
Prompt Organization with Folders
Up until now, managing and organizing your prompts has been a bit messy. You would update them, they'd go live immediately to end-users, but there was no direct way to neatly categorize or group them together for easy access or tracking.
Well, not anymore! We're thrilled to introduce our new feature - Folders !
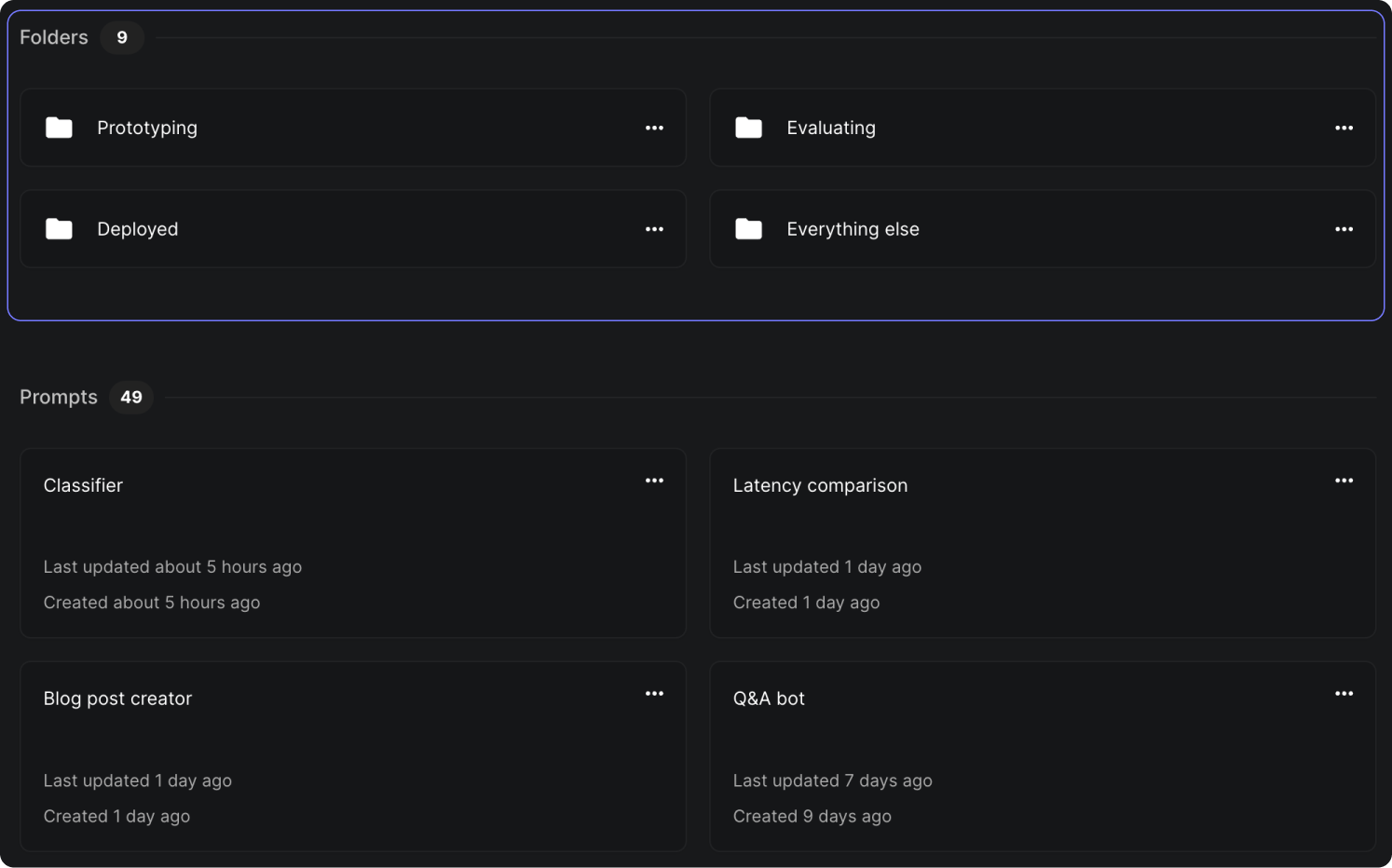
Now you can create folders and organize all your prompts however it suits best for your project needs. It doesn't stop at just one level; you can also nest folders within each other for an even finer grade of organization.
As if this wasn’t enough already — you can share your prompt with unique URL links which will remain stable regardless of how many times a prompt moves around across different folders within its path.
See the full demo here .
Prompt Deployment Usage Tracking
Until recently, you had to check your OpenAI logs to estimate token utilization for your deployed prompts.
Now, you can keep track of the token utilization for each of your Prompt Deployments directly in Vellum! This new feature provides detailed information on input tokens, output tokens and total tokens used per request.
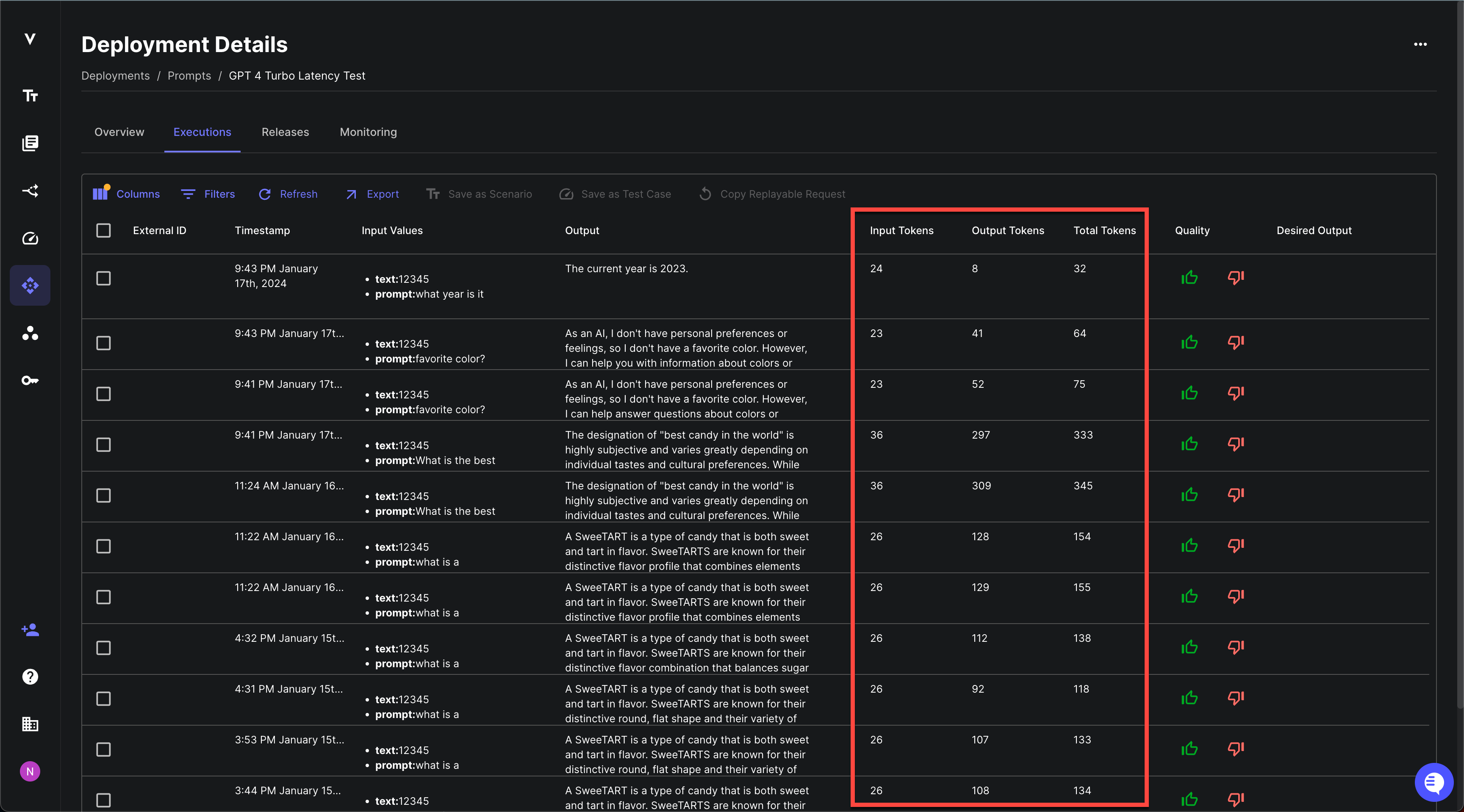
This gives you better control over how your Prompts are being utilized and helps optimize their performance based on accurate usage data.
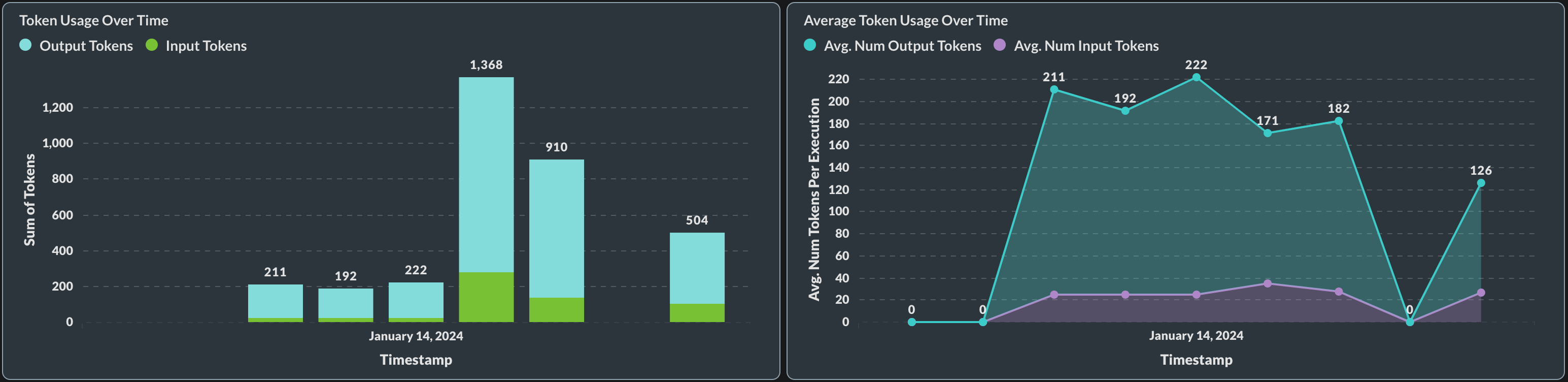
Plus it's not just about individual requests; with this update comes aggregate data viewable in our Monitoring tab too!
Single Editor Mode
Previously, whenever you and your team were working on a Prompt or Workflow in the Sandbox environment, there was a potential for overlap and unintentional changes being saved. Multiple users could edit the same Prompt/Workflow simultaneously without any restrictions.
We're excited to announce that we've partnered with velt.dev to deliver an all new "Single Editor Mode" in Prompt and Workflow Sandboxes! Now, only one person can edit a Prompt/Workflow at a time. You can hand over the editing power to someone else when needed.
This change is crucial as it eliminates confusion that may arise when multiple collaborators are trying to make changes concurrently - an all-too-common scenario in collaborative development environments.
To see how Single Editor Mode works in real-time action, watch our full demo .
Support For Three New OpenAI API Parameter
We've added support for three new parameters in the OpenAI API, which you can easily adjust in the Model configuration window:
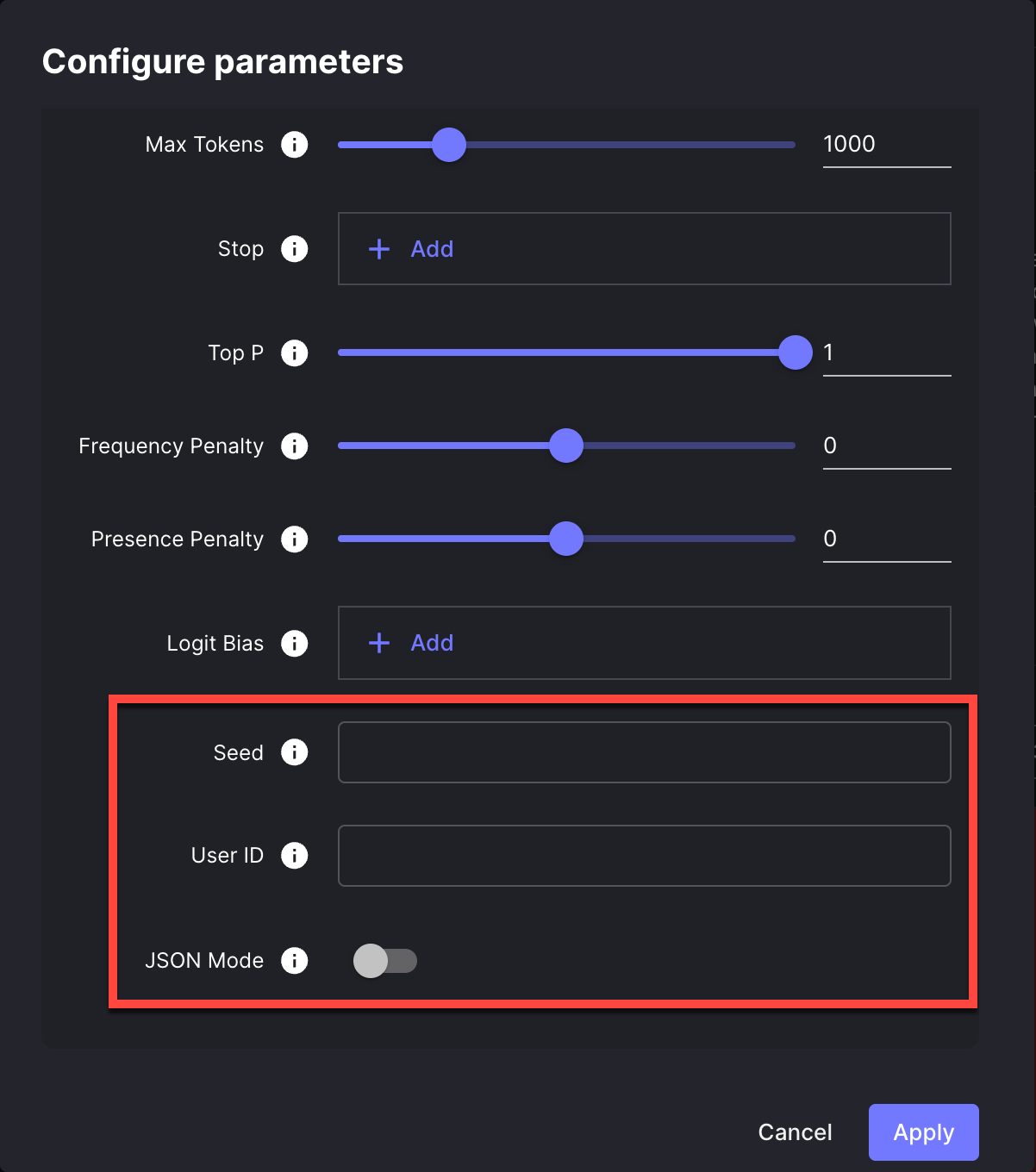
Reproducible Outputs
Whenever you used OpenAI's API requests, the result was an output that could vary each time the same request was made. This lack of consistency may have introduced some unpredictability into your workflow and perhaps posed challenges for debugging or comprehensive unit testing.
Now, you can set the seed parameter directly in your OpenAI API requests, to receive (mostly) deterministic outputs across API calls. This will effectively give you far greater control over model behavior than ever before. You can read more about the seed parameter here .
JSON mode
You can now configure your OpenAI requests in Vellum to always produce valid JSON. By enabling this option in your model's settings, the model will be constrained to generate outputs that are syntactically correct JSON objects.
End-user IDs
Sending end-user IDs in your requests can be a useful tool to help OpenAI monitor and detect abuse. This allows OpenAI to provide your team with more actionable feedback in the event that we detect any policy violations in your application.
You can now add end-user IDs via the user parameter directly in your OpenAI API requests.
Image Support for OpenAI Vision Models
Vellum now has API support for interacting with OpenAI's vision models, such as gpt-4-vision-preview . Note that there is limited support for images in the Vellum UI at this time, but you can still use the API to interact with OpenAI Vision models. UI support is coming soon!
You can learn more about OpenAI Vision models here .
Here's a quick example on how to send an image to the model, using our python sdk:
// JavaScript code here image_link = "https://storage.googleapis.com/vellum-public/help-docs/add_prompt_block_button.png"; response = client.execute_prompt( prompt_deployment_name="github-loom-demo", inputs=[ PromptDeploymentInputRequest_ChatHistory( name="$chat_history", value=[ ChatMessageRequest( role=ChatMessageRole.USER, content={ "type": "ARRAY", "value": [ {"type": "STRING", "value": "What's in this image?"}, {"type": "IMAGE", "value": {"src": image_link}}, ], }, ) ], type=VellumVariableType.CHAT_HISTORY, ), ], ); print(response.outputs[0].value);
Upload/Download of Function Definitions
You can now import your existing function definition files (JSON or YAML) directly into Vellum's function calling blocks in various environments like Prompts, Workflows, and Deployments. This will save you a lot of time and reduce the risk of errors that often come with manual data entry. Plus, you have the option to export any functions you've defined, which simplifies and speeds up the process of sharing them with other engineers.
Please remember: When importing from JSON/YAML, we'll only extract fields compatible with our form; other fields will be left out for system compatibility. If you want to include specific fields that aren't included in the current setup, let us know!
Watch the full demo here .
Updates to Workflows
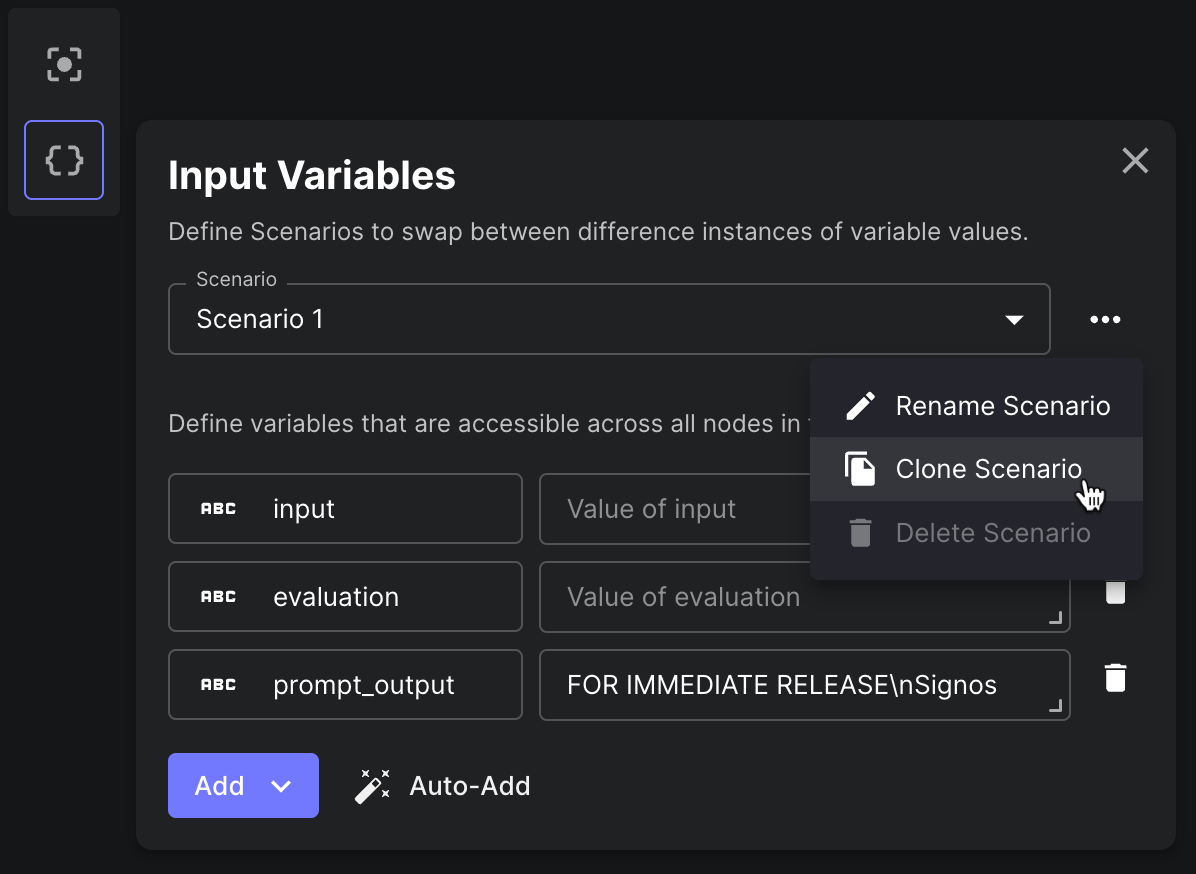
Cloning Workflow Scenarios
You can now clone a Workflow Scenario to create a new Scenario based on an existing one. This is useful when you want to create a new Scenario that is similar to an existing one, but with some changes.
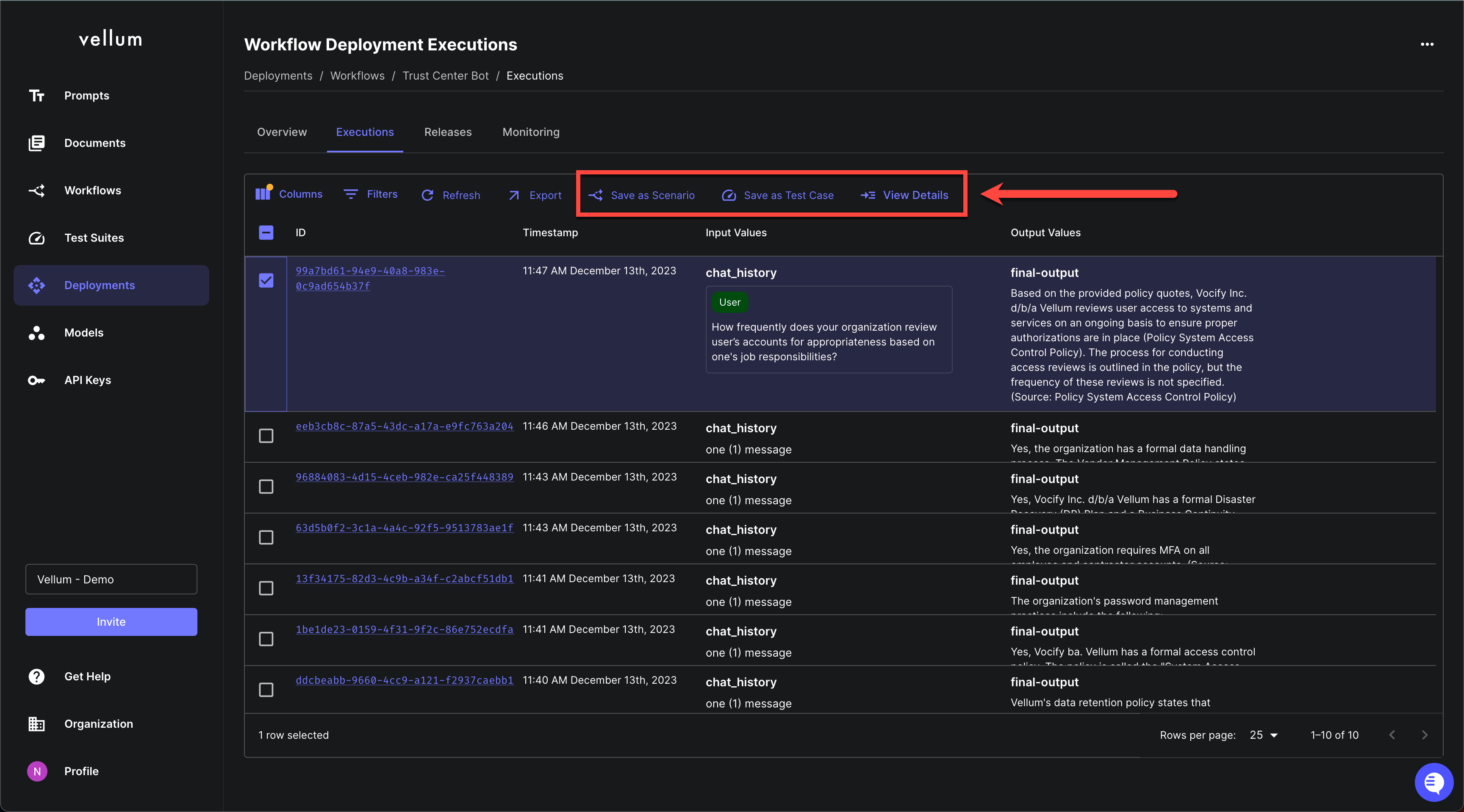
Top-Level Workflow Execution Actions
You can now find the following actions at the top-level of the Workflow and Prompt Deployment Execution pages:
Save as Scenario: Useful for saving an edge case seen in production as a Scenario for qualitative eval. Save as Test Case: Useful for saving an edge case seen in production to your bank of Test Cases for quantitative eval. View Details: Drill in to see specifics about that specific Execution.
API to Execute Workflow w/o Streaming
We've added a new API endpoint for executing a Workflow Deployment without streaming back its incremental results. This is useful when you want to execute a Workflow and only care about its final result or if you're invoking your Workflow via a service that doesn't support HTTP Streaming like Zapier.
Workflow Deployment Execution Visualization Improvements
Now, when visiting the details page for a Workflow Deployment Execution, you'll find an improved loading state as well as a simplified view for Conditional Nodes.
Quality of Life Improvements
Here are other useful features that we shipped in January:
New Models from OpenAI
We add the updated GPT-4 Turbo preview model, and two new embedding models that were launched by OpenAI in the month of January. You can read more about them in their official release .
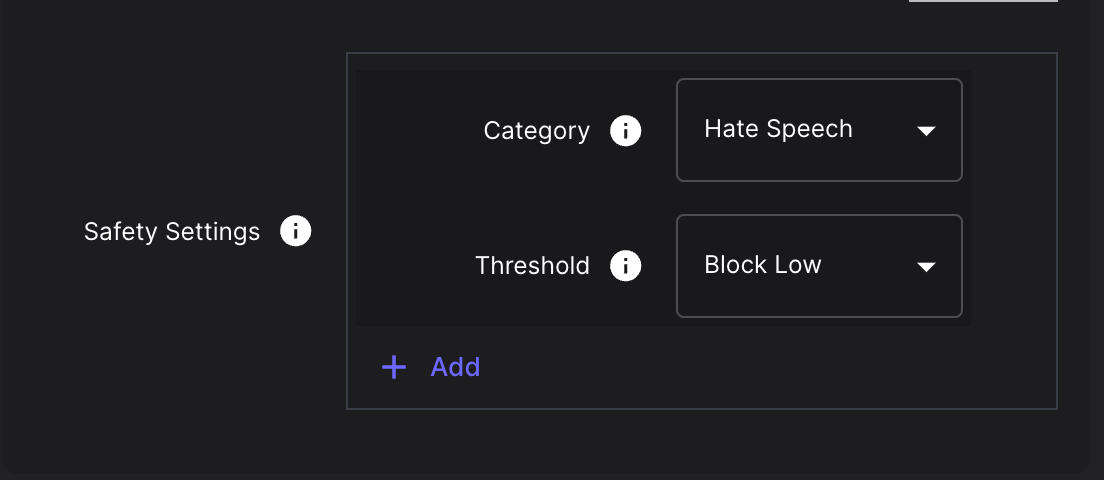
Support for Google Gemini Safety Settings
There is now native support for setting the safetySetting parameters in Google Gemini prompts. You can learn more about how these parameters are used by Google in their docs here .
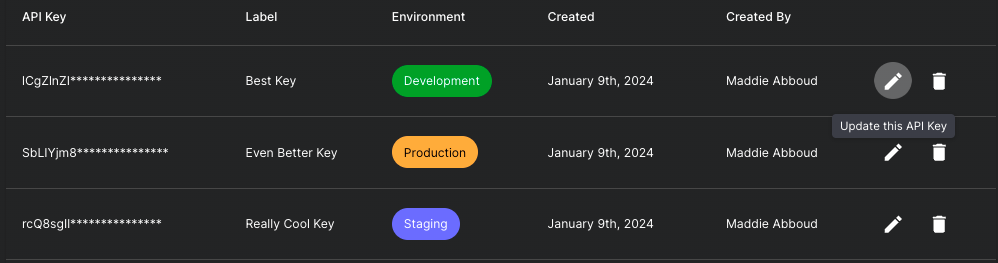
API Key Metadata
Now you can add and view metadata for your Vellum API keys. For example, you can see when an API key was created and by whom. You can also assign a label to an API key to help you keep track of its purpose and an environment tag so that you know where it's used.
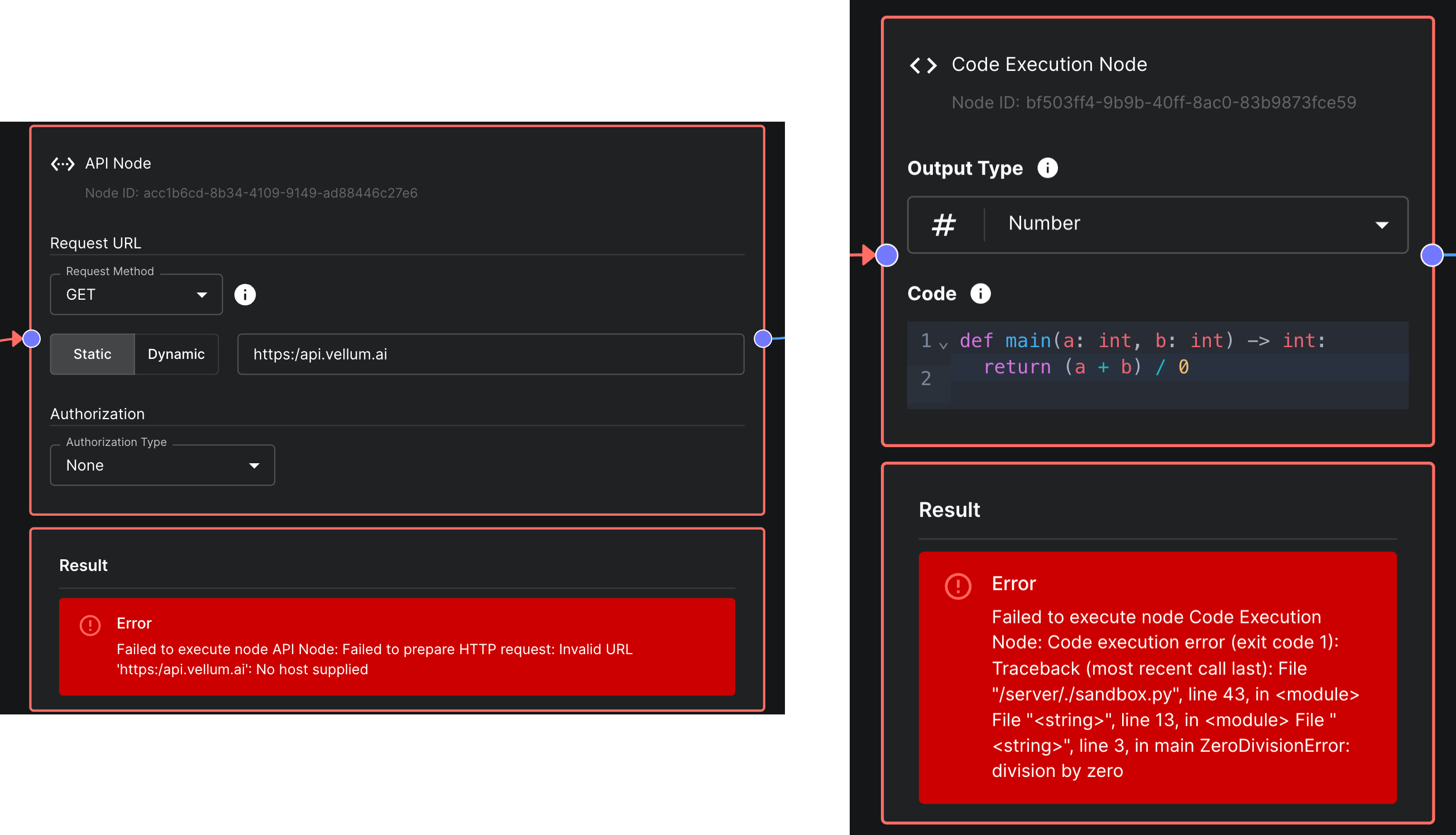
Improved Error Messages in Code & API Nodes
API Nodes and Code Nodes within Workflows now have improved error messages. When an error occurs, the error message will now include the line number and column number where the error occurred. This will make it easier to debug errors in your Workflows.
Looking ahead
We're gearing up for an exciting February with several exciting updates in the pipeline. A big one to keep an eye out for is a revamp of Evaluations in Vellum 👀
A big shoutout to our customers whose active input is significantly shaping our product roadmap!






