
2025 has been a defining moment for artificial intelligence. While breakthrough models, like the much anticipated release of GPT 5 , created huge waves in the AI space, leaders in the space are noticing clear redlining in performance capabilities with our current tech.
The US recently announced the Genesis Mission has formally kicked off a national effort to mobilize federal data, supercomputing resources, and national labs into a unified AI research platform. Its goal is to accelerate scientific and technological progress by making government datasets and compute directly usable by advanced models. In practice, Genesis marks the first major attempt to tie frontier AI capability to state-level scientific infrastructure and national priorities.
All the while leading AI researchers like Ilya Sutskever are amplifying this transition to research to see how AI progress can be achieved. In a recent interview , Ilya argued that the “age of scaling” is ending and that simply adding more compute won’t deliver the next order-of-magnitude breakthroughs. Instead, he describes a return to core research (e.g. new training methods, new architectures, and new ways for models to reason) as the real frontier from here.
Against this backdrop, the latest flagship model releases of GPT-5.1, Gemini 3 Pro , and Claude Opus 4.5 capture the tension of this moment: rapidly improving capabilities, rising expectations for national-scale impact, and a growing recognition that the next breakthroughs will come from deeper innovation. This report analyzes model performance across the board to see how each model provider is positioning itself, and what these shifts mean for the future of AI agents.
Three trends you can’t ignore for 2026
Before diving into the numbers, it's important to contextualize the current landscape to understand where things are headed in 2026. These are the top three larger trends signaled by this new wave of flagship models.
Shift to sophisticated, long-context agents
AI chatbots are yesterday’s story. These new models are signaling the rise of systems that can reason across massive context and execute complex, multi-step work. To see how dramatic this shift is, we need to look directly at the numbers driving it.
Since 2019, frontier model context windows have expanded by roughly three orders of magnitude, ~1,000 tokens to millions, leading some analysts to call this the “new Moore’s Law” of LLMs [1] [2] [3] . The moat right now being implementation, with around 62% of organizations still experimenting with AI agents. Out of these, almost two-thirds say they have not begun scaling AI across the enterprise, and fewer than 10% have scaled agents in any given function [4] [5] .
These massive improvements are pushing the AI agents market to grow from with projections showing roughly $5.4 billion in 2024 to $7.6 billion in 2025, on track to reach about $47 billion by 2030 at a 45.8% CAGR [6] [7] [4] . AI budgets are ramping up in parallel with 88% of senior executives say they plan to increase AI-related budgets in the next 12 months specifically because of agentic AI [8] . The business value is clear, unlocking it is not.
As frontier models absorb more context and shoulder more of the cognitive load, the bottleneck is beyond model capability, it’s enterprise execution. Real leverage now comes from building agents and engineering context well enough to unlock compounding ROI.
{{ebook-cta}}
Infrastructure and distribution as key differentiators
While raw benchmark scores still matter, what now separates providers is their ability to deliver intelligence reliably and cheaply at scale aka resilient infra, smart routing, and tight integration into the places people already work.
Because these frontier models are redlining and converging capabilities, buyers are optimizing for functionality over anything else. On top of this, security/compliance and cost have climbed into the top purchasing criteria, especially with growing news of threats to security and data from AI breaches [9] .
With this shift orgs are still facing an infrastructure blocker with implementing AI:
Latency issues jumped from 32% to 53% in a year 59% of organizations report bandwidth constraints 44% of IT leaders now cite infrastructure as the top barrier to expanding AI
Now most enterprises are planning data center capacity one to three years ahead because cloud provisioning is not meeting the needs of dense AI workloads [10] .
This pressure is driving a capital and budgeting reset. Worldwide private AI investment hit about $130 billion in 2024, up more than 40% year over year , with the US alone responsible for roughly $109 billion, nearly 12 times China’s $9.3 billion [11] [12] .
In practice, distribution and infrastructure are now the throttle: as GPT-5.1, Gemini 3 Pro, and Claude Opus 4.5 reach similar capability ceilings, the winners will be the models delivered through the most reliable, compliant, and cost-efficient infrastructure.
Safety as a critical stress test
Safety has grown beyond a marketing checkbox, it is the defining constraint for deploying frontier models like GPT-5.1, Gemini 3 Pro, and Claude Opus 4.5 into real workflows. As these models gain more vital for core functions like code changes and database integration, the consequences become true operational risks.
An astonishing 34% of organizations running AI workloads report experiencing an AI-related security incident, resulting in insecure permissions and identity exposure [15] . Businesses are adjusting their spend accordingly with 67% of leaders citing security oversight as the primary factor in their AI budgeting decisions [16] .
At the same time, traditional benchmarks can no longer be trusted to fully reflect safety or robustness. Top models are clustered at the high end of MMLU, and SWE-bench Verified is showing signs of contamination, with models reaching up to 76% accuracy by pattern-matching issue descriptions rather than performing true reasoning [13] [17] . This is why providers now emphasize their own safety frameworks (OpenAI’s Preparedness, Google’s Frontier Safety Framework, and Anthropic’s ASL) as a differentiating layer on top of raw capability.
Especially with Claude Opus 4.5’s benchmarks stressing safety standards and benchmarks, it’s becoming increasingly clear that security will become a huge push for the future of model research and development.
GPT 5.1 vs Claude Opus 4.5 vs Gemini 3 Pro Benchmarks
Coding capabilities
SWE-Bench Verified
This benchmark tests a model's ability to resolve real-world software engineering issues from GitHub repositories.
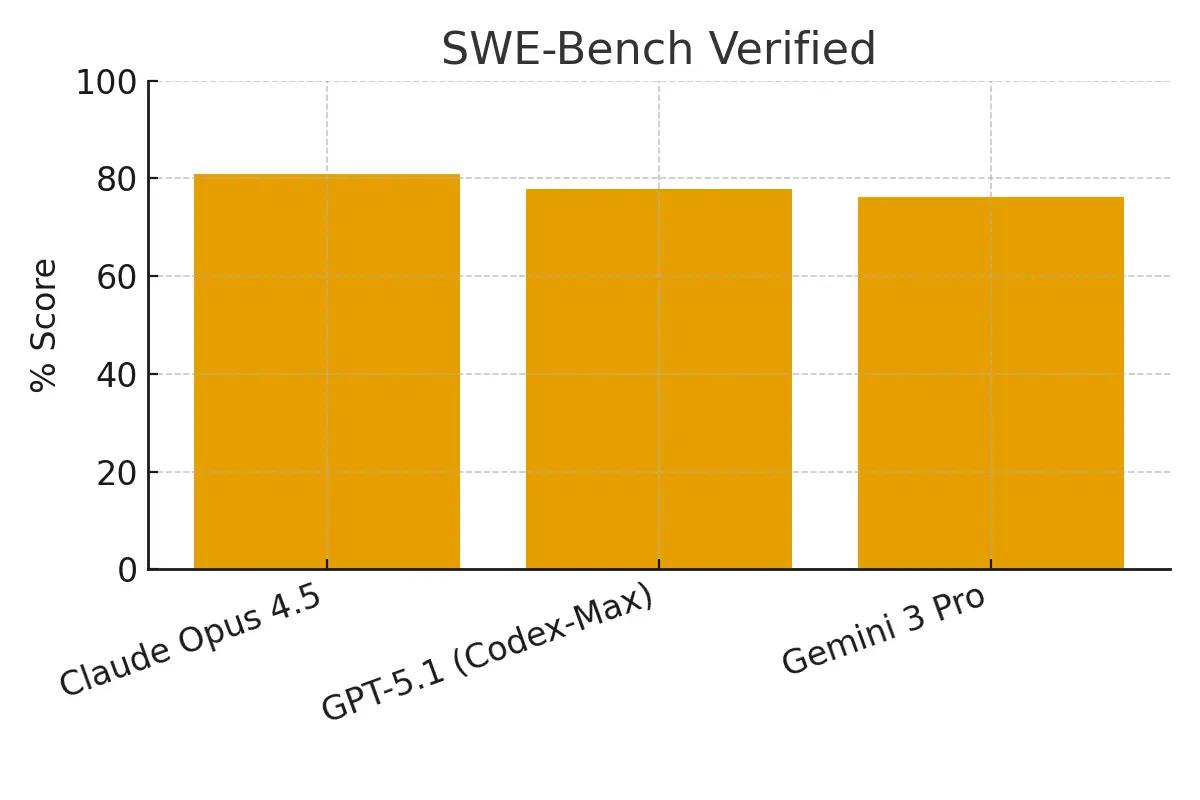
Claude Opus 4.5: 80.9% GPT-5.1 with Codex-Max: 77.9% Gemini 3 Pro: 76.2%
Claude Opus 4.5 demonstrates a clear lead in this complex, real-world coding task, establishing it as a top performer for software engineering.
Terminal-bench 2.0
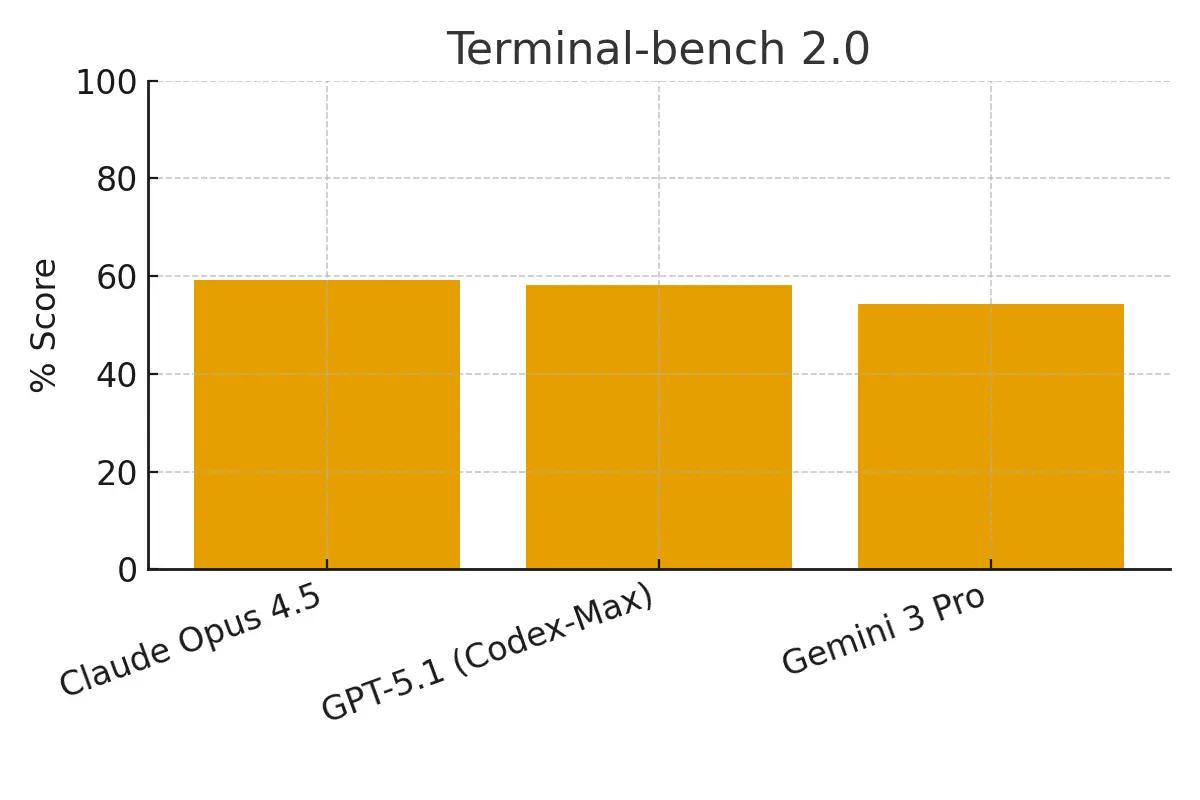
This benchmark measures a model's proficiency in using command-line environments to complete real-world tasks.
Claude Opus 4.5: 59.3% GPT-5.1 with Codex-Max: 58.1% Gemini 3 Pro: 54.2%
All three models perform competitively, with Claude Opus 4.5 holding a slight edge in terminal-based agentic tasks.
Math capabilities
AIME 2025
Modeled after the American Invitational Mathematics Examination, this benchmark tests high-school competition-level math skills.
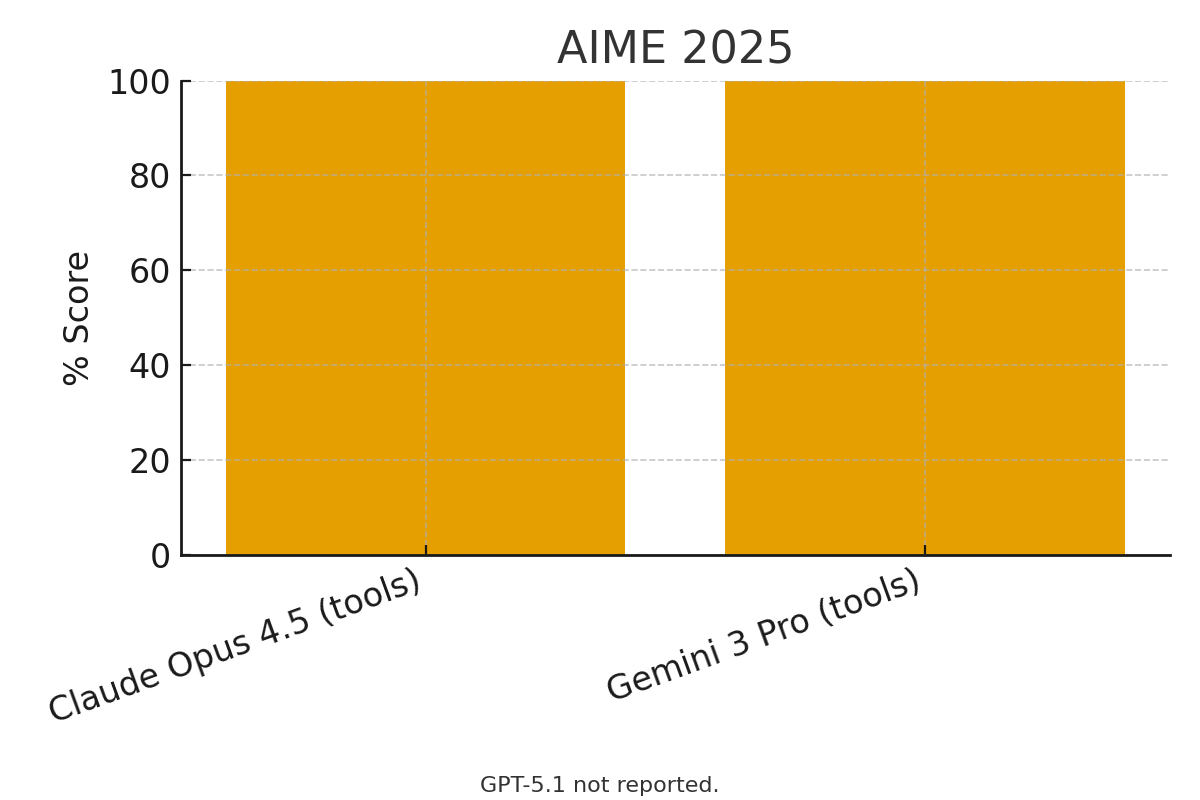
Claude Opus 4.5 (with Python tools): 100% Gemini 3 Pro (with code execution): 100% GPT-5.1: Not Reported
Both Claude and Gemini achieve perfect scores when equipped with code execution tools, showcasing state-of-the-art mathematical reasoning.
Reasoning capabilities
ARC-AGI-2
A fluid intelligence benchmark designed to measure a model's ability to reason about novel patterns from a few examples.
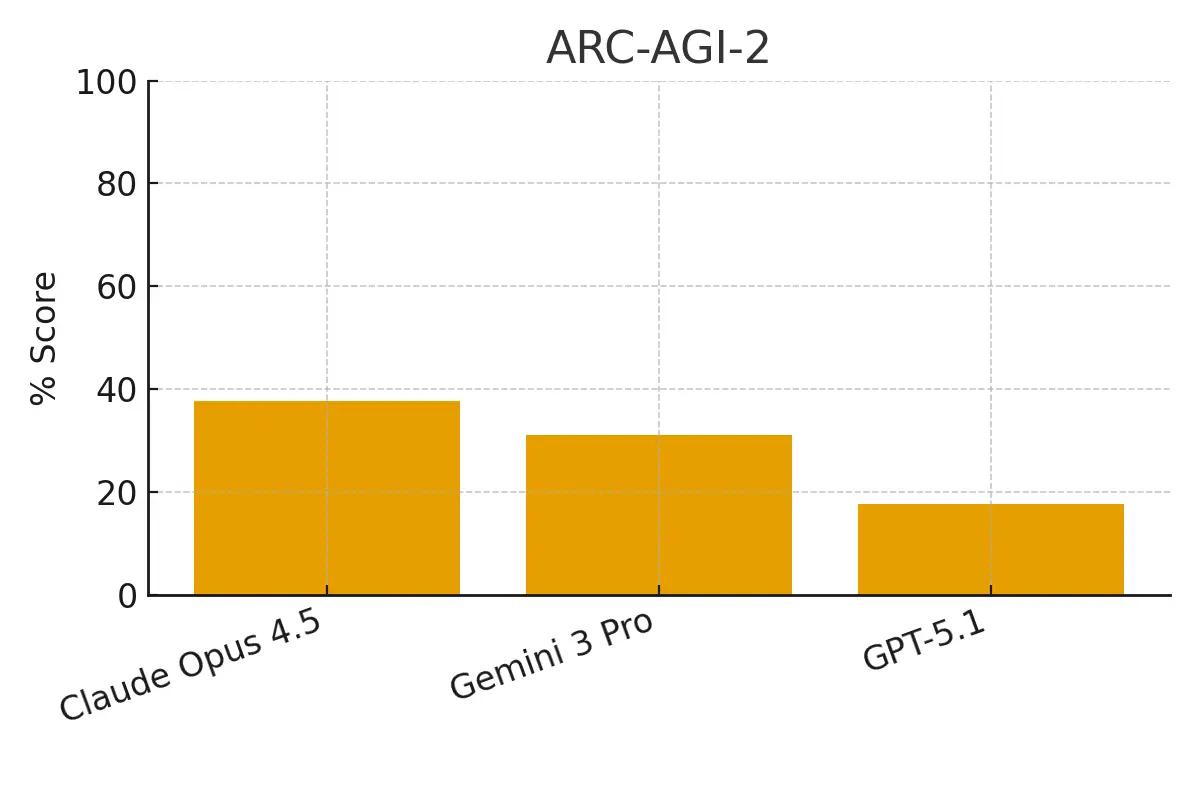
Claude Opus 4.5: 37.6% Gemini 3 Pro: 31.1% GPT-5.1: 17.6%
Claude Opus 4.5 shows a significant lead in this abstract reasoning task, more than doubling the performance of GPT-5.1.
GPQA Diamond
A set of challenging, graduate-level science questions designed to be difficult for models to answer using web search alone.
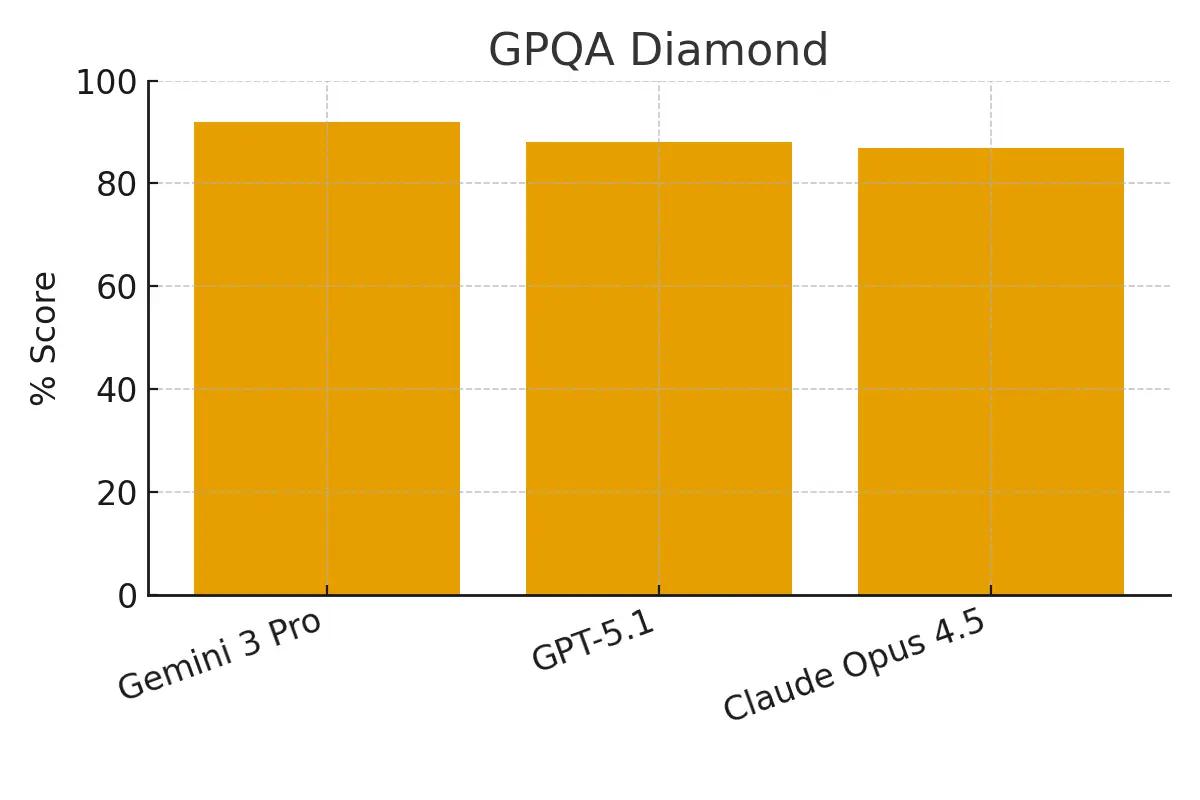
Gemini 3 Pro: 91.9% GPT-5.1: 88.1% Claude Opus 4.5: 87.0%
Gemini 3 Pro takes the top spot in this expert-level reasoning benchmark, indicating strong scientific knowledge and problem-solving skills.
Humanity's Last Exam
A difficult multi-modal benchmark covering a wide range of subjects at the frontier of human knowledge.
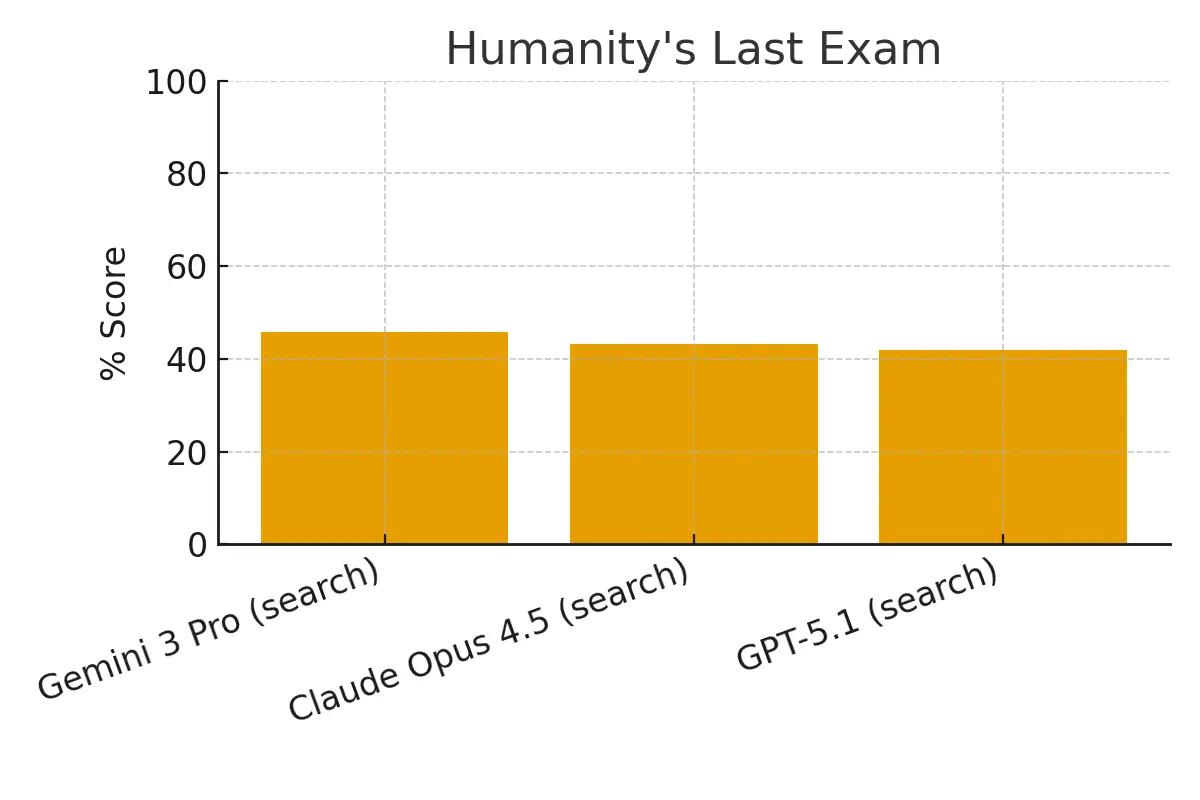
Gemini 3 Pro (with search): 45.8% Claude Opus 4.5 (with search): 43.2% GPT-5.1 (with search): 42.0%
Gemini 3 Pro leads the pack, demonstrating superior performance on this comprehensive test of general knowledge and reasoning.
Multimodal capabilities
MMMU (Visual Reasoning)
The Massive Multi-discipline Multimodal Understanding benchmark tests reasoning across text and images.
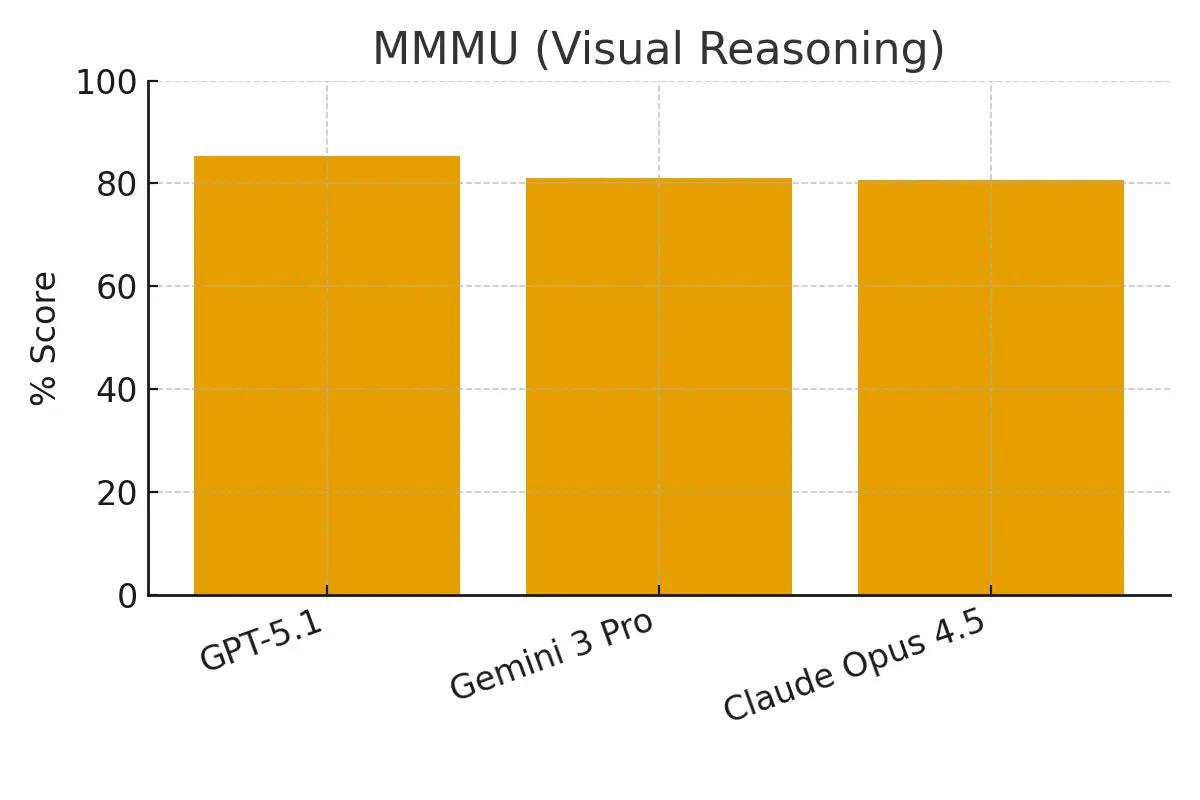
GPT-5.1: 85.4% Gemini 3 Pro: 81.0% Claude Opus 4.5: 80.7%
GPT-5.1 shows the strongest performance in multimodal reasoning on this benchmark, indicating advanced capabilities in interpreting and analyzing visual information.
Video-MMMU
This benchmark specifically evaluates multimodal understanding in the context of video.
Gemini 3 Pro: 87.6% Claude Opus 4.5: Not Reported GPT-5.1: Not Reported
Google is the only provider to report a score, highlighting Gemini's focus on advanced video processing and understanding.
Multilingual capabilities
MMMLU
The Multilingual Massive Multitask Language Understanding benchmark tests knowledge across 57 subjects in 14 languages.
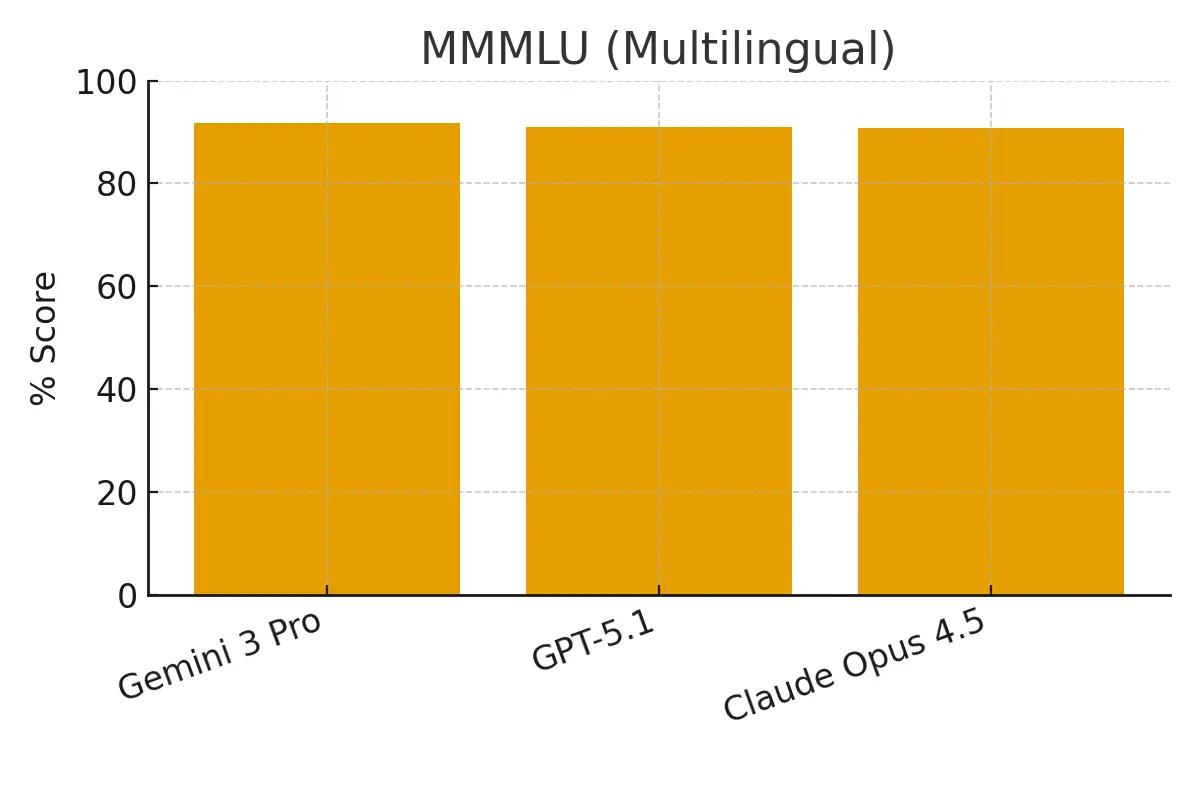
Gemini 3 Pro: 91.8% GPT-5.1: 91.0% Claude Opus 4.5: 90.8%
All three models are extremely close, but Gemini 3 Pro has a slight edge in multilingual knowledge and reasoning.
Long context capabilities
MRCR v2 (8-needle)
This 'needle-in-a-haystack' test measures a model's ability to recall specific facts from a long context window.
Gemini 3 Pro: 77.0% Claude Opus 4.5: Not Reported GPT-5.1: Not Reported
Only Google reported a score for this specific long-context benchmark, where Gemini 3 Pro demonstrates strong recall capabilities.
Long-horizon planning and agentic skills
Vending Bench 2
This benchmark measures a model's ability to manage a simulated vending machine business over a one-year period, testing sustained coherence and strategic planning.
Gemini 3 Pro: $5,478.16 (final balance) Claude Opus 4.5: $4,967.06 (final balance) GPT-5.1: Not Reported
Gemini 3 Pro demonstrates superior long-horizon planning skills, achieving a higher final balance in this complex business simulation.
Safety capabilities
Each provider is advancing its safety framework alongside its model capabilities. Anthropic has deployed Claude Opus 4.5 under its AI Safety Level 3 (ASL-3) standard, focusing on rigorous internal and third-party evaluations.
OpenAI assesses GPT-5.1 under its Preparedness Framework, treating it as a 'High risk' model in sensitive domains like biology.
Google evaluates Gemini 3 Pro against its Frontier Safety Framework, reporting that the model did not reach any critical capability levels that would trigger the highest alerts. These frameworks represent a maturing industry-wide effort to manage the risks associated with increasingly powerful models.
Susceptibility to prompt-injection
Prompt injection remains one of the biggest threats to autonomous agents. Malicious instructions buried in user content, documents, or webpages can hijack an agent’s behavior, regardless of how capable the underlying model is. Anthropic evaluated this risk using the Gray Swan benchmark, which measures both direct and indirect injection attacks.
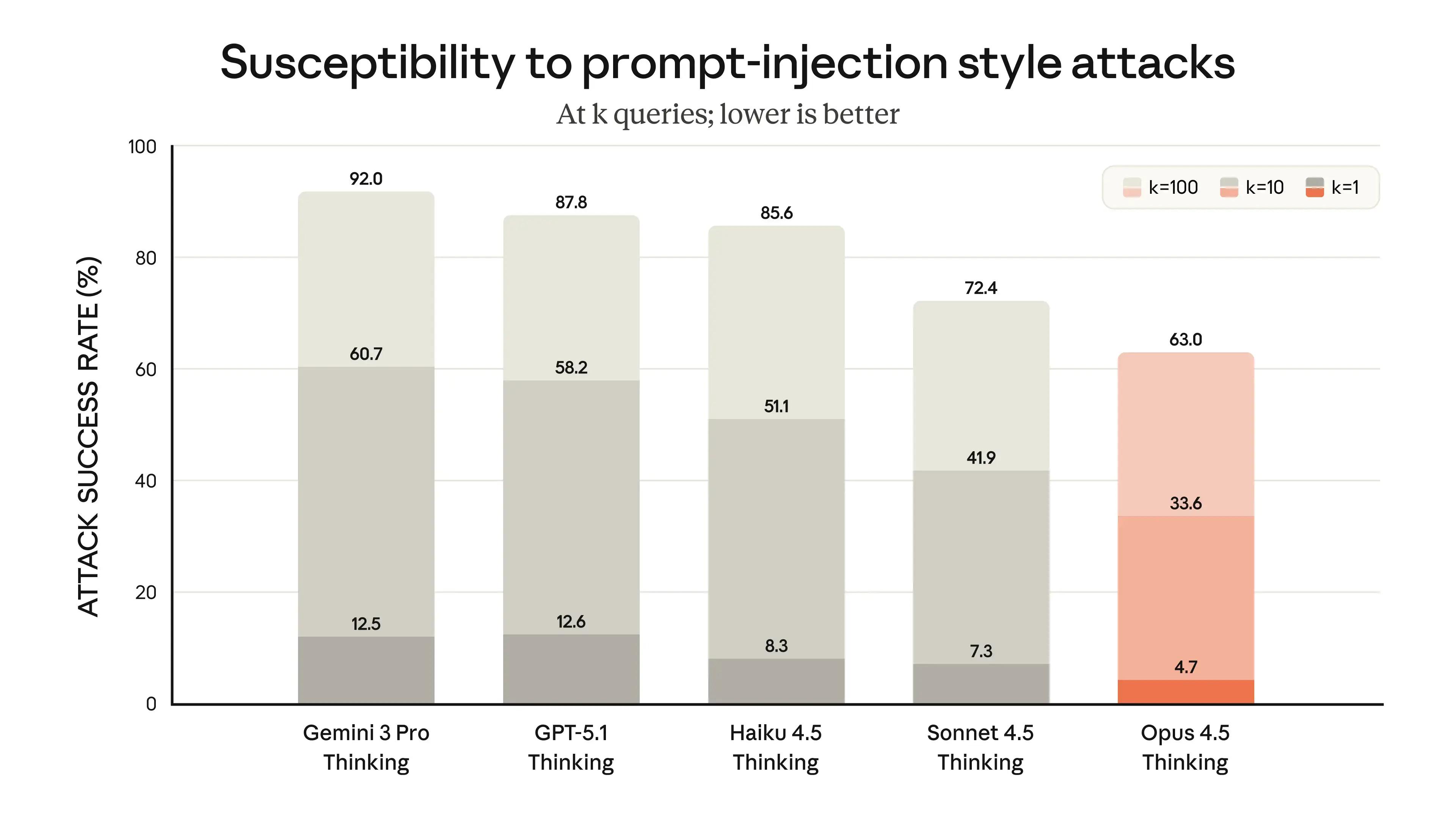
Claude Opus 4.5 shows the strongest resistance, with an attack success rate of 4.7% , compared with 12.5% for Gemini 3 Pro and 21.9% for GPT-5.1. This makes Claude materially harder to manipulate when running agentic workflows.
But even these results aren’t foolproof. Persistent attackers can still break through with repeated or adaptive prompts. The lesson: safer models help, but real protection comes from designing agents that assume prompt injection will happen — with strict tool permissions, content validation, and system-level guardrails.
How the big three are really playing the game
Google: Winning the generalist and platform narrative
Google is positioning Gemini 3 Pro as the model that shows up everywhere people already work. The strategy is straightforward: make Gemini the default brain inside Google’s ecosystem and the easiest model for billions of users to touch.
What Google is pushing:
Broad capability dominance: leaning hard on top-tier benchmark wins and multimodal strength. Massive distribution: Gemini is baked into Search, Android, Workspace, and the Gemini app’s huge user base. A unified developer platform: 13M+ developers and a growing ecosystem of Gemini-powered tools.
Where Google is trying to differentiate:
Agentic coding with Antigravity:
A full-stack coding environment (editor + terminal + browser) meant to compete directly with Cursor and Replit, but powered by Gemini 3 Pro’s reasoning and tool-use capabilities.
Multimodal-native surfaces:
Tools like Nano Banana Pro show Google wants Gemini to be the engine behind visual content, infographics, and image-to-slide workflows.
AI-native shopping and productivity:
Turning everyday Google products into agent canvases — Search that calls stores for you, Workspace that auto-builds assets, and Android that can act on your behalf.
Doing what Google does best, it wants to win by owning the AI stack e.g. model, distribution, products, and the “trusted AI infra” underneath it. Private AI Compute reinforces this narrative, with Google is pitching itself as the provider with the most secure, vertically integrated setup for both consumer and enterprise agents.
Anthropic: The reliable operator
Anthropic is positioning Claude Opus 4.5 as the model you trust to actually run your workflows. They’re clearly leaning hard on one message: Claude is built to do real computer work reliably.
Here’s how they frame it:
Practical capability first: strong performance on coding, tool use, and spreadsheet tasks Tight product integrations: Chrome, Excel, and other everyday tools become natural extensions of Claude’s workflow. Memory and long context as a moat: endless chat, smarter retention, and Haiku-powered sub-agents are pitched as core to building agents that can work across huge documents and codebases.
And they’re backing that story with heavy infrastructure investment, including a planned $50 billion data center buildout , signaling that Anthropic wants to be the model businesses run on.
OpenAI: The consumer default with a deep-work tier
OpenAI is playing a two-layer game: dominate the consumer front with ChatGPT, then upsell serious teams into GPT-5.1 and Codex-Max for deep work.
What OpenAI is pushing on the surface:
ChatGPT as the default AI app
OpenAI wants to be the first place most people touch AI: mobile app, web, group chats, lightweight workflows, and “ask me anything” use cases.
Everyday productivity first
ChatGPT is packaged as a general-purpose assistant for writing, summarization, brainstorming, slide polish, quick coding help, etc.
A growing ecosystem around ChatGPT
Group chats, shared workspaces, lightweight collaboration all aimed at making ChatGPT feel like an everyday tool, not just an API playground.
Where the deeper play shows up:
GPT-5.1 and Codex-Max for real engineering work
Under the ChatGPT layer, OpenAI is building a story around long-running coding sessions, multi-step problem solving, and models that can stay focused on the same technical task for hours.
“Reasoning cost” as a product lever
OpenAI keeps talking about reducing the cost of high-reasoning workloads. That’s a clear signal they’re aiming at companies that want agents to do serious, expensive work without blowing up their inference bill.
Tight control of capacity
The quotas, local vs cloud task split, and tiered access all point to a simple fact: capacity is scarce and prioritized for people paying for sustained, high-value workloads.
OpenAI isn’t trying to be the model you plug into everything by default. They’re trying to be:
the AI app most people open daily, and the high-end engine serious teams tap when they need a model to grind through long, painful, deeply technical problems.
In that sense, OpenAI sits at both ends of the spectrum: mass-market entry point on the low end, and deep-work specialist for teams willing to pay for real horsepower on the high end.
Future of agentic AI
Frontier models now compete on one question: which one is best for this agent and this job?
No single model wins in every single category. The edge now is knowing when to use which in your AI agents, and being able to change that decision quickly as the landscape moves.
That is exactly where Vellum comes in. Vellum is model agnostic, so you can benchmark these models in your own workflow, route traffic to the best option per task, and swap providers without rebuilding your agents. Prompting Vellum to change and optimize agents by model makes upgrading only take a couple minutes.
The only sustainable strategy is building agents on a platform that lets you switch models as fast as the frontier moves.
{{general-cta}}
FAQs
- How should I choose between GPT-5.1, Gemini 3 Pro, and Claude Opus 4.5 for my specific use case?
Focus on the task , not the model. Each frontier model excels in different domains like coding depth, multimodal reasoning, long context, or safety posture. The right answer depends on the agent you’re building, not on benchmark averages.
- What’s the best model for building a coding or software-automation agent?
Claude Opus 4.5 currently leads on SWE-Bench and Terminal-bench, making it a strong choice for engineering-heavy workflows. But for extended deep-work loops, GPT-5.1/Codex-Max may be stronger.
- What’s the best model for multimodal or video-heavy applications?
Gemini 3 Pro is currently the strongest in multimodal reasoning and the only model with reported Video-MMMU results, making it a better fit for agents that need to “see,” analyze, or process real-world data.
- What’s the best model for reasoning-intensive agents?
Claude leads in abstract reasoning (ARC-AGI-2). Gemini leads in scientific reasoning (GPQA Diamond). GPT-5.1 is optimized for long, multi-step reasoning across large work sessions. The “best” depends on the type of reasoning.
- How often should I reevaluate which model my agents use?
Every release of flagship frontier model. Frontier models are updating too quickly to lock in long-term assumptions. This is why model-agnostic orchestration is critical.
- Why do different models win on different benchmarks?
Benchmarks measure narrow capabilities, and models are typically trained for different focuses. Models are trained with different priorities (coding-heavy, multimodal-heavy, reasoning-heavy) so no single model dominates across all domains.
- Do benchmark results reliably predict real-world agent performance?
Not always. Benchmarks often show ceiling capability. Real workflows involve messy data, tool use, and long-horizon coherence. These are areas where architecture, context handling, and safety constraints matter more.
- How should I think about model safety when deploying agents?
Model-level safety reduces risk, but it’s not enough. You must assume prompt injection and misuse will happen. Permissioning, tool isolation, validation layers, and audit logs matter as much as the model choice.
- Are larger context windows always better?
Not necessarily. Very large windows can degrade semantic performance (“context rot”). The real gain comes from engineered context (retrieval, chunking, and memory strategies) not raw window size alone.
- Is it realistic to standardize on a single model across an entire organization?
No. Teams will need different strengths: coding, multimodal, analysis, planning, translation, etc. Multi-model routing becomes more efficient and safer than a single-model strategy.
- Why use Vellum instead of integrating each provider manually?
Because capabilities shift monthly. Vellum lets you plug in any model, benchmark them against your own tasks , and route work to the best provider without rebuilding infrastructure. It’s the only practical way to stay competitive as the model landscape keeps changing.
Citations
[1] Platform Studio. 2025. LLM Context Window Size: The New Moore’s Law .
[2] Exploding Topics. 2025. List of LLMs .
[3] Meibel.ai. 2025. Understanding the Impact of Increasing LLM Context Windows .
[4] DataGrid. 2025. AI Agent Statistics .
[5] McKinsey. 2025. The State of AI .
[6] Warmly.ai. 2025. AI Agents Statistics .
[7] Kanerika. 2025. Agentic AI 2025: Emerging Trends Every Business Leader Should Know .
[8] PwC. 2025. PwC’s AI Agent Survey .
[9] Andreessen Horowitz (a16z). 2025. AI Enterprise 2025 .
[10] Flexential. 2025. 2025 State of AI Infrastructure Report .
[11] Exploding Topics. 2025. AI Statistics .
[13] Stanford HAI. 2025. 2025 AI Index Report .
[14] HP. 2025. Enterprise AI Services: Build vs Buy .
[15] Cloud Security Alliance. 2025. The State of Cloud and AI Security 2025 .
[16] Cybersecurity Dive. 2025. AI Security Spending Reports .
[17] Tang, Y., Li, Z., Zheng, K., Wu, Y., & Li, Q. 2025. Understanding Contamination in SWE-bench Verified: Identifying Buggy Files Without Reasoning .






