
After extensive unit testing & finding the right prompt across model providers, you’ve finally brought your prompts into production. Your users are interacting with it and experiencing the magical UX you hoped to create. However, given the non-deterministic nature of responses generated by LLMs, it’s a good idea to keep an eye on how the prompt is performing in production.
Vellum has seen more than a million LLM requests made through our endpoints and in this blog post, we’ll share successful approaches we’ve seen our customers take to monitor and improve their prompts in production.
Monitoring production traffic
The observability layer for LLMs is being defined in the industry as we speak, but here are some metrics we’ve seen to be quite valuable to our customers:
Completion quality: Was the model generated response of good quality? Completion latency: How long did the response take to generate? Number of provider errors: How frequently was there an error because of the model provider? Cost: How much did you end up spending with model providers?
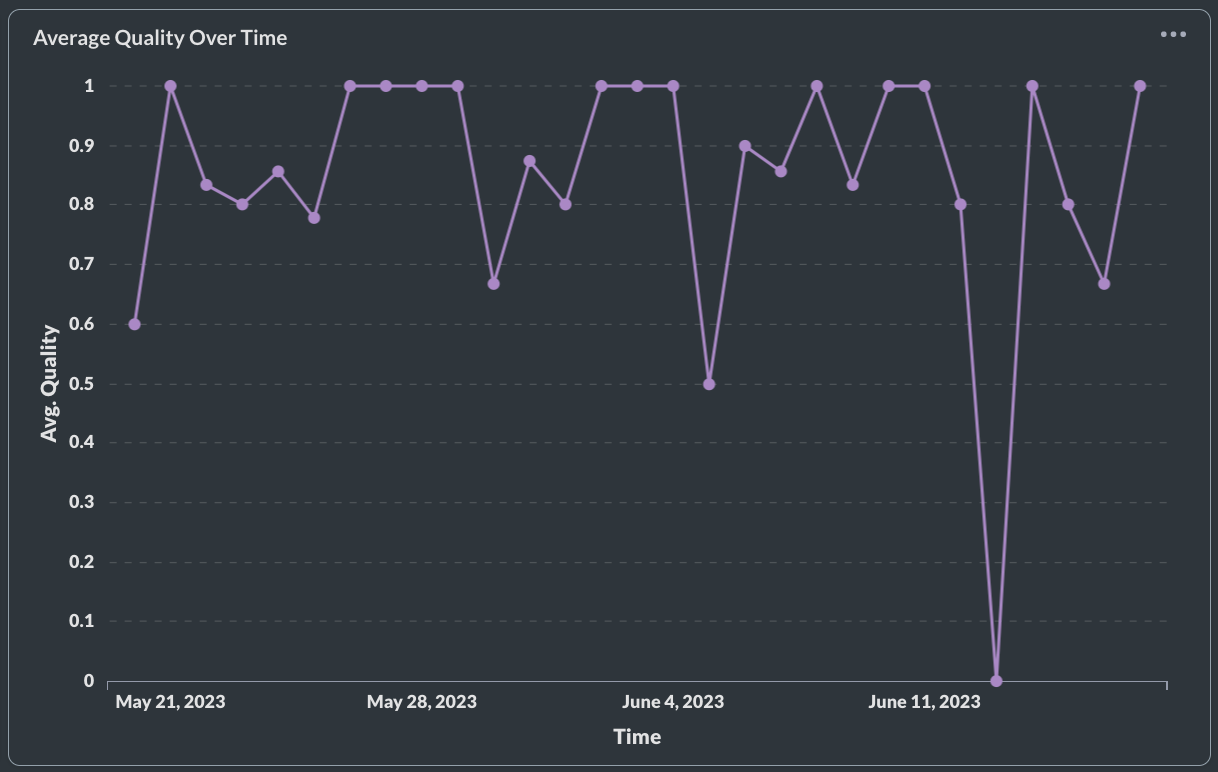
LLM completion quality
As outlined in our blog here , user feedback is the ultimate source of truth for model quality. Explicit feedback is collected through 👍 or 👎 in your UI, but may not have enough volume to measure overall quality. Implicit feedback is based on users' reactions to the LLM-generated output and can be a powerful gauge of quality. If explicit feedback collection rates are low, it is suggested to use implicit feedback when possible. You can also manually label completions generated by the LLM as good quality or not.
If your average quality over time is low, here are some questions you should ask:
Have your user expectations from the prompt changed? Has your model been hallucinating? Does it need more examples to provide good responses? Is the unit test bank robust enough to cover edge cases in production?
You should examine the low quality completions and modify your prompts / apply fine-tuning to increase quality in production.
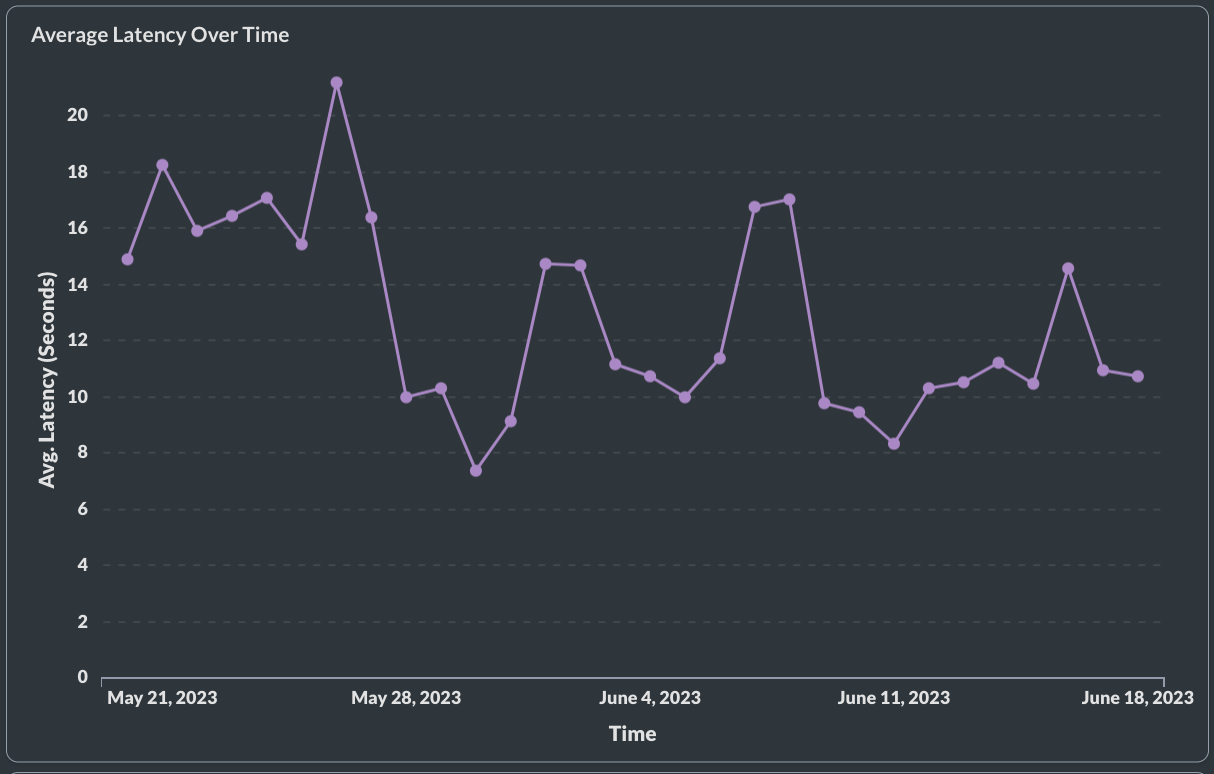
LLM completion latency
Maintaining low latency for your completions is important for a good user experience. As we’ve written in our blog with Activeloop here , latency is determined at the generated token level. When evaluating model latency, you should be looking at the time taken to generate the first token and the time taken for the full completion. If latency is a challenge you can start by streaming your responses in production (gives the perception of low latency), if it continues to be a problem we recommend exploring other providers or open source models.
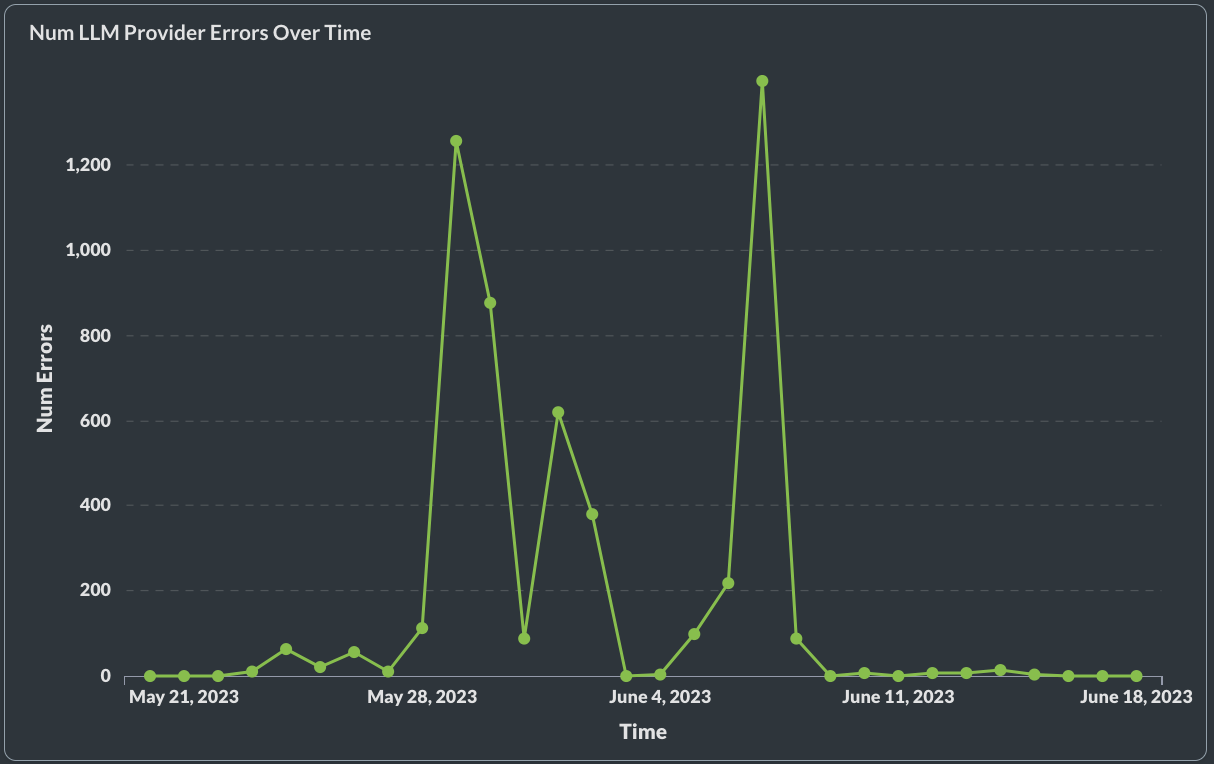
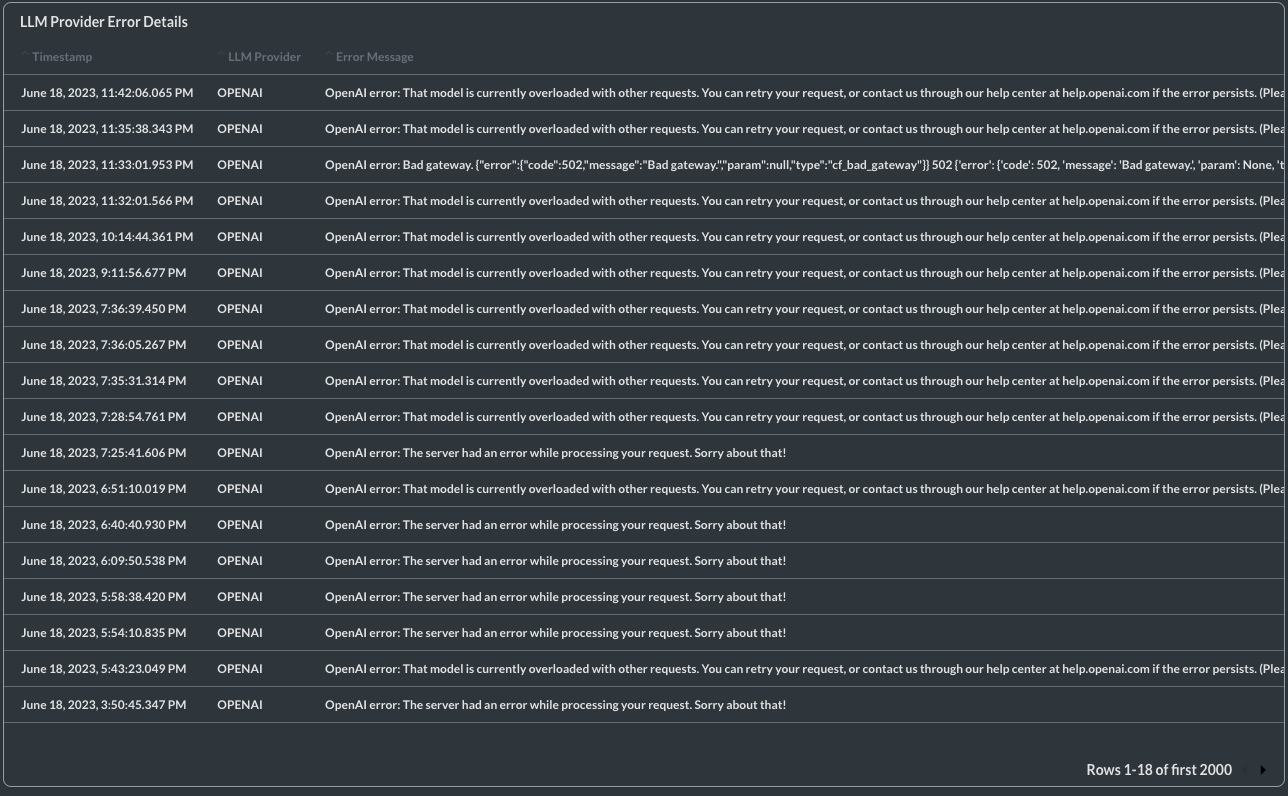
LLM provider errors
Tracking provider errors is another thing we’ve seen our customers do. Model providers could have some downtime which results in failed completions and ultimately a poor user experience. If you see too many provider errors in your application then it would be a good idea to implement provider retry logic, where if a request fails from one provider it could be routed to another one.
LLM costs
Finally, cost is important to measure and potentially control. We’ve seen costs for LLMs rise quickly, specially if there are some user segments that tend to use your LLM features quite a bit. Providers usually charge per token, so your total costs are a product of number of completions and tokens per prompt/completion. If costs need to be controlled then you should consider moving to cheaper models or fine tuning small open source models to provide similar results.
Tips to consider when changing prompts in production
Now that you have observability on your production traffic, you may occasionally want to make changes to improve quality, reliability or lower cost/latency. While making changes, there are several factors to consider, here’s a quick guide.
Regression testing to validate updates to prompts once in production: Make sure to run backtesting scripts when changing prompts in production, you don’t want to break any existing behavior! Back-testing is possible if you’re capturing the inputs/outputs of production requests. You can “replay” those inputs through your new prompt to see a before and after. Add edge cases noticed in production to your test bank: Your unit test bank shouldn’t be a static list. If you notice an input that produced an undesirable result in production, you should add it to your test bank! Each time you edit a prompt you should be able to make changes with confidence. When upgrading models (from GPT 3.5 to GPT 4, for example) or changing providers , you would need to change your prompt because the same prompt works differently on different foundation models. It’s best practice to pass all test cases each time a prompt is being sent to production Versioning prompts is important because if you modify a prompt and observe worse performance (either in quality, latency, costs or provider errors), you should be able to revert back to an old version immediately, ideally without too many code changes.
Need help with observability & changes in production?
As you can see, the internal tooling needed to observe the performance of your LLM powered features and making changes with confidence is non-trivial. Vellum’s platform for building production LLM application aims to solve just that. We provide the tooling layer to experiment with prompts and models, monitor them in production, and make changes with confidence if needed. If you’re interested, you can sign up here ! You can also subscribe to our blog and stay tuned for updates from us.





