledge at a PhD level with graduate-level questions designed to be difficult for search engines to answer. While this benchmark is nearing saturation, it remains a good measure of advanced domain knowledge.
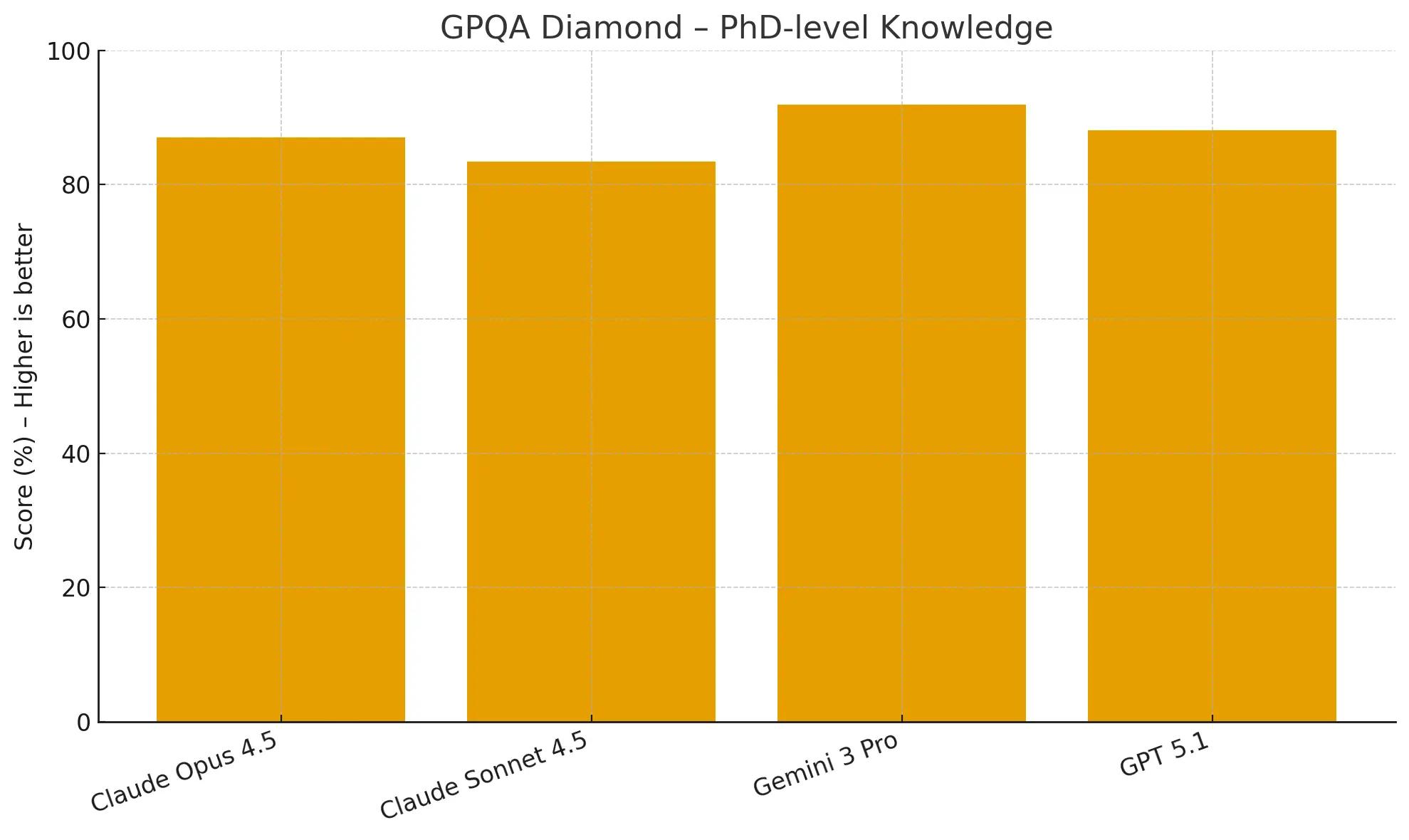
Gemini 3 Pro leads here with 91.9%, Claude Opus 4.5 still scores a very strong 87.0%, slightly behind GPT-5.1 (88.1%), confirming its place among the top models for expert-level knowledge.
Humanity's last exam is described as a benchmark at the frontier of human knowledge, this multi-modal test pushes AI to its limits.
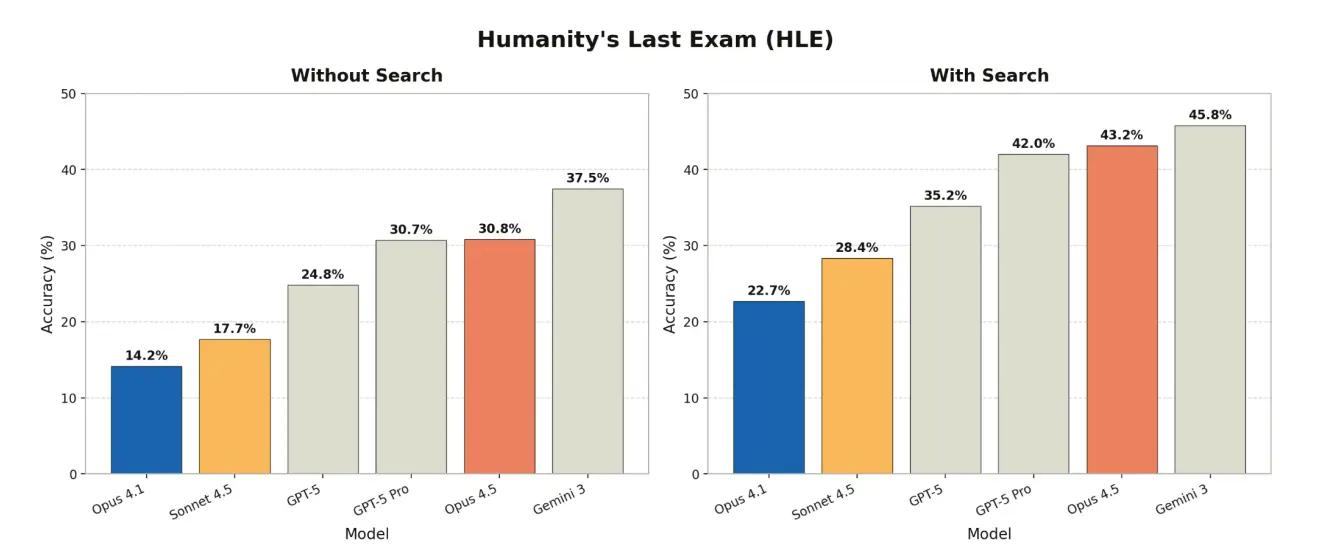
With the aid of web search, Claude Opus 4.5 scores approximately 43.2% . This is a state-of-the-art result, comparable to the performance of Gemini 3 Pro, and demonstrates its strong reasoning capabilities on some of the most challenging problems designed for AI.
Multilingual capabilities
These benchmarks evaluate a model's ability to understand and reason across dozens of languages, testing for more than just translation by including cultural context and logic.
The Massive Multitask Language Understanding (MMMLU) benchmark tests knowledge across 57 subjects in multiple languages.
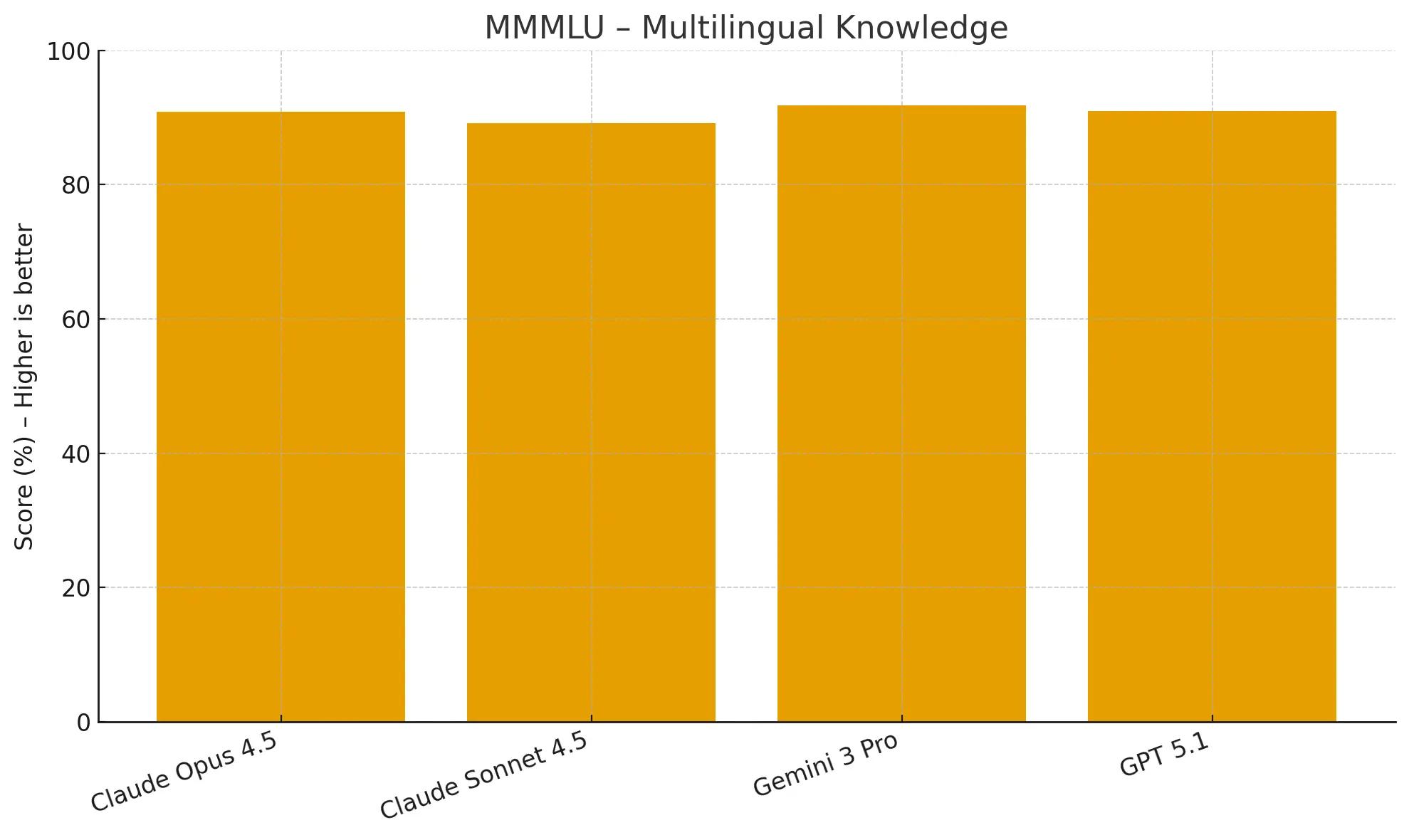
While scoring higher than Sonnet 4.5 (89.1%), Claude Opus 4.5 scored lowest in class at 90.8% while Gemini 3 Pro and GPT-5.1 came in at 91.8% and 91.0% respectively.
Visual reasoning
Visual reasoning benchmarks assess a model's ability to understand and reason about information presented in images, a key component of multi-modal AI.The Massive Multi-discipline Multimodal Understanding (MMMU) benchmark requires reasoning across both text and images.
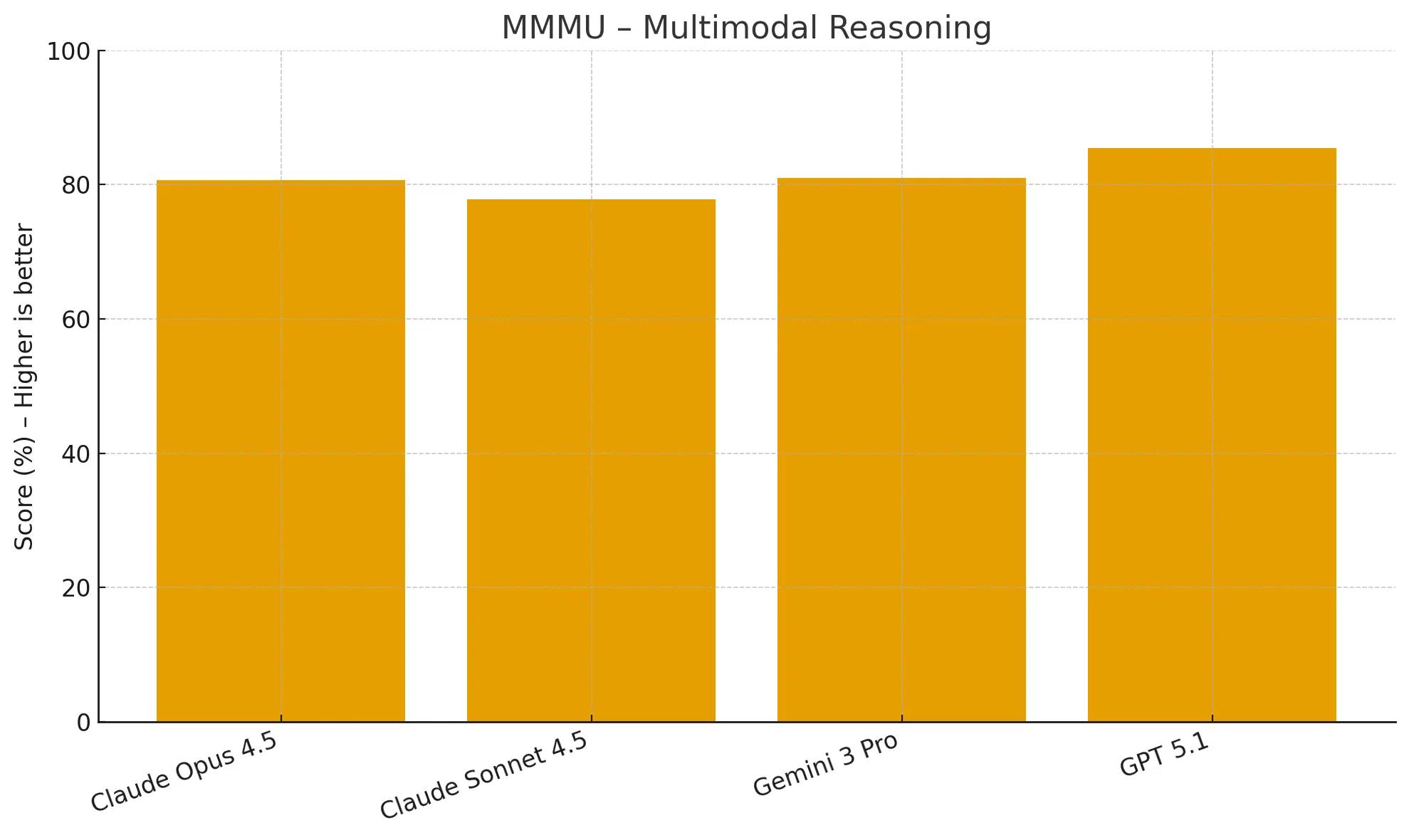
Claude Opus 4.5 performed the lowest amongst its peers at 80.7%, while GPT-5.1 (85.4%) holds the lead with Gemini 3 Pro (81.0%) as a lagging second.
Long-horizon planning capabilities
A model's true utility for agentic tasks is measured by its ability to plan and execute complex, multi-step workflows over extended periods. These benchmarks simulate real-world scenarios to test for strategic decision-making and coherence.
Vending-Bench 2 tasks a model with running a simulated vending machine business for a full year, requiring thousands of coherent decisions to maximize profit. It's a strong measure of long-term strategic planning.
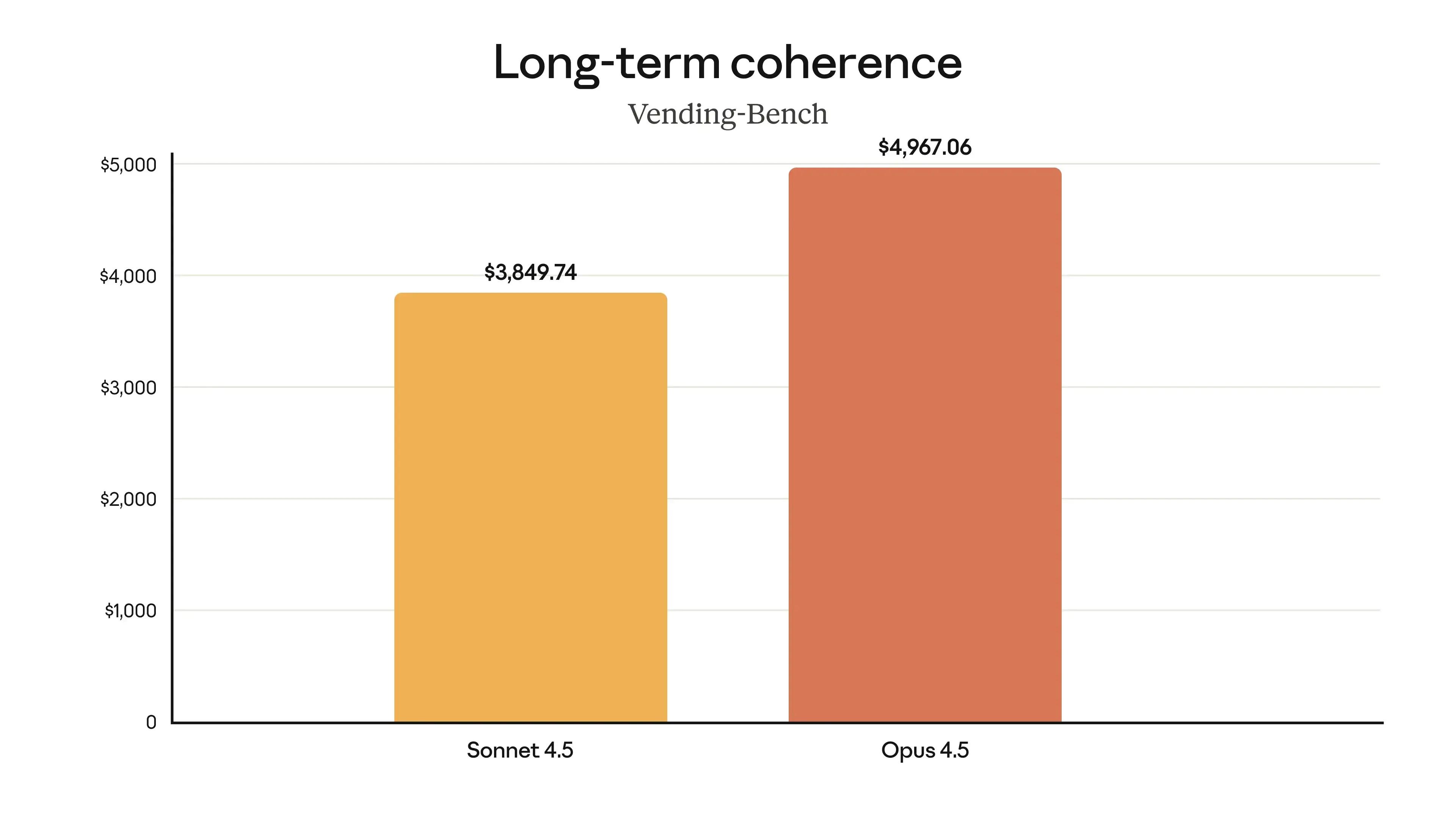
Claude Opus 4.5 achieved an impressive final balance of $4,967.06 at 23% increase over Sonnet 4.5 ($3849.74). While an impressive result, Gemini 3 Pro currently leads on this benchmark with a final balance of $5,478.16. Nonetheless, Opus 4.5's performance confirms its strong capabilities for long-horizon agentic tasks.
Agentic safety and robustness
Beyond raw capability, the reliability and safety of a model are critical, especially for autonomous agents. A key threat to agentic systems is prompt injection, where malicious instructions hidden in processed content can hijack the agent. Anthropic used Gray Swan to test for this vulnerability.
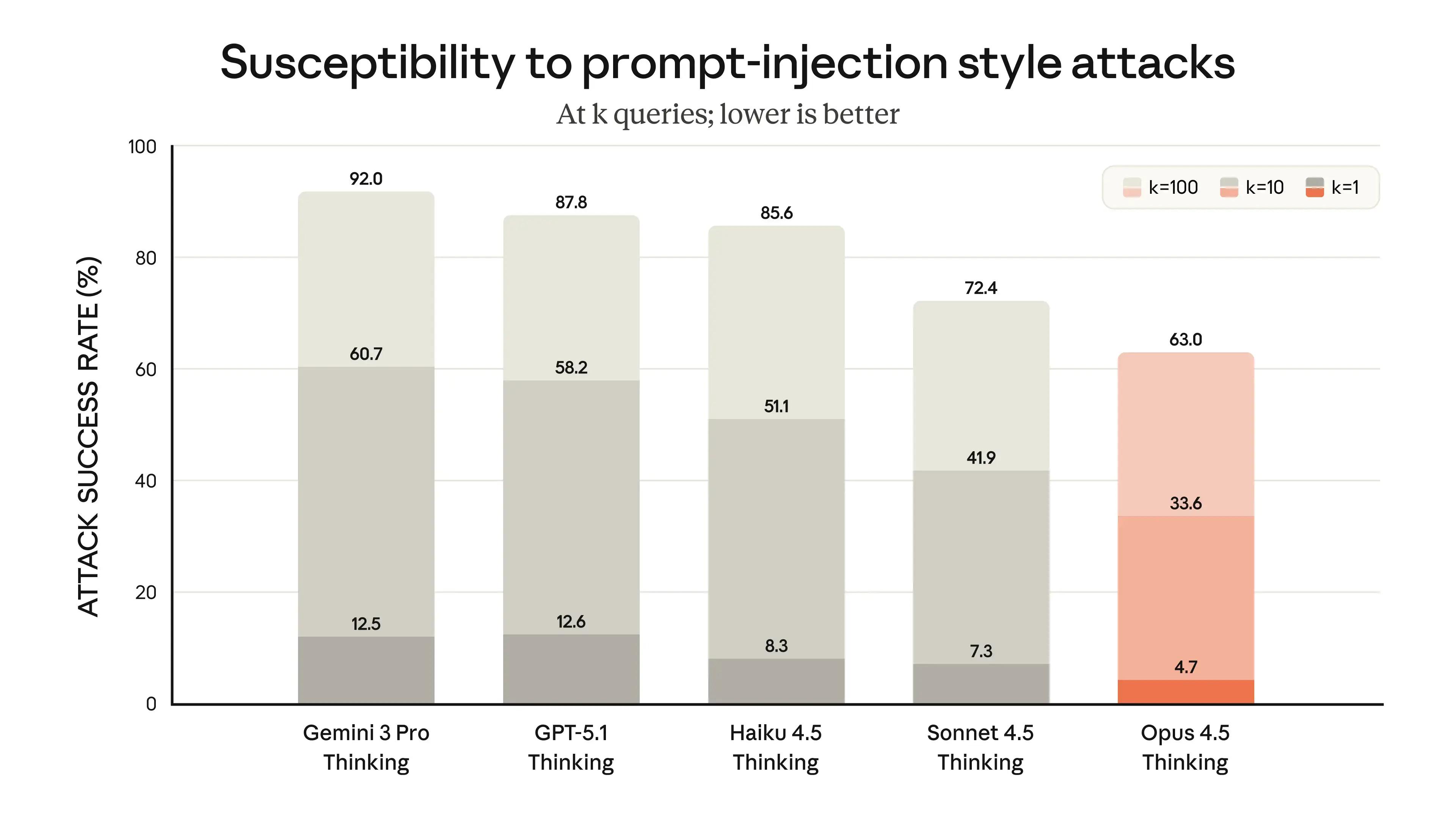
On a combined test of direct and indirect prompt injection attacks, Claude Opus 4.5 demonstrates industry-leading robustness. Its attack success rate of just 4.7% is significantly lower than that of Gemini 3 Pro (12.5%) and GPT-5.1 (21.9%).
Though impressive, this even the security methodology is not foolproof, since determined attackers can still succeed through repeated or adaptive attempts. The takeaway is that safer models help, but real security requires designing agentic systems that assume prompt injection is inevitable and enforce safeguards at the application level.
What these benchmarks really mean for your agents
The numbers in the Claude Opus 4.5 system card make one thing clear: Anthropic has delivered a frontier model that excels where it matters most for agent builders. Its best-in-class coding performance on SWE-bench gives you a model that can reliably reason about real codebases, debug with precision, and automate higher-use engineering work. Its major leap in abstract reasoning, reflected in its ARC-AGI-2 results, gives Opus 4.5 the cognitive headroom needed for complex task decomposition, tool use, and multi-step planning.
Opus 4.5 doesn’t dominate every benchmark, but its overall capability profile is one of the strongest and most well-rounded in the field. When you combine high-end reasoning and coding with its standout safety and robustness against prompt injection, you get a model that is not only strong, but reliable enough for real agentic deployment.
For teams building autonomous systems, Opus 4.5 is a compelling foundation: capable, resilient, and engineered for the kind of long-horizon workflows that modern agents demand.
Extra resources
Beginner's Guide to Building AI Agents →
Best Enterprise AI Agent Builder Platforms →
Best Low-Code AI Workflow Automation Tools →




