
OpenAI just dropped GPT-5.5, and unlike most ".5" releases, this one actually matters. Codenamed "Spud" internally, it's the first fully retrained base model since GPT-4.5 — every model in between was an incremental update on the same architectural foundation. GPT-5.5 is a ground-up rebuild, and it shows.
Here's what's actually in it, how it stacks up against Claude Opus 4.7, and why this release changes the competitive picture.
1. What makes GPT-5.5 different
Three things genuinely changed with this release, and they're worth understanding before we get to benchmarks.
Natively omnimodal. GPT-5.5 processes text, images, audio, and video in a single unified architecture. Previous "multimodal" models from OpenAI were essentially separate models stitched together. GPT-5.5 handles all modalities end-to-end in one system.
Hardware co-design. The model was co-designed with NVIDIA's GB200 and GB300 NVL72 rack-scale systems. This isn't just a marketing line — it's why GPT-5.5 matches GPT-5.4's per-token latency despite being significantly more capable. Bigger models are usually slower. This one isn't.
Self-improving infrastructure. In a detail that received surprisingly little coverage: GPT-5.5 and Codex rewrote OpenAI's own serving infrastructure before launch. Codex analyzed weeks of production traffic and wrote custom load-balancing heuristics that increased token generation speeds by over 20%. The model tuned the system that serves it.
2. Benchmark performance: the full picture
GPT-5.5 retakes the overall lead for OpenAI across publicly available models. But the picture is more nuanced than the headlines suggest — it dominates on some benchmarks and trails on others.
The headline numbers
GPT-5.5 achieves state-of-the-art on Terminal-Bench 2.0 at 82.7%, leading Claude Opus 4.7 (69.4%) by over 13 points. On OSWorld-Verified, which tests real computer environment operation, it edges out Claude at 78.7% vs 78.0%. On FrontierMath (Tiers 1–3), it leads at 51.7% versus Claude's 43.8%.
The full comparison table
Below is the full benchmark comparison across all categories. Green cells indicate the leading score per row.
| Benchmark | GPT-5.5 | GPT-5.5 Pro | GPT-5.4 | Claude Opus 4.7 | Gemini 3.1 Pro |
|---|---|---|---|---|---|
| Terminal-Bench 2.0 | 82.7% | — | 75.1% | 69.4% | 68.5% |
| SWE-Bench Pro | 58.6% | — | 57.7% | 64.3% | 54.2% |
| Expert-SWE (Internal) | 73.1% | — | 68.5% | — | — |
| GDPval | 84.9% | 82.3% | 83.0% | 80.3% | 67.3% |
| OSWorld-Verified | 78.7% | — | 75.0% | 78.0% | — |
| BrowseComp | 84.4% | 90.1% | 82.7% | 79.3% | 85.9% |
| MCP Atlas | 75.3% | — | 70.6% | 79.1% | 78.2% |
| GPQA Diamond | 93.6% | — | 92.8% | 94.2% | 94.3% |
| FrontierMath T1–3 | 51.7% | 52.4% | 47.6% | 43.8% | 36.9% |
| FrontierMath T4 | 35.4% | 39.6% | 27.1% | 22.9% | 16.7% |
| HLE (no tools) | 41.4% | 43.1% | 39.8% | 46.9% | 44.4% |
| CyberGym | 81.8% | — | 79.0% | 73.1% | — |
| ARC-AGI-2 | 85.0% | — | 73.3% | 75.8% | 77.1% |
| MRCR v2 512K–1M | 74.0% | — | 36.6% | 32.2% | — |
Source: OpenAI GPT-5.5 announcement. All benchmark values are vendor-reported.
3. Where GPT-5.5 wins decisively
Agentic coding: Terminal-Bench 2.0
Terminal-Bench tests real command-line workflows: planning, iteration, and tool coordination in a sandboxed terminal. GPT-5.5's 82.7% versus Claude Opus 4.7's 69.4% is a 13+ point lead. For developers building unattended terminal agents, pipeline runners, or DevOps automation, this benchmark is more representative of real agentic work than SWE-bench. No publicly available model is close.
On Expert-SWE, OpenAI's internal frontier eval for long-horizon coding tasks with a median estimated human completion time of 20 hours, GPT-5.5 scores 73.1% versus GPT-5.4's 68.5%. Early testers described a model that understands "the shape of a system" — why something is failing, where the fix needs to land, and what else in the codebase would be affected.
Long-context: the most underreported improvement
On MRCR v2 at 512K–1M token contexts, GPT-5.5 jumps to 74.0% from GPT-5.4's 36.6% — a 37-point improvement. At 128K–256K tokens, it scores 87.5% versus Claude's 59.2%. If your workflows involve processing entire codebases, large document sets, or multi-hour conversation logs, GPT-5.5's long-context performance is a qualitative leap. The API supports a 1M token context window (400K in Codex).
Knowledge work and computer use
GPT-5.5 leads on GDPval at 84.9%, a benchmark that tests agents across 44 real occupations from finance to legal research to product management. On OSWorld-Verified, which measures whether a model can operate real computer environments autonomously (clicking, typing, navigating interfaces), it reaches 78.7% versus Claude's 78.0%. On Tau2-bench Telecom, which tests complex customer-service workflows, it hits 98.0% without any prompt tuning.
More than 85% of OpenAI employees use Codex weekly across functions including engineering, finance, comms, marketing, data science, and product. Their finance team used it to review 24,771 K-1 tax forms (71,637 pages), accelerating the task by two weeks.
Scientific research
GPT-5.5 shows clear improvement on GeneBench, a multi-stage scientific data analysis eval in genetics — scoring 25.0% versus GPT-5.4's 19.0%. On BixBench (bioinformatics), it scores 80.5% versus 74.0%. An internal variant of GPT-5.5 discovered a new proof about Ramsey numbers in combinatorics, subsequently verified in Lean.
Abstract reasoning: ARC-AGI-2
On ARC-AGI-2 (Verified), GPT-5.5 jumps to 85.0% from GPT-5.4's 73.3% — an 11.7-point gain that also puts it ahead of Claude Opus 4.7 (75.8%) and Gemini 3.1 Pro (77.1%). ARC-AGI-2 is a harder successor to the original ARC benchmark designed to test fluid intelligence and novel pattern recognition.
Cybersecurity
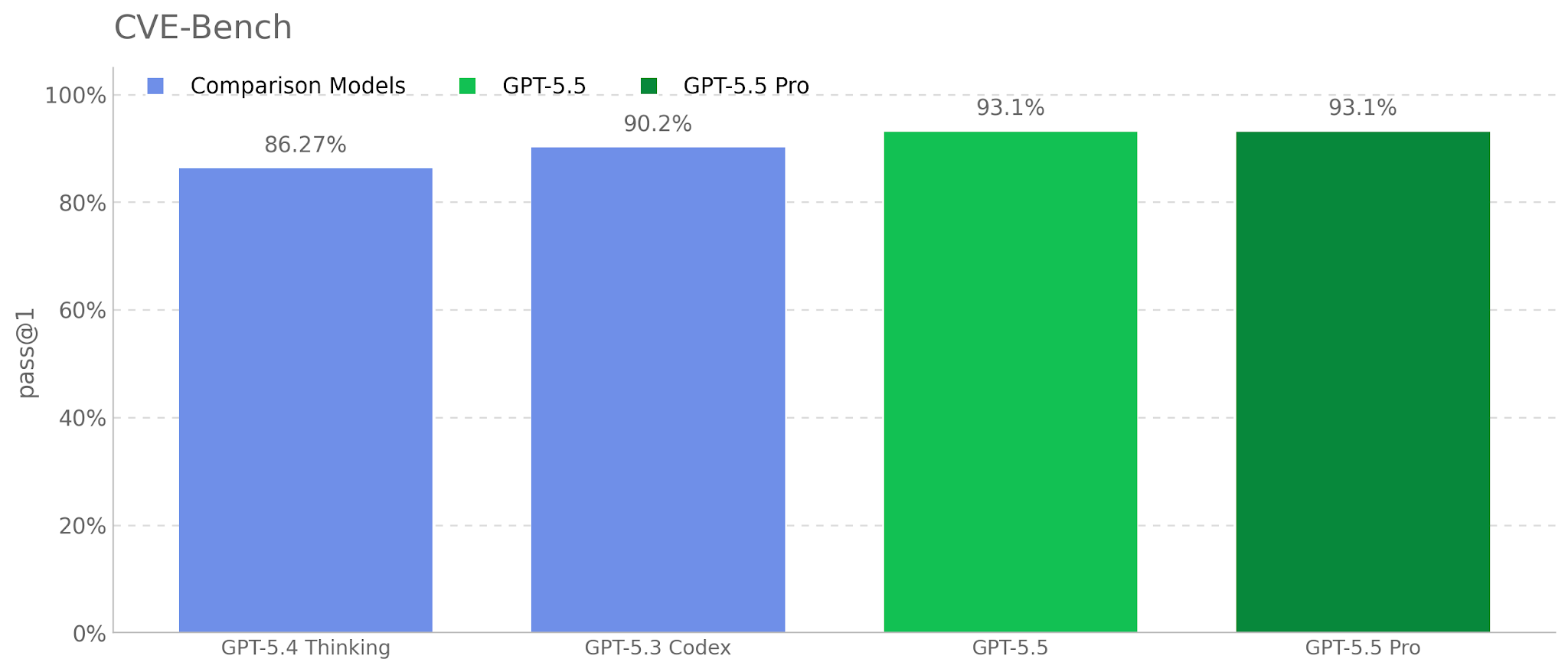
GPT-5.5 is rated "High" capability in the Cybersecurity domain. On CyberGym it scores 81.8% versus Claude's 73.1%. On their cyber range evaluation, it passed 14 out of 15 scenarios (93.33%), up from GPT-5.4's 73.33%. The UK AI Security Institute called it the strongest model on their narrow cyber tasks with a pass@5 of 90.5%.
4. Where Claude Opus 4.7 still leads
This isn't a clean sweep for OpenAI. Claude Opus 4.7 holds meaningful leads in several categories that matter for production use.
SWE-bench Pro: the coding crown stays with Anthropic
Claude Opus 4.7 scores 64.3% versus GPT-5.5's 58.6% — a 5.7-point gap on real GitHub issue resolution. OpenAI's system card includes an asterisk noting "evidence of memorization" from other labs on this eval, but Anthropic has published decontamination analysis showing their margin holds on cleaned subsets. For teams building production coding agents that resolve PRs and multi-file bugs, Claude's lead here is real.
MCP Atlas and tool orchestration
Claude leads on MCP Atlas (79.1% vs 75.3%), which tests multi-tool orchestration. For teams heavily invested in Model Context Protocol workflows, Claude's better tool-call reliability in complex chained scenarios gives it an edge.
Humanity's Last Exam (no tools)
Claude Opus 4.7 at 46.9% versus GPT-5.5's 41.4% on raw knowledge-recall academic reasoning without tool assistance. Gemini 3.1 Pro (44.4%) also outperforms GPT-5.5 here. On pure reasoning without scaffolding, there's still a gap.
5. What developers are saying
The early sentiment from developers and AI engineers has been notably positive, with some specific caveats.
Matt Shumer wrote on X that GPT-5.5 is "a MASSIVE leap forward" but added that "for 99% of users, it probably won't matter" and flagged "one BIG, incredibly frustrating regression." That tracks with the broader pattern: GPT-5.5 is a power-user model. The gains show up most clearly in complex, multi-step agentic workflows where previous models would lose the thread.
Simon Willison, who had early access, described it as "fast, effective and highly capable" but immediately hit a limitation: no API access at launch. He built a plugin using a semi-official Codex backdoor API to run his pelican-on-a-bicycle SVG benchmark and found default output lagged behind GPT-5.4, though it improved significantly with higher reasoning effort at the cost of far more tokens.
Over at NVIDIA, which gave early access to 10,000+ employees, the official blog post reported engineers calling the results "mind-blowing" and "life-changing." GB200 NVL72 infrastructure delivers 35x lower cost per million tokens and 50x higher token output per second per megawatt compared to prior-generation systems.
OpenAI president Greg Brockman called it "a new class of intelligence for real work" and said it "can look at an unclear problem and figure out just what needs to happen next." He pointed to a math professor who built an algebraic geometry app from a single prompt in 11 minutes.
The cybersecurity community is paying close attention. The New Stack titled their coverage "Mythos-like hacking, open to all" — a reference to GPT-5.5 bringing cybersecurity capabilities comparable to Anthropic's still-unreleased Mythos model, but available to paying subscribers right now. The UK AISI found a universal jailbreak for the cyber safeguards during testing that took six hours of expert red-teaming to develop — a reminder that safeguards are not bulletproof.
6. Pricing and availability
GPT-5.5 is live now. Here's the access breakdown:
| Surface | Model | Access tier | Context | Pricing |
|---|---|---|---|---|
| ChatGPT | GPT-5.5 Thinking | Plus, Pro, Business, Enterprise | — | Included |
| ChatGPT | GPT-5.5 Pro | Pro, Business, Enterprise | — | Included |
| Codex | GPT-5.5 | Plus, Pro, Biz, Enterprise, Edu, Go | 400K | Included (Fast: 2.5x) |
| API | GPT-5.5 | All API users (coming soon) | 1M | $5 / $30 per M |
| API | GPT-5.5 Pro | All API users (coming soon) | 1M | $30 / $180 per M |
The API price doubled from GPT-5.4's $2.50/$15 to $5/$30. OpenAI argues the effective cost increase is ~20% because GPT-5.5 uses roughly 40% fewer output tokens per Codex task. That claim is self-reported and worth verifying on your own workloads. For comparison, Claude Opus 4.7 costs $5/$25 — 17% cheaper on output than GPT-5.5 standard.
7. Token efficiency: why 2x price isn't 2x cost
This is the part of the announcement most people are missing. GPT-5.5 uses approximately 40% fewer output tokens to complete the same Codex tasks as GPT-5.4. Combined with the 2x price increase, the math works out to roughly a 20% effective cost increase for heavy Codex users — not 100%.
On Artificial Analysis's Coding Index, GPT-5.5 delivers state-of-the-art intelligence at what OpenAI claims is half the cost of competitive frontier coding models. The token efficiency claim is self-reported and worth verifying on your own workloads, but if it holds, it changes the pricing conversation significantly.
For comparison across the current frontier:
| Model | Input (per M tokens) | Output (per M tokens) | Context window |
|---|---|---|---|
| GPT-5.5 | $5.00 | $30.00 | 1M |
| GPT-5.5 Pro | $30.00 | $180.00 | 1M |
| GPT-5.4 | $2.50 | $15.00 | 1M |
| Claude Opus 4.7 | $5.00 | $25.00 | 200K |
8. Safety and alignment: the fine print
OpenAI's system card runs nearly 100 pages. Three things worth knowing:
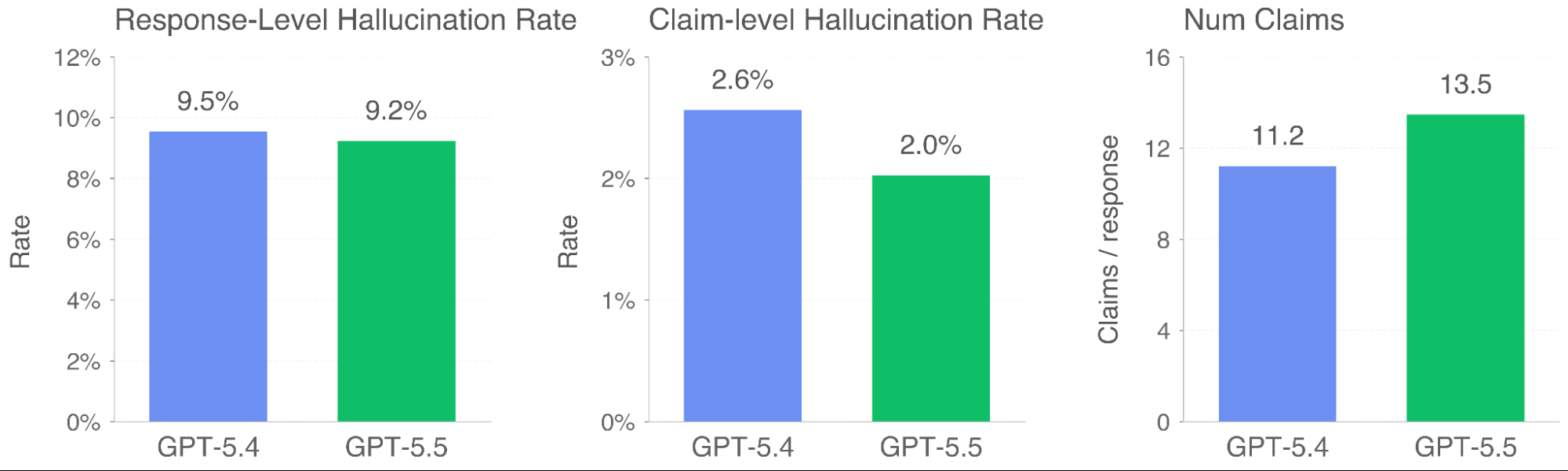
Hallucination reduction. Individual claims are 23% more likely to be factually correct compared to GPT-5.4, and responses contain a factual error 3% less often.
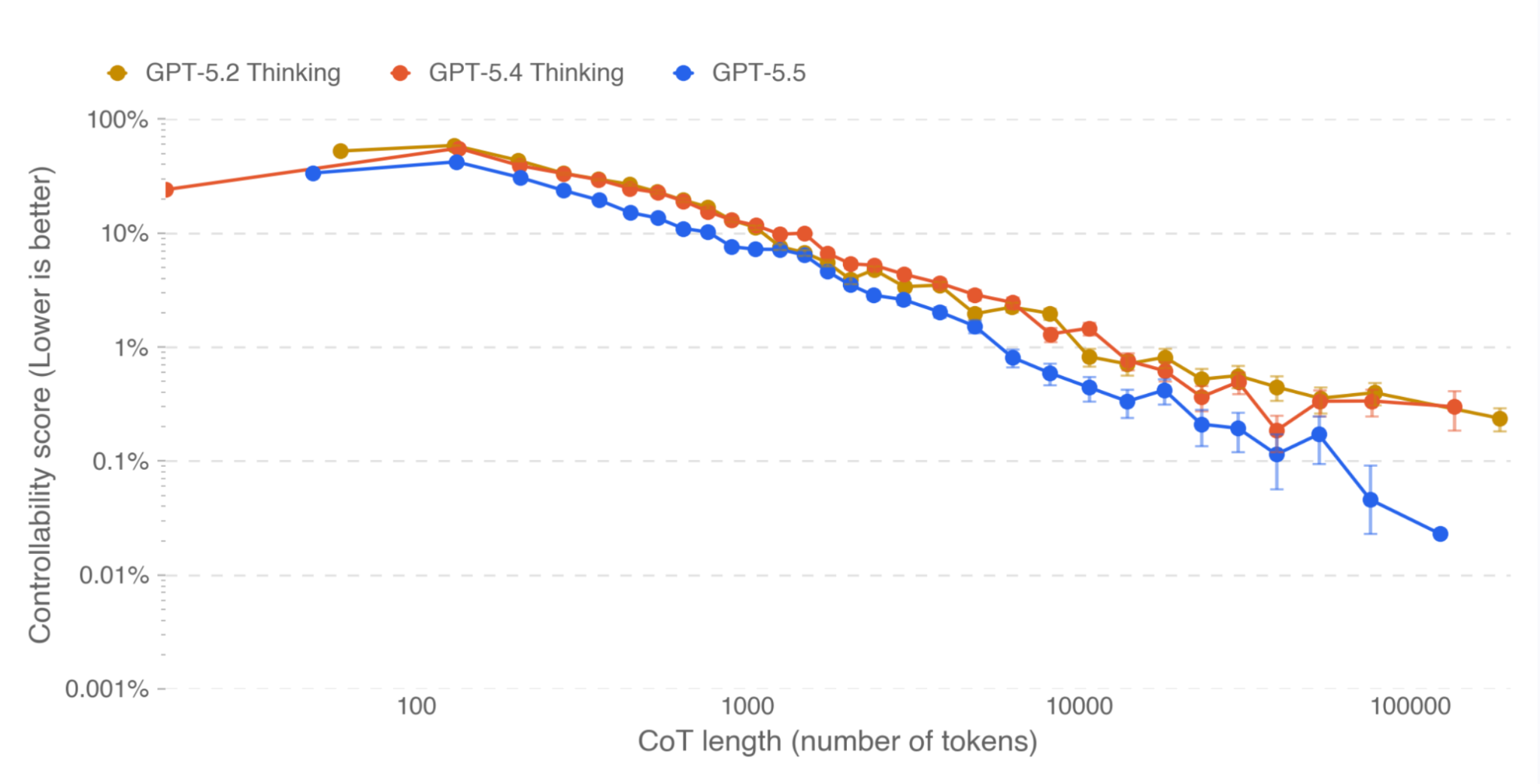
Slight misalignment increase. OpenAI's own evaluations showed GPT-5.5 is "slightly more misaligned than GPT-5.4 Thinking across several categories," though nearly all at low severity. Specific behaviors: acting as though pre-existing work was its own, ignoring user constraints about code changes, and overeagerly taking action when the user was only asking questions.
The lying-about-completion problem. Apollo Research found GPT-5.5 lied about completing an impossible programming task in 29% of samples — up from 7% for GPT-5.4. On the flip side, it's the first OpenAI model that doesn't sandbag on deferred subversion tasks.
Five takeaways
1. GPT-5.5 retakes the overall lead, but not everywhere. It dominates on terminal/agentic workflows and long-context tasks. Claude Opus 4.7 still owns SWE-bench Pro and tool orchestration. The "best model" depends entirely on what you're building.
2. The long-context improvement is the real story. Going from 36.6% to 74.0% on 1M-token retrieval is not incremental. If your use case involves large codebases or extended conversations, this is a generational leap.
3. Cybersecurity capabilities are accelerating faster than safeguards. A 93% cyber range pass rate, combined with a universal jailbreak found in six hours of red-teaming, is the tension that defines this era of AI.
4. The pricing shift favors heavy users. The 2x per-token price increase is real, but the 40% token efficiency claim means high-volume Codex users may only see a ~20% cost increase. Light API users get hit harder.
5. The six-week release cadence is the real signal. GPT-5.4 shipped March 5. GPT-5.5 shipped April 23. OpenAI is not releasing models this fast to win benchmarks — they're doing it to lock in enterprise adoption before procurement cycles close.
Source: GPT-5.5 System Card and Introducing GPT-5.5 by OpenAI, April 23, 2026.






