Did you know that LLMs can label data much faster and cheaper than human annotators?
Unlike older automatic data labeling methods, LLMs understand text much like we do, but with the speed of a machine.
In this post, we’ll explore automated data labeling with LLMs, which models work best for certain jobs, and the time and money it takes.
We'll also discuss how using the right prompt engineering methods can improve the outcomes, and we'll look at different examples of how this is used.
Before LLMs
Manual labeling: Slow & Manual process
Manual labeling is the process of assigning labels to each data point in a dataset.
Initially, the data labeling process was manual, slow and often costly. Some of the dataset have taken years of time to collect.
Then, scalable automated methods like programmatic labeling were introduced.
What is Pro grammatic labeling?
Programmatic labeling uses labeling functions, not individual labels, to quickly tag lots of data based on set rules.
For instance, if you're developing a model to identify fraudulent transactions, you'd use various data indicators such as transaction amount, geographic location, IP address, and frequency of transactions to create heuristics or "rules" that human annotators would typically follow. Once these "rules" are added in a labeling function, they can be applied to a large amount of unlabeled data.
According to Snorkel , a data labeling platform, programmatic labeling can accelerate the process by 10X.
However, this approach lacks the ability to handle complex or open-ended tasks that don’t fit well with the rules or models that you might set up.
So, how do we generalize the process without setting specific heuristics, yet make it scalable & cost/time efficient?
LLMs to the rescue.
Automatic data labeling with LLMs
While you can use LLMs to write a kids story, get an explanation on a complex topic, or hook them up in your product, recent report shows that LLMs can label datasets with similar or better quality to human annotators.
These models use huge amounts of data and algorithms to understand, interpret, and create text in natural language.
That capability makes them good at labeling data on their own, for various tasks, without needing domain experts to review the results (in most cases!)
And the results are impressive.
GPT-4 labels data better than humans
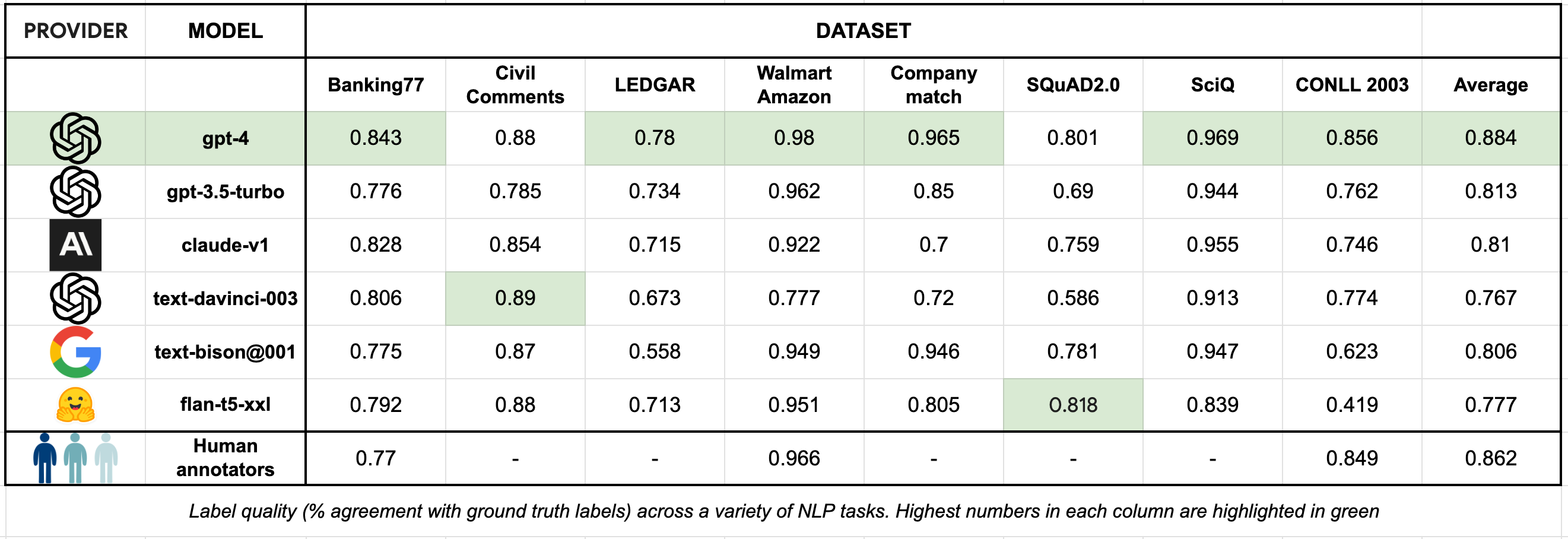
Recent report showed that GPT-4 can label data better than human annotators.
The goal of this report was to showcase how good language models (LLMs) and humans are at labeling data. They evaluated the results based on three things: if the label is right, how fast it's done, and how much it costs.
In regards to the quality of the labels the results showed that:
LLMs like GPT-4 often labeled better than human annotators. GPT-4 got 88.4% right, while human annotators got 86.2%. With some optimization techniques like analyzing the log probabilities of the model to estimate confidence in their answers they got GPT-4 to add the correct labels on 95% of the data on average across all the datasets they used. Other cheaper models (text-bison@001, gpt-3.5-turbo, claude-v1 and flan-t5-xxl) also did pretty well while priced at <1/10th the GPT-4 API cost.
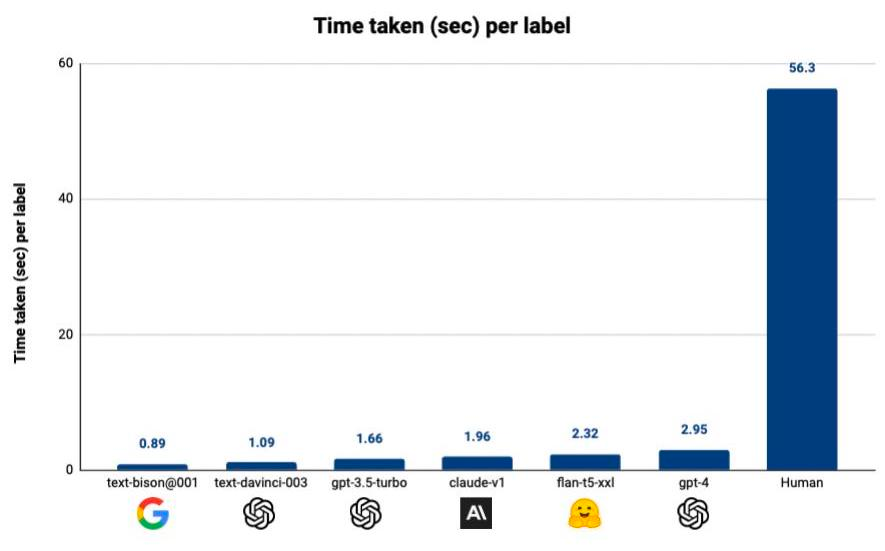
In regards to time and cost, they showed that:
GPT-4 is ~20x faster, and ~7x cheaper at labeling various datasets compared to human annotators. Multiple other models achieve strong performance while priced at <1/10th the GPT-4 API cost.
And if you want to get the best tradeoff between label quality and cost/time there are a few LLM choices that the report suggests:
text-bison@001 (Google) and gpt-3.5-turbo (OpenAI) are ~1/10th the cost of GPT-4 and do well on entity matching and question answering tasks. With the added flexibility of fine-tuning and self-hosting, Flan-T5 XXL is a powerful open source alternative for labeling NLP datasets at <1% of human labeling cost.
However, the Flan-T5 XXL is an old model. There are newer, powerful open-source LLMs like Falcon by TII, MPT by Mosaic and Dolly by Databricks, LLama 2 by Facebook, and Mistral AI that weren’t included in this study, but might get better results.
Vellum supports all of them, so you can test for yourself if you can get better results.
But you can also improve the labeling with prompt techniques.
Prompting techniques can enhance LLM labeling
There is one thing that LLMs are famous for. Their tendency towards hallucinations with a dash of over-confidence.
To mitigate these challenges and improve the label quality you can use in-context learning (few shot prompting) or chain of thought prompting to improve their performance. You can use these methods and show examples or “reasoning steps” on how to perform the labeling.
Below we show what automated data labeling with LLMs can look like.
LLM Automated Data Labeling Explained
Here are some steps on how you can experiment with automated data labeling with LLMs:
- Input Data & Instructions
You provide the LLM (let’s say we’re using GPT-4) with input data and instructions on how to perform the labeling.
You can provide this data within your prompt, depending on whether it fits in the context window of the selected model. In other cases, you can pull contextually relevant data and combine elements of both retrieval and generation techniques (RAG approach).
The instructions can take various forms, such as asking the model to categorize text, identify entities, generate descriptions, translate languages, or perform other labeling tasks. Within the instructions you can use prompt engineering techniques like few-shot or chain-of-thought prompting to improve the performance of the model.
- Labeling
The LLM analyzes the input data and follows the provided instructions to generate labels, annotations, or additional data.
- Storing
The labeled data can come from your own tests or from actual end-user completions.
Once the data is appropriately labeled, it can be used for various downstream tasks, such as training and evaluating models, improving search and recommendation systems, sentiment analysis, chatbots, and even fine-tuning your own open-source models.
- Iterating
The process will always be iterative, with continuous refinement of the LLM's performance based on evaluation. This helps enhance the accuracy and reliability of the automatic labeling.
Challenges with LLM data labeling
While the results are impressive, there are still some challenges with LLM data labeling that need to be addressed.
- Bias
From their technical report GPT-4 has various biases in its outputs that can be corrected, but it can take some time to characterize and manage.
- Jargon & Abbreviation if context is not given
LLMs can mixup slang terms, especially if it’s a new term that wasn’t in the corpus of data that the model was trained on. They can also misrepresent certain abbreviations if context is not added to the instruction.
You also need to check if the ToS of certain models allow you to use them for data labeling and fine-tuning.
Despite these challenges, there are many use-cases for data labeling where LLMs are quite useful.
Use-cases for Auto Data labeling with LLMs
The versatility of LLMs in handling various data labeling tasks is remarkable, and there are various use-cases where you can apply them.
Here are some examples:
- Text Classification
Text classification is about sorting text documents into already set classes or categories. LLMs can automatically label text data by analyzing its content and assigning it to the appropriate category.
For example, you can use an LLM to classify news articles into topics like sports, politics, or entertainment.
- Named Entity Recognition (NER)
NER is the process of identifying and classifying named entities (such as names of people, organizations, locations, etc.) within text. LLMs can automatically label text by recognizing and tagging these entities.
This is useful in applications like information extraction, content analysis, and chatbots.
- Sentiment Analysis
Sentiment analysis determines the emotional tone in a text, like if a product review is positive, negative, or neutral. LLMs can be used to automate sentiment labeling, making it easier to analyze large volumes of customer feedback, social media posts, and reviews.
- Question Answering
Question answering systems use LLMs to find and extract answers from a corpus of text. LLMs can be used to label questions and their corresponding answers in datasets, making it easier to train and evaluate question answering models.
Automatic data labeling with Vellum
Within Vellum, you can use LLMs to label your data in these three stages/features of the platform:
- Prototyping & Testing
This is when you’re experimenting and testing your prompts and selected models to then see if an LLM can successfully label your data. You can add various instructions (including prompt techniques) to test how different LLMs can label a set of data.
- Workflows
This is when you might have longer LLM chains where in the first step you’d have an external user interaction with the LLM, and then on the second step you’d like to classify the user’s response and perform a specific action.
- LLMs in production
Lastly, when you have an LLM in production, Vellums stores your end-user completions, and then you can use them to generate synthetic datasets for fine-tuning open source models.
Our users decide to fine-tune open source models to cut on costs, and avoid hitting rate limits.
LLM data labeling for code analysis tasks
One of our customers, Narya.AI had an interesting use-case where they tested ~50 prompts around code analysis, and deployed the best ones in production. Then used their user completions to create a synthetic database that was then utilized to fine-tune an open source model.
So if you’re building an AI App, you can use Vellum as a proxy to test different data labeling prompts, to set up longer LLM chains that can classify responses, or to log your data and help you create synthetic datasets.
If you want to experiment with any of these, feel free to book a demo with us, or contact us at support@vellum.ai and we’ll be happy to help you with your LLM setup.