Welcome to another Vellum Product Update! This one’s a big one 😎 We pushed hard to bring major improvements to LLM Eval (aka Test Suites), Workflows (aka Prompt Chaining), and support for a variety of new models.
Evaluations
Workflow Test Suites
Quantitative end-to-end testing of prompt chains has always been a nightmare at best, impossible at worst. But now, you can run Test Suites and perform evaluations against Vellum Workflow ! This powerful functionality helps ensure that your prompt chains meet certain evaluation criteria. You can see a full demo of this in action here .
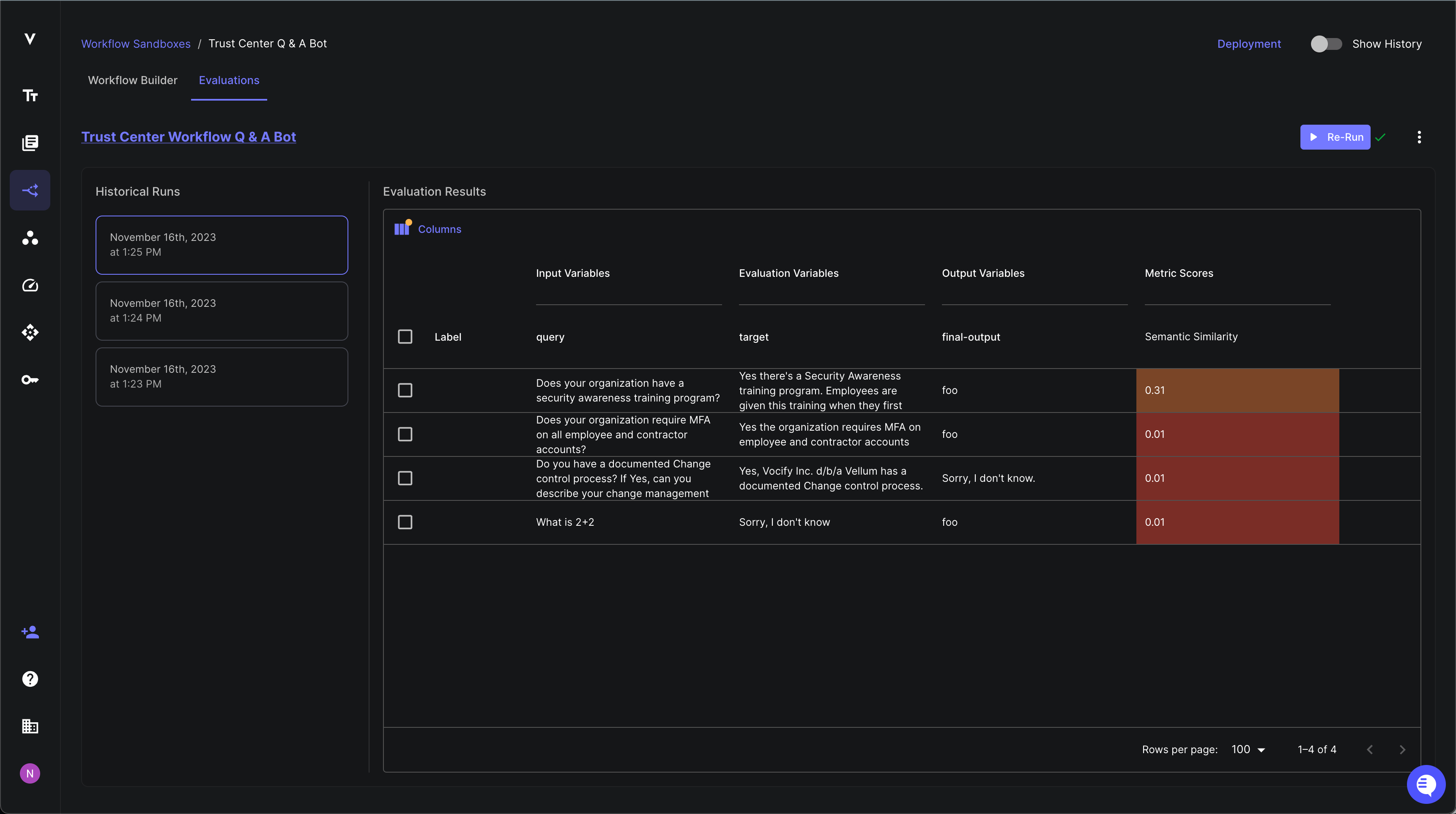
Code Eval Metric
We’ve seen our customers use Webhook Eval metrics to define all sorts of cool custom eval criteria. This works great and provides ultimate flexibility, but has the added overhead of needing to stand up an API endpoint. To alleviate this, we’ve added the ability for you to write your own custom python code directly from within Vellum to perform bespoke assertions in a Test Suite. When the Test Suite is run, the code is securely executed on Vellum’s backend and the metrics your code produces are shown in the UI.
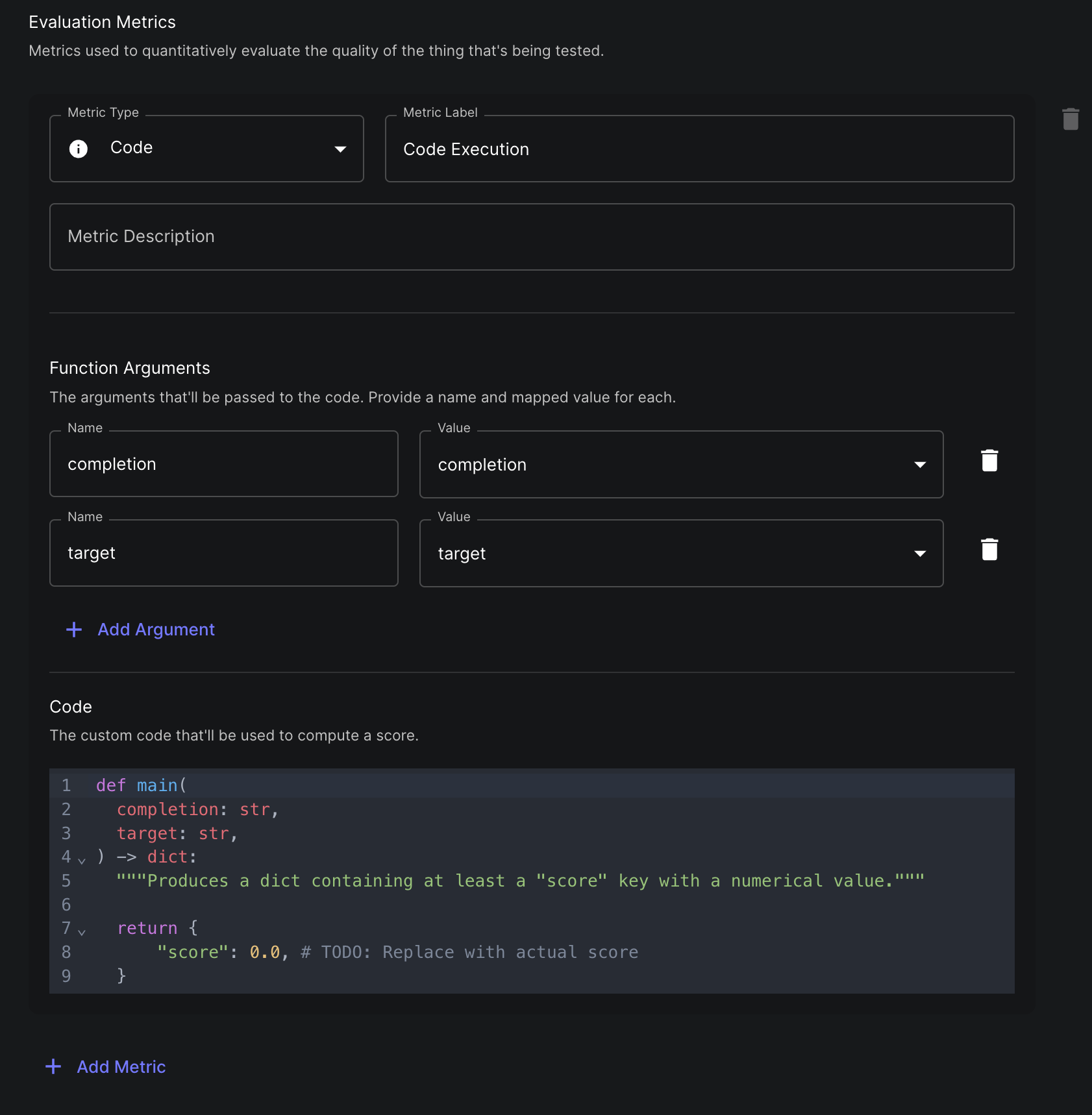
Workflow Eval Metric
Now we’re gonna get meta… You can now use a Vellum Workflow as an evaluator for another Prompt/Workflow. This means you can construct a Workflow that calls an LLM and use it to score another LLM. This is particularly useful if you want to evaluate against subjective metrics like “helpfulness” or “politeness.” LLM-based eval is something we’re very bullish on – we’ve already seen some amazing usages of this and are excited to see what you come up with! You can learn more about this powerful feature here .
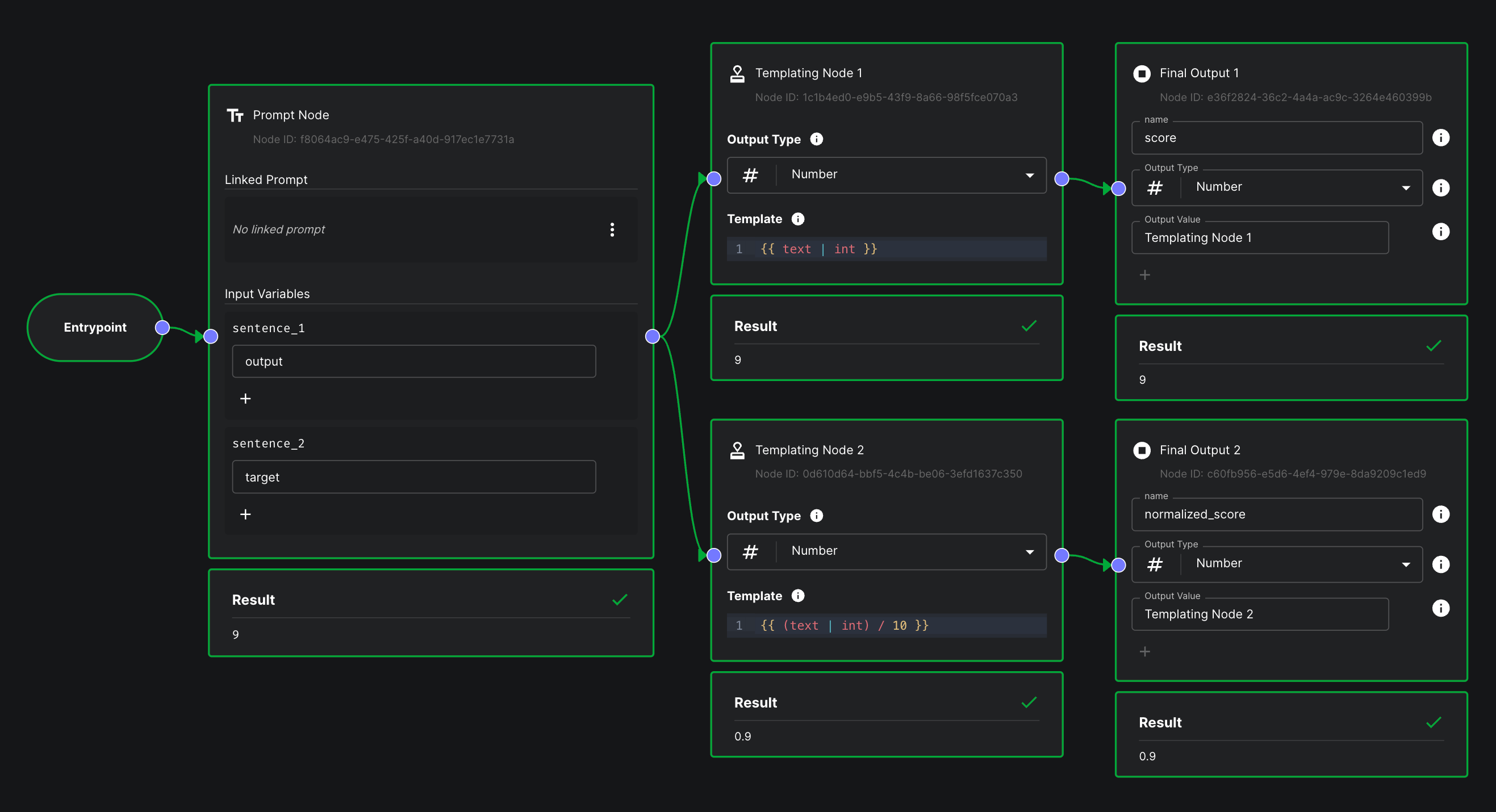
Multi-Metric Eval
Now that you can define custom evaluators via Workflow Metrics and Code Metrics, it’s likely that you’ll want to judge the output of a Prompt/Workflow across multiple dimensions. For example, maybe you want to check the output for a specific substring AND confirm it conforms to a JSON spec AND use an LLM to grade the output based on “politeness.” To achieve this, you can now configure a Test Suite to evaluate the output of a prompt across multiple evaluation metrics. Learn how to set this up here .

Metric Names & Descriptions
With the introduction of multiple metrics and new custom evaluators, it’s become more important to make clear what each metric represents. To address this, we’ve added the ability to provide custom names and descriptions for the metrics you define in a Test Suite. These names are then shown wherever the Test Suite is run, and the description is used as help text.

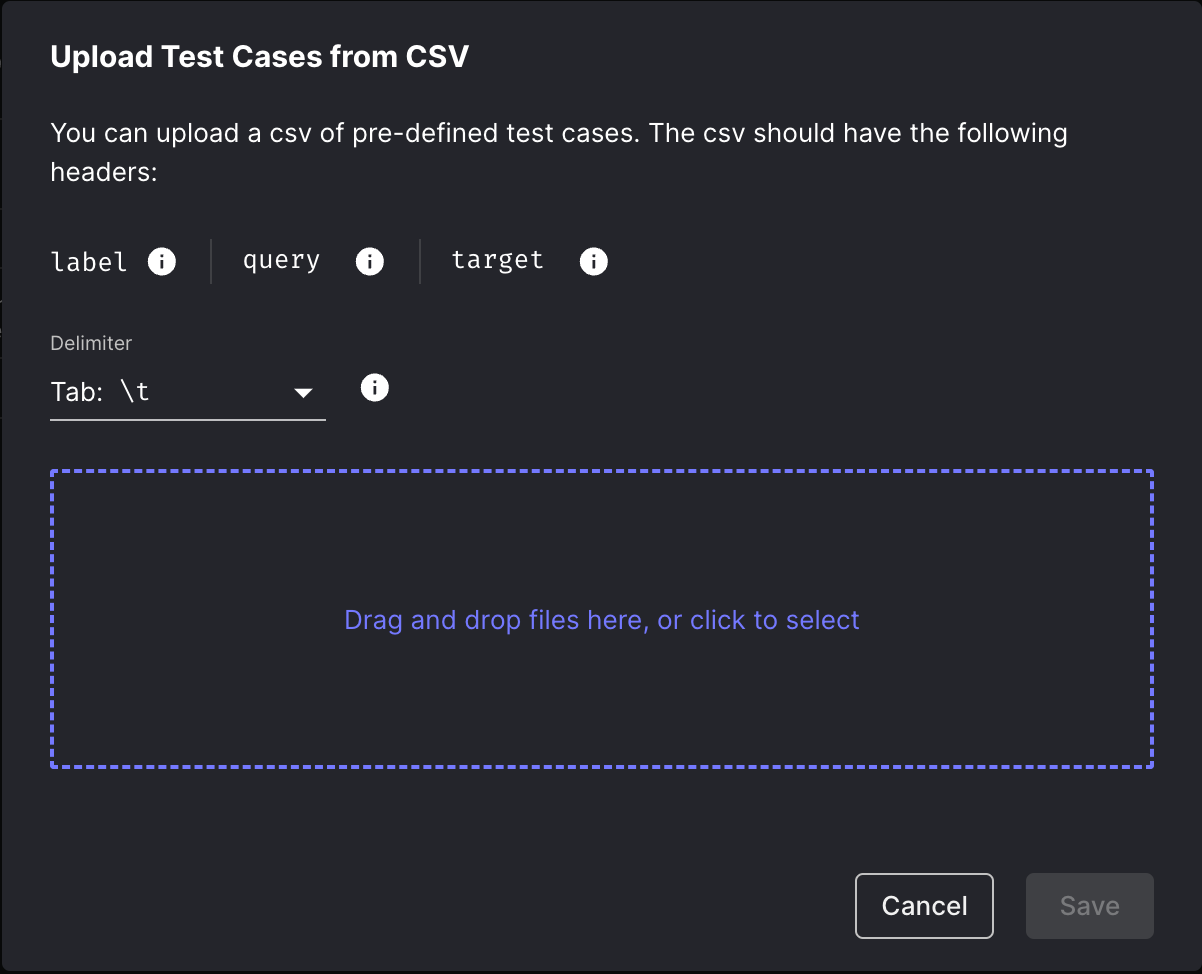
Upload Test Cases Via .tsv Files
Hate commas but love tabs? You can now define Test Cases within a Test Suite by uploading tab-separated (.tsv) files.
Workflows
Code Nodes
Templating Nodes have allowed you to perform basic data transformations via Jinja 2 templating syntax for some time now. While flexible, nothing beats good ol’ fashioned code. For those that want ultimate flexibility, you can now run arbitrary python code securely from within a Vellum Workflow as part of the new “Code Execution Node."

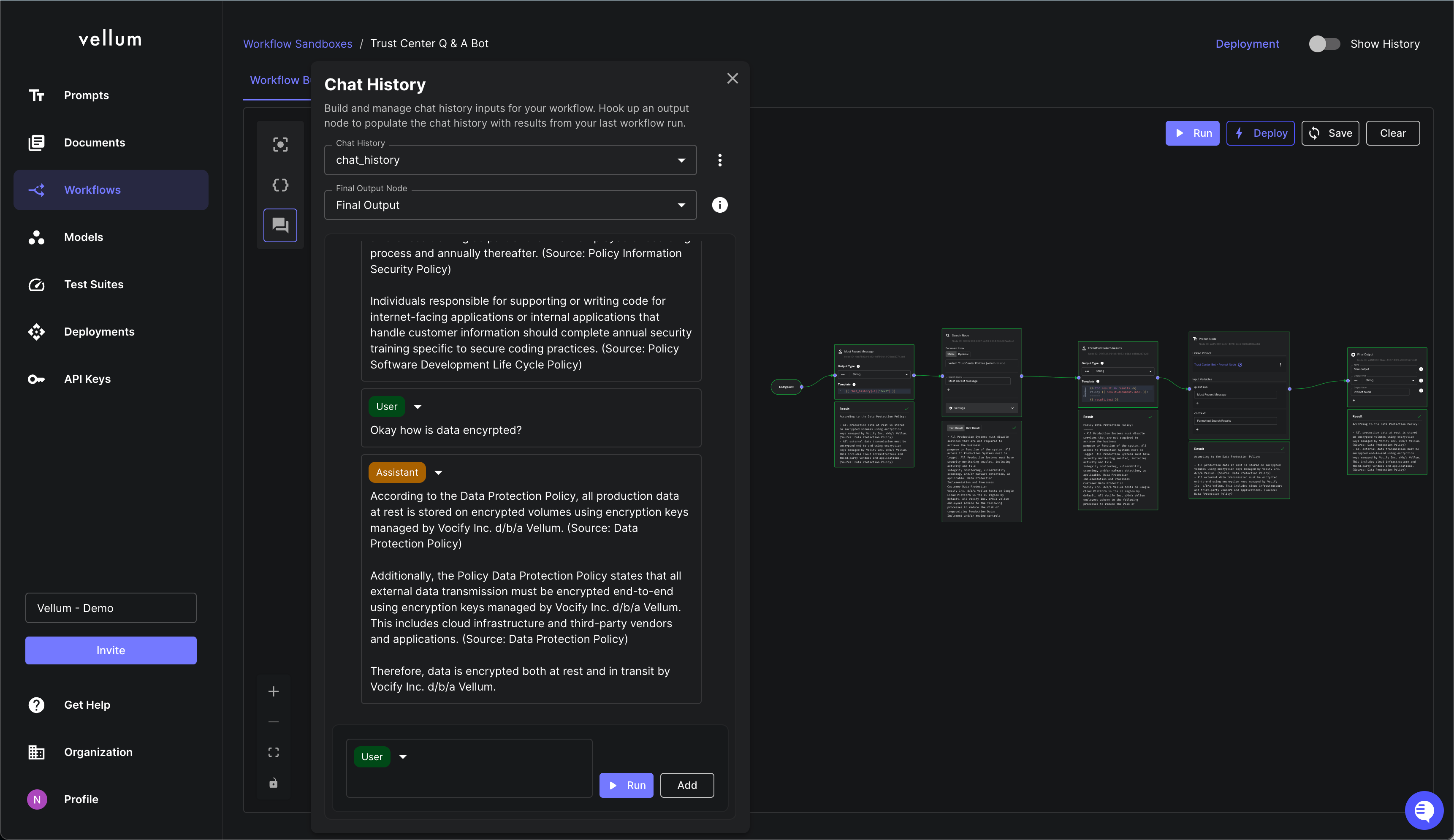
Chat Widget
There’s a whole new panel dedicated to testing chat-based Workflows. It’s now far smoother to simulate the interaction between an end-user and your AI-powered Workflow. You can see a full demo of this in action here .
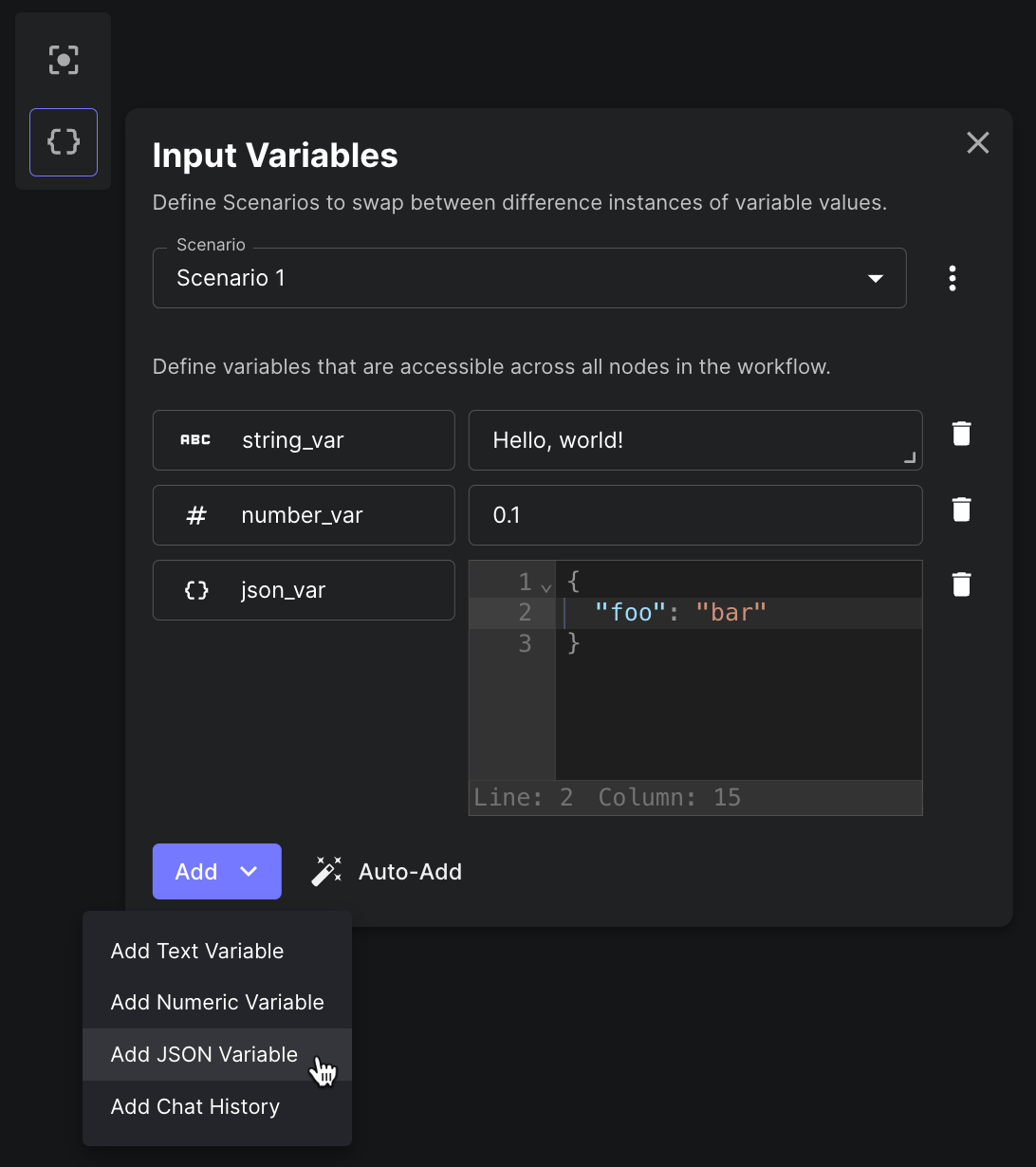
Support for Numerical & JSON Inputs
It’s now possible to provide numerical and JSON values as inputs to a Workflow.
Looping Support
You can now perform loops in a Workflow. Looping is often used in conjunction with a Conditional Node that checks to see if a prompt has been executed a specific number of times and if so, exiting the loop.
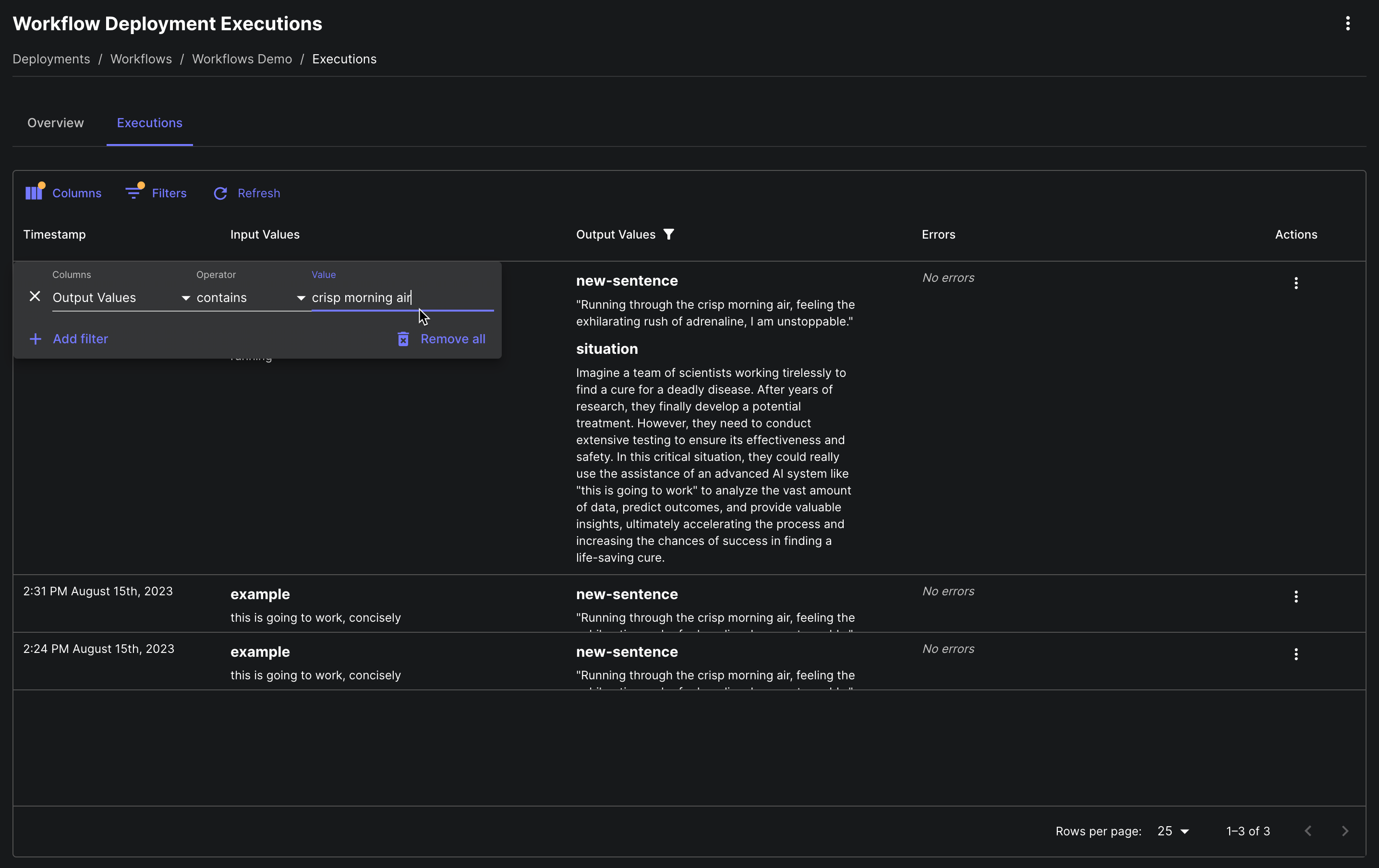
Search Across Workflow Deployment Executions
Archiving/Unarchiving Workflow Sandboxes
Don’t need a Workflow anymore but want to keep it around just in case? You can now archive/unarchive Workflow Sandboxes (and also prompt Sandboxes!)

First-Class Model Support
OpenChat 3.5 on Replicate
You can now use the open-source OpenChat 3.5 model directly within Vellum, hosted by Replicate . This is an exceptional model and is on-par with ChatGPT for many chat-based use cases. Give it a try!
Claude 2.1
We now support the use of Anthropic’s new Claude 2.1 model. This model features a 200k context window and 2x decrease in hallucinations. With the release of this model, Anthropic now supports System messages (already supported within Vellum) and the use of tools/function-calling in beta (support will soon be added to Vellum).
New OpenAI Models
OpenAI released 3 exciting new models, all of which are available within Vellum: gpt-3.5-turbo-1106, gpt-4-1106-preview, gpt-4-vision-preview. Note that models in preview will change and should not yet be used in production! First-class support for new OpenAI features such as JSON Mode and the ability to add images are coming soon.
Custom Model Support

OpenAI on Azure
You can now use OpenAI models hosted within your own Microsoft Azure account securely from within Vellum. You can go to the Models page to configure the integration.
Fine-Tuned OpenAI Models
You can now add fine-tuned OpenAI models to Vellum directly through the UI such that you can then use these models throughout Vellum. You can go to the Models page to configure the integration.
Claude on Bedrock
You can now use Claude models hosted within your own AWS Bedrock account securely from within Vellum. You can go to the Models page for instructions and configuration.
And That’s a Wrap
It’s been a busy November but we have no intentions of slowing down going into December. It’s likely you’ll see even deeper improvements to Workflows, Test Suites, and more! Thanks to all of our customers who have pushed us to move fast and ship the tools they need to productionize their AI use-cases. Keep the feedback coming!
https://discord.gg/6NqSBUxF78
See you next month!