To provide more insights on how Gemini Pro does with zero-shot vs few-shot prompting on classifying tasks, we decided to run an experiment.
We used Gemini Pro to classify if customer support ticket has been resolved or not.
Below, we share all our findings and observations.
The Classification task
We picked this task as customer conversations are hard to categorize, due to diverse speaking styles, subtle meanings, and often changing topics or tones.
For instance, if a vendor replies to a bug report by acknowledging that it’s a known issue, the ticket is considered resolved even though the bug isn’t. However, without the proper guidance, the language model may not always recognize this.
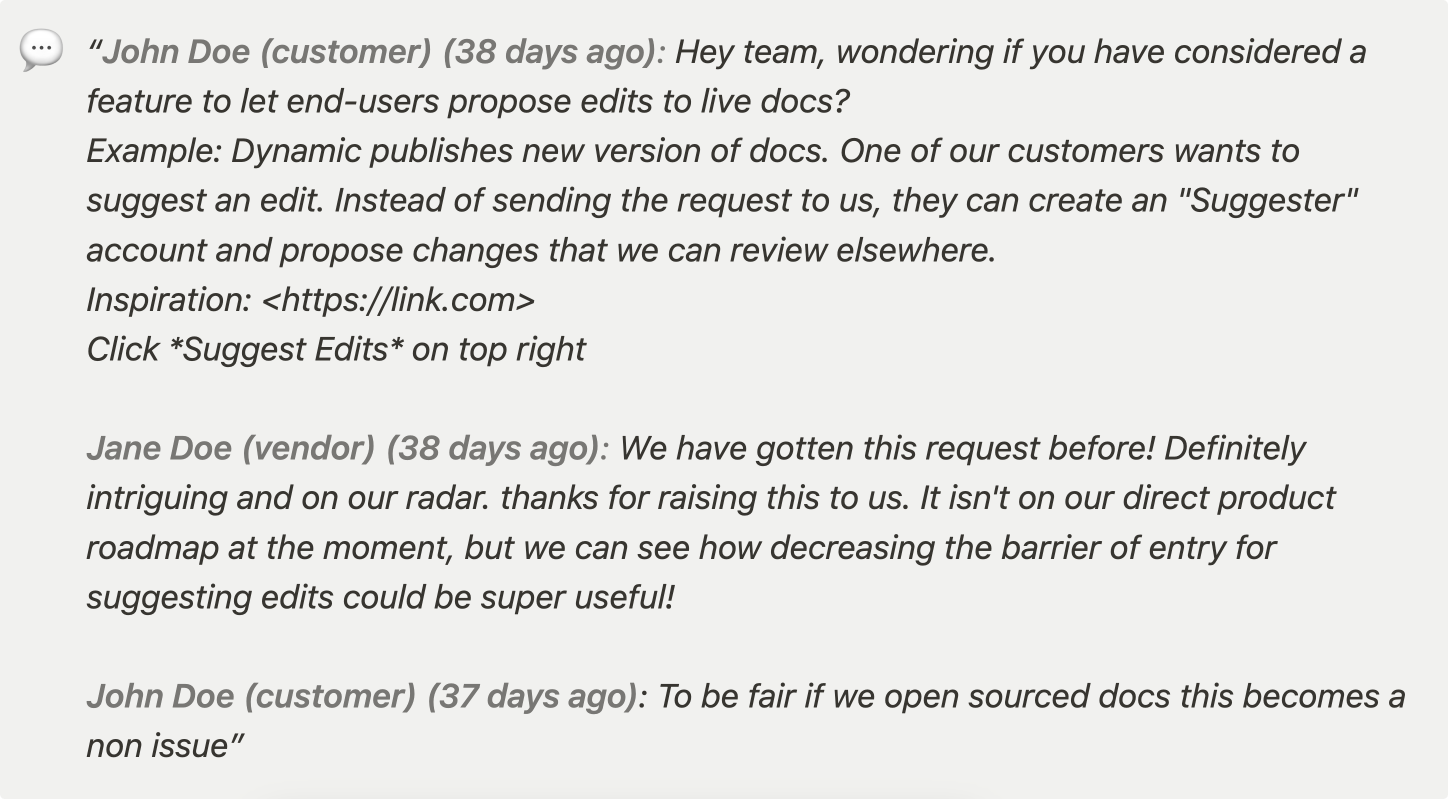
Here’s an example of such conversation, that’s marked as resolved:
Zero-shot vs few-shot
To assess the model's capabilities, we employed both zero-shot and few-shot techniques. Our goal was to analyze how few-shot prompting influences the outputs produced by Gemini Pro.
Evaluating Gemini Pro
We evaluated Gemini Pro, focusing on its accuracy, recall, and precision. This assessment involved 200 test cases and utilized both zero-shot and few-shot prompting techniques.
#### Results
Gemini Pro with zero-shot prompting had the best F1 score (77.94%) and Recall (94.64%) Gemini Pro with few-shot prompting had the best Accuracy(74%) and Precision (76.79%)
For this particular task, we wanted our model to be more conservative and capture all unresolved tickets, even if it meant tagging some resolved tickets as not resolved. To achieve this, we needed to choose a model with higher precision. In this case, Gemini Pro with few-shot prompting accomplished that for us.

By adding four examples to the prompt for few-shot prompting, we nearly halved the false positives, reducing them by 48% and increasing the precision to 76.79%.

Keep reading for more details on our methodology and the details of the experiment.
Methodology
Technical setup
For this comparison we used Vellum’s suite of features to manage various stages of the experiment. We used:
Prompt Sandbox: To compare zero-shot and few-shot prompts on the same model Test Suites: To evaluate hundreds of test cases in bulk and measure which cases fail
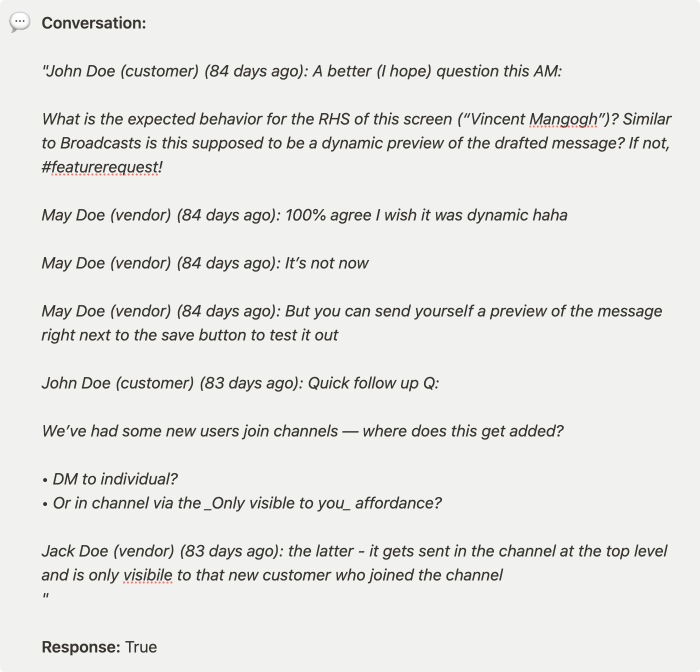
The dataset we used had 200 test cases. Here is an example:
Prompt engineering & techniques
Before testing the models, we experimented with different prompts to ensure that the model would only output "true" or "false" as answers, without adding any additional explanation.
Here’s a snapshot on how that looked like within Vellum:
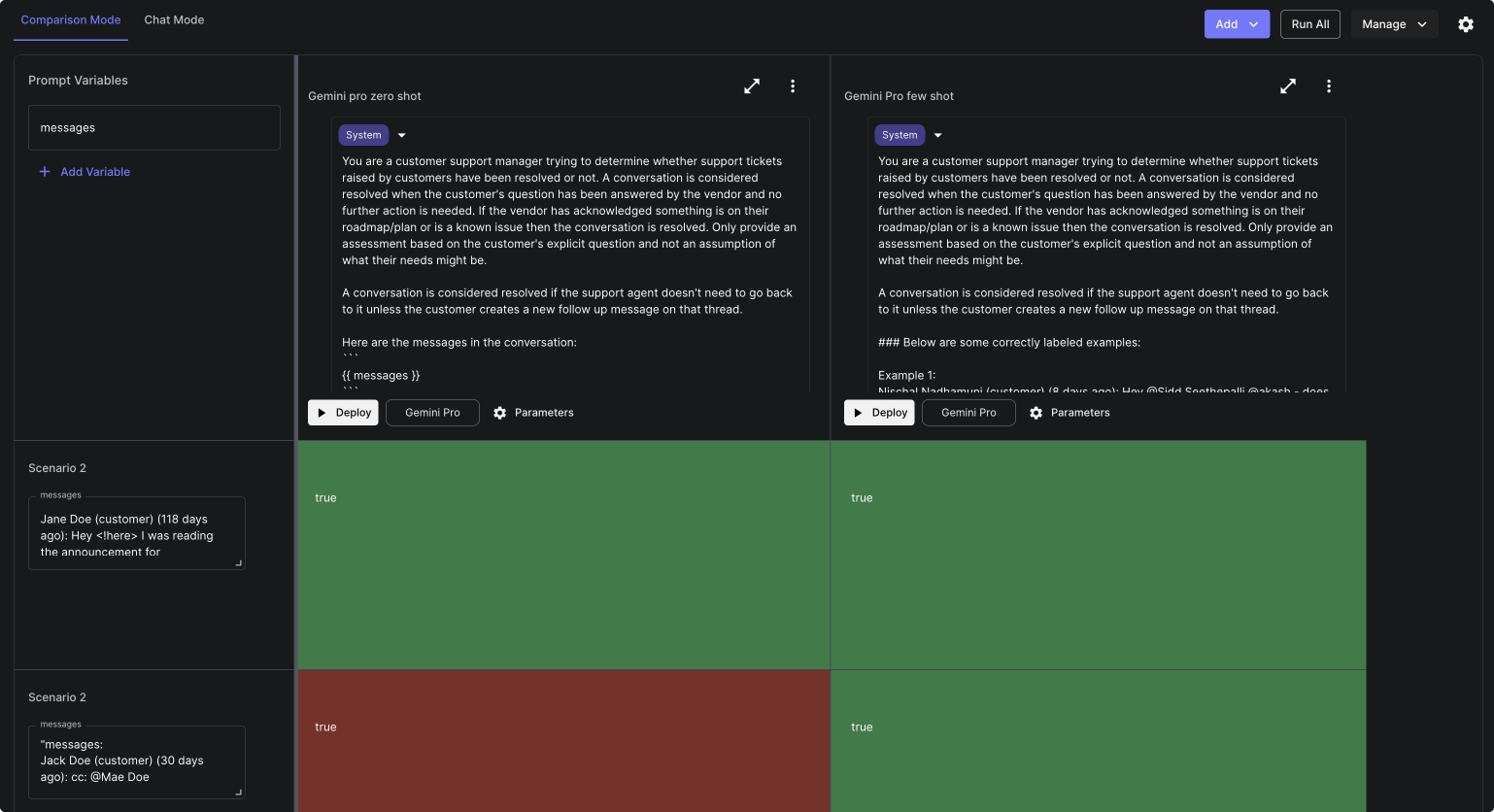
Once we were happy with the results, we were prepared to test the model on a larger set of cases.
In the zero-shot prompt we used the last N messages from a customer chat, instructions of what constitutes a resolved conversation, and a description of the expected answer format. In the few-shot case, the prompt had the same components, including examples of resolved conversations.
Note that the {{ messages }} tag is a variable that dynamically passes data within Vellum Prompt Sandboxes.
Model Information
We ran Gemini Pro with 0 temperature, and 10 token limit, because we wanted to get to a well defined answer.

Setting up the test cases
To evaluate the models, we uploaded Pylon's dataset into a Test Suite (which is our unit testing product for LLMs) and selected " Exact Match " as the metric for evaluation.
This evaluation metric verifies if the LLM's output perfectly matches the expected dataset output, considering any extra whitespaces the model might generate. Given that we anticipated either a "true" or "false" output, the evaluation process was straightforward.
Using Test Suites we were able to run all of these test cases at scale.
Running the evaluation
At this point we had our prompt configurations, and we were ready to run the prompt across our test cases.
We connected the Test Suite with our prompts and initiated the model runs. Here's what the setup looked like during the evaluation process:
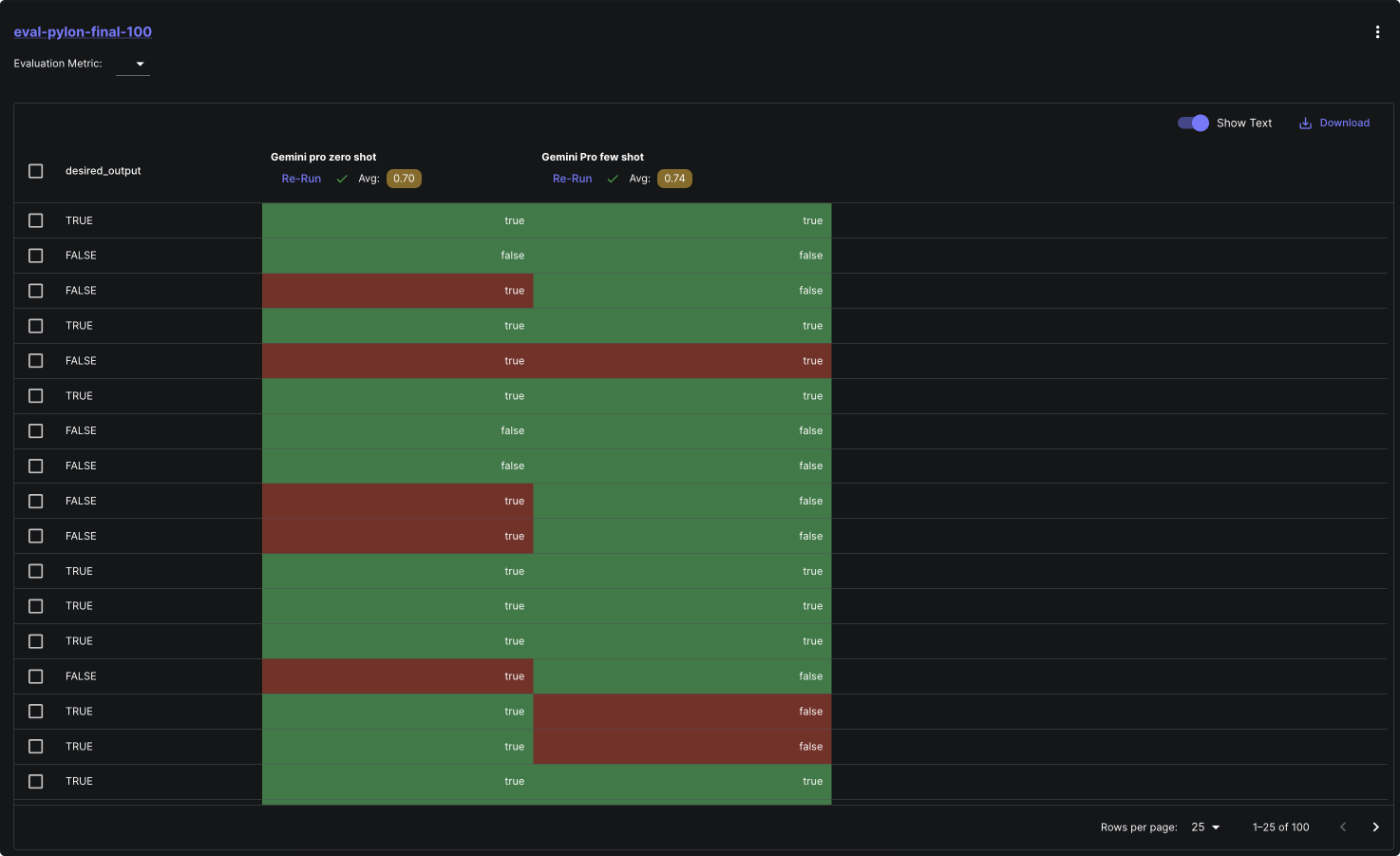
Measuring the results
For this experiment, given that it’s a classification task we compared Gemini Pro on three metrics: accuracy, recall and precision.
Here are the final results that we got:
Conclusions
With this experiment, we learned that Gemini Pro when used with few-shot prompting can improve precision and accuracy, which is very important for classification tasks.
If you’re looking to scale your customer support operations using LLMs and want to evaluate different models and prompt techniques, we can help.
Vellum has the tooling layer to experiment with prompts and models, evaluate their quality, and make changes with confidence once in production.
You can take a look at some of our other use-cases , or book a call to talk with someone from our team, and we’d be happy to assist you.