
In May 2024, our team of 15 engineers at Vellum shipped 946 PRs. By October, we built a system leveraging coding agents to merge over 1,900 PRs.
Rather than adding more engineering headcount, we invested time into implementing coding agents into every engineering workflow. This resulted in 37% of our PRs now being initiated by background agents, helping our engineers ship faster than ever without sacrificing code quality.
Here's what we learned the hard way about making coding agents actually work.
Watch our webinar on coding agents with special guest Eashan from Cognition to get the full breakdown!
Rethinking the way we use coding tools
Six months before that May baseline, we were already experimenting with tools like Devin and Cursor. We struggled to get a single PR over the line. The tools felt promising but still not there yet.
Our breakthrough came when we redesigned how our engineering team approached work. These coding agents couldn’t remain as a passive tool that only work when we tell them to. So we made a system that embedded it into all our engineering process to start realizing speed and quality gains from coding agents.

Here’s how we run our stack of codings agents:
Foreground agents
Our engineers use foreground coding agents like Cursor, Claude Code, etc. when they want to stay in a tight feedback loop while actively writing code.
These tools fit naturally into existing workflows, so we don’t standardize on a single option. Each engineer will gravitate toward the agent that matches how they think and work, so in practice, comfort and fluency matter more than picking a single “best” tool.
💡 Good to know: Foreground agents amplify your clarity or your confusion because Foreground agents tend to mirror the engineer’s own working style. We’ve found they’re most effective when the engineer already has a clear mental model and uses the agent to move faster, instead to figure out what to do.
Background agents
Background agents are where we saw the biggest change in how work gets done. These are used by engineers to delegate a task or kick one off automatically and let it run independently until it opens a pull request.
This screenshot below shows our CTO sharing a p0 issue with our team. Then Vargas uses the Linear bot to create the ticket, and just pings Devin to resolve.
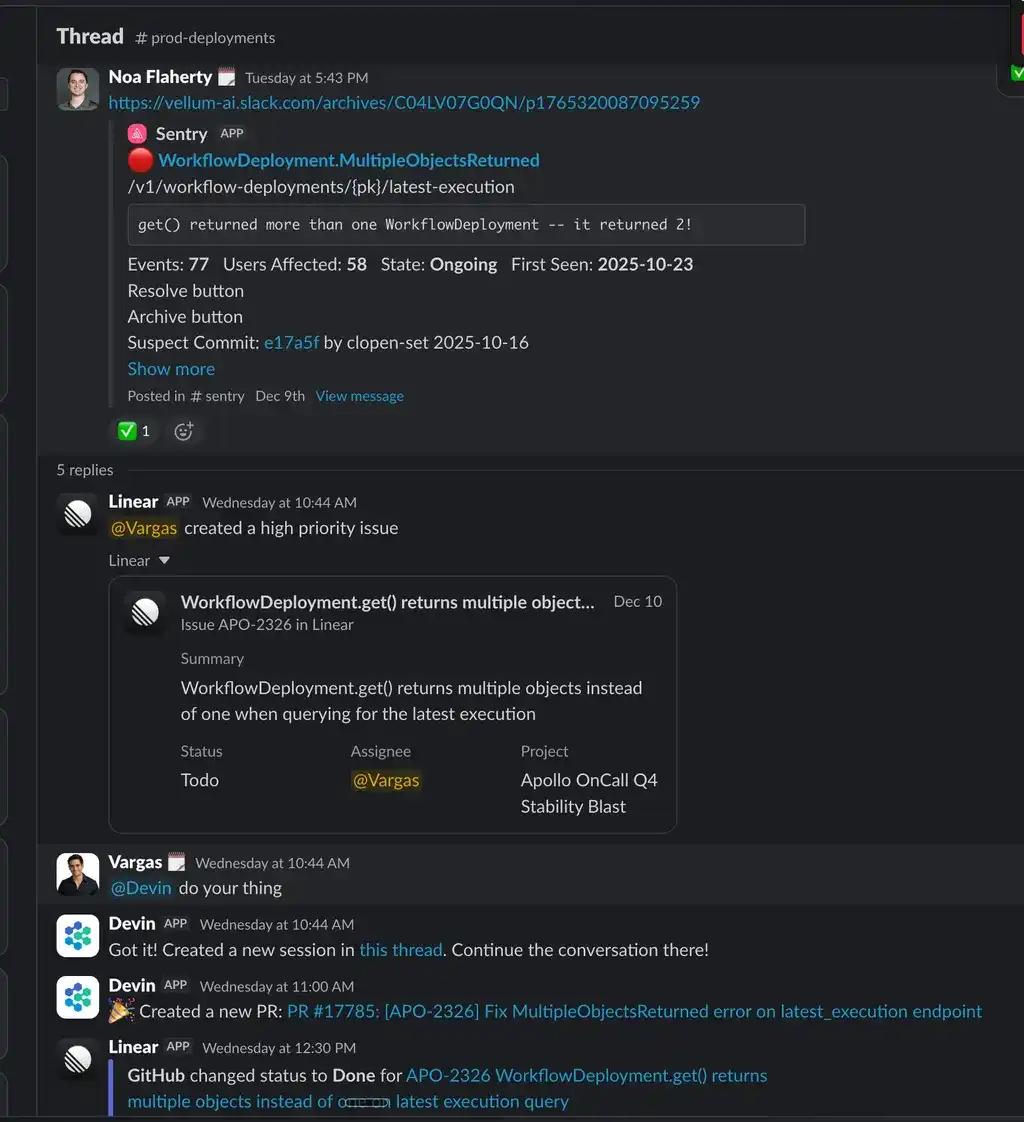
We primarily use background agents when we want to move multiple pieces of work forward in parallel. Engineers spend less time inside a single task and more time defining work, reviewing output, and deciding what to ship next.
💡 Good to know: Background agents work best when they are treated like a real contributor. We give them access to the same context our engineers use, wire them into our tools (Linear and Slack), and expect them to follow the same conventions as the rest of the team. Over time, this made it natural to hand off entire classes of work, including test writing and straightforward feature changes.
Code review agents
Code review agents are trustable and often times better than humans at code review because code review agents have complete context of your entire repo.
We use Codex as our main code review agent sitting at the front of our review process and acting as the first pass on almost every pull request, whether it was opened by a human or a background agent.
Their role is not to replace human review, but to shift what human review is for. Code review agents are especially good at catching issues that are easy for humans to miss, including problems that live outside the immediate diff or require broader repository context. Here’s an example from the other day:
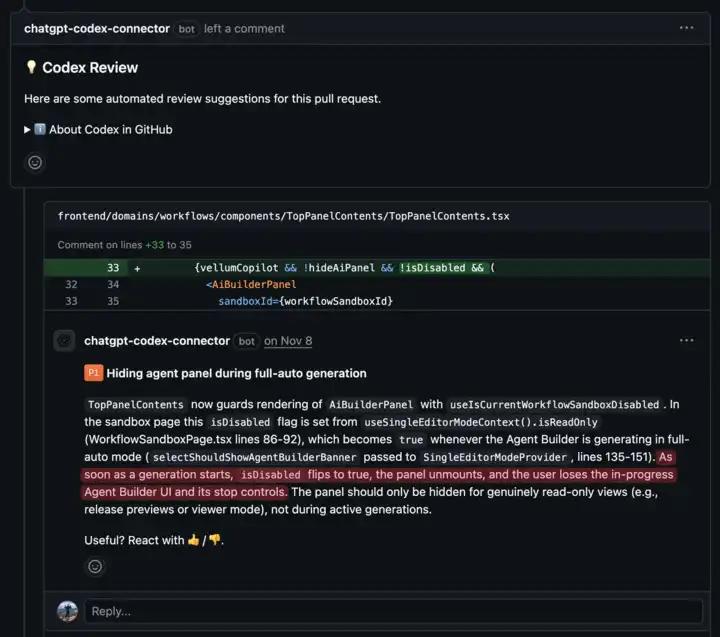
In another instance, Devin opened a simple copy change PR, and while the diff looked fine, Codex flagged a completely unrelated copy elsewhere in the codebase that should be updated as a result of the logical change. No human reviewer would have caught that because it wasn't in the diff, and you'd somehow need to remember some obscure copy three folders away to do so.
Code review agents have fundamentally changed how we do code reviews. Codex reviews first, catches the bugs, then humans review post-merge for context sharing and pattern consistency. No more waiting on human reviews for every PR.
As a result of eliminating this velocity bottleneck, we’ve enabled our engineers to 2x the amount of PRs we shipped from May (946) to October (1910).
💡 Good to know: Code review agents work best when they are intentionally separated from the agent that wrote the code. Treating authorship and review as two independent agents creates a real checks-and-balances system and avoids the subtle bias where an agent implicitly trusts its own work. In practice, this is what makes agent-written PRs safe to merge quickly.
Optimizing for parallelizing work & mindset shift
Traditional engineering looks very linear. Usually, an engineer picks up a ticket, enters flow state, grinds on it for hours or days, opens a PR, wait for review, merge, and repeat. The goal with coding agents, however, is to optimize the number of units of work you can run in parallel at once.
So while you’re in deep focus on a complex fix or project, background agents can be working on multiple PRs simultaneously. Using this objective as our north star, we started to build the processes we needed to parallelize some of our engineering work.
But before all of this happens, we needed to prepare our engineering team for a mindset shift geared for context switching; treating their attention as a coordination layer rather than an execution layer.
Obsessing over the logs
We made huge improvements on our coding agents from one hour of looking at end-to-end execution traces than from a week of theorizing about why something didn't work.
When an agent fails, our temptation was to debate prompt structures, model choices, and agentic logic. We did this constantly at first. Turns out, it’s a total waste of time.
We found real traction in our coding agents output when we started to obsess about reviewing our logs . As a matter of fact, storage is cheap, and tokens are not, so it made sense to just save everything in a database. With this our agent turned from a black box into a more deterministic system you can analyze and improve off of.
This applies to human work too. We review post-merge PRs primarily for context sharing now, and leave the bug catching to our code review agents.
Invest in your agent's machine
If you want background agents to work, you need to build a proper development environment for them.
The single highest-leverage thing we did was invest in Devin's machine setup. We created one-line commands for everything: make lint , make up , make test . Before coding agents, we had multi-step processes scattered across READMEs and tribal knowledge that made linting alone require running commands across our backend, frontend, and multiple microservices.
Using coding agents forced us to consolidate and standardize, which as a side effect made our human engineers more productive too. Better tooling for agents is better tooling for everyone.
We also set up a root .envrc file with all the credentials an agent needs like Linear API keys, test user accounts, environment variables. We created a user account called devin@vellum.ai so our agents can log into our app and QA their own work.
This might sound like overkill for some, but it was a necessity for us, otherwise agents would constantly ask you for credentials or failing mysteriously because they can't access something they need.
Foreground agents are still necessary
I don't want to give the impression that background agents are always the answer. They're not.
Foreground agents are still incredibly useful for:
UI work where you want instant feedback. Tweaking styling and seeing changes immediately is still faster with a foreground agent. Prototyping and R&D. When you're not sure what the approach should even be, tight iteration cycles help you explore the solution space. Deep, complex problems requiring handholding. Sometimes the agent needs your brain in the loop to push forward.
As Eashan from Cognition put it: "If there's a task I'm very confident the agent could accomplish with a simple prompt, I go straight to Devin. Otherwise, I start in Windsurf [a foreground agent], build up context, and then hand it off to Devin once I'm confident it knows what to do."
The key is knowing which tool fits which job.
The required infra for executing coding agents tooling
Let me be specific about the infrastructure we built to make this work:
- Preview Environments for Every PR
We automatically spin up a full staging environment for every PR. This is critical for QA'ing agent-generated PRs without pulling code locally. It also works on mobile, which is huge for UI changes.
- One-Command Local Setup
We built a single make up command that:
Starts all Docker dependencies Runs database migrations Pulls prod configs into local DB Spins up all dev servers in parallel
Before this, getting our local environment running was a nightmare of open terminal tabs and tribal knowledge. Now an agent (or a new engineer) can get up and running in one command.
- Context Engineering Scripts
We wrote management commands that agents can call to fetch context they need. For example, a command to pull full Linear ticket details, even when working in a different repo than where the command lives.
(Side note: Cognition has since built native Linear and Slack integrations, plus an MCP marketplace, which would probably handle a lot of this now. But the principle stands, give your agents the tools to fetch context.)
- Standardized Testing Commands
make test runs our entire test suite across all services. Sounds basic, but having one command the agent can rely on is huge.
What we’re still figuring out
We're not claiming to have this all solved. Two big challenges we're actively working on:
Priority Management
When you have five agents working in parallel, how do you ensure they're working on the right things? We experimented with having an agent autonomously pick tickets from our backlog once a day. It worked, but created a review bottleneck where suddenly we had PRs for random refactors competing for attention with critical feature work.
We haven't cracked this yet. Right now, humans are still the priority queue.
Human Review Bottlenecks
Even with code review agents, humans are still the final quality gate. For UI work especially, someone needs to look at it and confirm it matches our standards. When you're opening 10 agent PRs a day, that review time adds up.
We're exploring ways to have agents self-QA more thoroughly before opening PRs, but it's still a work in progress.
How to start with coding agents?
If you're convinced and want to try this at your engineering team, here's what I'd recommend:
Start with foreground agents. Get your team comfortable with AI pair programming first. This is low-risk and doesn't require much infrastructure investment. Prove value, then invest. Once you've seen the productivity gains from foreground agents, make the case for investing in background agent infrastructure. Build the one-line commands. Standardize your repo interfaces. make lint , make test , make up . Do this before you even try background agents—it'll make your human engineers happier too. Set up preview environments. You need a way to QA agent work without pulling it locally. This is non-negotiable. Start with low-risk tasks. Have agents write tests, fix linter errors, update documentation. Build trust before handing them feature work. Look at the logs. When things go wrong (and they will), resist the urge to theorize. Pull up the execution trace and see exactly what the agent did. Embrace the behavior change. Parallelizing work feels weird at first. You'll feel scattered. Push through it. The productivity gains are worth it.
The future is weirder than you think
Eashan shared something that stuck with me:
I never write my own tests anymore. Background agents just handle all that for me.
Think about that for a second. A engineer at the company building Devin doesn't write tests anymore. That's how fast this is moving.
We're seeing the same thing. More and more of our engineers are becoming coordinators and quality gates rather than code writers. We're spawning work, reviewing output, and shipping, while the actual coding is increasingly done by agents.
Earlier this year it felt like some far-off future, but this is happening right now at companies like ours. The gap between teams that figure this out and teams that don't is going to be massive in 2026.
If you haven't looked at background coding agents in the last six months, it's time. The tools have gotten dramatically better. But more importantly, the playbooks for actually using them are starting to emerge.
We're still early, still figuring this out, and we're shipping twice as much code with the same team. Imagine when the velocity when we perfect this system.
That's not the AI hype you’re used to hearing, it’s just what our logs show.
{{general-cta}}





