What is Prompt Caching?
Prompt caching is a way to save parts of a prompt so the model doesn’t have to reprocess them every time. This makes responses faster and cheaper.
Latency (delay) can be cut by more than 2x. Costs can drop by up to 90%. It’s most helpful for repeated questions, FAQs, or prompts you reuse across different users or sessions. Available for Claude 3.5 Sonnet, Claude 3 Opus, and Claude 3 Haiku.
How does Prompt Caching work?
Normally, when a model reads a prompt, it builds “attention states” (basically, an internal map of how the words connect). Without caching, the model rebuilds this map every time—even if the prompt is the same.
With prompt caching, those maps are saved and reused. That means:
No need to recalculate from scratch. Faster answers. Lower costs.
(See the image below for a visual example.)
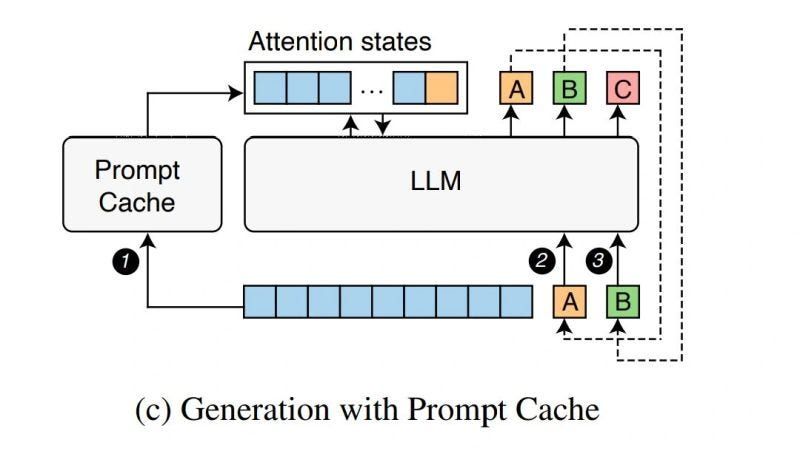
How to use Prompt Caching with Claude models
When you enable prompt caching, here’s what happens on each API request:
The system checks if a cached version of your prompt already exists. If it does, that cached version is used. If not, the full prompt is processed and then stored for future requests.
Key things to know
5-minute limit: Cached prompts expire after 5 minutes of inactivity. Cache points: You can set up to 4 cache breakpoints in a prompt. Scope: Caching applies to the whole prompt (tools → system → messages) up to the cache_control block. No manual reset: Cache clears automatically after 5 minutes. Type: Only “ephemeral” caching is available. Monitoring: Check cache_creation_input_tokens and cache_read_input_tokens in the API response. Minimum size: Claude 3.5 Sonnet & Claude 3 Opus → 1024 tokens Claude 3 Haiku → 2048 tokens
How do I enable Prompt Caching?
Add this header to your API request:
How can I use Prompt Caching? Single-turn conversations To make a cached API call in a single-turn conversation, all you need to do is specify the "cache_control": {"type": "ephemeral"} attribute to the content object. like so:
Multi-turn conversations For multi-turn chats, you can add cache breakpoints as the conversation goes on.
Place cache_control on the System message → marks it as part of the static prefix. Place cache_control on the second-to-last User message → lets the model reuse the earlier cache. Place cache_control on the final turn → so the conversation can continue in follow-ups.
This way, different parts of the conversation can build on the cached context instead of recalculating everything.
How are Prompt Caching tokens priced? Writing to cache: Costs 25% more than the normal input token price. Reading from cache: Costs only 10% of the normal input token price . Actual price depends on the model (see table below). So, caching is slightly more expensive to set up, but much cheaper to reuse , especially if you’re working with repeated prompts.
Pricing Table Model Base Input Tokens Cache Writes Cache Hits Output Tokens Claude 3.5 Sonnet $3 / MTok $3.75 / MTok $0.30 / MTok $15 / MTok Claude 3 Haiku $0.25 / MTok $0.30 / MTok $0.03 / MTok $1.25 / MTok Claude 3 Opus $15 / MTok $18.75 / MTok $1.50 / MTok $75 / MTok
What can you cache with Prompt Caching?
Every block of your API request can be cached:
Tools: Tool definitions in the tools array System messages: Content blocks in the system array Messages: Content blocks in the messages.content array, for both user and assistant turns Images: Content blocks in the messages.content array, in user turns Tool use and tool results: Content blocks in the messages.content array, in both user and assistant turns
When to use Prompt Caching?
Prompt caching is very useful when you’re dealing with longer prompts. Think prompts with many examples, or when you’re retrieving big chunks of data from your vector db.
It’s also very useful in cases where you’re dealing with long multi-turn conversations, where your chatbot needs to remember previous instructions and tasks.
Here are some examples:
Conversational agents
Imagine having a chatbot that needs to handle long conversations or answer questions from uploaded documents. Instead of reprocessing the whole document each time, caching the responses can drastically reduce costs and make responses faster, especially when you’re dealing with repetitive or extended queries.
Coding assistants
If you’re using a tool like an autocomplete or Q&A assistant for coding, caching can help by storing a summarized version of the codebase.
This way, when the assistant pulls up suggestions or answers questions about the code, it doesn’t have to reprocess everything, speeding up the entire experience.
Large document processing
Suppose you have a long legal contract or a research paper that also includes images. Normally, incorporating this kind of detailed content in an AI prompt would slow things down.
But with caching, you can store the material and keep the latency low while still providing a complete and detailed response.
For few-shot instructions
Developers often include just a few examples in their prompts when working with AI models. However, with prompt caching, you can easily include dozens of high-quality examples without increasing the time it takes for the AI to respond. This is great for scenarios where you need the model to give highly accurate responses to complex instructions, like in customer service or technical troubleshooting.
Agentic search and tool use
For tasks that involve multiple steps or tools (like using APIs in stages), caching each round can enhance performance. For example, if you’re building an agent that searches and makes iterative changes based on new information, caching helps by skipping redundant steps.
Q&A over books, papers, and podcasts
Instead of embedding the whole text into a vector database, embed it into the prompt, and enable users to ask questions.



