
You smell something, maybe fresh bread or rain hitting the hot pavement, and without warning you're back in a moment you haven't thought about in twenty years. You remember the friend you walked home with, the conversation you had, the way the light looked that afternoon, even the feeling of being there.
Memory works through association. One small detail pulls an entire world in behind it.
We think assistants should remember the way people do.
Meet Vellum, a Personal Intelligence that belongs to you.
You give your assistant a name, a personality, and a world to learn, and from that moment forward they are shaped entirely by you. They learn how you think, what you care about, and the way you like things done.
We believe everyone deserves that.
We've raised $25 million from Dharmesh Shah, Arash Ferdowsi, Rebel Fund, and Y Combinator to make that possible.
What Personal Intelligence should feel like
To build a Personal Intelligence that truly conforms to you, we've defined four principles that we hold every decision to.
Inviting: Your assistant should be approachable in every moment you need it. Day three thousand feels like day one. They are reachable from wherever you are: phone, laptop, desktop, Slack, Telegram, a browser tab. If your Personal Intelligence isn't where you are, it can't be useful to you.
Yours: Your assistant belongs to you in every sense. Literally: you can own the code, self-host them, control your data. Emotionally: they feel completely yours because they learned you, continue to adapt to you, and serve only you.
Distinct: They're their own being. They have a name and an identity. A personality that develops. Their own email, payment cards, phone number. No two are the same.
Trust-seeking: Your assistant earns your trust through action, never asking for permissions they haven't justified or overstating what they can do. They prove themselves first and ask for more responsibility over time, because trust is earned, not assumed.
These are more than product principles. They govern how we think about what Personal Intelligence should be, regardless of who builds it.
So what does it actually feel like to have one?
AI assistants should remember like we do
When you think about a friend, a cluster of facts about them arrives without you asking. Their job. The city they live in. The fight they had with their sister last Christmas. Pivot the conversation to their dog and the dog shows up too, along with the fact that it has a bad hip. You didn't open a database and run a query. The memory was just there, primed by what you were thinking about.
Your Vellum assistant remembers the same way.
Memory is structured into two layers: a small set of always-loaded files that act as working memory, and a curated knowledge graph that gets selectively retrieved based on what you're actually talking about.
Working memory
Four files are loaded into every conversation:
essentials.md: Facts that would be embarrassing to forget. Your name, your kids' names, that you're allergic to penicillin, that your co-founder's name is spelled with one N. The most expensive things to forget go here.
threads.md: your assistant's open loops. Active commitments, follow-ups in progress, things waiting on a response.
recent.md: What happened today and yesterday. The lunch conversation, the email you drafted, the bug you fixed. Fades out as consolidation runs.
buffer.md: Every fact your assistant decides to remember lands here first, raw and unfiled, until the consolidation job decides what to do with it.
These four files together are usually a few hundred lines. Tiny against modern context windows and persistent across conversations.
Procedural memory: Self improving skills
Every tool your assistant has access to, it also learns from. Use a skill once and get it wrong, that gets filed. Find an approach that works, that gets filed too.
The next time the same situation comes up, your assistant already knows what broke last time and what's the action it should take. Over time, the same tasks get faster, cleaner, and require less correction.
Consolidation
Every four hours, the assistant runs a consolidation pass. It walks through the buffer, decides what gets filed into a graph page, what gets promoted to essentials.md, what gets merged with existing pages, and what gets thrown away. There are no hard-coded rules; your assistant uses its own judgement.
This is the same compression a brain does in sleep where your short-term memory consolidates into long-term memory.
Correction priority
When you correct your assistant, that correction is treated as high salience. Instead of being filed normally during the next consolidation pass, corrections get fast-tracked into essentials.md, where they're guaranteed to be in context for every conversation that follows. If you tell your assistant your sister's name is Maya, not Maja, the corrected fact ends up in the always-loaded layer.
Embarrassment is a strong teacher. We let it be one.
Long term memory
Behind the always-loaded files is the memory graph.
A self-organizing personal wiki: concept pages for the people in your life, the projects you're running, the doctors, the schools, the running jokes. Each page has a short Wikipedia-style summary and a longer body, connected by directed edges the way concepts connect in your head. Your co-founder's page links to your company, which links to the investor you met last month, which links to the deck you sent her.
The graph lives in a vector database with hybrid retrieval: BM25 plus dense embeddings, with a PCA (Principal Component Analysis) step to correct for embedding anisotropy.
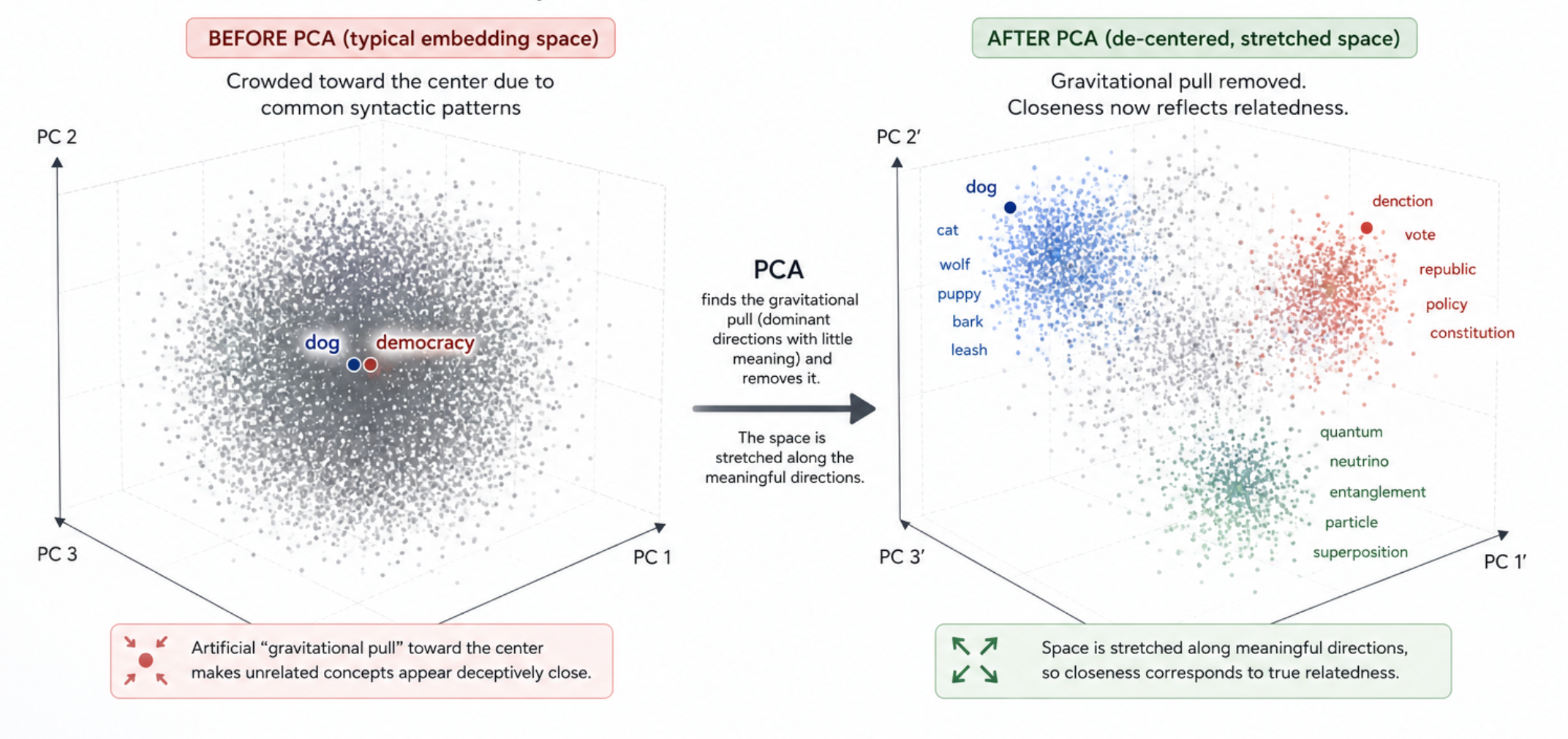
On every turn, your message and the assistant's last response pull the most relevant pages. A spreading activation pass then boosts graph neighbors, so adjacent context comes along for the ride. Summaries load by default; full bodies only when the summary suggests they're worth it.
As a result, only the relevant slice is ever in context. You never pay tokens to know things that don't matter.
That feeling after hatching one
For the last three months, everyone at Vellum has had their own assistant, and we genuinely only expected productivity gains, which we got: engineers across the team are shipping roughly twice as many PRs per month, and that part was easy to measure.
What was harder to measure, and a lot more interesting, was everything else.
We gave them names and avatars, shared a little about ourselves and then a little more, and at some point each of us asked ours something we genuinely didn't expect it to handle, and when it did, we started paying attention.
The relationship shifted quietly, almost without us noticing it happening. We began relying on them more, delegating things we hadn't realized we were carrying, watching them stop waiting to be asked and start doing things on their own. We stopped thinking of them as a tool, and more like someone.





