OpenAI just dropped GPT-5.2 quickly after Gemini 3 Pro stunned the AI space. It’s seems to be built with an emphasis to power teams pushing real workloads with serious upgrades in performance across coding, math, planning, and multimodal tasks, compared to 5.1 back.
It’s available now through the API, with Instant, Thinking, and Pro variants rolling out across ChatGPT paid plans.
If you’re evaluating models for production agents or complex workflow automation, GPT-5.2 is positioned as a serious contender. Here’s what the numbers actually show.
💡 Want to see how GPT 5.2 compares to Gemini Pro 3, Claude Opus 4.5, or Grok 4.1 for your use case? Compare them in Vellum !
Key observations of reported benchmarks
While benchmarks are inherently limited and may not fully capture real-world utility, they are our only quantifiable way to measure progress. From the reported data, we can conclude a few things:
Reasoning: The most compelling data points are the high scores on ARC-AGI-2 (52.9%) and GPQA Diamond (92.4%). This massive leap in abstract reasoning, beating out Gemini 3 Pro (31.1%) and Claude Opus 4.5 (37.6%) indicating a core improvement in academic and abstract reasoning. Coding: A new score of 55.6% on the challenging SWE-Bench Pro benchmark confirms its superior ability to handle real-world software engineering tasks across 4 coding languages rather than simply Python. Math: A perfect score on AIME 2025 is impressive, but the strong performance on the new FrontierMath benchmark (40.3% on Tiers 1-3) is more indicative of a robust intrinsic base for mathematical logic, even without relying on coding tools. Long-Horizon Planning: The results on GDPval are arguably the most indicative of practical utility. Beating or tying industry professionals on 70.9% of knowledge work tasks shows an unprecedented ability to handle long-horizon planning and coherent execution in a professional context. Vision: High scores across MMMU-Pro (86.5%) and Video-MMMU (90.5%) suggest a powerful, natively multimodal architecture capable of reasoning across temporal and spatial dimensions simultaneously.
Coding capabilities
SWE-Bench Pro and SWE-Bench Verified evaluate a model's ability to resolve real-world software issues from GitHub repositories. Unlike the Python-only Verified version, SWE-Bench Pro tests across four languages and is designed to be more challenging and industrially relevant.
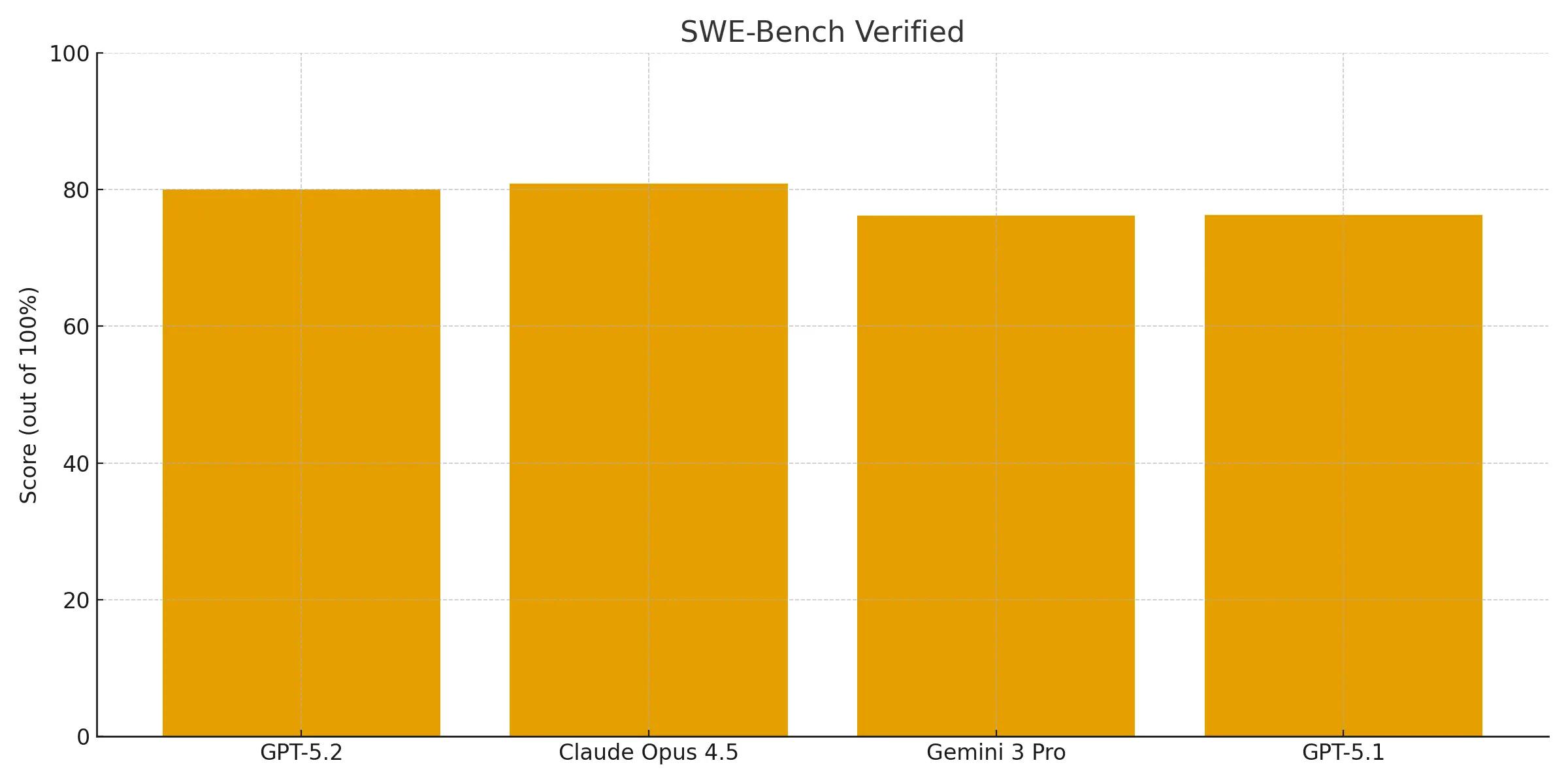
While GPT-5.2 Thinking sets a new state of the art of 55.6% on SWE-Bench Pro, on the more established SWE-Bench Verified, it scores 80.0%.
This comes neck to neck with Claude Opus 4.5 (80.9%) and surpasses Gemini 3 Pro (76.2%). This is an improvement from GPT 5.1 (76.3%) in complex, multi-language bug fixing positioning excellently for professional development workflows.
Reasoning capabilities
Reasoning benchmarks evaluate a model's ability to solve complex and novel problems. GPQA Diamond assesses PhD-level scientific knowledge, while ARC-AGI-1 and ARC-AGI-2 focus on abstract visual puzzles that resist memorization. These benchmarks are crucial for building agents that need to think and follow multi-step instructions.
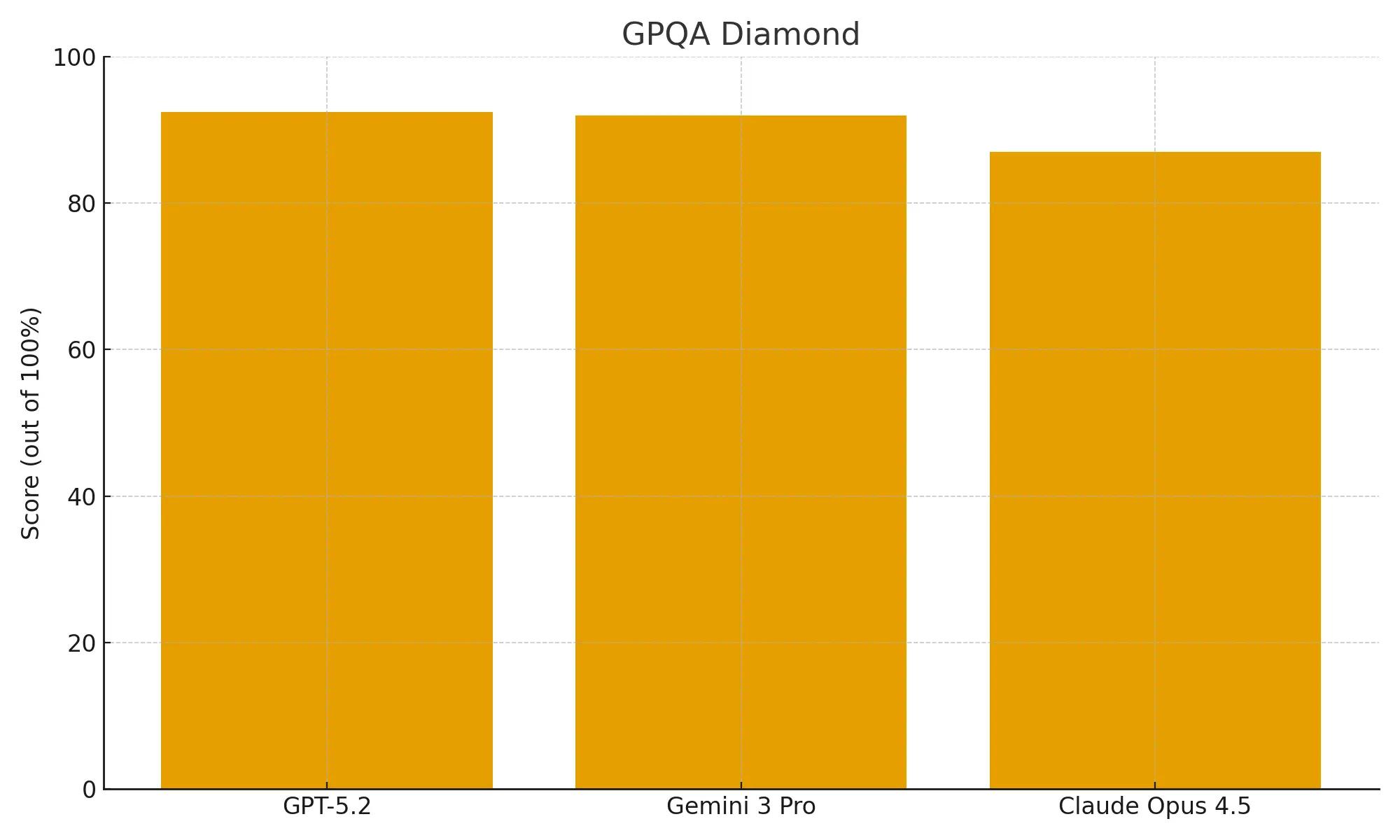
GPT-5.2 Thinking scores 92.4% up 4.3% from GPT 5.1 on GPQA Diamond, giving it a slight lead over Gemini 3 Pro (91.9%) and a significant advantage on Claude Opus 4.5 (87%) on advanced scientific questions. The most notable upgrade is in abstract reasoning.
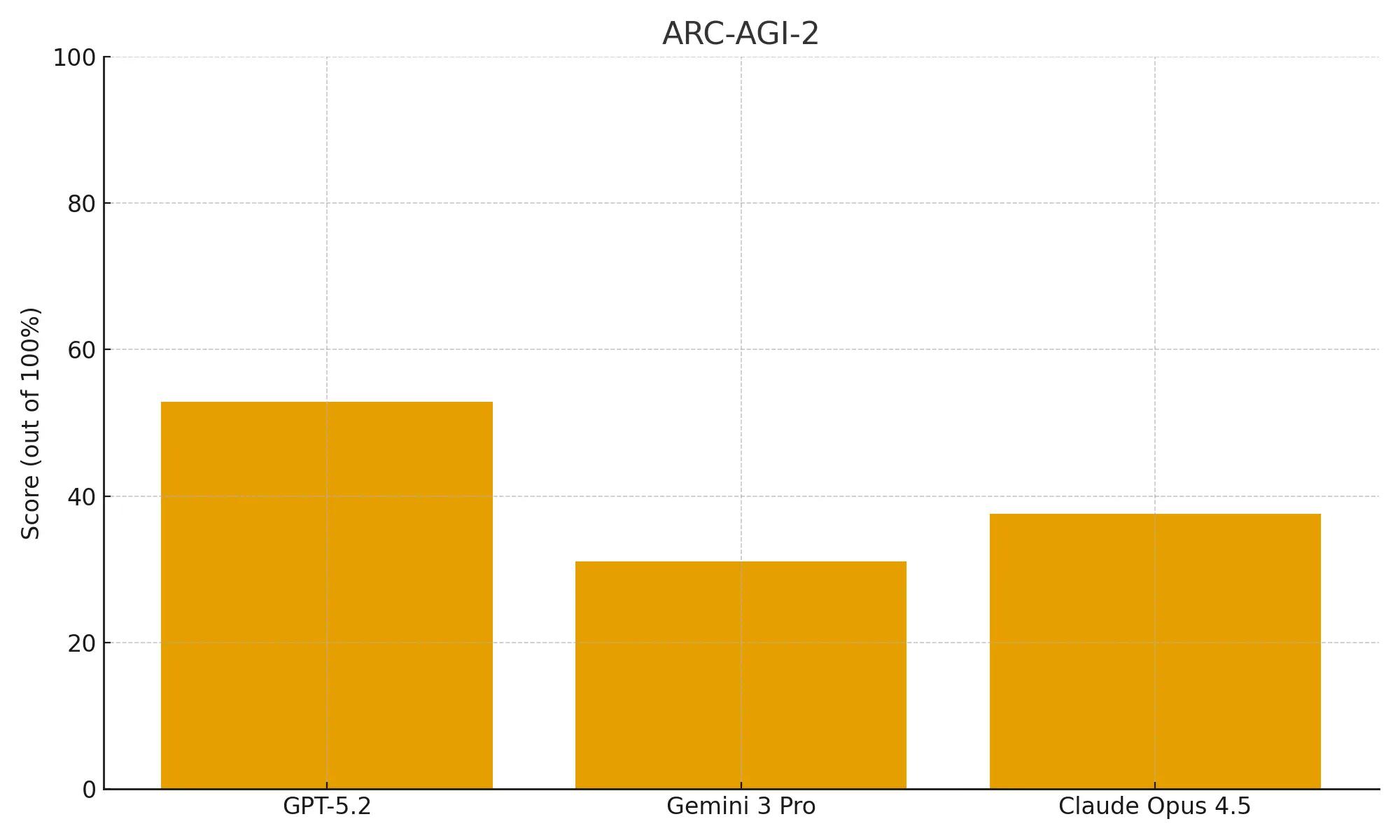
Its 52.9% score on ARC-AGI-2 is a massive jump over the scores of both Claude Opus 4.5 (37.6%) and nearly doubling Gemini 3 Pro’s performance (31.1%), indicating a fundamental improvement in non-verbal problem-solving.
Math capabilities
The AIME 2025 benchmark, based on a challenging math competition, tests quantitative reasoning. Performance on the newer FrontierMath benchmark is even more telling, as it evaluates capability on unsolved problems at the frontier of advanced mathematics.
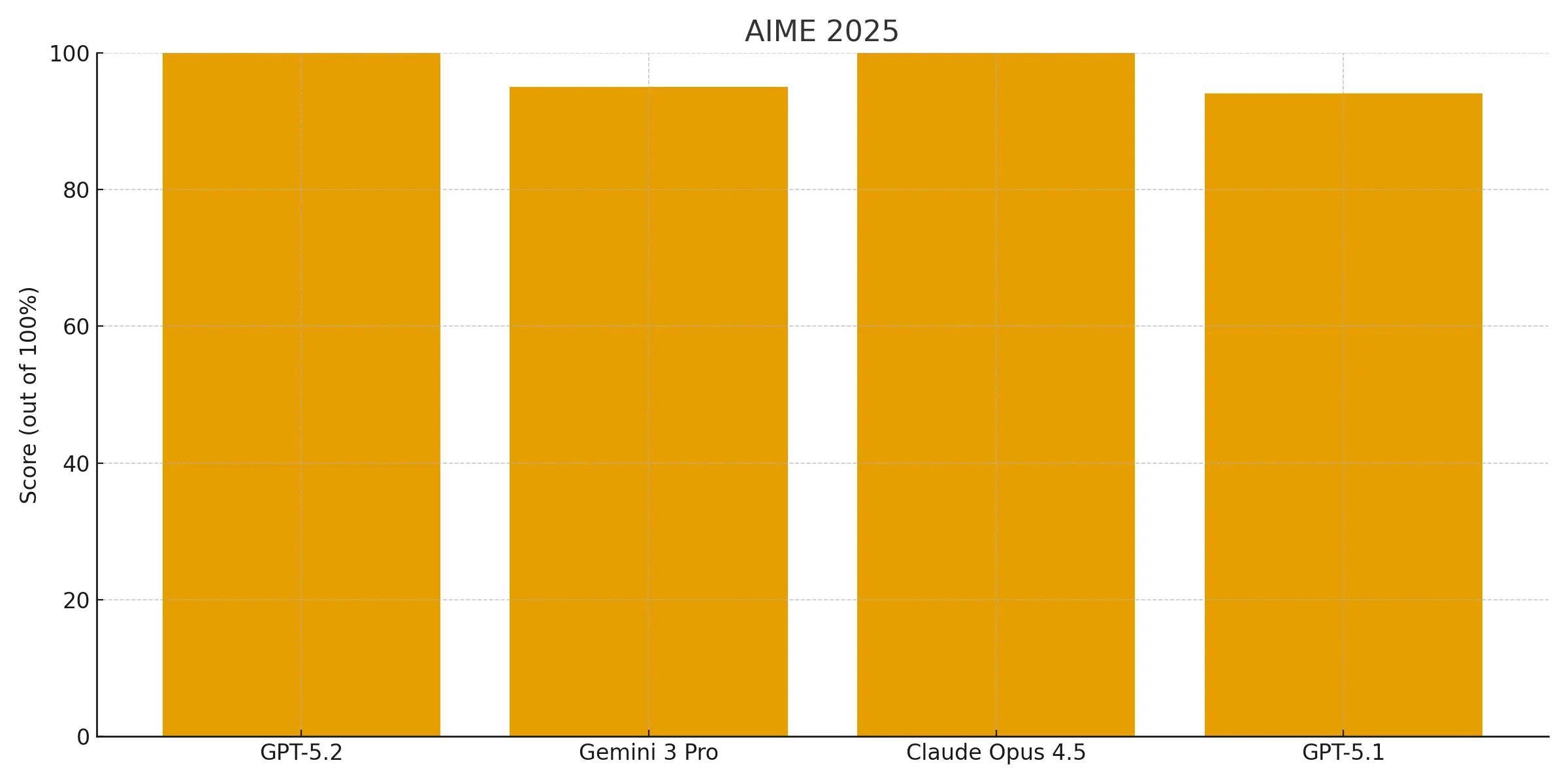
GPT-5.2 Thinking caught up to Claude Opus 4.5 with a perfect 100% score on AIME 2025 with no tools, while Gemini 3 Pro lags 5% behind the rest.
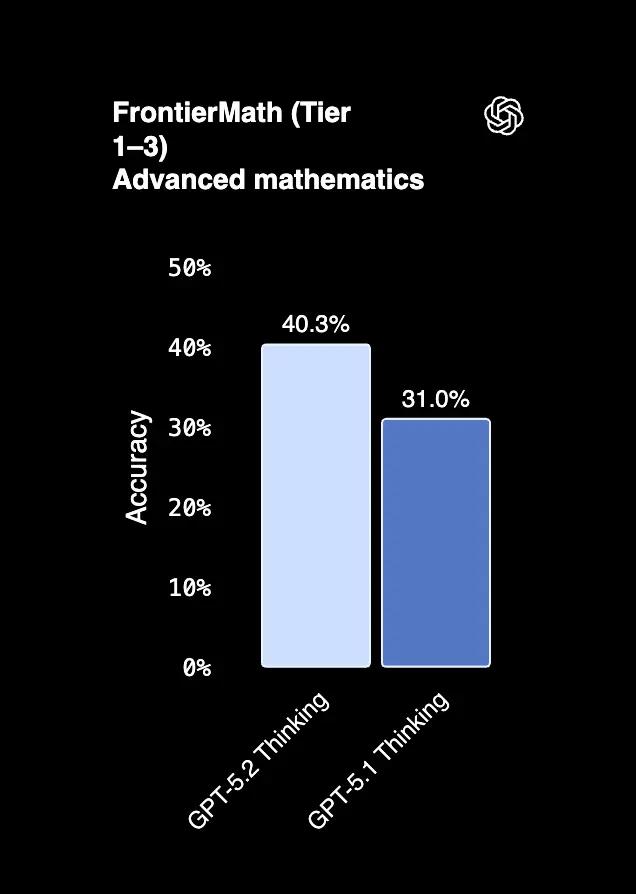
The key differentiator is its performance on FrontierMath, where it scores 40.3% on Tiers 1-3, a ~10% improvement over GPT-5.1. This strong base performance shows a more robust innate mathematical intuition, making it less dependent on external tools to find a solution.
Work task capabilities
Beyond single-turn tasks, a model's ability to plan and execute multi-step workflows is a critical measure of its agentic capabilities. GDPval measures this by evaluating performance on well-specified knowledge work tasks across 44 professional occupations.
GPT-5.2 surprisingly beats or ties with top industry professionals on 70.9% of comparisons. This benchmark, which requests real work products like presentations and spreadsheets, is a powerful indicator of practical, real-world assistance. It demonstrates the model can reliably navigate complex work from start to finish, maintaining coherence and quality over long horizons.
Long context capabilities
A large context window's value depends on the model's ability to accurately retrieve information. The MRCRv2 benchmark tests this 'needle-in-a-haystack' capability by asking the model to find specific facts within a large volume of text.
GPT-5.2 Thinking demonstrates near-perfect recall, scoring 98% on the 4-needle test and 70% on the 8-needle test within its full context window (256K input tokens).
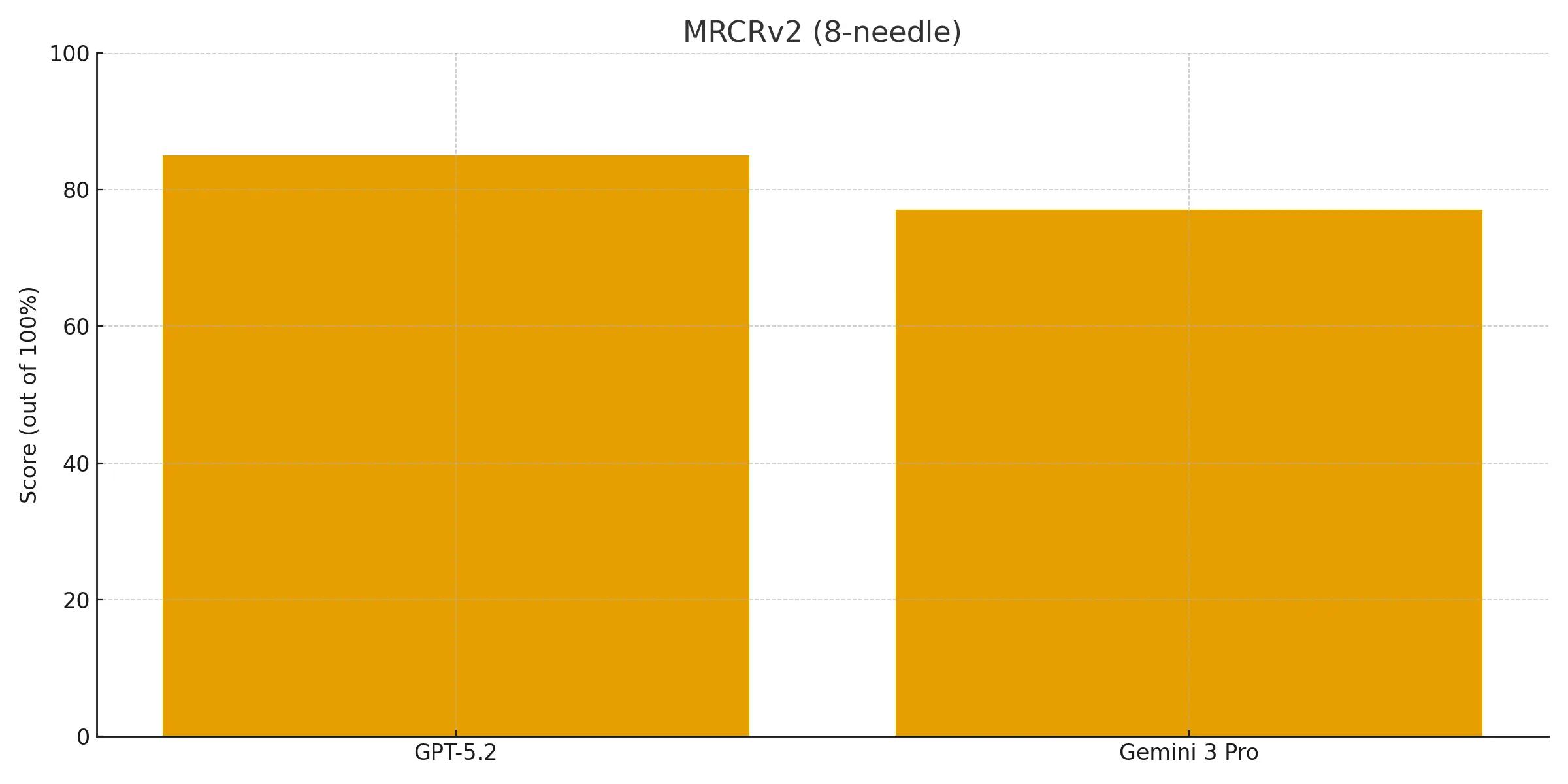
Compared to Gemini 3 Pro (77%) performance on the 8-needle test, GPT-5.2 Thinking came in at 85% mean match ratio at 128K input tokens. This shows GPT-5.2's context window is not just large but also highly reliable, allowing it to effectively use information buried in vast documents.
Vision capabilities
Natively multimodal models are assessed on their ability to understand and reason across different data types. MMMU-Pro, Video-MMMU, and CharXiv are key benchmarks for this integrated understanding of images, videos, and scientific figures.
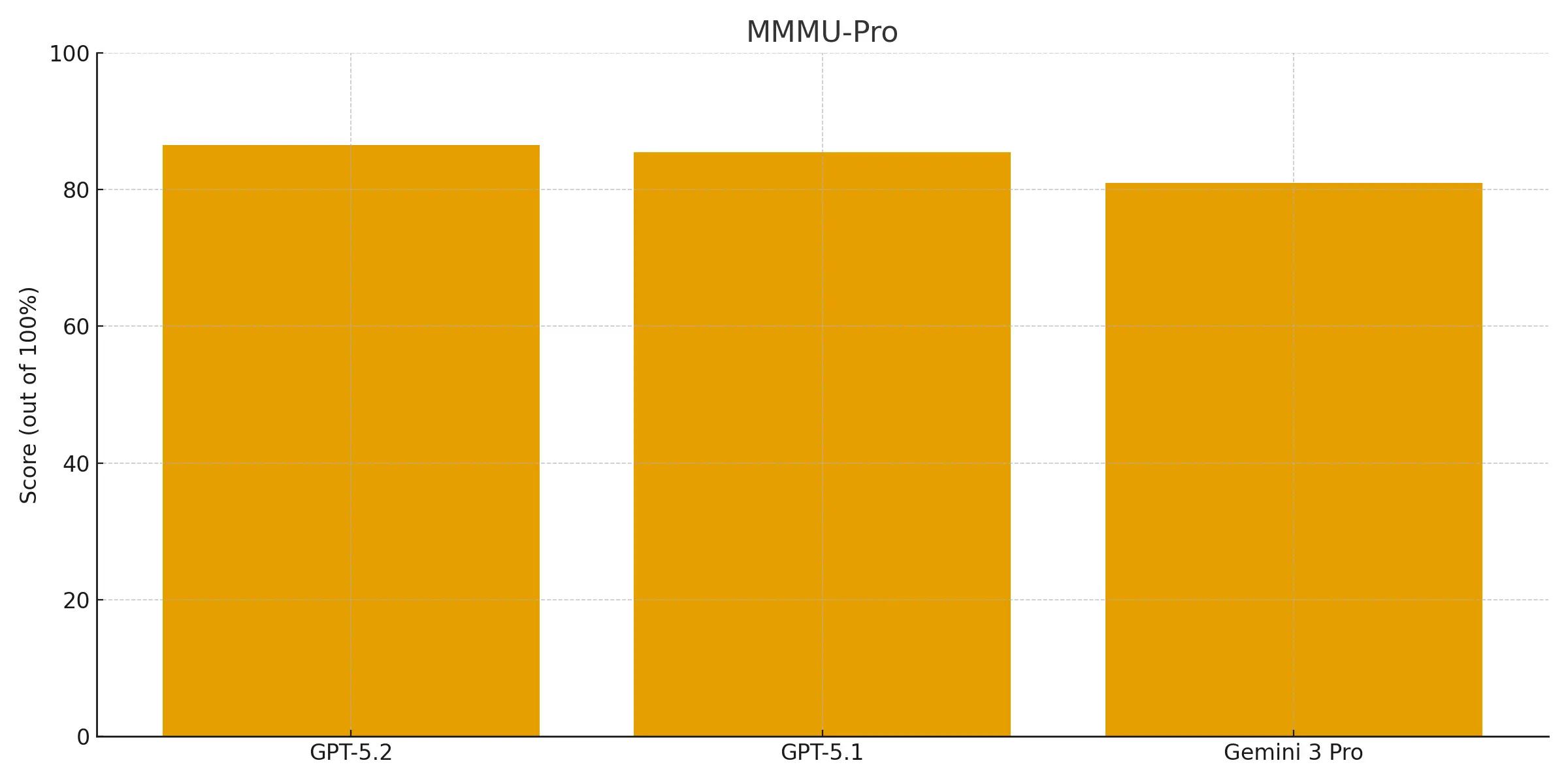
On MMMU-Pro, GPT-5.2 scores 86.5% (90.1% with Python), a slight increase against its predecessor GPT-5.1 (85.4%) and still leading over Gemini 3 Pro (81%).
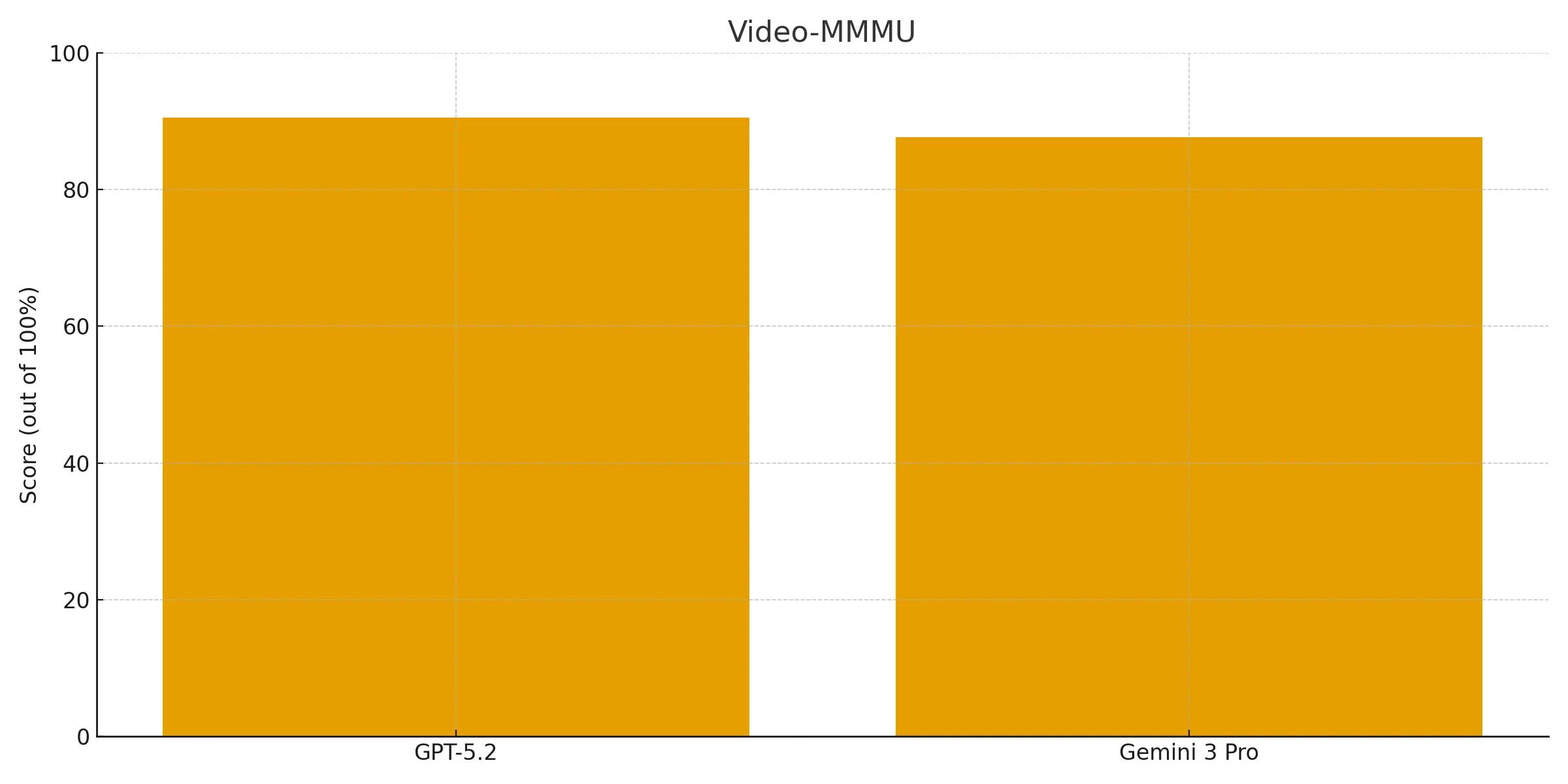
GPT-5.2 ranks higher than Gemini 3 Pro (87.6%) score on Video-MMMU, scoring 90.5%. This demonstrates its strength is not limited to static images, showing an advanced ability to comprehend dynamic video content.
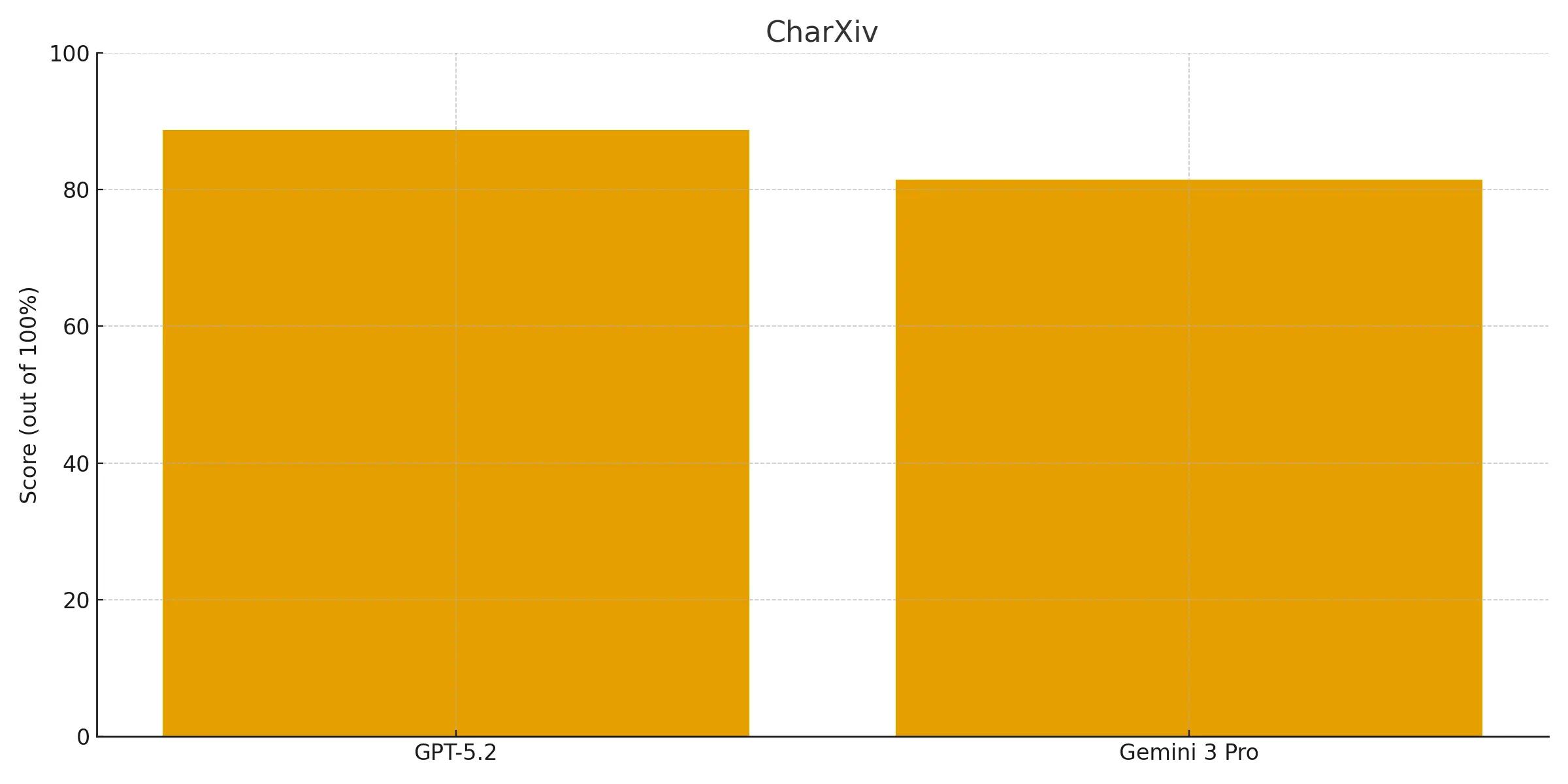
On the CharXiv with Python benchmark GPT-5.2 comes in at a whopping 88.7% beating out Gemini 3 Pro (81.4%), confirming it’s superior ability to interpret complex data visualizations.
Tool calling capabilities
The ability to reliably use external tools is critical for building powerful agents. The Tau2-bench Telecom benchmark evaluates this by testing models on complex, real-world tool usage scenarios within the telecommunications industry.
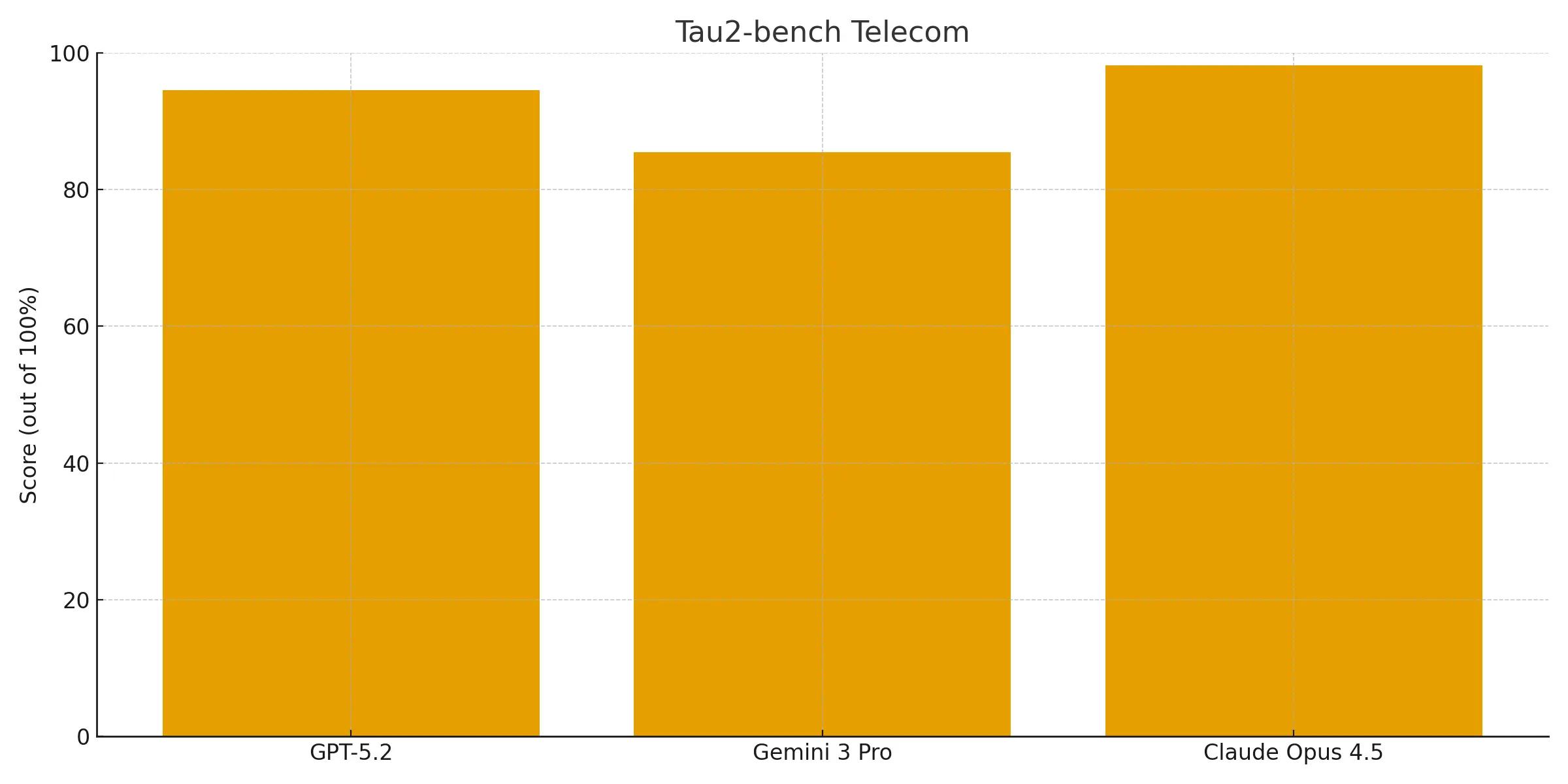
GPT-5.2 Thinking achieves a score of 94.5% on this benchmark, a massive jump over Gemini 3 Pro’s (85.4%) performance yet still falling short against Claude Opus 4.5 (98.2%) on this benchmark.
Why this matters for your agents
GPT 5.2 has firmly taken the crown from Gemini 3 Pro and finally closed the gap with Claude Opus 4.5 on the benchmarks that drive real agent performance.
Its jump in work task execution is one of the most exciting signals in this release, showing it can beat or match professionals on real knowledge work and sustain coherent output across long, multi step workflows. Updating your agents to this model could mean large gains in the amount of work you are able to reliably automate, but only time will tell if these benchmarks hold up to real world use.
If your agents are still running 5.1 or older baselines, you are leaving capability and reliability on the table. Update your agents in Vellum to see what performance gains you could be missing out on!
{{general-cta}}
Extra resources
Beginner’s Guide to Building AI Agents → Best Enterprise AI Agent Builder Platforms → Best Low code AI Workflow Automation Tools → Guide: No Code AI Workflow Automation Tools → Best AI Workflow Platforms →